- Pumping-Lemma
-
Das Pumping-Lemma bzw. Pumplemma (auch Schleifensatz genannt) beschreibt in der theoretischen Informatik eine Eigenschaft bestimmter Klassen formaler Sprachen. In vielen Fällen lässt sich anhand des Lemmas nachweisen, dass eine formale Sprache nicht regulär bzw. nicht kontextfrei ist.
Seinen Namen hat das Lemma vom englischen Begriff to pump, zu deutsch aufpumpen. Es leitet sich davon ab, dass Teile von Wörtern aus Sprachen bestimmter Klassen vervielfacht (aufgepumpt) werden können, so dass die dabei entstehenden Wörter ebenfalls in der Sprache sind.
Man unterscheidet zunächst zwischen dem Pumping-Lemma für reguläre Sprachen und jenem für kontextfreie Sprachen. In der Literatur sind weiterhin Pumping-Lemmata für Erweiterungen der kontextfreien Sprachen anzutreffen. Mächtigere Sprachklassen in der Chomsky-Hierarchie wie die kontextsensitiven Sprachen und auch die wachsend kontextsensitiven Sprachen ermöglichen jedoch kein Pumpinglemma.
Alternativ wird das Lemma bzw. seine Ausprägungen auch als uvw-Theorem, uvwxy-Theorem, Schleifenlemma, Iterationslemma oder Lemma von Bar-Hillel bezeichnet.
Inhaltsverzeichnis
Reguläre Sprachen
Pumping-Lemma für reguläre Sprachen
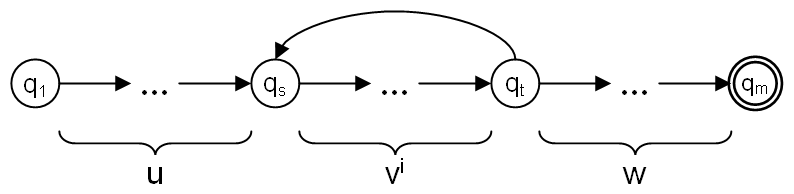
Für jede reguläre Sprache L gibt es eine natürliche Zahl n, so dass gilt: Jedes Wort z in L mit Mindestlänge n hat eine Zerlegung z = uvw mit den folgenden drei Eigenschaften:
- Die beiden Wörter u und v haben zusammen höchstens die Länge n.
- Das Wort v ist nicht leer.
- Für jede nichtnegative Zahl i ist das Wort uviw in der Sprache L. Das heißt die Wörter uw, uvw, uvvw, uvvvw, usw. sind alle in der Sprache L.
Neben den regulären Sprachen gibt es auch nicht-reguläre Sprachen, die dieses Lemma erfüllen. Eine notwendige und hinreichende Bedingung für reguläre Sprachen liefern der Satz von Myhill-Nerode oder Jaffes Pumping-Lemma.
Das Pumping-Lemma enthält mehrere Wechsel zwischen universeller und existentieller Quantifizierung. Diese kann man gut anhand der folgenden formalen Formulierung des Lemmas erkennen. Darin bezeichnet
 die Menge aller regulärer Sprachen.
die Menge aller regulärer Sprachen.Beweis
Die Gültigkeit des Lemmas basiert darauf, dass es zu jeder regulären Sprache einen deterministischen endlichen Automaten gibt, der die Sprache akzeptiert. Über einem endlichen Alphabet enthält eine reguläre Sprache mit unendlich vielen Wörtern auch solche Wörter, die mehr Zeichen enthalten als der Automat Zustände hat. Zum Akzeptieren solcher Wörter muss der Automat also einen Zyklus enthalten, der dann in beliebiger Häufigkeit durchlaufen werden kann. Die Buchstabenfolge, die beim Durchlaufen des Zyklus gelesen wird, kann also entsprechend beliebig oft in Wörtern der Sprache vorkommen.
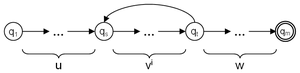 Die Idee des Pumping-Lemmas ist, dass ein Wortteil durch einen Zyklus im deterministischen endlichen Automaten beliebig oft wiederholt werden kann.
Die Idee des Pumping-Lemmas ist, dass ein Wortteil durch einen Zyklus im deterministischen endlichen Automaten beliebig oft wiederholt werden kann.
Der folgende Beweis setzt die Mindestlänge n aus dem Lemma mit der Anzahl der Zustände des Automaten gleich und zeigt, dass wegen der Existenz eines Zyklus jedes Wort mit dieser Mindestlänge die geforderte Zerlegung besitzt.
Sei L eine reguläre Sprache. Ist L endlich, dann gibt es ein Wort mit maximaler Länge k. Sei n = k + 1, so ist für alle
 die Prämisse
die Prämisse  falsch und die Implikation damit wahr.
falsch und die Implikation damit wahr.Ist L unendlich, dann sei M ein deterministischer endlicher Automat, der L akzeptiert, und sei n die Anzahl der Zustände dieses Automaten. Da L regulär ist, existiert ein solcher Automat M immer.
Sei nun z ein beliebiges Wort aus L mit mindestens n Zeichen, also
 . Bezeichne mit
. Bezeichne mit  die Zustandsfolge, die M beim Lesen von z beginnend mit dem Startzustand q1 durchläuft. Insbesondere gilt k = | z | + 1. Da z in L ist, muss z von M akzeptiert werden, d.h. qk muss ein Endzustand sein. Da der Automat M gerade n Zustände hat, muss spätestens nach dem Lesen von n Zeichen eine Zustandswiederholung eintreten. Das heißt es existieren
die Zustandsfolge, die M beim Lesen von z beginnend mit dem Startzustand q1 durchläuft. Insbesondere gilt k = | z | + 1. Da z in L ist, muss z von M akzeptiert werden, d.h. qk muss ein Endzustand sein. Da der Automat M gerade n Zustände hat, muss spätestens nach dem Lesen von n Zeichen eine Zustandswiederholung eintreten. Das heißt es existieren  mit qi = qj. Der Automat M durchläuft auf z also einen Zyklus.
mit qi = qj. Der Automat M durchläuft auf z also einen Zyklus.Sei v der Teil von z, der beim Durchlaufen des Zyklus
 gelesen wird. Ferner sei u der Teil von z, der beim Durchlaufen der davor liegenden Zustandsfolge
gelesen wird. Ferner sei u der Teil von z, der beim Durchlaufen der davor liegenden Zustandsfolge  gelesen wird, und w sei der Teil von z, der beim Durchlaufen der dahinter liegenden Zustandsfolge
gelesen wird, und w sei der Teil von z, der beim Durchlaufen der dahinter liegenden Zustandsfolge  gelesen wird. Mit dieser Wahl gilt z = uvw.
gelesen wird. Mit dieser Wahl gilt z = uvw.Mit dieser Wahl von u, v und w gelten die Aussagen aus dem Pumping-Lemma:
- Die Länge von uv ist j − 1 und somit nicht größer als n.
- Das Wort v ist nicht leer, da
 gilt, so dass beim Durchlauf des Zyklus mindestens ein Zeichen gelesen wird.
gilt, so dass beim Durchlauf des Zyklus mindestens ein Zeichen gelesen wird. - Für beliebiges
 durchläuft der Automat beim Lesen des Worts uvmw zunächst die Zustandsfolge , dann m-mal den Zyklus und schließlich die Zustandsfolge . Am Ende befindet sich der Automat im Endzustand qk. Somit gilt
durchläuft der Automat beim Lesen des Worts uvmw zunächst die Zustandsfolge , dann m-mal den Zyklus und schließlich die Zustandsfolge . Am Ende befindet sich der Automat im Endzustand qk. Somit gilt  für alle .
für alle .
Beispiel
Ist die Sprache
 regulär?
regulär?Angenommen, L sei eine reguläre Sprache. Dann gibt es gemäß Pumping-Lemma eine Zahl n, so dass sich alle Wörter
mit wie beschrieben zerlegen lassen.Man betrachte nun speziell das Wort z = uvw = anbn.
Gemäß Bedingung 1 ist v nicht leer, gemäß Bedingung 2 besteht uv und somit auch v ausschließlich aus as (da
 und
und  ). Mit Bedingung 3 müsste das Wort
). Mit Bedingung 3 müsste das Wort  in L liegen. Das ist aber offensichtlich falsch, denn dieses Wort hat mehr as als bs, da
in L liegen. Das ist aber offensichtlich falsch, denn dieses Wort hat mehr as als bs, da  größer 0. Damit gilt: L kann nicht regulär sein.
größer 0. Damit gilt: L kann nicht regulär sein.Eine nicht-reguläre Sprache, die das Pumping-Lemma erfüllt
Die Sprache
 ist nicht regulär. Allerdings erfüllt L das Pumping-Lemma, denn jedes Wort lässt sich so zerlegen z = uvw, dass auch für alle
ist nicht regulär. Allerdings erfüllt L das Pumping-Lemma, denn jedes Wort lässt sich so zerlegen z = uvw, dass auch für alle 
 . Dazu kann v einfach als erster Buchstabe gewählt werden. Dieser ist entweder ein a, die Anzahl von führenden as ist beliebig. Oder er ist ein b oder c, ohne führende as ist aber die Anzahl von führenden bs oder cs beliebig.
. Dazu kann v einfach als erster Buchstabe gewählt werden. Dieser ist entweder ein a, die Anzahl von führenden as ist beliebig. Oder er ist ein b oder c, ohne führende as ist aber die Anzahl von führenden bs oder cs beliebig.Jaffes Pumping-Lemma
Jeffrey Jaffe hat ein verallgemeinertes Pumping-Lemma entwickelt [1], das äquivalent zur Definition der regulären Sprachen ist. Es ist also eine notwendige und hinreichende Bedingung zum Nachweis der Regularität einer Sprache.
Die Sprache
 ist regulär genau dann, wenn eine Konstante
ist regulär genau dann, wenn eine Konstante  existiert, so dass es für alle
existiert, so dass es für alle  , eine Zerteilung z = uvw mit
, eine Zerteilung z = uvw mit  gibt, so dass für alle und Suffixe
gibt, so dass für alle und Suffixe  gilt:
gilt: .
.
Kontextfreie Sprachen
Annahmen
Sei
 die Klasse aller Sprachen, die von Chomsky-Hierarchie-Typ-2-Grammatiken erzeugt werden. bezeichnet somit die Klasse der kontextfreien Sprachen.
die Klasse aller Sprachen, die von Chomsky-Hierarchie-Typ-2-Grammatiken erzeugt werden. bezeichnet somit die Klasse der kontextfreien Sprachen.Aussage des Pumping-Lemmas für kontextfreie Sprachen
Für eine kontextfreie Sprache L gibt es eine natürliche Zahl n so, dass sich alle Wörter z der Sprache mit Mindestlänge n in fünf Teilworte uvwxy zerlegen lassen, wobei das zweite und das vierte Wort vx nicht beide leer sein dürfen, die drei mittleren Worte zusammen vwx nicht länger als n sind, und das zweite und vierte beliebig, aber gleich oft (auch keinmal) wiederholt werden dürfen, ohne dass das entstehende, aufgepumpte Wort nicht mehr in der Sprache L wäre:
Neben den kontextfreien Sprachen gibt es auch nicht kontextfreie Sprachen, die dieses Pumping-Lemma erfüllen. Die Umkehrung des Lemmas gilt im Allgemeinen also nicht. Eine Verallgemeinerung des Pumping-Lemmas für kontextfreie Sprachen ist Ogdens Lemma.
Korrektheitsbeweis
Gegeben sei eine kontextfreie Grammatik G in Chomsky-Normalform mit N Variablen, für die gilt, dass sie gerade die gewünschte Sprache beschreibt. Sei nun ein Wort x aus dieser Sprache gegeben, für das gilt:
 .
.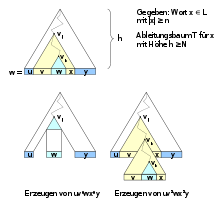 Die Idee des Pumping-Lemmas für kontextfreie Sprachen ist, dass ein Wortteil durch mehrfaches Ableiten derselben Variablen beliebig oft wiederholt werden kann.
Die Idee des Pumping-Lemmas für kontextfreie Sprachen ist, dass ein Wortteil durch mehrfaches Ableiten derselben Variablen beliebig oft wiederholt werden kann.Betrachten wir nun einen Ableitungsbaum T für x mit Höhe h. Da unsere Sprache in CNF angegeben wurde, hat T die Form eines Binärbaumes. Daraus folgt für die Höhe von T
 . Es gibt also einen Pfad
. Es gibt also einen Pfad  in T von der Wurzel zu einem Blatt, für den gilt, dass er Länge
in T von der Wurzel zu einem Blatt, für den gilt, dass er Länge  hat. Es existieren also zwei Knoten vj,vk auf diesem Pfad mit
hat. Es existieren also zwei Knoten vj,vk auf diesem Pfad mit  , welche die gleichen Variablen von G Aj,Ak repräsentieren.
, welche die gleichen Variablen von G Aj,Ak repräsentieren.Betrachtet man den Teilbaum Tk, welcher von vk aus aufgespannt wird, so bilden dessen Blätter den Teilstring w. Der Teilbaum Tj, welcher von vj aufgespannt wird, besitzt als Teilbaum den Baum Tk. Man kann also die Blätter von Tj aufteilen in Blätter links von Tk und Blätter rechts von Tk und erhält somit eine Aufteilung der Blätter von Tj der Form vwx. Ebenso unterteilt der Teilbaum Tj den gesamten Ableitungsbaum in drei Teile u,vwx,y. Wir erhalten also als Aufteilung die Teilstrings u,y, welche im Ableitungsbaum links bzw. rechts von dem von vj aufgespannten Teilbaum liegen, die Teilstrings v,x, welche in dem Teilbaum Tj liegen nicht jedoch in Tk, und zu guter Letzt den Teilstring w, welcher in Tk liegt. Da vj und vk die gleichen Variablen unserer Grammatik repräsentieren, folgt daraus, dass der Pfad von vj nach vk beliebig oft wiederholt werden kann. Durch eine Wiederholung des Pfades würden wir Worte der Form uviwxiy erzeugen, ohne unsere Sprache zu verlassen. Womit wir das Pumping-Lemma für kontextfreie Sprachen bewiesen hätten.
Beispiel
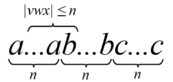 Das Wort vwx enthält höchstens zwei verschiedene Buchstaben.
Das Wort vwx enthält höchstens zwei verschiedene Buchstaben.Ist die Sprache
 kontextfrei?
kontextfrei?Wir nehmen an, L sei kontextfrei. Sei dann n die zugehörige Konstante aus dem Pumping-Lemma.
Wir betrachten das Wort z = anbncn. Es muss dann eine Zerlegung z = uvwxy geben, so dass
 ,
,  ,
,  für alle ist. Da , enthält das Wort vwx höchstens zwei verschiedene Buchstaben. Da , kann uv2wx2y nicht von allen drei Buchstaben gleich viele enthalten. Also kann L nicht kontextfrei sein.
für alle ist. Da , enthält das Wort vwx höchstens zwei verschiedene Buchstaben. Da , kann uv2wx2y nicht von allen drei Buchstaben gleich viele enthalten. Also kann L nicht kontextfrei sein.Quellen
- ↑ Jeffrey Jaffe: A necessary and sufficient pumping lemma for regular languages
Kategorien:- Theorie formaler Sprachen
- Compilerbau



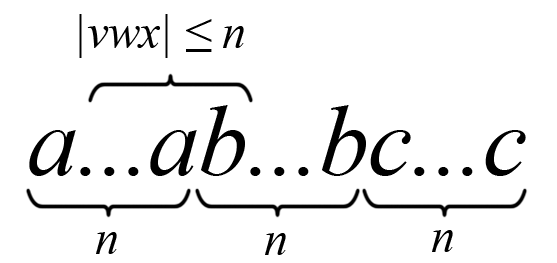
Wikimedia Foundation.