Nächste-Nachbarn-Klassifikation
- Nächste-Nachbarn-Klassifikation
-

K-
Nächste-
Nachbarn in einer zweidimensionalen Punktmenge mit k=
1 (
dunkelblau)
und k=
5 (
hellblau).
Der Radius der Kreise ist nicht fest.
Die Nächste-Nachbarn-Klassifikation ist eine parameterfreie Methode zur Schätzung von Wahrscheinlichkeitsdichtefunktionen. Der daraus resultierende k-Nearest-Neighbor-Algorithmus (KNN, zu deutsch „k-nächste-Nachbarn-Algorithmus“) ist ein Klassifikationsverfahren, bei dem eine Klassenzuordnung unter Berücksichtigung seiner k nächsten Nachbarn vorgenommen wird. Der Teil des Lernens besteht aus simplem Abspeichern der Trainingsbeispiele, was auch als lazy learning („träges Lernen“) bezeichnet wird.
k-Nearest-Neighbor-Algorithmus
Die Klassifikation eines Objekts  (oft beschrieben durch einen Merkmalsvektor) erfolgt im einfachsten Fall durch Mehrheitsentscheidung. An der Mehrheitsentscheidung beteiligen sich die k nächsten bereits klassifizierten Objekte von x. Dabei sind viele Abstandsmaße denkbar (Euklidischer Abstand, Manhattan-Metrik, usw.). x wird der Klasse zugewiesen, welche die größte Anzahl der Objekte dieser k Nachbarn hat.
(oft beschrieben durch einen Merkmalsvektor) erfolgt im einfachsten Fall durch Mehrheitsentscheidung. An der Mehrheitsentscheidung beteiligen sich die k nächsten bereits klassifizierten Objekte von x. Dabei sind viele Abstandsmaße denkbar (Euklidischer Abstand, Manhattan-Metrik, usw.). x wird der Klasse zugewiesen, welche die größte Anzahl der Objekte dieser k Nachbarn hat.
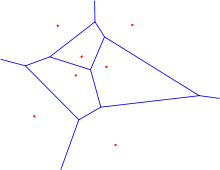
Voronoi-
Diagramm mit sieben Stützstellen
Für ein klein gewähltes k besteht die Gefahr, dass Rauschen in den Trainingsdaten die Klassifikationsergebnisse verschlechtert. Für k = 1 ergibt sich ein Voronoi-Diagramm. Wird k zu groß gewählt, besteht die Gefahr, Punkte mit großem Abstand zu x in die Klassifikationsentscheidung mit einzubeziehen. Diese Gefahr ist insbesondere groß, wenn die Trainingsdaten nicht gleichverteilt vorliegen oder nur wenige Beispiele vorhanden sind. Bei nicht gleichmäßig verteilten Trainingsdaten kann eine gewichtete Abstandsfunktion verwendet werden, die näheren Punkten ein höheres Gewicht zuweist als weiter entfernten. Ein praktisches Problem ist auch der Speicher- und Rechenaufwand des Algorithmus bei hochdimensionalen Räumen und vielen Trainingsdaten.
Siehe auch
Wikimedia Foundation.
Schlagen Sie auch in anderen Wörterbüchern nach:
K-Nearest-Neighbor — K Nächste Nachbarn in einer zweidimensionalen Punktmenge mit k=1 (dunkelblau) und k=5 (hellblau). Der Radius der Kreise ist nicht fest. Die Nächste Nachbarn Klassifikation ist eine parameterfreie Methode zur Schätzung von… … Deutsch Wikipedia
Nächster-Nachbar-Klassifikator — K Nächste Nachbarn in einer zweidimensionalen Punktmenge mit k=1 (dunkelblau) und k=5 (hellblau). Der Radius der Kreise ist nicht fest. Die Nächste Nachbarn Klassifikation ist eine parameterfreie Methode zur Schätzung von… … Deutsch Wikipedia
Nächster Nachbar Klassifikator — K Nächste Nachbarn in einer zweidimensionalen Punktmenge mit k=1 (dunkelblau) und k=5 (hellblau). Der Radius der Kreise ist nicht fest. Die Nächste Nachbarn Klassifikation ist eine parameterfreie Methode zur Schätzung von… … Deutsch Wikipedia
Klassifikationsverfahren — sind Methoden und Kriterien zur Einteilung von Objekten oder Situationen in Klassen, das heißt zur Klassifizierung. Ein solches Verfahren wird auch als Klassifikator bezeichnet. Viele Verfahren lassen sich als Algorithmus implementieren; man… … Deutsch Wikipedia
Nicht-parametrische Statistik — Der Zweig der Statistik, der als parameterfreie Statistik bekannt ist, beschäftigt sich mit parameterfreien statistischen Modellen und parameterfreien statistischen Tests. Andere gebräuchliche Bezeichnungen sind nicht parametrische Statistik oder … Deutsch Wikipedia
Nicht-parametrischer Test — Der Zweig der Statistik, der als parameterfreie Statistik bekannt ist, beschäftigt sich mit parameterfreien statistischen Modellen und parameterfreien statistischen Tests. Andere gebräuchliche Bezeichnungen sind nicht parametrische Statistik oder … Deutsch Wikipedia
Nichtparametrische Statistik — Der Zweig der Statistik, der als parameterfreie Statistik bekannt ist, beschäftigt sich mit parameterfreien statistischen Modellen und parameterfreien statistischen Tests. Andere gebräuchliche Bezeichnungen sind nicht parametrische Statistik oder … Deutsch Wikipedia
Nichtparametrische Verfahren — Der Zweig der Statistik, der als parameterfreie Statistik bekannt ist, beschäftigt sich mit parameterfreien statistischen Modellen und parameterfreien statistischen Tests. Andere gebräuchliche Bezeichnungen sind nicht parametrische Statistik oder … Deutsch Wikipedia
Verteilungsfreie Statistik — Der Zweig der Statistik, der als parameterfreie Statistik bekannt ist, beschäftigt sich mit parameterfreien statistischen Modellen und parameterfreien statistischen Tests. Andere gebräuchliche Bezeichnungen sind nicht parametrische Statistik oder … Deutsch Wikipedia
Liste von Algorithmen — Dies ist eine Liste von Artikeln zu Algorithmen in der deutschsprachigen Wikipedia. Siehe auch unter Datenstruktur für eine Liste von Datenstrukturen. Inhaltsverzeichnis 1 Klassen von Algorithmen nach Komplexität 2 Klassen von Algorithmen nach… … Deutsch Wikipedia


