- Chowtest
-
Der Chow-Test ist ein statistischer Test mit dem sich die Koeffizienten zweier linearer Regressionen auf Gleichheit testen lassen. Der Test ist nach seinem Erfinder, dem Ökonomen Gregory Chow benannt.
Der Chow-Test wird in der Ökonometrie verwandt, um Zeitreihenanalysen auf Strukturbrüche zu testen. Eine weiteres Anwendungsgebiet ist die Programmevaluation, hierbei werden 2 unterschiedliche Teilgruppen (Programme), wie zum Beispiel 2 Schultypen, miteinander verglichen. Im Gegensatz zur Zeitreihenanalyse lassen sich hier die beiden Teilgruppen keinen aufeinander folgenden Intervallen zuordnen, stattdessen erfolgt die Einteilung nach einen qualitativen Aspekt, wie zum Beispiel den Schultyp.
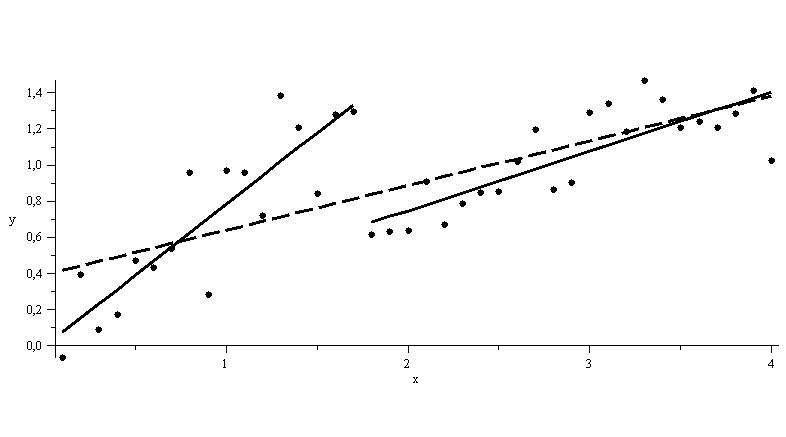
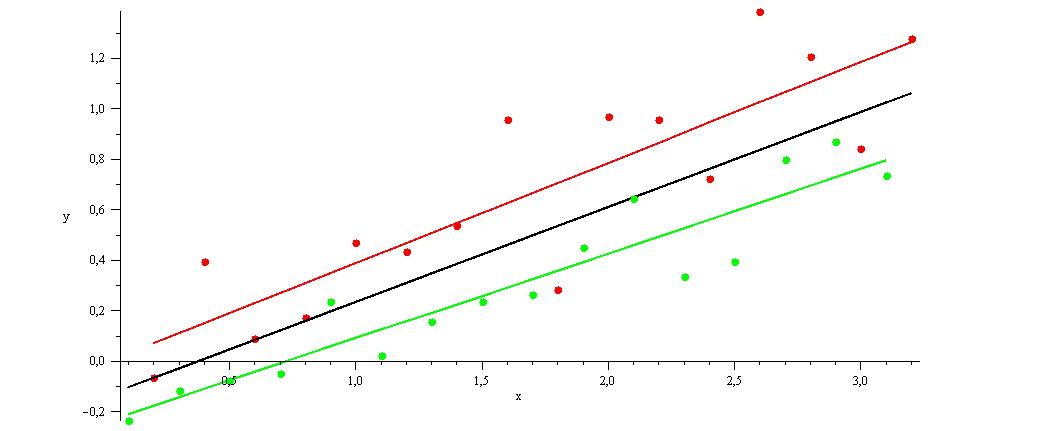
Strukturbruch Programmevaluation 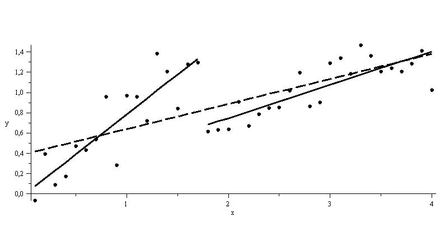
Bei x = 1.7 liegt ein Strukturbruch vor, Regression auf den Teilintervallen [0,1.7] und [1.7,4] liefern eine bessere Modellierung als die Regression über dem Gesamtinerval (gestrichelt)
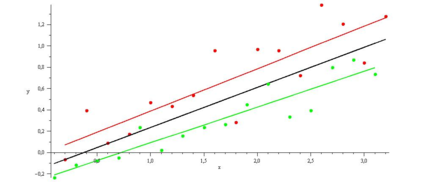
Vergleich zweier Programme (rot,grün) im selben Datensatz, separate Regressionen auf den zu einem Programm gehörigen Daten liefert eine bessere Modellierung als die Regression über den gesamten Datensatz (schwarz)
Gegeben ist ein Datensatz (Yi,Xi) mit
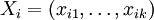 für
für  , dessen Beziehung durch eine lineare Funktion mit einen normalverteilten Fehler (ε) mit Erwartungswert 0 (E(ε) = 0) beschrieben wird (multiple Regressionsanalyse), d.h. man hat
, dessen Beziehung durch eine lineare Funktion mit einen normalverteilten Fehler (ε) mit Erwartungswert 0 (E(ε) = 0) beschrieben wird (multiple Regressionsanalyse), d.h. man hat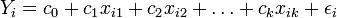 für
für
Man vermutet jedoch, das sich der Datensatz in 2 Gruppen aufteilen lässt, die durch 2 unterschiedliche lineare Funktionen besser beschrieben werden.
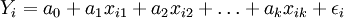 für
für 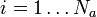
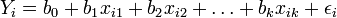 für
für 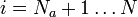
Hierbei ist N = Na + Nb und es wird die Hypothese
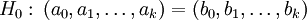 gegen
gegen 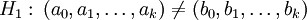 gestestet. Bezeichnet man die Summe der quadrierten Residuen der Regression über den gesamten Datensatz mit S und über die beiden Teilgruppen mit Sa und Sb, dann folgt die unten definierte Testgröße T einer F-Verteilung mit den Freiheitsgraden k + 1 und Na + Nb − 2(k + 1).
gestestet. Bezeichnet man die Summe der quadrierten Residuen der Regression über den gesamten Datensatz mit S und über die beiden Teilgruppen mit Sa und Sb, dann folgt die unten definierte Testgröße T einer F-Verteilung mit den Freiheitsgraden k + 1 und Na + Nb − 2(k + 1).Beispiel
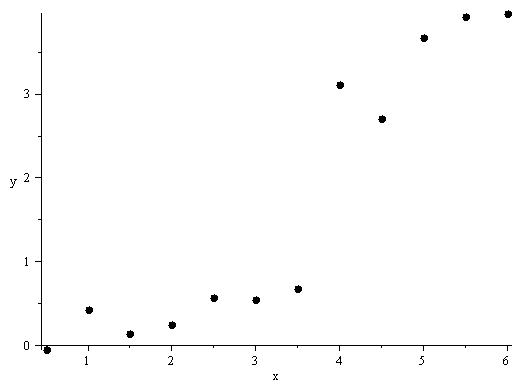
Gegeben ist der folgende Datensatz dess Beziehung durch die lineare Y = c0 + c1X modelliert werden soll:
Xi 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 5.5 6.0 Yi −0.043 0.435 0.149 0.252 0.571 0.555 .678 3.119 2.715 3.671 3.928 3.962  Datenplot legt einen Strukturbruch bei x = 4 nahe
Datenplot legt einen Strukturbruch bei x = 4 naheEin Datenplot lässt vermuten, dass bei x = 4 ein Strukturbruch vorliegt, daher teilt man den Datensatz in 2 Intervalle [0.5,3.5] und [4.0,6.0] ein und führt über diesen, zusätzlich zur Regression über den gesamten Datensatz, getrennte Regressionen durch. Dann testet man,ob die beiden Teilregressionen dieselbe lineare Funktion erzeugen, also
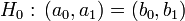 gegen
gegen 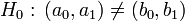
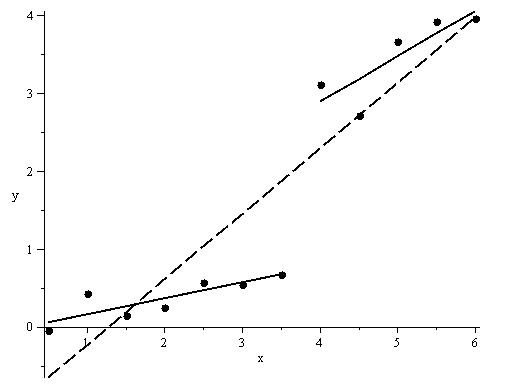
Regression auf dem gesamten Datensatz:
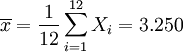
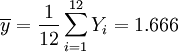
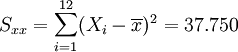
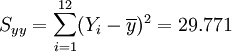
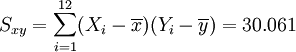
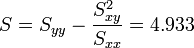
Regression auf [0.5,3.5]
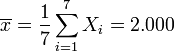
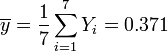
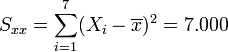
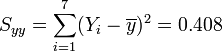
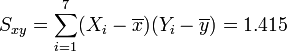
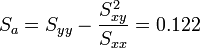
Regression auf [4.0,6.0]
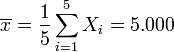
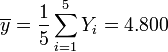
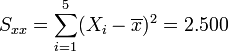
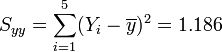
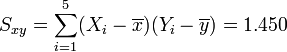
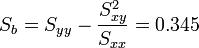
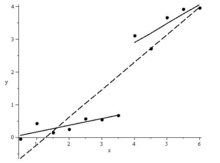 Datenplot mit Regressionsgeraden
Datenplot mit RegressionsgeradenBerechnung der Testgröße:
wegen F0.95(2,8) = 4.59 gilt
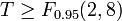 , somit kann die Hypothese H0 verworfen werden, d.h. die beiden Regressionsgeraden aus den Teilintervallen sind nicht identisch. Es liegt also ein Strukturbruch vor und die Teilregressionen liefern eine bessere Modellierung als die Regression über den gesamten Datensatz.
, somit kann die Hypothese H0 verworfen werden, d.h. die beiden Regressionsgeraden aus den Teilintervallen sind nicht identisch. Es liegt also ein Strukturbruch vor und die Teilregressionen liefern eine bessere Modellierung als die Regression über den gesamten Datensatz.Literatur
- Howard E. Doran: Applied Regression Analysis in Econometrics. CRC Press 1989, ISBN 0824780493, S.146 (eingeschränkte Online-Version (Google Books))
- Christopher Dougherty: Introduction to Econometrics. Oxford University Press 2007, ISBN 0199280967, S.194 (eingeschränkte Online-Version (Google Books))
- Gregory C. Chow: Tests of Equality Between Sets of Coefficients in Two Linear Regressions. In: Econometrica. 28(3), 1960, S. 591–605
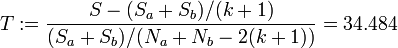
Wikimedia Foundation.