- Abhängigkeitstreue
-
Funktionale Abhängigkeiten (Abk. FA, englisch functional dependency, FD) sind ein Konzept der relationalen Entwurfstheorie und bilden die Grundlage für die Normalisierung von Relationenschemata.
Eine Relation wird durch Attribute definiert. Bestimmen einige dieser Attribute eindeutig die Werte anderer Attribute, so spricht man von funktionaler Abhängigkeit. So könnte man sich etwa eine Kundendatenbank vorstellen, in der die Anschrift und die Telefonnummer eines Kunden eindeutig durch seinen Namen zusammen mit seinem Geburtsdatum bestimmt sind. Hier wären also Anschrift und Telefonnummer funktional abhängig von Name und Geburtsdatum.
Mit Hilfe funktionaler Abhängigkeiten lässt sich auch der Begriff Schlüssel definieren:
Bestimmen einige Attribute einer Relation eindeutig die Werte aller Attribute der Relation, so spricht man von einem Superschlüssel, das heißt, jedes Tupel dieser Relation ist eindeutig durch die Werte dieser Attribute bestimmt. Zum Beispiel könnte man eine Kundennummer einführen, die jeden Kunden identifiziert. Ein Schlüsselkandidat ist ein minimaler Superschlüssel, das heißt, keine echte Teilmenge der Attribute dieses Schlüssels bestimmt vollständig die Werte aller anderen Attribute der Relation. Unter allen Schlüsselkandidaten einer Relation wird ein so genannter Primärschlüssel ausgewählt.
Beispiel:
A B C 1 1 3 1 1 3 1 2 4 In diesem Beispiel ist C funktional abhängig von A und B, geschrieben A, B → C. Der Pfeil kann somit gelesen werden als „bestimmt eindeutig“: Die ersten beiden Attribute zusammen bestimmen eindeutig, welchen Wert Attribut C. hat. Anders ausgedrückt: Ist bekannt, welche Werte die ersten beiden Attribute haben, ist damit auch der Wert des letzten Attributes bestimmt. Aber C ist nicht funktional abhängig von A allein. Es gelten auch die funktionalen Abhängigkeiten „A ist funktional abhängig von C“, „A ist funktional abhängig von B“ und „C ist funktional abhängig von B“.
Inhaltsverzeichnis
Formale Definition
Sei r(R) eine Relation mit dem Relationenschema R und seien α und β Teilmengen von Attributen von R. Sei t ∈ r ein Tupel aus r. Dann ist t[α] die Einschränkung von t auf die Attribute aus α. Die funktionale Abhängigkeit α → β (β ist funktional abhängig von α) gilt auf R, wenn für jede zulässige Relation r(R) gilt:
![\forall t_1, t_2 \in r: t_1[\alpha]=t_2[\alpha] \implies t_1[\beta]=t_2[\beta]](/pictures/dewiki/48/0714de29cec80db1abaf811634463c03.png)
Das heißt, für alle Tupel t1, t2 ∈ r mit gleichen α-Attributen (t1[α] = t2[α]) gilt auch, dass ihre β-Attribute gleich sind (t1[β] = t2[β]). Die Werte der Attribute aus der Attributmenge α bestimmen also eindeutig die Werte der Attribute aus der Attributmenge β. Übrigens: Für Attributmengen schreibt man üblicherweise kurz αβ statt α⋃β.
β heißt voll funktional abhängig von α, wenn aus α kein Attribut entfernt werden kann, so dass die Bedingung immer noch gilt.
Im Beispiel oben spielt das Attribut 'A' für die Bestimmung von 'C' keine Rolle:
Aus der funktionalen Abhängigkeit AB → C lässt sich die volle funktionale Abhängigkeit B → C gewinnen.
Axiome von Armstrong
Mit Hilfe der Axiome von Armstrong (auch Armstrong-Axiome) lassen sich aus einer Menge von funktionalen Abhängigkeiten, die auf einer Relation gelten, weitere funktionale Abhängigkeiten ableiten. Die folgenden drei Regeln reichen aus, um alle funktionalen Abhängigkeiten herzuleiten:
1. Eine Menge von Attributen bestimmt eindeutig die Werte einer Teilmenge dieser Attribute (triviale Abhängigkeit), das heißt,
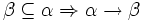 . (Reflexivität)
. (Reflexivität)2. Gilt
 , so gilt auch
, so gilt auch 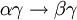 für jede Menge von Attributen γ der Relation. (Erweiterungsregel, Verstärkung)
für jede Menge von Attributen γ der Relation. (Erweiterungsregel, Verstärkung)3. Gilt
und 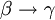 , so gilt auch
, so gilt auch 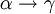 . (Transitivitätsregel)
. (Transitivitätsregel)Um Herleitungen einfacher zu gestalten, können zusätzlich die folgenden (abgeleiteten) Regeln verwendet werden:
4. Gelten
und , so gilt auch 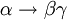 . (Vereinigungsregel)
. (Vereinigungsregel)5. Gilt
, so gelten auch und . (Dekompositions-/Zerlegungsregel)6. Gilt
und 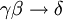 , so gilt auch
, so gilt auch 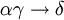 . (Pseudotransitivitätsregel)
. (Pseudotransitivitätsregel)Normalisierung mit funktionalen Abhängigkeiten
Mit Hilfe von funktionalen Abhängigkeiten lassen sich Relationenschemata normalisieren. Ein Relationenschema R ist zum Beispiel in Boyce-Codd-Normalform, wenn für alle funktionalen Abhängigkeiten α → β, die auf R gelten, gilt: Die funktionale Abhängigkeit ist trivial oder α ist ein Superschlüssel für R. Die 3. Normalform ist etwas abgeschwächt. Für sie muss eine der oben angegebenen Bedingungen gelten oder dass alle Attribute aus β − α in mindestens einem der Schlüsselkandidaten von R enthalten sind.
Es gibt Algorithmen, die ein Relationenschema auf der Grundlage funktionaler Abhängigkeiten in normalisierte Schemata zerlegen. Ziel einer solchen Zerlegung ist Verlustlosigkeit und Abhängigkeitstreue (auch Abhängigkeitsbewahrung) der Zerlegung. Abhängigkeitstreue bedeutet, dass alle funktionalen Abhängigkeiten die auf der ursprünglichen Relation gelten, auch auf der Zerlegung noch gelten. Ein solcher Algorithmus, der in die dritte Normalform transferiert, ist der Synthesealgorithmus.
Attributhülle
Die Attributehülle α + eines bestimmten Attributs α ist eine Liste aller Attribute, die von α funktional abhängen. Im kleinsten Fall ist die Attributhülle nur das Attribut selbst, da keine anderen Attribute von ihm abhängen. Will man die Attributhülle eines Attributs bei einer gegebenen Anzahl funktionaler Abhängigkeiten F bestimmen, kann man einen einfachen Algorithmus anwenden, der durch wiederholte Anwendung der Transitivitätsregel die Menge der abhängigen Attribute bestimmt. Der Algorithmus ist wie folgt definiert:
Eingabe:
- eine Menge funktionaler Abhängigkeiten F
- eine Menge von Attributen α
Ausgabe:
- die vollständige Menge der Attribute α + die sich aus α durch die Abhängigkeiten F ableiten lässt. Es gilt
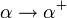 .
.
Hülle(F,α)
α + = α
while( Änderung an α + ) do
foreach( Abhängigkeit ∈ F) do
if (β ⊆ α + ) then α + = α + ∪γ
Angewendet auf eine konkrete Menge an funktionalen Abhängigkeiten F:- F hat die Abhängigkeiten:
- Wir wollen die Attributhülle für A bestimmen.
1. A + = A
2. Durchlaufen der funktionalen Abhängigkeiten von oben nach unten:
-
- A,B ist keine Teilmenge von A
- D ist keine Teilmenge von A
- A ist Teilmenge von A
- A + = A + + G,H
- G ist Teilmenge von A,G,H
- A + = A + + B
- Neuer Durchlauf:
- A,B ist Teilmenge von A,G,H,B
- A + = A + + C
- ...danach ändert sich nichts mehr an der Menge A + = A,G,H,B,C
Abgeschlossene Hülle
Intuitiv gesprochen ist die abgeschlossene Hülle einer Menge von funktionalen Abhängigkeiten die Menge der Attribute, die durch die „linken Seiten“ der Abhängigkeiten bestimmt ist.
Ist F ={α1 → β1,...,αn → βn} eine Menge von funktionalen Abhängigkeiten, so ist die abgeschlossene Hülle oder Attributhülle die Menge
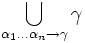
und wird mit F + bezeichnet. Für die Hülle gilt:
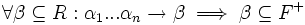
Weiterführende Konzepte
- Mehrwertige Abhängigkeiten bilden eine Erweiterung der Funktionalen Abhängigkeiten, die es ermöglichen, zusätzliche Anomalien in einem relationalen Schema aufzudecken.
- Konditionale Abhängigkeiten (engl. Conditional Functional Dependencies) bilden eine Erweiterung der Funktionalen Abhängigkeiten um konkrete Wertetabellen. Eine Abhängigkeit wie zum Beispiel PLZ → Ort wird um eine zusätzliche Tabelle mit konkreten Werten wie zum Beispiel 80001 → München erweitert. Der Postleitzahl 80001 wird der Ort München direkt zugeordnet. Mit Hilfe dieser konditionalen Abhängigkeiten lässt sich die Qualität von Daten messen, bzw. es lassen sich Maßnahmen zur Verbesserung der Datenqualität ableiten.
Literatur
- Alfons Kemper, André Eickler: Datenbanksysteme. Eine Einführung. Oldenbourg, München 2004, ISBN 3-486-27392-2
- P. Bohannon, W. Fan, F. Geerts, X. Jia, and A. Kementsietsidis: Conditional Functional Dependencies for Data Cleaning, ICDE, 2007.
Siehe auch
- Minimale Überdeckung von Mengen funktionaler Abhängigkeiten: Kanonische Überdeckung
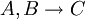
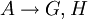
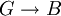
Wikimedia Foundation.