- Klassifizierer
-
Ein Klassifikator (Informatik) sortiert Dokumente in Klassen ein. Diese Methodik kommt vor allem im Webmining zum Einsatz.
Inhaltsverzeichnis
Trainieren
Ein Klassifikator wird zunächst trainiert, das heißt er bekommt Daten, von denen die Kategorisierung bekannt ist, um anhand derer neue Beispiele einordnen zu können. Man unterscheidet folgende Lernarten:
- betreutes Lernen (supervised learning): Ein „Lehrer“ gibt die Werte der Zielfunktion für alle Trainingsbeispiele an
- halb-betreutes Lernen (semi-supervised learning): Nur ein Teil der Trainingsbeispiele wird klassifiziert
- aktives Lernen (active learning): Der Klassifikator wählt die Beispiele aus, die vom „Lehrer“ eingeordnet werden sollen
- Selbst-Training (self-training): Der Klassifikator ordnet die Beispiele selbst ein
- Co-Training: Zwei Klassifikatoren ordnen gegenseitig ihre Beispiele ein
- Multi-View-Lernen: Zwei identische Klassifikatoren, die unterschiedlich trainiert wurden, ordnen gegenseitig ihre Beispiele ein
- unterstütztes Lernen (reinforcement learning): Der Agent bekommt zwar Feedback von der Umwelt zu seiner Kategorisierung, erfährt aber nicht explizit, was die richtige Kategorisierung gewesen wäre.
- unbetreutes Lernen (unsupervised learning): Es gibt keine vorkategorisierten Beispiele
Lernmethoden
Klassifikatoren können auf sehr unterschiedliche Weise lernen und ihre Trainingsbeispiele verwerten. Die Wahl des Algorithmus ist abhängig von der Art der Trainingsdaten sowie den verfügbaren Leistungsreserven. Folgende Lernmethoden werden eingesetzt:
- Entscheidungsbäume und Regressionsbäume
- Induktive logische Programmierung
- Neuronale Netzwerke
- Support-Vector-Maschine
- Clustering z. B. k-means-Clustering (unsupervised)
- Genetische Algorithmen
- kNN-Klassifikator (überwacht)
- Rocchio Klassifikator
- statistische Modellierung z. B. Naive Bayes Klassifikator
- Regelbasierte Klassifikator (Rasteranalyse)
Weitere Lernansätze sind beispielsweise
- Lernen als Suchen
- Generalisierung mit Bias (Der Lerner hat bestimmte „Vorlieben“, zieht Klassen vor)
- Teile und Herrsche-Strategien
- Overfitting-Avoidance: Das Modell generalisieren um die Fehleranfälligkeit zu reduzieren (Bsp.: (Ockhams Rasiermesser)
Evaluierung
Zur Evaluierung des gelernten Modells werden folgende Verfahren eingesetzt:
- Validierung durch Experten
- Validerung auf Daten
- Online-Validierung
Die Valdierung auf Daten hat als Nachteil, dass Trainingsdaten zur Validierung „verschwendet“ werden (Out-of-Sample Testing). Dieses Dilemma kann durch Quer-Validierung (Cross-Validation) gelöst werden: Man teilt die Datensätze in n Teile. Dann nutzt man für jede Partition p die anderen n-1 Partitionen zum Lernen und die Partition p zum Testen.
Zur Bewertung eines Klassifizieres werden gängigerweise drei Größen angegeben, die auf folgender Tabelle basieren:
positiv klassifiziert negativ klassifiziert tatsächlich positiv a c a+c tatsächlich negativ b d b+d a+b c+ d n Treffergenauigkeit (Accuracy)
Die Treffergenauigkeit gibt den Anteil der korrekt klassifizierten Beispiele an.
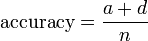
Erinnerung (Recall)
Die Erinnerung gibt den Anteil der positiven Beispiele an, die positiv klassifiziert wurden.
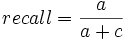
Präzision (Precision)
Die Präzision gibt den Anteil der positiv klassifizierten Beispiele an, die tatsächlich positiv sind.
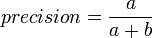
zusätzliche Eigenschaften (Feature Engineering)
Die Ansätze zur Erweiterung von Klassifikatoren gliedern sich wie folgt:
- textabhängige Eigenschaften
- n-Gramme: Ausnutzen des Kontextes durch Verwendung von Sequenzen der Länge n anstelle einzelner Worte (dadurch Unterscheidung von z. B. „mining“ in „web mining“ und „coal mining“)
- Positionsinformationen
- Linguistische Eigenschaften
- Stemming: gebeugte Verben auf ihren Wortstamm zurückführen
- noun phrases: Fokus von n-Grammen auf „echte“ Sätze beschränken (z. B. nur Bigramme mit Noun-Noun und Adverb-Noun)
- linguistic phrases: Finde alle Vorkommnisse eines syntaktischen Templates (z. B. „noun aux-verb <d-obj>“ findet „I am <Thomas>“)
- Strukturelle Eigenschaften
- Structural markup
- Hypertexte
- Feature Subset Selection (FSS)
- Feature Construction
- Latent Semantic Indexing: Die Probleme von Mehrdeutigkeit und Synonymen durch Trennung der Beispiele mit Hyperebenen mittels Singular Value Decomposition lösen.
- Stoppwort-Listen
Verwendung von Dokumentbezügen
Dokumente stehen für gewöhnlich nicht alleine, sondern befinden sich gerade im Netz in gegenseitigem Bezug, vor allem durch Links. Die Informationen aus diesen Links und der Vernetzungsstruktur lassen sich von Klassifikatoren verwenden.
Hubs & Authorities
Siehe auch den Artikel Hubs und Authorities
- Authorities sind Seiten die viele Informationen zum gesuchten Thema enthalten
- Hubs sind Seiten, die viele Links auf gute Authorities haben
Hierdurch ergibt sich eine gegenseitige Verstärkung. Durch iterative Berechnung der Scores mittels Hub score
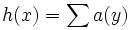 und Authority score
und Authority score 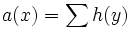 sowie anschließende Normalisierung konvergiert das Verfahren. Probleme:
sowie anschließende Normalisierung konvergiert das Verfahren. Probleme:- Effizienz
- Irrelevante Links (z. B. Werbelinks)
- Gegenseitige Verstärkung von Hosts
- Abweichungen vom Thema
Verbesserungen:
- Verbesserte Verbindungsanalyse: Die Wertungen nach Anzahl der Links normalisieren (Mehrere Links von einem Host werden schwächer gewertet)
- Relevanz-Gewichtung: Dokumente die eine ungenügende Ähnlichkeit zu einem Durchschnittsdokument des Root-Sets haben werden nicht betrachtet
Page Rank
Siehe auch den Artikel PageRank.
Die Idee hinter dem Page Rank ist der „Random Surfer“, der mit Wahrscheinlichkeit d auf einen zufälligen Link auf einer Seite klickt.
Der Page Rank bevorzugt Seiten mit
- vielen eingehenden Links
- Vorgängern mit hohem Page Rank
- Vorgängern mit wenig ausgehenden Links
Hypertext Klassifizierung
Häufig enthalten Webseiten nur wenig Text und/oder viele Bilder. Sie sind in einer anderen Sprache geschrieben, enthalten irritierende Begriffe oder enthalten gar keine nützliche Information. Links hingegen sind von mehreren Autoren geschrieben, enthalten ein reicheres Vokabular, redundante Informationen, erschliessen unterschiedliche Aspekte einer Seite und haben ihren Fokus auf den wichtigen Inhalten von Seiten. Sie sind daher zur Klassifizierung von vernetzten Dokumenten sehr geeignet. Die besten Ergebnisse lassen sich erzielen, wenn man zur Klassifizierung einer Seite die Klassen der Vorgänger sowie den Text betrachtet.
Hyperlink Ensembles
- Der Seitentext ist nicht interessant
- Jeder Link zur Seite wird ein eigenes Beispiel
- Linkankertext, Überschrift und den Paragraphen, in dem der Link vorkommt erfassen
- die Trainingsbeispiele (einer pro Link) klassifizieren und daraus die Klassifizierung für das aktuelle Dokument berechnen
Quellen
J. Fürnkranz: Webmining – Data Mining im Web http://www.ke.informatik.tu-darmstadt.de/lehre/ss05/web-mining.html
Wikimedia Foundation.