- Referenzielle Integrität
-
Die referentielle Integrität – oft auch als RI abgekürzt – ist eine Form der Datenintegrität. Unter der referentiellen Integrität versteht man die Integrität auf Beziehungsebene. Neben der referentiellen Integrität unterscheidet man noch die Wertebereichsintegrität (Integrität auf Datenfeldebene) und die Datenintegrität auf Datensatzebene (siehe Integritätsbedingung).
Inhaltsverzeichnis
Definition
Die referentielle Integrität befasst sich mit der Korrektheit zwischen Attributen von Relationen und der Erhaltung der Eindeutigkeit ihrer Schlüssel.
Die referentielle Integrität gewährleistet, dass in einer Detailtabelle die Fremdschlüssel nur solche Werte annehmen können, die in der referenzierten Mastertabelle der Beziehung bereits als Primärschlüssel angelegt worden sind.
Verwendung in Datenbanksystemen
Die Beziehungen werden zuvor in einem Datenbanksystem festgelegt. Das Datenbanksystem wird dann diese Beziehungen zwischen den Relationen garantieren. Lösch- oder Änderungsoperationen, die die Integrität verletzen würden, werden von der Datenbank nicht ausgeführt – eine zugehörige Transaktion wird zurückgefahren. So werden Inkonsistenzen im Datenbestand verhindert, d. h. werden in einer Datenbank einzelne Tabellen mit referentieller Integrität verbunden, so kontrollieren sich die Daten gegenseitig. Beispiel: In einer Lagertabelle können nur dann neue Waren aufgenommen werden, wenn zuvor der entsprechende Artikel mit seiner Artikelnummer (= Primärschlüssel) erfasst wurde. Wird der Artikel gelöscht, müssen auch die Artikelbestände in der Lagertabelle gelöscht werden, da sonst die Datenbank inkonsistent wird. (Allerdings wird man mit der Löschung sinnvollerweise warten, bis keine Lagerbestände mehr vorhanden sind.)
Technisch wird die referentielle Integrität zwischen zwei Relationen über einen so genannten Fremdschlüssel realisiert. Beide Relationen benötigen ein "gemeinsames" Attribut, das in der einen Relation ein Primärschlüssel und in der anderen Relation vom selben oder einem kompatiblen Datentyp sein muss. Die zweite Relation verweist („referenziert“) über diesen Fremdschlüssel auf den Primärschlüssel. Die Datenbank stellt sicher, dass dieser Primärschlüssel existiert und nur gemeinsam mit dem Fremdschlüssel geändert oder gelöscht werden kann.
Im Zusammenhang mit Tabellen bezeichnet man die Tabelle, auf deren Primärschlüssel verwiesen wird, als Parent-Tabelle. Die Tabelle, die den Fremdschlüssel enthält, bezeichnet man als Child-Tabelle. In der Literatur werden auch manchmal die deutschen Bezeichnungen Eltern-Tabelle und Kind-Tabelle sowie Mastertabelle und Detailtabelle verwendet.
Für Aktualisierungen des Primärschlüssels in der Mastertabelle sind folgende Optionen möglich:
- ON UPDATE CASCADE (Aktualisierungsweitergabe) bedeutet, dass die Aktualisierung auch an den Fremdschlüsseln der Detailtabelle vorgenommen wird.
- ON UPDATE RESTRICT (Aktualisierungsrestriktion) bedeutet: Wenn ein Schlüssel in der Mastertabelle geändert werden soll, und es existieren abhängige Sätze in der Detailtabelle, dann wird die Änderung verweigert.
Für Löschungen in der Mastertabelle sind folgende Optionen möglich:
- ON DELETE CASCADE (Löschweitergabe) bedeutet, es werden auch alle Sätze in der Detailtabelle gelöscht, die auf diesen Schlüssel referenzieren.
- ON DELETE RESTRICT (Löschrestriktion) bedeutet: wenn ein Satz in der Mastertabelle gelöscht werden soll, und es existieren abhängige Sätze in der Detailtabelle, dann wird die Löschung verweigert.
- ON DELETE SET NULL (Nullifies) bedeutet: wenn ein Satz in der Mastertabelle gelöscht werden soll, und es existieren abhängige Sätze in der Detailtabelle, dann wird in diese Fremdschlüssel NULL eingetragen. Voraussetzung ist hier, dass der Fremdschlüssel als optional-Spalte in der Tabelle definiert ist. (nicht mit NOT NULL)
Die verschiedenen Update- und Lösch-Optionen werden nicht von allen RDBMS unterstützt. Die Option ON UPDATE CASCADE z. B. wird von einigen RDBMS (z.B. Oracle) nicht angeboten. Der Grund dafür ist die Sichtweise, dass ein Primärschlüssel konstant und nicht veränderbar sein sollte.
Für die Detailtabelle bedeutet ein Fremdschlüssel die Restriktion, dass in diese Spalten nur Werte eingefügt (INSERT / UPDATE) werden dürfen, die in der Mastertabelle auch vorkommen. Einzige Ausnahme ist, wenn die Fremdschlüssel-Spalte als Optional-Spalte definiert ist. Dann kann hier auch NULL eingefügt werden, obwohl NULL niemals als Primärschlüssel in der Mastertabelle stehen wird.
Beispiel
Annahme, es wurden zwei Tabellen wie folgt in einer Datenbank angelegt:
Kunden 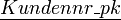
Name Ort Bestellung 1 Meier AG Marburg 2 Müller Bank Waldhausen * 3 Fa. Schaffel Woauchimmer 4 Kinder KG Kleckerdorf * Bestellungen Bestellnr 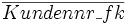
1 2 2 4 Weiter wurde definiert, dass die Kundennr in der Tabelle Kunden der Primärschlüssel und in der Tabelle Bestellungen der Fremdschlüssel (Foreign Key) ist.
Das Datenbankmanagementsystem sorgt dafür, dass:
- keine neue Bestellung ohne vorhandene Kundennr eingetragen werden kann.
- keine Kundensätze gelöscht werden können solange noch Bestellungen vorliegen. (Mit * markiert). Wurde allerdings die Löschweitergabe (DELETE CASCADE) eingestellt, werden alle Bestellsätze zum Kunden und der Kundensatz gelöscht.
- keine Kundennummern geändert werden können, ohne die abhängigen Bestellsätze mitzuändern (Update-Weitergabe) oder dass Änderungen an Kundennummern (bei den mit * markierten Sätzen) erst gar nicht zugelassen werden (Update-Restriktion).
SQL-Kommando zum Erstellen der Beziehung:ALTER TABLE Bestellungen ADD CONSTRAINT fk_bestellungen_kundennr FOREIGN KEY (kundennr_fk) REFERENCES Kunden (kundennr_pk) ON UPDATE RESTRICT ON DELETE RESTRICT
Fremdschlüssel aus mehreren Attributen
Primärschlüssel und Fremdschlüssel können auch aus mehreren Spalten bestehen. Beispiel:
CREATE TABLE p ( p1 INTEGER NOT NULL , p2 INTEGER NOT NULL , PRIMARY KEY (p1, p2) ) ; CREATE TABLE d ( d1 INTEGER NOT NULL , d2 INTEGER , d3 INTEGER , PRIMARY KEY (d1) , FOREIGN KEY (d2, d3) REFERENCES p ON DELETE CASCADE ) ;
Darstellung in Datenmodellen und Diagrammen
Leider wird die Pfeilrichtung bei einer graphischen Darstellung von den verschiedenen Autoren unterschiedlich verwendet. Einige zeichnen die Pfeile von der Mastertabelle zur Detailtabelle ein.
Kunden (Mastertabelle) | V Bestellungen (Detailtabelle)
Andere gehen von den Abhängigkeiten aus, die in der Datenbank definiert sind: der Fremdschlüssel in der Detailtabelle verweist auf den Primärschlüssel in der Mastertabelle.
Kunden (Mastertabelle) ^ | Bestellungen (Detailtabelle)
Kombination von Fremdschlüsseln
Grundsätzlich kann eine Detailtabelle gleichzeitig als Mastertabelle für eine andere Tabelle definiert werden. Dann sind aber nicht alle Kombinationen von Lösch-Weitergabe und Lösch-Restriktion zulässig (Ebenso bei der Update-Option). Das RDBMS prüft beim Ausführen der DDL-Befehle, ob die gewünschte Regel zulässig ist.
ist nicht zulässig:
Tabelle A (Mastertabelle) ^ | mit Löschweitergabe | Tabelle B (Detailtabelle von A) ^ | mit Lösch-Restriktion | Tabelle C (Detailtabelle von B)
ist zulässig:Tabelle A (Mastertabelle) ^ | mit Lösch-Restriktion | Tabelle B (Detailtabelle von A) ^ | mit Löschweitergabe | Tabelle C (Detailtabelle von B)
rekursive Fremdschlüssel
Fremdschlüsselbeziehungen können auch rekursiv definiert werden. Dabei verweist eine abhängige Spalte einer Tabelle auf den Primärschlüssel der eigenen Tabelle.
Beispiel
CREATE TABLE Abteilung ( AbtNr INTEGER NOT NULL , UebergeordneteAbt integer , AbtName VARCHAR(100) , PRIMARY KEY(AbtNr) , FOREIGN KEY (UebergeordneteAbt) REFERENCES Abteilung(AbtNr) ON DELETE CASCADE )
Rekursive Fremdschlüsselbeziehungen sind etwas problematisch in der Handhabung. Wenn Sätze eingefügt werden, dann muss das in einer bestimmten Reihenfolge geschehen.
Wenn Sätze gelöscht werden, dann kann es – bei Löschweitergabe – zur Löschung von wesentlich mehr Daten kommen, als in der WHERE-Bedingung angegeben:
DELETE FROM Abteilung WHERE AbtNr = 33
Es werden bei diesem Beispiel auch alle Sätze gelöscht, die der Abteilung 33 untergeordnet sind.
Wenn der Fremdschlüssel mit Lösch-Restriktion definiert wurde, dann wird nach jeder Löschung eines einzelnen Satzes geprüft, ob es keine Fremdschlüsselverletzung gibt. Selbst wenn alle Sätze aus der Tabelle entfernt werden sollen, kann es passieren, dass die Ausführung fehlschlägt.
DELETE FROM Abteilung
Das liegt daran, dass bei der Ausführung des DELETE-Statements die Sätze in einer beliebigen Reihenfolge gelöscht werden, meistens in der Reihenfolge, in der sie im Tablespace gespeichert sind. Nur wenn die Sätze exakt in der richtigen Reihenfolge (von der untersten Abteilung beginnend bis zur obersten Abteilung) gespeichert sind, dann kann die Ausführung des DELETE-Statements gelingen.
Dass der Erfolg eines SQL-Statements von der physischen Speicherreihenfolge der Sätze abhängig ist, darf in einem RDBMS nicht vorkommen. Daher bieten einige RDBMS die Möglichkeit der verzögerten Prüfung bei der Löschweitergabe.
Durch ein einziges DELETE-Statement können mehrere Sätze evtl. auch alle Sätze einer Tabelle gelöscht werden. Innerhalb einer Transaktion können mehrere DELETE-Statements ausgeführt werden. Standardmäßig wird die Prüfung, ob eine Lösch-Operation ausgeführt werden darf, ausgeführt, nach jedem einzelnen Satz, der gelöscht wurde. Das hat den Vorteil, dass bei einer unzulässigen Löschung gleich abgebrochen werden kann und der Rollback nicht unnötig viel zu tun hat.
Um die oben beschriebenen Lösch-Anomalien zu vermeiden, bieten einige RDBMS die Möglichkeit, die Prüfung, ob die Löschung zulässig ist, nicht nach jedem einzelnen Satz auszuführen, sondern
- nach der Löschung aller Sätze, die durch ein DELETE-Statement angewiesen werden (Diese Variante wird z. B. von DB2 angeboten durch die Option ON DELETE NO ACTION)
- erst zum Abschluss der Transaktion auszuführen. (Diese Variante wird z. B. von ORACLE angeboten durch die Option INITIALLY IMMEDIATE DEFERRABLE)
- einige RDBMS bieten auch die Möglichkeit, Fremdschlüssel-Beziehungen zu deaktivieren und später wieder zu aktivieren. Bei einer Aktivierung muss der gesamte Datenbestand der betroffenen Tabelle überprüft werden und es müssen Anweisungen erteilt werden, wie mit fehlerhaften Sätzen umgegangen werden soll.
- Mit Tools (z. B. Import, Load) kann man bei den meisten RDBMS Sätze in eine Tabelle laden ohne dabei die Fremdschlüssel-Beziehungen zu prüfen. Bei DB2 z. B. ist die Tabelle danach gesperrt und muss durch das CHECK-Tool geprüft werden. Erst dann steht die Tabelle wieder für reguläre Zugriffe zur Verfügung.
- wieder andere RDBMS lassen rekursive Fremdschlüsselbeziehungen erst gar nicht zu.
Nachteile
Die Vorteile der referentiellen Integrität haben aber auch ihren Preis, denn jede Prüfung, die von einem RDBMS vorgenommen wird, kostet CPU-Zeit.
Wenn in einer Parent-Tabelle ein Satz gelöscht wird, dann muss das RDBMS alle Child-Tabellen durchsuchen, und überprüfen, ob dieser Schlüssel noch irgendwo verwendet wird. Wenn die Child-Tabelle für die Spalte mit dem Fremdschlüssel keinen Index hat, dann müssen alle Sätze der Child-Tabelle durchsucht werden. Bei einem großen Datenvolumen ist dafür viel Zeit erforderlich (kann mehrere Minuten dauern).
Wenn in einer Child-Tabelle ein Satz eingefügt wird oder wenn ein Fremdschlüssel-Attribut geändert wird, dann muss das RDBMS auf die Parent-Tabelle zugreifen. Da bei den meisten Datenbank-Systemen für einen Primärschlüssel zwingend auch ein entsprechender Index angelegt werden muss, ist hier das Risiko eines langsamen Zugriffs nicht in gleicher Weise gegeben. Doch auch ein Index-Zugriff erfordert seine CPU-Zeit.
In der Praxis stellt sich oft die Aufgabe, große Datenmengen z. B. täglich aus einem System in ein anderes zu importieren. Wenn in dem Liefer-System die Konsistenz der Daten durch referentielle Integrität gesichert ist, dann kann man in dem aufnehmenden System auf die Definition von Fremdschlüsseln verzichten.
Ein weiterer Nachteil von referentieller Integrität ist das Generieren von Testdaten zur Validierung von Programmen. Wenn die Tabellen untereinander verknüpft sind, dann kann nicht eine Tabelle „mal eben“ mit Testdaten befüllt werden. Zuvor müssen alle übergeordneten Tabellen (Parent-Tabellen) mit Testdaten befüllt werden. Möglicherweise haben diese Tabellen selber weitere Fremdschlüssel und so weiter.
Siehe auch
Weblinks
Wikimedia Foundation.