- Theta join
-
In der Theorie der Datenbanken versteht man unter einer Relationenalgebra oder einer Relationalen Algebra eine formale Sprache, mit der sich Anfragen über einem relationalen Schema formulieren lassen. Sie erlaubt es, Relationen miteinander zu verknüpfen oder zu reduzieren und komplexere Informationen daraus herzuleiten.
Es werden Operationen definiert, die sich auf einer Menge von Relationen anwenden lassen. Damit lassen sich bspw. Relationen verknüpfen, filtern oder umbenennen. Die Ergebnisse aller Operationen sind ebenfalls Relationen. Aus diesem Grund bezeichnet man die Relationenalgebra als abgeschlossen.
Ihre Bedeutung hat die Relationenalgebra als theoretische Grundlage für Anfragesprachen in relationalen Datenbanken. Hier werden die Operationen der Relationalen Algebra in so genannten Datenbankoperatoren implementiert. Wenn jeder Term der relationalen Algebra in der Anfragesprache umgesetzt werden kann, heißt sie relational vollständig. Wenn jeder Term durch genau einen Ausdruck der Anfragesprache umgesetzt werden kann, heißt sie streng relational vollständig. Im Gegensatz zu den Kalkülen ist die relationale Algebra sicher, d.h. sie liefert in endlicher Zeit ein endliches Resultat. Eine relationale Algebra ist darüber hinaus ein Beispiel für eine prozedurale Sprache; im Unterschied zu Kalkülen, die meist als deskriptive Sprachen formalisiert sind.
Die Erfindung der relationalen Algebra durch Edgar F. Codd hat in den 1970er Jahren die Datenbankwelt revolutioniert, deren Standarddatenmodelle damals das hierarchische Modell und das Netzwerkdatenbankmodell waren. Die Datenbanksprache SEQUEL, ein Vorläufer des heutigen SQL, war neben QBE und QUEL eine der ersten Umsetzungen der Ideen des relationalen Modells, und damit der relationalen Algebra.
Inhaltsverzeichnis
Operationen
Mengenoperationen
Um Mengenoperationen auf den Relationen R und S durchführen zu können, müssen beide miteinander kompatibel sein. Die Typkompatibilität zweier Relationen ist gegeben, wenn
- R und S den gleichen Grad (Tupelelementanzahl) haben
- der Wertebereich der Attribute von R und S identisch ist
Die Typkompatibilität wird auch Vereinigungsverträglichkeit genannt.
Vereinigung
Bei der Vereinigung R ∪ S werden alle Tupel der Relation R mit allen Tupeln der Relation S zu einer einzigen Relation vereint. Voraussetzung dafür ist, dass R und S das gleiche Relationenschema haben. Das heißt, sie haben gleiche Attribute und Attributtypen. Duplikate werden bei der Vereinigung gelöscht.
Definition
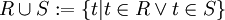
Beispiel
R: A B C 1 2 3 4 5 6 S: A B C 7 8 9 4 5 6 R ∪ S: A B C 7 8 9 4 5 6 1 2 3 Voraussetzung
- Vereinigungsverträglichkeit von R und S
Differenz
Bei der Operation R \ S werden aus der ersten Relation R alle Tupel entfernt, die auch in der zweiten Relation S vorhanden sind. Die Differenz (sowie die symmetrische Differenz) ist keine monotone Operation, daher ist auch die Relationale Algebra im Vergleich zu anderen deklarativen Anfragesprachen (z. B. Datalog) nicht monoton.
Definition
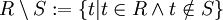
Beispiel
R: A B C 1 2 3 4 5 6 S: A B C 7 8 9 4 5 6 R \ S: A B C 1 2 3 Voraussetzung
- Vereinigungsverträglichkeit von R und S
Symmetrische Differenz
Bei der symmetrischen Differenz R △ S handelt es sich um die Menge aller Tupel, die entweder in R oder in S aber nicht in beiden gleichzeitig enthalten sind.
Definition
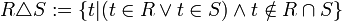
Die Operation kann aus den Grundoperationen abgeleitet werden:
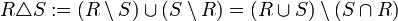
Beispiel
R: A B C 1 2 3 4 5 6 S: A B C 7 8 9 4 5 6 R △ S: A B C 1 2 3 7 8 9 Voraussetzung
- Vereinigungsverträglichkeit von R und S
Durchschnitt
Das Ergebnis der Durchschnittsoperation R ∩ S sind all die Tupel, die sich sowohl in R als auch in S finden lassen. Der Mengendurchschnitt lässt sich auch durch die Mengendifferenz ausdrücken: R ∩ S = R \ (R \ S)
Definition
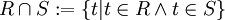
Beispiel
R: A B C 1 2 3 4 5 6 S: A B C 7 8 9 4 5 6 R ∩ S: A B C 4 5 6 Voraussetzung
- Vereinigungsverträglichkeit von R und S
Kartesisches Produkt (Kreuzprodukt)
Das Kartesische Produkt R × S ist eine Operation sehr ähnlich dem Kartesischen Produkt aus der Mengenlehre.
Das Resultat des Kartesischen Produkts ist die Menge aller Kombinationen der Tupel aus R und S, d.h. jede Zeile der einen Tabelle wird mit jeder Zeile der anderen Tabelle kombiniert. Wenn alle Merkmale (Spalten) verschieden sind, so umfasst die Resultatstabelle die Summe der Merkmale der Ausgangstabellen. Die Anzahl Tupel (Zeilen) im Resultat ist die Multiplikation der Anzahl Zeilen der Ausgangstabellen.
Definition
Zwei beliebige Relationen R = (a1,a2,...,an) und S = (b1,b2,...,bm) sind gegeben. Das kartesische Produkt ist definiert durch
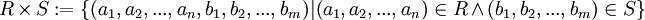
Beispiel
R: A B C D 1 2 3 4 4 5 6 7 7 8 9 0 S: E F G 1 2 3 7 8 9 R × S: A B C D E F G 1 2 3 4 1 2 3 4 5 6 7 1 2 3 7 8 9 0 1 2 3 1 2 3 4 7 8 9 4 5 6 7 7 8 9 7 8 9 0 7 8 9 Projektion
Die Projektion kann auch Attributbeschränkung genannt werden. Sie extrahiert einzelne Attribute aus der ursprünglichen Attributmenge und ist somit als eine Art Selektion auf Spaltenebene zu verstehen, das heißt, die Projektion blendet Spalten aus. Wenn β die Attributliste ist, schreibt man πβ(R) oder in der linearen Schreibweise R[β]. β heißt auch Projektionsliste. Duplikate in der Ergebnisrelation werden eliminiert.
Definition
Sei R eine Relation über {A1, …, Ak} und β ⊆ {A1, …, Ak}.
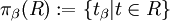
Die tβ := (β), das heißt, die Tupel erhalten nur die Attribute aus der Attributliste β.
Beispiel
R: A B C 1 2 3 4 5 6 1 3 8 R[A,B]: A B 1 2 4 5 1 3 R[A]: A 1 4 Voraussetzung
- Die angegebenen Spalten müssen in R enthalten sein.
Selektion (Restriktion)
Bei der Selektion kann man mit einem Vergleichsausdruck (Prädikat) festlegen, welche Tupel in die Ergebnismenge aufgenommen werden sollen. Es werden also Tupel („Zeilen“) ausgeblendet. Man schreibt σAusdruck(R) oder in der linearen Schreibweise R[Ausdruck]. Ausdruck heißt dann Selektionsbedingung.
Definition
Sei R eine Relation.
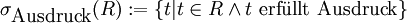
Ausdruck bezeichnet dabei eine Formel. Diese kann bestehen aus:
- Konstantenselektionen Attribut θ Konstante, wobei θ ein üblicher (passender) Vergleichsoperator ist.
- Attributselektionen Attribut θ Attribut
- Eine Verknüpfung einer Formel mit logischen Prädikaten ∧, ∨, ¬ (Klammerung wie üblich).
Beispiel
R: A B C 1 2 4 4 6 7 1 6 7 8 6 1 R[A=1]: A B C 1 2 4 1 6 7 R[C>6]: A B C 4 6 7 1 6 7
Voraussetzung- Jedes Element der angegebenen Spalte muss über den Bedingungsoperator mit dem Vergleichswert vergleichbar sein.
Join
Ein Join (zu deutsch Verbund) bezeichnet die beiden hintereinander ausgeführten Operationen kartesisches Produkt und Selektion. Die Selektionsbedingung ist dabei üblicherweise ein Vergleich von Attributen A θ B, wobei θ ein passender Vergleichsoperator ist. Man bezeichnet den allgemeinen Verbund daher auch als θ-Verbund („Theta-Verbund“). Ein Spezialfall des allgemeinen Verbundes ist der Equi Join (siehe unten).
Definition
Für zwei Relationen R(A1,...,An) und S(B1,...,Bn) ist das Ergebnis des allgemeinen Verbundes mit einer Formel Ausdruck als Selektionsbedingung
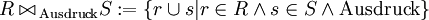
Die Ableitung ist:
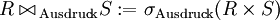
BeispielR: A B C D 1 2 3 4 4 5 6 7 7 8 9 0 S: E F G 1 2 3 7 8 9 R x S: A B C D E F G 1 2 3 4 1 2 3 4 5 6 7 1 2 3 7 8 9 0 1 2 3 1 2 3 4 7 8 9 4 5 6 7 7 8 9 7 8 9 0 7 8 9 JOIN(R, R.A <> S.E, S): A B C D E F G 4 5 6 7 1 2 3 7 8 9 0 1 2 3 1 2 3 4 7 8 9 4 5 6 7 7 8 9 Joinverfälschung
Sei
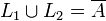 und
und 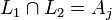 , dann gilt:
, dann gilt: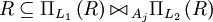
Beispiel
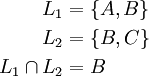
R: A B C 1 2 3 2 1 2 2 2 1 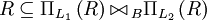 :
:A B C 1 2 3 1 2 1 2 1 2 2 2 3 2 2 1 Equi Join
Beim Equi-Join (auch Gleichverbund) wird als erstes das kartesische Produkt gebildet. Dann erfolgt die Selektion mit der Bedingung, dass der Inhalt bestimmter Spalten identisch sein muss. Der Equi-Join ist ein allgemeiner Verbund mit einer Formel der Form A = B.
Definition
Für die Relationen R, S und dazugehörige Attribute A (ist Attribut von R) und B (ist Attribut von S) ist der Equi-Join
![R \triangleright\!\!\triangleleft\,_{A=B} S:= \{ r \cup s | r \in R \land s \in S \land r_{[A]}=s_{[B]} \}](/pictures/dewiki/54/6ae5831d2134a1172cb5bfea19c3c06a.png)
Beispiel
Hier:
![R \triangleright\!\!\triangleleft\,_{A=E} S:= \{ r \cup s | r \in R \land s \in S \land r_{[A]}=s_{[E]} \}](/pictures/dewiki/48/0b5697e4c6b215c2ad33c9235e13dc92.png)
R: A B C D 1 2 3 4 4 5 6 7 7 8 9 0 S: E F G 1 2 3 7 8 9 R x S: A B C D E F G 1 2 3 4 1 2 3 4 5 6 7 1 2 3 7 8 9 0 1 2 3 1 2 3 4 7 8 9 4 5 6 7 7 8 9 7 8 9 0 7 8 9 JOIN(R, R.A = S.E, S): A B C D E F G 1 2 3 4 1 2 3 7 8 9 0 7 8 9 Natural Join
Der Natural Join setzt sich zusammen aus dem Equi-Join und einer zusätzlichen Ausblendung gleicher Spalten (Projektion). Der Join erfolgt über die Attribute (Spalten) die in beiden Relationen die gleiche Bezeichnung haben. Gibt es keine gemeinsamen Attribute, so ist das Ergebnis des natürlichen Verbundes das kartesische Produkt. Der natürliche Verbund ist kommutativ und assoziativ, das heißt, es gilt
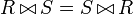 sowie
sowie 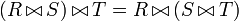 , was eine Rolle bei der Optimierung von Anfragen spielt.
, was eine Rolle bei der Optimierung von Anfragen spielt.Definition
Für zwei Relationen R(A1,...,An,B1,...,Bn) und S(B1,...,Bn,C1,...,Cn) ist das Ergebnis des natürlichen Verbundes
![R \triangleright\!\!\triangleleft\, S:= \{ r \cup s_{[C_1, ..., C_n]} | r \in R \land s \in S \land r_{[B_1, ..., B_n]} =s_{[B_1, ..., B_n]} \}](/pictures/dewiki/53/5dddaced1c846b0fc0ccc7a40183b5e5.png)
Beispiel
R: A B C D 1 2 3 4 4 5 6 7 7 8 9 0 S: A F G 1 2 3 7 8 9 NATURAL JOIN (R, S): A B C D F G 1 2 3 4 2 3 7 8 9 0 8 9 Semi Join
Der Semi Join berechnet den Anteil eines Natural Joins, welcher nach einer Reduktion auf die linke Relation übrig bleibt.
Definition
Für zwei Relationen R(A1,...,An,B1,...,Bn) und S(B1,...,Bn,C1,...,Cn) ist das Ergebnis des natürlichen Verbundes
![R \ \triangleright\!\!\!&lt; S:= \{ r | r \in R \land s \in S \land r_{[B_1, ..., B_n]} =s_{[B_1, ..., B_n]} \}](/pictures/dewiki/54/6394ea76d327ff2b3fe87ce4b3b47d69.png)
Beispiel
R: A B C D 1 2 3 4 4 5 6 7 7 8 9 0 S: A F G 1 2 3 7 8 9 SEMIJOIN (R, R.A = S.A, S): A B C D 1 2 3 4 7 8 9 0 Outer Join
Im Gegensatz zum Equi-Join werden beim Outer-Join auch die Tupel der linken (left outer join) bzw. der rechten (right outer join) Tabelle in die Ergebnisrelation mit aufgenommen, die keinen Join-Partner finden. Die nicht vorhandenen Attribute der Join-Relation werden mit Nullwerten aufgefüllt. Die Kombination aus Left- und Right-Outer-Join wird Outer-Join oder Full-Outer-Join genannt. Dabei werden alle Tupel in die Ergebnisrelation aufgenommen und jene Attribute eines Tupels mit Nullwerten aufgefüllt, die keinen Join-Partner in der jeweils anderen Relation gefunden haben.
Der Outer-Join kann mit oder ohne (natural outer join) Join-Bedingung verwendet werden.
Beispiel
R: A B C D 1 2 3 4 4 5 6 7 7 8 9 0 S: A F G 1 2 3 7 8 9 LEFT OUTER JOIN (R, R.A = S.A, S): A B C D F G 1 2 3 4 2 3 4 5 6 7 NULL NULL 7 8 9 0 8 9 Umbenennung
Durch diese Operation können Attribute und Relationen umbenannt werden. Diese Operation ist wichtig,
- um Joins von unterschiedlichen benannten Relationen zu ermöglichen,
- kartesische Produkte zu ermöglichen, wo es gleiche Attributnamen gibt, insbesondere auch mit der gleichen Relation, und
- Mengenoperationen zwischen Relationen mit unterschiedlichen Attributen zu ermöglichen.
Die Schreibweise ist
![\rho_{[\mathrm{neu}\leftarrow\mathrm{alt}]} (R)](/pictures/dewiki/55/776ea0c8ccbee157b8f20b4093644c67.png) , linear R[alt→neu].
, linear R[alt→neu].Definition
Wir konstruieren eine neue Tupelmenge t' aus der alten:
![\rho_{[\mathrm{neu}\leftarrow\mathrm{alt}]}(R):= \{t'|t'(R-\mathrm{neu})=t(R-\mathrm{neu}) \land t'(\mathrm{neu})=t(\mathrm{alt})\}](/pictures/dewiki/51/381245293efddde27de2efc1dadbdf63.png)
Beispiel
R: A B C 1 2 3 4 5 6 R[X←B]: A X C 1 2 3 4 5 6 Division
Definition
Da die Division eine abgeleitete Operation ist, definieren wir sie mit Hilfe der anderen Operationen der Relationenalgebra. Seien R, S Relationen und β die zu R sowie γ die zu S dazugehörigen Attributmengen.
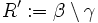 .
.Die Division ist dann definiert durch:
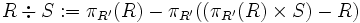
BeispielGegeben ist eine Relation R, die Väter und Mütter, deren Kinder und das Alter dieser Kinder enthält. Zusätzlich dazu ist eine Relation S gegeben, die einige Kinder und deren Alter enthält: Maria (4) und Sabine (2). Dividiert man R durch S, so erhält man als Ergebnis eine Relation, die nur noch diejenigen Ehepaare enthält, die sowohl eine Tochter Maria mit Alter 4 als auch eine Tochter Sabine mit Alter 2 haben:
R: Vater Mutter Kind Alter Franz Helga Harald 5 Franz Helga Maria 4 Franz Ursula Sabine 2 Martin Melanie Gertrud 7 Martin Melanie Maria 4 Martin Melanie Sabine 2 Peter Christina Robert 9 S: Kind Alter Maria 4 Sabine 2 R÷S Vater Mutter Martin Melanie Minimalität und Vollständigkeit
Eine minimale Menge von Operationen, das heißt, eine Menge von Operationen, die mindestens notwendig ist, um alle Ausdrücke der relationalen Algebra bilden zu können, umfasst
- Projektion
- Selektion
- Kreuzprodukt
- Vereinigung
- Differenz
- Umbenennung
Alle anderen Operationen (zum Beispiel Joins) lassen sich durch diese Grundoperationen nachbilden.
Jede andere Menge von Operationen ist relational vollständig, wenn sie die gleiche Mächtigkeit wie die oben genannten Operationen haben.
Erweiterungen der relationalen Algebra
Um andere Abfragesprachen, speziell SQL, vollständig in die relationale Algebra abbilden zu können, ist die relationale Algebra nicht mächtig genug. Es gibt z. B. keine Möglichkeit, die SQL-Operatoren
GROUP BY/HAVING, Aggregatfunktionen und Nullwerte in die relationale Algebra zu übersetzen. Wir betrachten hier einige Erweiterungen (die teilweise ähnliches bewirken), die eine vollständige Abbildung in die relationale Algebra, und damit eine vollständige theoretische Betrachtung dieser Abfragesprachen, ermöglichen.Nullwerte
SQL ermöglicht die Verwendung von NULL-Werten, die mit dem speziellen Prädikat
IS NULLabgefragt werden können. Dies ist insbesondere wichtig bei der Bildung von äußeren Verbunden, die eine Relation erzeugen, die alle Werte der einen Relation enthalten, sowie alle Werte der anderen, für die die Verbundbedingung wahr ist, sonst eben NULL-Werte. Dies kann mit der relationalen Algebra so nicht abgebildet werden.Eine Möglichkeit ist die Definition von Nullwerten wie in SQL mit einer dreiwertigen Logik, das heißt, die booleschen Operatoren werden mittels Wahrheitstabellen so erweitert, dass festgelegt ist, wie zu verfahren ist, wenn ein Operand NULL ist.
Erweiterte Wahrheitstabelle für AND ∧ true false NULL true true false NULL false false false false NULL NULL false NULL Selektionsbedingungen oder Verbunde, die auf Nullwerte angewendet werden, ergeben NULL. Eine Schwierigkeit damit (d.h. mit der SQL-artigen Behandlung von Nullwerten) besteht darin, dass die Ergebnisse von Abfragen mit Unterabfragen, die NULL ergeben, nicht notwendigerweise der Intention des Benutzers entsprechen. Diese Art der Nullwertbehandlung ist auch nicht orthogonal, d. h. das Verhalten auf der einen Ebene (boolesche Operatoren, 3-wertige Logik) entspricht nicht dem auf einer anderen (Verbunde, 3-wertige Logik wird auf 2-wertige abgebildet).
Eine andere Möglichkeit ist die Unterscheidung zweier verschiedener Arten von Nullwerten, die jeweils „beliebig“ oder „nicht definiert“ bedeuten.
Gruppierungsoperator und Aggregatfunktionen
Die Gruppierung wendet Funktionen auf gleiche Attribute in einer Relation an. Der Operator γ erhält eine Liste von Funktionen und eine Attributliste. Die Funktionen werden dann auf Tupel angewendet für die die Attribute der Attributliste gleich sind. Die Ausgabe ist eine neue Relation bestehend aus der Attributliste und einem neuen Attribut, das die Ergebnisse der Funktionsliste enthält.
Die Funktionen sind dann die üblichen Aggregatfunktionen
count, sum, max, avg ….Definition
Seien R eine Relation und A = {A1, …, An} Attribute aus R. F(X) sei eine Funktionsliste f1(x1), …, fn(xn). Die Gruppierung ist dann
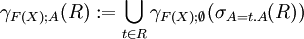
Für eine leere Attributmenge (also γF(X);{}(…)) wird ein zusätzliches Attribut erzeugt, das den Wert der Funktionsanwendung über die gesamte Relation enthält. Dies wird ausgenutzt, um die Relation mit der Selektion in Teilrelationen mit gleichen Attributen zu zerlegen, die dann mit der Funktionsanwendung wieder zusammengesetzt werden.
Weiter gilt, dass eine Gruppierung mit einer leeren Funktionsliste keinen Effekt hat.
NF²
Eine Erweiterung des relationalen Datenbankmodells ist das NF²-Modell. Der Name steht für Non-first-normal-form (NFNF), was andeuten soll, dass die Bedingung atomarer Attributwerte der 1. Normalform aufgebrochen wird. Folglich werden Mengen von Attributen und Mengen von Mengen erlaubt, was dazu führt, dass ein Attribut einer Relation wieder eine Relation sein kann. Die Domäne (Wertebereich) eines kombinierten Attributs ist das Kreuzprodukt der beteiligten Attributdomänen.
NF² erweitert die relationale Algebra dahingehend, dass neben den üblichen (entsprechend angepassten) Operationen der relationalen Algebra zwei Operationen hinzu genommen werden, die eine Relation schachteln (Nestung ν) und entschachteln (Entnestung μ). Die Nestung fasst eine Menge von Attributen in eine Unterrelation zusammen, die einen neuen Attributnamen erhält. Die Entnestung hebt Schachtelungen auf. Diese Operationen dienen dazu NF² Relationen in die 1. Normalform zu transformieren und umgekehrt. Die Operationen sind im Allgemeinen nicht bijektiv.
NF² benötigt aus obigen Gründen keine Fremdschlüssel.
Multimengensemantik
SQL liefert als Ergebnis von Anfragen eine Multimenge zurück, also eine Menge, die Elemente mehrfach enthalten kann. Dies wurde aus Performance-Gründen so gehandhabt, um den zusätzlichen Schritt der Duplikatentfernung zu sparen. Es können also streng genommen nur Anfragen in die relationale Algebra übersetzt werden, die mit
DISTINCTangegeben sind.Für die relationale Algebra kann man dann zusätzlich eine Funktion bag-to-set spezifizieren, die die Duplikate aus einer Multimenge entfernt und somit eine Menge erzeugt, und die Basisoperationen dann einfach als Multimenge { { t | …} } spezifizieren. Vorsicht muss man aber bei der Definition abgeleiteter Operationen walten lassen.
Beispiele
Als Relationenschemata für die Beispiele nehmen wir die klassische Beispieldatenbank bestehend aus den Schemata Kunde, Lieferant und Ware. Die Schemata seien:
- KUNDE(Kundennr, Name, Wohnort, Kontostand)
- LIEFERANT(Lieferantennr, Name, Ort, Telefon)
- WARE(Warennr, Bezeichnung, Lieferantennr, Preis)
Grundoperationen der relationalen Algebra werden dann so benutzt:
- Die Preise aller Waren:
- πBezeichnung, Preis(WARE)
- Alle Lieferanten aus Bremen:
- σOrt='Bremen'(LIEFERANT)
- Kunden mit negativem Kontostand:
- σKontostand<0(KUNDE)
- Ort von LIEFERANT umbenennen (zum Beispiel um Mengenoperationen durchführen zu können):
- βOrt→Wohnort(LIEFERANT)
Da die Ergebnisse der relationalen Algebra wieder Relationen sind (die RA ist orthogonal), können die Operationen wieder auf die Ergebnisse von Operationen angewendet werden. Dies erlaubt komplexe Abfragen. Für eine einfachere Schreibweise nehmen wir an, dass das Kreuzprodukt eine implizite Umbenennung der Attribute vornimmt, so dass die neuen Attributnamen mit dem Relationennamen qualifiziert sind, d.h. aus Lieferantennr aus der Relation WARE wird WARE.Lieferantennr:
- Die Telefonnummern aller Lieferanten, die Gemüse in Bremen liefern:
- πTelefon(σBezeichnung='Gemüse' ∧ Ort='Bremen' ∧ LIEFERANT.Lieferantennr=WARE.Lieferantennr(LIEFERANT × WARE))
- Alle Orte, die wenigstens einen Lieferanten und wenigstens einen Kunden enthalten
- πOrt(βWohnort→Ort(KUNDE)) ∩ πOrt(LIEFERANT)
Siehe auch
Literatur
- Edgar F. Codd: A Relational Model of Data for Large Shared Data Banks. In: Communications of the ACM. 6/13/1970, S. 377–387. (Die fundamentale Arbeit, mit der Codd 1970 erstmals das relationale Datenmodell vorstellte. Kostenfrei online verfügbar unter: ACM Classics oder als PDF-Datei: FHTW Berlin - Peter Morcinek; Größe: ca. 1,4 MB)
- Alfons Kemper, André Eickler: Datenbanksysteme – Eine Einführung. ISBN 3-486-57690-9
- Peter Kandzia und Hans-Joachim Klein: Theoretische Grundlagen relationaler Datenbanksysteme. ISBN 3-411-14891-8
- Andreas Heuer, Gunter Saake: Datenbanken: Konzepte und Sprachen. MITP Verlag, ISBN 3-8266-0619-1, S. 297 ff.
- H. Buff Datenbanktheorie BoD GmbH Norderstedt, ISBN 3-0344-0201-5, 312 Seiten
- H.-J. Schek, P. Pistor: Data Structures for an Integrated Data Base Management and Information Retrieval System (Non First Normal Form NF²), Proceedings fo the 8th International Conference on Very Large Data Bases
- Dirk Leinders, Jerzy Tyskiewicz, Jan Van den Bussche On the expressive power of semijoin queries : [1]
Weblinks
Wikimedia Foundation.