- Normalisierung (Datenbank)
-
Die Normalisierung eines relationalen Datenschemas überführt es in eine Form, die keine vermeidbaren Redundanzen mehr enthält.
Ein konzeptionelles Schema, das Datenredundanzen enthält, kann dazu führen, dass bei Änderungen der damit realisierten Datenbank die mehrfach enthaltenen Daten nicht konsistent, sondern nur teilweise und unvollständig geändert werden, womit sie obsolet oder widersprüchlich werden können. Man sagt auch, dass Anomalien auftreten können. Zudem belegt mehrfache Speicherung derselben Daten unnötig Speicherplatz. Aus diesen Gründen wird versucht, solche Redundanzen durch Normalisierung zu vermeiden.
Es gibt verschiedene Ausmaße, in denen ein Datenbankschema gegen Anomalien gefeit sein kann. Je nachdem spricht man davon, dass es in erster, zweiter, dritter usw. Normalform vorliege. Diese Normalformen sind durch bestimmte formale Anforderungen an das Schema definiert.
Man bringt ein Datenbankschema in eine Normalform, indem man fortschreitend anhand für sie geltender funktionaler Abhängigkeiten seine Relationen in einfachere zerlegt, bis keine weitere Zerlegung mehr möglich ist. Dabei dürfen jedoch auf keinen Fall Daten verloren gehen. Mit dem Satz von Delobel kann man für einen Zerlegungsschritt förmlich nachweisen, dass er keine Datenverluste mit sich bringt.
Normalisiert wird vor allem in der Phase des Entwurfs einer relationalen Datenbank. Für die Normalisierung gibt es Algorithmen (Synthesealgorithmus (3NF), Zerlegungsalgorithmus (BCNF) usw.), die automatisiert werden können.
Die Zerlegungsmethodik folgt der relationalen Entwurfstheorie.
Inhaltsverzeichnis
Vorgehen
Ziel: Konsistenzerhöhung durch Redundanzvermeidung
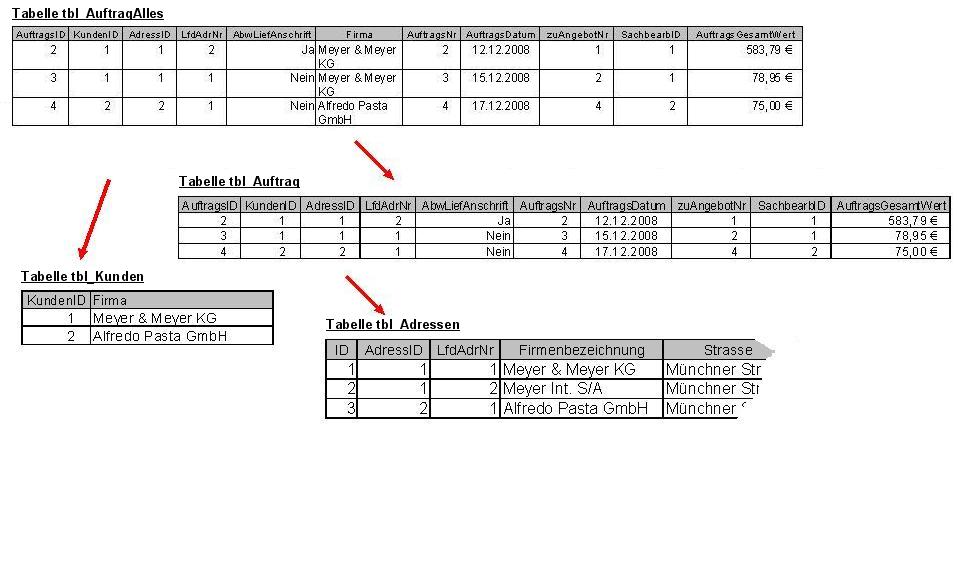
 Aufspaltung der Tabelle TBL_AdressenAlles
Aufspaltung der Tabelle TBL_AdressenAlles
Bei der Normalisierung werden zunächst Spalten (synonyme Begriffe: Felder, Attribute) von Tabellen innerhalb der Datenschemas in neue Spalten aufgeteilt, z. B. Adressen in Postleitzahl, Ort und Strasse. Zweitens werden Tabellen aufgeteilt, zum Beispiel eine Tabelle
tbl_AdressenAlles mit den Feldern Firma, Strasse, PLZ und Ort in diese Tabellen:- tbl_Adressen mit den Feldern AdressID, Firma, Strasse und PLZ und eine Tabelle
- tbl_PLZOrt mit den Feldern PLZ und Ort
Siehe Bild Aufspaltung der Tabelle tbl_AdressenAlles – wobei die Tabelle tbl_Adressen noch den eindeutigen Primärschlüssel AdressID erhält. In diesem Beispiel wird angenommen, dass es zu jeder Postleitzahl nur jeweils einen Ortsnamen gibt, was in Deutschland jedoch nicht immer zutrifft.
Die Normalisierung hat den Zweck, Redundanzen (mehrfaches Festhalten des gleichen Sachverhalts) zu verringern und dadurch verursachte Anomalien (infolge Änderung an nicht allen Stellen) zu verhindern, um so die Aktualisierung einer Datenbank zu vereinfachen (wegen Änderung an lediglich einer Stelle) sowie die Konsistenz der Daten zu gewährleisten.
Beispiel
Deutlich wird dies an einem einfachen Beispiel: Eine Datenbank enthält Kunden und deren Adressen sowie Aufträge, die den Kunden zugeordnet sind. Da es mehrere Aufträge vom selben Kunden geben kann, würde eine Erfassung der Kundendaten (womöglich mit Adressdaten) in der Auftragstabelle dazu führen, dass sie dort mehrfach vorkommen, obwohl der Kunde immer nur einen Satz gültiger Daten hat (Redundanz). Beispielsweise kann es dazu kommen, dass in einem Auftrag fehlerhafte Adressdaten zum Kunden eingegeben werden, im nächsten Auftrag werden die korrekten Daten erfasst. So kann es – in dieser Tabelle oder auch gegenüber anderen Tabellen – zu widersprüchlichen Daten kommen. Die Daten wären dann nicht konsistent, man wüsste nicht, welche Daten korrekt sind. Womöglich sind sogar beide Adressen unkorrekt, weil der Kunde umgezogen ist (Lösung siehe unten).
Bei einer normalisierten Datenbank gibt es für die Kundendaten nur einen einzigen Eintrag in der Kundentabelle, mit der jeder Auftrag dieses Kunden verknüpft wird (üblicherweise über die Kundennummer). Im Falle des Umzugs eines Kunden (ein anderes Beispiel ist die Änderung der Mehrwertsteuer) gäbe es zwar mehrere Einträge in der entsprechenden Tabelle, die aber zusätzlich durch die Angabe eines Gültigkeitszeitraums unterscheidbar sind und im obigen Kundenbeispiel über die Kombination Auftragsdatum/Kundennummer eindeutig angesprochen werden können.
Ein weiterer Vorteil von Redundanzfreiheit, der bei Millionen Datensätzen einer Datenbank auch heute noch eine wichtige Rolle spielt, ist der geringere Speicherbedarf, wenn der Datensatz einer Tabelle zum Beispiel tbl_Auftrag auf einen Datensatz einer anderen Tabelle z. B. tbl_Kunde verweist, anstatt diese Daten selbst zu enthalten.
 Aufspaltung von Tabellen zur Normalisierung
Aufspaltung von Tabellen zur NormalisierungDieses sind die Empfehlungen, die ausgehend von der Theorie der Normalisierung bei der Datenbankentwicklung gegeben werden, um vor allem Konsistenz der Daten und eine eindeutige Selektion von Daten zu gewährleisten. Die hierzu angestrebte Redundanzfreiheit steht allerdings in speziellen Anwendungsfällen in Konkurrenz zur Performance oder/und zu anderen Zielen. Es kann daher sinnvoll sein, auf eine Normalisierung zu verzichten oder diese durch eine Denormalisierung rückgängig zu machen, um
- die Performance (Verarbeitungsgeschwindigkeit) zu erhöhen oder
- Anfragen zu vereinfachen und damit die Fehleranfälligkeit zu verringern oder
- Besonderheiten von Prozessen (zum Beispiel Geschäftsprozessen) abzubilden.
In diesen Fällen sollten regelmäßig automatische Abgleichroutinen implementiert werden, um Inkonsistenzen zu vermeiden. Alternativ kann man die betreffenden Daten auch für Änderungen sperren.
Normalformen
Zurzeit gebräuchliche Normalformen sind:
- 1. Normalform (1NF)
- 2. Normalform (2NF)
- 3. Normalform (3NF)
- Boyce-Codd-Normalform (BCNF)
- 4. Normalform (4NF)
- 5. Normalform (5NF)
Zum einen dienen sie der Beurteilung der Qualität eines betrachteten Datenbankschemas, zum anderen helfen sie, Fehler beim Erzeugen neuer Schemata zu vermeiden.
Außerdem können mit Hilfe der Normalisierung Datenstrukturen aus nichtrelationalen Quellen gewonnen werden, die im Sinne des Normalisierungskonzepts formal korrekt sind und die Daten aus ihren jeweiligen nichtrelationalen Quellen, aus denen sie entstanden sind (zum Beispiel Formulardaten oder Spreadsheets), aufnehmen können.
Nachfolgend werden die Kriterien der jeweiligen Normalformen erklärt. Dabei ist zu beachten, dass jede Normalform die Kriterien der „vorherigen“ Normalformen mit einschließt.
Erste Normalform (1NF)
Jedes Attribut der Relation muss einen atomaren Wertebereich haben. (Anm.: statt „atomar“ wird auch die Bezeichnung „atomisch“ verwendet.[1])
Das heißt, zusammengesetzte, mengenwertige oder geschachtelte Wertebereiche (relationenwertige Attributwertebereiche) sind nicht erlaubt. Damit sind auch Wiederholungsgruppen nicht zugelassen. Kurz: Kein Attributwertebereich kann in weitere (sinnvolle) Teilbereiche aufgespalten werden (Beispiel: Die Adresse darf nicht als Attribut verwendet werden, sondern muss – sofern es der zugrunde liegende Prozess erfordert – in PLZ, Ort, Straße und Hausnummer aufgeteilt werden).
Dass die Relation frei von Wiederholungsgruppen sein muss, bedeutet, dass Attribute, die gleiche oder gleichartige Information enthalten, in eine andere Relation ausgelagert werden müssen.
Ein Beispiel für eine Wiederholungsgruppe wäre eine Spalte Telefon, die mehrere Telefonnummern enthält. Wichtig ist anzumerken, dass zum Beispiel die Attribute {Telefon1, Telefon2, Telefon3} nicht notwendigerweise immer eine Wiederholungsgruppe bilden. Ob das der Fall ist, und man diese Attribute daher auslagert, ist eine Frage der Anforderungen an die Anwendung (siehe Alternative Formulierungen).
Praktischer Nutzen
Abfragen der Datenbank werden durch die 1NF erleichtert bzw. überhaupt erst ermöglicht, da die Attributwertebereiche atomar sind. So ist es beispielsweise in einem Feld, das einen ganzen Namensstring aus Titel, Vorname und Zuname enthält, schwierig bis unmöglich, nach Zunamen zu sortieren.Alternative Formulierungen
Alle Attribute enthalten atomare Inhalte, und die Relation hat eine feste Breite. Diese Formulierung bezieht sich darauf, dass niemals weitere Attribute in die Relation aufgenommen werden müssen, weil die Wiederholungszahl der Wiederholungsgruppe zu klein wird (z. B.: es wird bei drei Attributen Telefon1-3 eine 4. Telefonnummer für eine Person bekannt). Sie ist insofern interessant, als sie helfen kann zu entscheiden, ob tatsächlich eine Wiederholungsgruppe vorliegt: Obwohl z. B. { .., Telefon1, Telefon2, Telefon3,.. } sehr stark das Vorhandensein einer Wiederholungsgruppe impliziert, könnte es bei lediglich anderen Attributnamen klar werden, dass – freilich unter dem Licht der Anwendung – dem nicht so sein muss: { .., Telefon, Fax, Mobil,.. }Eine weitere Variante entsteht durch folgenden Zusatz: .. und die Relation einen Primärschlüssel hat. Obwohl diese Formulierung so nicht bei Codd nachgelesen werden kann, handelt es sich um eine Erweiterung, die zu ausgesprochen praxistauglichen Datenstrukturen führt.
Beispiel
CD_Lied CD_ID Album Jahr der Gründung Titelliste 4711 Anastacia - Not That Kind 1999 {1. Not That Kind, 2. I'm Outta Love, 3. Cowboys & Kisses} 4712 Pink Floyd - Wish You Were Here 1964 {1. Shine On You Crazy Diamond} 4713 Anastacia - Freak of Nature 1999 {1. Paid my Dues} Verletzung der 1NF
- Das Feld Album beinhaltet die Attributwertebereiche Interpret und Albumtitel.
- Das Feld Titelliste enthält eine Menge von Titeln.
Dadurch hat man ohne Aufspaltung folgende Probleme bei Abfragen:
- Zur Sortierung nach Albumtitel muss das Feld Album in Interpret und Albumtitel aufgeteilt werden.
- Die Titel können (mit einfachen Mitteln) nur alle gleichzeitig als Titelliste oder gar nicht dargestellt werden.
Lösung
CD_Lied CD_ID Albumtitel Interpret Jahr der Gründung Track Titel 4711 Not That Kind Anastacia 1999 1 Not That Kind 4711 Not That Kind Anastacia 1999 2 I'm Outta Love 4711 Not That Kind Anastacia 1999 3 Cowboys & Kisses 4712 Wish You Were Here Pink Floyd 1964 1 Shine On You Crazy Diamond 4713 Freak of Nature Anastacia 1999 1 Paid my Dues Die Attributwertebereiche werden in atomare Attributwertebereiche aufgespalten:
- Das Feld Album wird in die Felder Albumtitel und Interpret gespalten.
- Das Feld Titelliste wird in die Felder Track und Titel gespalten sowie auf mehrere Datensätze aufgeteilt.
Da jetzt jeder Attributwertebereich atomar ist sowie die Tabelle einen eindeutigen Primärschlüssel (Verbundschlüssel aus den Spalten CD_ID und Track) besitzt, befindet sich die Relation in 1NF.
Zweite Normalform (2NF)
Eine Relation ist in der zweiten Normalform, wenn die erste Normalform vorliegt und kein Nichtschlüsselattribut voll funktional abhängig von einer echten Teilmenge eines Schlüsselkandidaten ist.
Anders gesagt: Jedes nicht-primäre Attribut (nicht Teil eines Schlüssels) ist jeweils von allen ganzen Schlüsseln abhängig, nicht nur von einem Teil eines Schlüssels. Wichtig ist hierbei, dass die Nichtschlüsselattribute wirklich von allen Schlüsseln vollständig abhängen.
Somit gilt, dass Relationen, die keinen zusammengesetzten Primärschlüssel sondern lediglich ein einzelnes Attribut als Primärschlüssel haben, automatisch die 2NF erfüllen!
In einer Relation R(A,B) ist das Attribut B von dem Attribut A funktional abhängig, falls zu jedem Wert des Attributs A genau ein Wert des Attributs B gehört. In einer Relation R(S1,S2,B) ist das Attribut B von den Schlüsselattributen S1 und S2 voll funktional abhängig, wenn B von den zusammengesetzten Attributen (S1,S2) funktional abhängig ist, nicht aber von einem einzelnen Attribut S1 oder S2.
Diese informelle Definition kann wie folgt präzisiert werden:
Eine Relation ist genau dann in zweiter Normalform, wenn sie
- in der ersten Normalform ist und
- für jedes Attribut a der Relation gilt:
- a ist Teil eines Schlüsselkandidaten oder
- a ist nicht von einer echten Teilmenge eines Schlüsselkandidaten abhängig.
a ist voll funktional abhängig von jedem Schlüsselkandidaten (wobei die Schlüsselkandidaten KC auch durch die Kombination mehrerer Attribute gebildet werden können). Die 2NF eliminiert alle partiellen funktionalen Abhängigkeiten, d. h. funktionale Abhängigkeiten von Teilen des Schlüsselkandidaten.
Falls ein Schlüsselkandidat zwei Attribute besitzt, können bei der Zerlegung in die 2NF höchstens drei Relationen entstehen. Falls ein Schlüsselkandidat drei Attribute besitzt, können bei der Zerlegung in die 2NF höchstens sieben Relationen entstehen. Das sind jeweils die Anzahl der Teilmengen einer gegebenen Menge minus 1 (leere Menge) und entspricht der Anzahl der Elemente der Potenzmenge ( 2n ) als Obergrenze.
Praktischer Nutzen
Die 2NF erzwingt wesentlich „monothematische“ Relationen im Schema: jede Relation modelliert nur einen Sachverhalt.Dadurch werden Redundanz und die damit einhergehende Gefahr von Inkonsistenzen reduziert. Nur noch logisch/sachlich zusammengehörige Informationen finden sich in einer Relation. Dadurch fällt das Verständnis der Datenstrukturen leichter.
Beispiel
CD_Lied CD_ID Albumtitel Interpret Jahr der Gründung Track Titel 4711 Not That Kind Anastacia 1999 1 Not That Kind 4711 Not That Kind Anastacia 1999 2 I'm Outta Love 4711 Not That Kind Anastacia 1999 3 Cowboys & Kisses 4712 Wish You Were Here Pink Floyd 1964 1 Shine On You Crazy Diamond 4713 Freak of Nature Anastacia 1999 1 Paid my Dues Verletzung der 2NF
- Der Primärschlüssel der Relation ist aus den Feldern CD_ID und Track zusammengesetzt. (Grundsätzlich darf ein Primärschlüssel aus mehreren Attributen bestehen, jedoch entsteht daraus im genannten Beispiel ein Konflikt.)
- Die Felder Albumtitel, Interpret und Jahr der Gründung sind vom Feld CD_ID abhängig, aber nicht vom Feld Track. Dies (Punkt 2) verletzt die 2. Normalform, da die drei nicht-primären Attribute nicht nur von einem Teil des Schlüssels (hier CD_ID) abhängen dürfen. Wäre Punkt 1 nicht erfüllt, so könnte dies nicht passieren.
Probleme, die sich daraus ergeben:
Die Informationen aus diesen beiden Feldern sind, wie am Beispiel der CD Not That Kind zu erkennen, mehrfach vorhanden, d. h. redundant. Dadurch besteht die Gefahr, dass die Integrität der Daten verletzt wird. So könnte man den Albumtitel für das Lied Not That Kind in I Don’t Mind ändern, ohne jedoch die entsprechenden Einträge für die Titel I'm Outta Love und Cowboys & Kisses zu ändern (Update-Anomalie).CD_Lied (inkonsistent) CD_ID Albumtitel Interpret Jahr der Gründung Track Titel 4711 I Don’t Mind Anastacia 1999 1 Not That Kind 4711 Not That Kind Anastacia 1999 2 I'm Outta Love 4711 Not That Kind Anastacia 1999 3 Cowboys & Kisses 4712 Wish You Were Here Pink Floyd 1964 1 Shine On You Crazy Diamond 4713 Freak of Nature Anastacia 1999 1 Paid my Dues In diesem Fall ist ein Zustand erreicht, den man als Dateninkonsistenz bezeichnet. Über die komplette Tabelle betrachtet, „passen“ die Daten nicht mehr zusammen.
Lösung
Die Daten in der Tabelle werden in zwei Tabellen aufgeteilt: CD und Lied. Die Tabelle CD enthält nur noch Felder, die voll funktional von CD_ID abhängen, hat also CD_ID als Primärschlüssel. Auch der Albumtitel allein sei eindeutig, also ein Schlüsselkandidat. Da keine weiteren (zusammengesetzten) Schlüsselkandidaten existieren, liegt die Tabelle damit automatisch in der 2. Normalform vor. Die Tabelle Lied enthält schließlich nur noch Felder, die voll funktional von CD_ID und Track abhängen, liegt also auch in der 2. Normalform vor. Mit Hilfe dieser verlustfreien Zerlegung sind auch die genannten Redundanzen der Daten beseitigt.
CD CD_ID Albumtitel Interpret Jahr der Gründung 4711 Not That Kind Anastacia 1999 4712 Wish You Were Here Pink Floyd 1964 4713 Freak of Nature Anastacia 1999 Lied CD_ID Track Titel 4711 1 Not That Kind 4711 2 I'm Outta Love 4711 3 Cowboys & Kisses 4712 1 Shine On You Crazy Diamond 4713 1 Paid my Dues Das Attribut CD_ID aus der Tabelle Lied bezeichnet man als Fremdschlüssel, der auf den Primärschlüssel der Tabelle CD verweist. Zugleich stellen die Attribute CD_ID und Track den zusammengesetzten Primärschlüssel der Tabelle Lied dar.
Dritte Normalform (3NF)
Die dritte Normalform ist erreicht, wenn sich das Relationenschema in 2NF befindet, und kein Nichtschlüsselattribut (hellgraue Zellen in der Tabelle) von einem Schlüsselkandidaten transitiv abhängt.
Ein Attribut A ist vom Schlüsselkandidaten P transitiv abhängig, wenn es ein Attribut B gibt, sodass
 und
und  .
.Hierbei handelt es sich um eine Abhängigkeit, bei der ein Attribut A2 über ein anderes Attribut A1 von einem Schlüsselkandidaten P1 der Relation abhängig ist (ohne dass zugleich auch P1 direkt von A1 abhängig, also A1 ein Schlüsselkandidat ist). Das heißt: Wenn Attribut A1 von der Attributmenge P1 (dem Primärschlüssel) abhängt und Attribut A2 von A1, dann ist A2 transitiv abhängig von P1. Formal ausgedrückt:
 .
.Einfach gesagt: Ein Nichtschlüsselattribut darf nicht von einer Menge aus Nichtschlüsselattributen abhängig sein. Ein Nichtschlüsselattribut darf also nur direkt von einem Primärschlüssel abhängig sein.
Siehe auch: Transitivität (Mathematik), Synthesealgorithmus-Normalform
Praktischer Nutzen
Transitive Abhängigkeiten sind sofort ersichtlich, ohne dass man die Zusammenhänge der Daten kennen muss. Sie sind durch die Struktur der Relationen wiedergegeben.Außerdem werden verbliebene thematische Durchmischungen in der Relation behoben: nach der 3NF sind die Relationen des Schemas zuverlässig monothematisch.
Beispiel
CD CD_ID Albumtitel Interpret Jahr der Gründung 4711 Not That Kind Anastacia 1999 4713 Freak of Nature Anastacia 1999 4712 Wish You Were Here Pink Floyd 1964 Verletzung der 3NF
Offensichtlich lässt sich der Interpret einer CD aus der CD_ID bestimmen, das Gründungsjahr der Band hängt wiederum vom Interpreten und damit transitiv von der CD_ID ab.
Das Problem ist hierbei wieder Datenredundanz. Wird zum Beispiel eine neue CD mit einem existierenden Interpreten eingeführt, so wird das Gründungsjahr redundant gespeichert.
Lösung
CD CD_ID Albumtitel Interpret 4711 Not That Kind Anastacia 4713 Freak of Nature Anastacia 4712 Wish You Were Here Pink Floyd Künstler Interpret Jahr der Gründung Anastacia 1999 Pink Floyd 1964 Lied CD_ID Track Titel 4711 1 Not That Kind 4711 2 I'm Outta Love 4711 3 Cowboys & Kisses 4712 1 Shine On You Crazy Diamond 4713 1 Paid my Dues An der Tabelle "Lied" wurden keine Änderungen bei der Übertragung in die 3. Normalform vorgenommen. Sie ist hier nur der Vollständigkeit halber gelistet.
Die Relation wird aufgeteilt, wobei die beiden voneinander abhängigen Daten in eine eigene Tabelle ausgelagert werden. Der Schlüssel der neuen Tabelle muss als Fremdschlüssel in der alten Tabelle erhalten bleiben.
Boyce-Codd-Normalform (BCNF)
Eine Relation ist in BCNF, wenn sie die Voraussetzungen der 3NF erfüllt, und jede Determinante (Attributmenge, von der andere Attribute funktional abhängen) ein Schlüsselkandidat ist (oder die Abhängigkeit ist trivial). Ein Schlüsselkandidat ist eine Menge von Attributen, von der alle Attribute der Relation voll funktional abhängig sind.
Die BCNF (nach Raymond F. Boyce und Edgar F. Codd) verhindert, dass Teile zweier aus mehreren Feldern zusammengesetzten Schlüsselkandidaten voneinander abhängig sind.
Die Überführung in die BCNF ist zwar immer verlustfrei möglich, aber nicht immer abhängigkeitserhaltend. Die Boyce-Codd-Normalform war ursprünglich als Vereinfachung der dritten Normalform gedacht, führte aber zu einer neuen Normalform, die die 3NF verschärft.
Beispiel
In diesem Beispiel gibt es eine einfache Datenbank, in der die Vereinszugehörigkeit von Sportlern gespeichert wird. Es sollen die folgenden Bedingungen gelten:
- jeder Verein bietet nur eine Sportart an.
- ein Sportler kann in verschiedenen Vereinen spielen, aber nur, wenn diese Vereine unterschiedliche Sportarten betreiben. Damit wird sichergestellt, dass der Sportler nie gegen einen Verein spielt, in dem er selbst Mitglied ist.
Sportler Name Sportart Verein Schuster Fußball FC Musterhausen Leitner Fußball FC Musterhausen Leitner Eishockey EC Beispielstadt Verletzung der BCNF
Aus den oben genannten Bedingungen folgt, dass das Attribut Sportart funktional abhängig vom Attribut Verein ist, d. h. Verein ist eine Determinante. Jedoch ist Verein kein Schlüsselkandidat. Mögliche Schlüsselkandidaten sind {Name,Verein} und {Name,Sportart}. Wie man sieht, kommt jedes Attribut in einem Schlüsselkandidaten vor, wodurch die Relation in 3NF, allerdings nicht in BCNF ist. Jedoch ist eine Konvertierung in BCNF möglich, indem (Name, Verein) als Primärschlüssel verwendet und die Relation aufgeteilt wird:
Lösung
Sportler Name Verein Schuster FC Musterhausen Leitner FC Musterhausen Leitner EC Beispielstadt Verein Verein Sportart FC Musterhausen Fußball EC Beispielstadt Eishockey Zerlegungsalgorithmus
Es existiert ein Algorithmus, der relationale Schemata durch Zerlegung (engl. decomposition) in die Boyce-Codd-Normalform überführt. Alle Schemata werden dabei solange aufgespalten, bis keines mehr die BCNF bricht. Jede Aufspaltung erfolgt anhand einer, die BCNF verletzenden, funktionalen Abhängigkeit. Die Attribute der verletzenden Abhängigkeit bilden das erste neue Schema, und die restlichen Attribute plus die Determinante ein weiteres Schema. Die beiden neuen Schemata enthalten von den ursprünglichen funktionalen Abhängigkeiten lediglich solche, welche nur Attribute des jeweiligen Schemas nutzen, der Rest geht verloren.
Folgender Pseudocode beschreibt den Zerlegungsalgorithmus:[2]
1: Gegeben ist ein relationales Schema  , mit der Menge aller Attribute
, mit der Menge aller Attribute  und der Menge der funktionalen Abhängigkeiten
und der Menge der funktionalen Abhängigkeiten  über diesen Attributen.
über diesen Attributen.2: Die Ergebnismenge Dekomposition, bestehend aus den zerlegten Schemata, wird mit R initialisiert. 3: Solange es ein Schema S in der Menge Dekomposition gibt, das nicht in der BCNF ist, führe folgende Zerlegung aus: - 4:
Sei  eine Attributmenge für die eine funktionale Abhängigkeit
eine Attributmenge für die eine funktionale Abhängigkeit  definiert ist, welche der BCNF widerspricht.
definiert ist, welche der BCNF widerspricht.- 5:
Ersetze S in der Ergebnismenge Dekomposition durch zwei neue Schemata  , ein Schema bestehend nur aus den Attributen der Abhängigkeit, welche die BCNF ursprünglich verletzt hat; und
, ein Schema bestehend nur aus den Attributen der Abhängigkeit, welche die BCNF ursprünglich verletzt hat; und  , ein Schema mit allen Attributen, außer denen die nur in der abhängigen Menge
, ein Schema mit allen Attributen, außer denen die nur in der abhängigen Menge  und nicht in der Determinante
und nicht in der Determinante  enthalten sind. Die Menge der funktionalen Abhängigkeiten
enthalten sind. Die Menge der funktionalen Abhängigkeiten  enthält nur noch die Abhängigkeiten, welche lediglich Attribute aus
enthält nur noch die Abhängigkeiten, welche lediglich Attribute aus  enthalten, entsprechendes gilt für
enthalten, entsprechendes gilt für  . Damit fallen alle Abhängigkeiten weg, welche Attribute aus beiden Schemata benötigen.
. Damit fallen alle Abhängigkeiten weg, welche Attribute aus beiden Schemata benötigen.6: Ergebnis: Dekomposition – eine Menge von relationalen Schemata, welche in der BCNF sind. Durchlauf des Algorithmus am obigen Beispiel (ohne Darstellung aller trivialen Abhängigkeiten):
- 1: R = ( { Name, Sportart, Verein }, { ( { Name, Sportart } → { Verein } ), ( { Verein } → { Sportart } ), ( { Name, Verein } → { Name, Verein } ) } )
- 2: Dekomposition = { R }
- 3: da R aus Dekomposition nicht die BCNF erfüllt mache folgendes:
- 4,5: { Verein } → { Sportart } ist die Abhängigkeit, die die Verletzung der BCNF bedingt, damit ist S1 = ( { Verein, Sportart }, { ( { Verein } → { Sportart }) } ) und S2 = ( { Name, Verein }, { ( { Name, Verein } → { Name, Verein } ) } )
- 6: Ergebnis: Dekomposition: = {S1,S2}
Unterschied zur 3.NF
Die BCNF-Normalform ist strenger hinsichtlich der erlaubten funktionalen Abhängigkeiten. Beispielsweise können in Relationen der 3. Normalform einige Informationen doppelt vorkommen, in der BCNF jedoch nicht.
Vierte Normalform (4NF)
Die 4. Normalform beschreibt die mehrwertige Abhängigkeit (MWAs). Eine Datenbank ist dann in der 4. Normalform, wenn sie nur noch triviale mehrwertige Abhängigkeiten enthält oder die nicht-trivialen mehrwertigen Abhängigkeiten von Superschlüsseln ausgehen. Einfach gesagt: Es darf in einer Relation nicht mehrere, voneinander unabhängige, 1:n- oder m:n-Beziehungen zu einem Schlüsselwert geben, z. B. gehört zu einem Schlüsselwert i-mal Attribut a, aber davon unabhängig auch m-mal Attribut b.
Beispiel
Besitz Personnummer Haustier Fahrzeug 1 Katze Volkswagen 1 Katze Ferrari 1 Pelikan Volkswagen 1 Pelikan Ferrari 2 Hund Porsche Verletzung der 4NF
Zu einer Personennummer gibt es mehrere Haustiere und Fahrzeuge. Haustier und Fahrzeug sind aber unabhängig voneinander. Personnummer → Haustier ist dabei eine mehrwertige Abhängigkeit (MWA), Personnummer → Fahrzeug auch. Diese beiden MWAs sind unabhängig voneinander, also können wir diese Tabelle in die 4NF aufspalten.
Lösung
Haustier Personnummer Haustier 1 Katze 1 Pelikan 2 Hund Fahrzeug Personnummer Fahrzeug 1 Volkswagen 1 Ferrari 2 Porsche Hinweis
Folgende Relation erfüllt die 4NF:
Familie Personnummer Partner Kind Person → Partner und Person → Kind sind zwar zwei MWAs, aber diese beiden sind auch untereinander abhängig: Partner → Kind. Solche untereinander abhängigen MWAs werden erst in 5NF gelöst.
Fünfte Normalform (5NF)
Die 5NF vereinfacht Relationen soweit, dass durch Projektions- und Verbundoperationen die Informationen der ursprünglichen Relation wiederhergestellt werden. Sie ist somit sehr generell gehalten und dadurch (vorerst) die letzte Normalform. So können Relationen in einzelne Abfragen aufgeteilt werden und durch spätere Verbundsoperationen wieder zusammengefügt werden, wobei eine Teilmenge des so genannten kartesischen Produkts entsteht. Einfach gesagt: Eine Relation ist in 5NF, wenn sie sich nicht aus einfacheren Relationen (solche, die weniger Attribute enthalten) durch Verbundoperationen rekonstruieren lässt.
Beispiel
Die folgende Relation zeigt, welche Lieferanten welche Bauteile an welches Projekt liefern können:
Lieferant Teil Projekt Müller Schraube Projekt 1 Müller Nagel Projekt 2 Maier Nagel Projekt 1 Verletzung der 5NF
Die Relation kann weiter zerteilt werden, ohne dass Information verloren geht.
Lösung
Um diese Relation in die 5. Normalform umzuwandeln, müssen drei Relationen erstellt werden (Lieferant-Teil, Teil-Projekt und Lieferant-Projekt).
- Welche Teile kann welcher Lieferant liefern?
Lieferant-Teil Lieferant Teil Müller Schraube Müller Nagel Maier Nagel - Welche Teile werden von welchem Projekt benötigt?
Teil-Projekt Teil Projekt Schraube Projekt 1 Nagel Projekt 2 Nagel Projekt 1 - Welche Projekte können von welchem Lieferanten beliefert werden?
Lieferant-Projekt Lieferant Projekt Müller Projekt 1 Müller Projekt 2 Maier Projekt 1 Hinweis
Anders als bei der Umformung zwischen den bisherigen Normalformen wird durch diese Umwandlung etwas anderes durch die neuen Relationen ausgedrückt als zuvor in der 4. Normalform.
Das merkt man leicht, wenn man die drei Relationen aus dem Beispiel oberhalb wieder vereinigt:
Lieferant Teil Projekt Müller Schraube Projekt 1 Müller Nagel Projekt 2 Müller Nagel Projekt 1 Maier Nagel Projekt 1 Neu ist das Tupel: Müller – Nagel – Projekt 1.
Denn Müller könnte theoretisch das Projekt 1 mit Nägeln beliefern, da
- er auch Projekt 2 mit Nägeln beliefert und
- Projekt 1 auch Nägel benötigt (die jedoch bisher von Maier geliefert wurden).
Die Überführung in 5NF ist also nur dann möglich, wenn man die Möglichkeiten der Verbindungen aus drei Beziehungen ausdrücken möchte und nicht eine konkrete Verbindung zwischen den dreien haben möchte.
Bemerkungen
Schwächen im Datenmodell aufgrund fehlender Normalisierung können – neben den typischen Anomalien – einen höheren Aufwand bei einer späteren Weiterentwicklung bedeuten. Andererseits kann beim Datenbankentwurf aus Überlegungen zur Performance bewusst auf Normalisierungsschritte verzichtet werden (Denormalisierung). Typisches Beispiel dafür ist das Sternschema im Data-Warehouse.
Die Erstellung eines normalisierten Schemas wird durch automatische Ableitung aus einem konzeptuellen Datenmodell gestützt; hierzu dient in der Praxis ein erweitertes Entity-Relationship-Modell (ERM) oder ein Klassendiagramm der Unified Modeling Language (UML) als Ausgangspunkt. Das aus dem konzeptionellen Entwurf abgeleitete Relationenschema kann dann mit Hilfe der Normalisierungen überprüft werden; es existieren jedoch Formalismen und Algorithmen, die diese Eigenschaft bereits sicherstellen können.
Statt des ursprünglichen von Peter Chen 1976 entwickelten ER-Modells werden heute erweiterte ER-Modelle verwendet: Das Structured-ERM (SERM), das E3R-Modell, das EER-Modell sowie das von der SAP AG verwendete SAP-SERM.
Befindet sich ein Relationenschema nicht in der 1NF, so nennt man diese Form auch Non-First-Normal-Form (NF²) oder Unnormalisierte Form (UNF).
Der Prozess der Normalisierung und Zerlegung einer Relation in die 1NF, 2NF und 3NF muss die Wiederherstellbarkeit der ursprünglichen Relation erhalten, das heißt die Zerlegung muss verbundtreu und abhängigkeitstreu sein.
Merkspruch
Als eine Gedächtnisstütze für die Grade von Abhängigkeit vom Schlüssel in den ersten drei Normalformen wird gerne folgender Spruch genannt: the key, the whole key, and nothing but the key - so help me Codd (Der Schlüssel, der ganze Schlüssel und nichts als der Schlüssel – so wahr mir Codd helfe.):
- alle (impliziert: atomaren) Werte beziehen sich auf den Schlüssel – 1. NF
- bei zusammengesetzten Schlüsseln beziehen sie sich jeweils auf den gesamten Schlüssel – 2. NF
- die Werte hängen nur vom Schlüssel ab, und nicht von weiteren Werten – 3. NF
Merkregeln
- Ist die Relation in 1. Normalform und besteht der Primärschlüssel aus nur einem Attribut, so liegt automatisch die 2. Normalform vor.
- Ist eine Relation in 2. Normalform und besitzt sie außer dem Primärschlüssel höchstens ein weiteres Attribut, so liegt die Tabelle in 3. Normalform vor.
Quellen
- ↑ Paul Alpar: Datenorganisation und Datenbanken, S. 31 (PDF)
- ↑ Philip M. Lewis, Arthur Bernstein, Michael Kifer: Databases and transaction processing: an application-oriented approach. Addison-Wesley, 2002, ISBN 0-201-70872-8, S. 232.
Literatur
- Ramez Elmasri, Shamkant B. Navathe: Grundlagen von Datenbanksystemen. Pearson Studium, 2002, ISBN 3-8273-7021-3
- Alfons Kemper, Andre Eickler: Datenbanksysteme. Eine Einführung. Oldenbourg, München 2004, ISBN 3-486-27392-2
- Stefan M. Lang, Peter C. Lockemann: Datenbankeneinsatz. Springer, Berlin u. a. 1995, ISBN 3-540-58558-3
Weblinks
- Der Königsweg: Normalisierung, Hochschule der Medien Stuttgart
- Access: Grundlagen der Datenbanknormalisierung, Microsoft Hilfe und Support
- Normalisierung von Datenbanken, Richard-Wossidlo-Gymnasium Ribnitz-Damgarten
- Erklärung der Normalformen, Ziemer's Informatik
- Interaktiver Normalformentrainer bis zur 3. Normalform
- Normalisierung, Vorlesungsskript TU Berlin


Dieser Artikel wurde in die Liste der lesenswerten Artikel aufgenommen. Kategorien:- Wikipedia:Lesenswert
- Datenbankmodellierung
- Datenbanktheorie

Wikimedia Foundation.