- Schlüssel (Datenbank)
-
Ein Schlüssel dient in einer Relationalen Datenbank dazu, die Tupel einer Relation eindeutig zu identifizieren. Anschaulich kann man sich eine Relation als Tabelle vorstellen. Ein Schlüssel für eine solche Tabelle ist dann eine Gruppe von Spalten, die so ausgewählt wird, dass jede Zeile der Tabelle über den Werten dieser Spaltengruppe eine einmalige Wertekombination hat.
Inhaltsverzeichnis
Einführung
In der Theorie der relationalen Datenbanken sind pro Entität ein oder mehrere Schlüsselkandidaten erforderlich, welche definitionsgemäß eindeutig sein müssen. Von diesen Schlüsselkandidaten wird ein Kandidat als Primärschlüssel ausgewählt und bei der Umsetzung der Entität als Datenbanktabelle als solcher implementiert. Abweichend von dieser Konvention gibt es auch Datenbanksysteme, die Tabellendefinitionen erlauben, ohne dass ein Primärschlüssel definiert wird. Solche Tabellen erlauben damit auch doppelte Datensätze und sind damit definitionsgemäß keine relationale Entitäten.
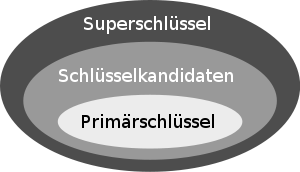 Superschlüssel ⊇ Schlüsselkandidaten, aus diesen wird der Primärschlüssel gewählt
Superschlüssel ⊇ Schlüsselkandidaten, aus diesen wird der Primärschlüssel gewählt
In Relationalen Datenbanken unterscheidet man die Schlüsselbegriffe
- Superschlüssel: Menge von Attributen (Feldern) in einer Relation (Tabelle), die die Tupel (Zeilen) in dieser Relation eindeutig identifizieren, also bei paarweise ausgewählten Tupeln immer unterschiedliche Werte enthalten (man sagt auch: „eindeutig sind“). Ein trivialer Superschlüssel wäre zum Beispiel die Menge aller Attribute einer Relation gemeinsam (trivial deswegen, weil eine Relation eine Menge von Tupeln ist. Die Elemente von Mengen müssen eindeutig sein, also darf es in einer Relation keine zwei gleichen Tupel geben)
- Schlüsselkandidat (auch Kandidatenschlüssel oder Alternativschlüssel genannt): Eine minimale Teilmenge der Attribute eines Superschlüssels, welche die Identifizierung der Tupel ermöglicht (Schlüsselkandidaten ⊆ Superschlüssel).
- Primärschlüssel: Der ausgewählte Schlüsselkandidat, der in Folge für die Abbildung der Relationen verwendet wird. Die Werte dieses Schlüssels werden in referenzierenden Tabellen als Fremdschlüssel verwendet.
Formale Definition
Es sei ein bestimmtes Relationenschema R (das Tabellen-Gerüst, d. h. alle Spalten) gegeben. Eine Teilmenge S der Attribute des Schemas R heißt Schlüssel, wenn gilt:
- Eindeutigkeit: Keine Ausprägung von R (keiner der Einträge in der Tabelle) darf zwei verschiedene Tupel (Zeilen) enthalten, bei denen die Werte von S gleich sind.
- Definitheit: alle Einträge der Tabelle müssen die Attribute aus S definieren, keiner der Einträge darf NULL sein.
- Minimalität: Keine echte Teilmenge von S erfüllt bereits die Bedingung der Eindeutigkeit.
Beispiele
a)
Literatur ISBN Autor Buchtitel … 0001 Hans V … 0002 Lutz W … 0003 Peter W … 0004 Peter X … 0005 Ralf Y … … … … … b)
Kunde Name Geburtstag Wohnort … Heinz Hoffmann 01.08.1966 Norden, BBS … Alf Appel 08.11.1957 Kassel … Sebastian Sonnenschein 04.08.1979 Hamburg … Klaus Schreiber 15.04.1970 Frankfurt … Barbara Schulze 17.10.1940 Kirchheim … … … … … c)
IstChefVon Vorgesetzter Untergebener 002 104 030 512 115 512 234 993 234 670 … … - a) Hier ist der Schlüssel ein einzelnes Attribut. Die ISBN eignet sich dafür sehr gut, denn keine zwei Bücher haben dieselbe ISBN. Bücher können allerdings sehr wohl den gleichen Titel haben oder vom selben Autor stammen.
- Anm: Die ISBN (International Standard Book Number) wird hier nur symbolisch als Laufnummer dargestellt, eine ISBN ist in Wirklichkeit komplizierter aufgebaut.
- b) Hier wird ein Teil der Attribute als Schlüssel verwendet. Der Entwickler der Datenbank geht davon aus, dass es keine Kunden gibt, die denselben Namen tragen und am selben Tag Geburtstag haben.
- c) Hier kommen nur alle Attribute der Relation als Schlüssel in Frage. Anhand der Personalnummer wird dargestellt, welcher Angestellte einer Firma Vorgesetzter welches anderen Angestellten ist.
Superschlüssel
Ein Superschlüssel (auch Oberschlüssel, engl. super key) ist eine beliebige Menge von Attributen, die die Tupel einer Relation eindeutig identifiziert. Die formale Definition lautet:
- Ist R(A) eine Relation über der Menge von Attributen
 , so gilt:
, so gilt:  ist genau dann ein Superschlüssel von R, wenn gilt:
ist genau dann ein Superschlüssel von R, wenn gilt:  .
.
Diese Definition setzt den Begriff der funktionalen Abhängigkeit (die Grundlage des Zeichens „
 “) voraus. bedeutet: Haben zwei Tupel die gleichen Werte in den Attributen von α, so haben sie auch die gleichen Werte in den Attributen A.
“) voraus. bedeutet: Haben zwei Tupel die gleichen Werte in den Attributen von α, so haben sie auch die gleichen Werte in den Attributen A.Anhand dieser Definition ergeben sich schon für kleine Anzahlen von Attributen sehr viele Superschlüssel. Für die Beispielrelationen der Einleitung sind dies die folgenden:
- a) {ISBN}, {ISBN, Autor}, {ISBN, Autor, Buchtitel}, {Autor, Buchtitel}, {Autor, Buchtitel, …}, {ISBN, Autor, Buchtitel, …}
- b) {Name, Geburtstag}, {Name, Geburtstag, Wohnort}, {Name, Geburtstag, Wohnort, …}
- c) {Vorgesetzter, Untergebener}
Besonders zu beachten ist, dass die Kombination aller Attribute einer Relation immer einen Superschlüssel bildet. Das kommt daher, dass Relationen keine zwei völlig identischen Tupel enthalten dürfen – denn eine Relation ist prinzipiell eine Menge und nach der Mengenlehre darf eine solche keine zwei identischen Elemente enthalten. Des Weiteren sind in dieser oft unüberschaubaren Menge auch die „praktischeren“ Schlüsselkandidaten enthalten. Der Begriff des Superschlüssels spielt allerdings bei den Definitionen der Normalformen 3. Normalform (3NF) und Boyce-Codd-Normalform (BCNF) eine wichtige Rolle.
Schlüsselkandidat
Ein Schlüsselkandidat (engl. candidate key) ist eine minimale Menge von Attributen, die die Tupel (Datensätze) einer Relation eindeutig identifiziert. Die formale Definition lautet:
- Ist R(A) eine Relation über der Menge von Attributen A: = {A1,...,An}, so gilt: ist genau dann ein Schlüsselkandidat von R, wenn gilt:
 .
.
Hierbei wird der Begriff der vollen funktionalen Abhängigkeit – dargestellt durch
– verwendet. Hier ist A von α voll funktional abhängig, was bedeutet:- Haben zwei Tupel in den Schlüsselattributen (α) dieselben Werte, so haben sie auch in allen übrigen Attributen (A) dieselben Werte. Und:
- Entfernt man ein Attribut aus α, so gilt Eigenschaft 1 nicht mehr.
Im Gegensatz zum Superschlüssel werden hier also nur noch diejenigen Attributmengen betrachtet, die nicht mehr verkleinert werden können, ohne ihre Schlüsseleigenschaft zu verlieren; man sagt auch, sie seien minimal identifizierend. Für die Beispielrelationen der Einleitung ergeben sich folgende Schlüsselkandidaten:
- a) {ISBN}, {Autor, Buchtitel}
- b) {Name, Geburtstag}
- c) {Vorgesetzter, Untergebener}
Aus der Liste der Superschlüssel wurden also gerade diejenigen ausgewählt, die minimal sind. Gelegentlich wird auch die Bezeichnung Kandidatenschlüssel verwendet, was eine wörtliche Übersetzung des englischen Fachbegriffs candidate key ist.
Primärschlüssel und Sekundärschlüssel
Um mitzuteilen, welchen der Schlüsselkandidaten man zur Identifikation der Tupel in einer Relation bevorzugt, wird aus allen Schlüsselkandidaten der Primärschlüssel ausgewählt. Der Primärschlüssel wird üblicherweise so ausgewählt, dass er möglichst klein ist, das heißt möglichst wenige Attribute umfasst. Er sollte zeitlich stabil sein, seine Werte sollten sich also während des gesamten Lebenszyklus der betroffenen Tabellen nicht ändern, da dies auch Änderungen an den zugehörigen Fremdschlüsselwerten mit sich zöge. Darüber hinaus muss der ausgewählte Primärschlüssel tatsächlich die eindeutige Identifizierbarkeit der realen Objekte erlauben, die durch die Tupel der Relation repräsentiert werden. Wählt man beispielsweise die Kombination {Name, Geburtstag} als Primärschlüssel aus, so legt man damit auch fest, dass es keine zwei gleichnamigen Personen geben darf, die am gleichen Tag Geburtstag haben. Durch die Einführung von Surrogatschlüsseln wird dieses Problem in jedem Fall vermieden. Für die Beispielrelationen aus der Einleitung bieten sich die folgenden Primärschlüssel an:
- a) {ISBN}
- b) {Name, Geburtstag}
- c) {Vorgesetzter, Untergebener}
Bei den Beispielen b) und c) ist die Entscheidung müßig, denn es gibt jeweils nur einen Schlüsselkandidaten, folglich muss dieser auch als Primärschlüssel verwendet werden. In Beispiel a) entscheidet man sich für {ISBN} als Primärschlüssel, weil dies der kleinste Schlüssel ist (er hat im Gegensatz zu {Autor, Buchtitel, …} nur ein Attribut), zudem wird dadurch die Realität genau wiedergegeben. Besteht ein Primärschlüssel aus mehreren Attributen, spricht man auch von einem kombinierten Primärschlüssel oder einem Verbundschlüssel. Durch die Auswahl des Primärschlüssels werden alle anderen Schlüsselkandidaten der Relation automatisch zu Sekundärschlüsseln. In unseren Beispielrelationen wären dies:
- a) {Autor, Buchtitel}
- b) keine
- c) keine
Sekundärschlüssel werden hauptsächlich dazu verwendet, effiziente Sekundärindizes zu erzeugen; ein Sekundärindex ist eine optionale Suchstruktur einer Datenbank, um Tupel schneller zu finden. Sekundärschlüssel müssen nicht notwendigerweise eindeutig sein, obwohl die nicht zum Primärschlüssel erhobenen, verbliebenen Schlüsselkandidaten es natürlich sind. Aber auch Fremdschlüssel sind Sekundärschlüssel, weil sie dazu dienen, Datensätze zu beschreiben (ordnen, gruppieren etc.).
Stellvertretender Schlüssel
Es ist möglich, dass alle Schlüsselkandidaten einer Relation aus mehreren Attributen bestehen, oder dass alle Schlüsselkandidaten die tatsächlichen Verhältnisse nur unzureichend widerspiegeln. Von unseren Beispielen ist b) ein solcher Fall. Will man in der Tabelle Kunde eine Person identifizieren, muss man stets Name und Geburtstag gleichzeitig angeben. Es ist daher oft wünschenswert, ein zusätzliches Attribut einzuführen, das als Primärschlüssel dient: Man nennt dies einen stellvertretenden Schlüssel (engl. surrogate key). Für Beispiel b) würden sich hier allgemeine Attribute wie „Personalausweis-Nummer“ oder geschäftseigene Identifikationsnummern wie „Kundennummer“ oder eine fortlaufende Nummer anbieten.
Fremdschlüssel
 Ein Primärschlüssel einer Relation kann Fremdschlüssel einer anderen werden
Ein Primärschlüssel einer Relation kann Fremdschlüssel einer anderen werdenEin Fremdschlüssel ist ein Attribut oder eine Attributkombination einer Relation, welches auf einen Primärschlüssel (bzw. Schlüsselkandidaten) einer anderen oder der gleichen Relation verweist.
Er dient als Verweis zwischen zwei Relationen, d. h. er zeigt an, welche Tupel der Relationen inhaltlich miteinander in Verbindung stehen. Beispiele für Fremdschlüssel sind die beiden Attribute „Vorgesetzter“ und „Untergebener“ aus der Beispielrelation c) der Einleitung: Hier wird jeweils die „Personalnummer“ eines Angestellten angegeben. Doch mit einer solchen Nummer lässt sich im Alltag eher wenig anfangen; viel wichtiger sind Name, Abteilung, Beschäftigung und ähnliche Informationen. Deshalb wird hier höchstwahrscheinlich eine weitere Relation existieren, die Attribute wie {Personalnummer, Name, Abteilung, Beschäftigung, …} enthält. Diese Relation wird ebenso höchstwahrscheinlich den Primärschlüssel {Personalnummer} besitzen; es bietet sich also an, Personalnummer als Fremdschlüssel zu benutzen.
Definition
Seien R, S Relationen und die Attributmenge α der Primärschlüssel von R. Wenn eine kompatible Attributmenge β aus S ein Fremdschlüssel bzgl. α sein soll, so müssen die Werte von β Teilmenge der Werte des Primärschlüssels α in R sein. (vgl. referentielle Integrität)
Eine Attributmenge ist dann kompatibel zu einer anderen, wenn die Wertebereiche der beteiligten Attribute gleich sind, also dom(α) = dom(β).
Fremdschlüssel und Beziehungstypen
In der Datenbankwelt unterscheidet man verschiedene Arten von Beziehungen zwischen zwei Relationen R und S. Der Begriff „Relation“ ist – für das bessere Verständnis – mit der Tabelle gleichzusetzen. Im Falle relationaler Datenbanken werden die folgenden Beziehungsarten unterschieden:
- 1:1-Beziehung, einem jeden Datensatz aus R ist maximal 1 Datensatz aus S zugeordnet; einem jeden Datensatz aus S ist maximal 1 Datensatz aus R zugeordnet
- 1:n-Beziehung, einem jeden Datensatz aus R ist/sind kein Datensatz, ein Datensatz oder mehrere Datensätze aus S zugeordnet; einem jeden Datensatz aus S ist maximal 1 Datensatz aus R zugeordnet
- n:m-Beziehung, einem jeden Datensatz aus R kann/können ein Datensatz oder mehrere Datensätze aus S zugeordnet sein; einem jeden Datensatz aus S kann/können mehrere Datensätze aus R zugeordnet sein.
Die Fälle 1. und 2. werden implementiert, indem S den Primärschlüssel aus R als Fremdschlüssel enthält. Im Falle der 1:1-Beziehung wird dies auch der Primärschlüssel. Für die n:m-Beziehung braucht man, wie in Beispiel c) oben, eine eigene Relation, die die Primärschlüssel beider Relationen als Fremdschlüssel erhält. Beide Attributmengen zusammen sind der Primärschlüssel dieser „Verknüpfungsrelation“.
Hinweis: Die eigentlichen sogenannten Kardinalitäten dieser drei Beziehungstypen sind 1:1 ⇒ [0,1]:[0,1], 1:n ⇒ [1,1]:[0,*] und n:m ⇒ [0,*]:[0,*]. Das Zeichen „*“ steht für „beliebig viele“.
Anderweitige Begriffsverwendungen
Folgende Begriffe sind keine Schlüssel im Sinne der relationalen Datenbanken:
- Suchschlüssel: Ein Attribut oder eine Attributkombination einer Relation, die als Suchkriterium dient. Ein Suchschlüssel muss nicht notwendigerweise auch ein identifizierender Schlüssel sein. Es können sich also auch mehrere Datensätze über den gleichen Schlüsselwert qualifizieren.
Schlüssel können auch nach der Kategorie ihrer Herleitung als natürliche oder künstliche Schlüssel unterschieden werden.
- sprechender Schlüssel (auch natürlicher Schlüssel genannt): Ein Schlüsselkandidat, der im Tupel auf natürliche Weise vorhanden ist. Ein solcher Schlüssel besitzt also auch in der realen Welt eine Bedeutung, wie z. B. „Fahrgestellnummer“ bei polizeilich zugelassenen Kfz. Bei sprechenden Schlüssel ist zu beachten, das die Schlüsseldomäne zerbrechen kann, falls die Felddomäne nicht mit Bedacht gewählt wird. So können etwa fünfstellige Kfz-Nummern aufgrund des Wachstums in den Neufahrzeugzulassungen irgendwann mal zu klein sein, was eine entsprechende Reorganisation der Schlüsselbezeichnungen erfordert. Wenn versucht wird, im Schlüssel auch sprechende Gruppenzuordnungen zu codieren, sind Schlüsselbrüche sehr wahrscheinlich, da die Nummernbereiche nicht fortlaufend verwendet werden. Darüber hinaus verletzt eine solche Praxis auch das Normalisierungsgebot, deshalb sollte eine Gruppenzuordnung über ein Attributfeld, oder gar eine N:M Zuordnungstabelle vorgenommen werden. Oft sind natürliche Schlüssel sinnvoll, um beispielsweise die Datensätze in der Chronologie ihrer Entstehung zu sortieren, oder werden vom Auftraggeber zwingend verlangt. Beispielsweise folgen die Kontennummern den Vorgaben des Kontenrahmens. Bei der Auslegung der Schlüsseldomäne sind Kriterien wie geplante Kardinalität, Lesbarkeit und Handhabung durch die Anwender genügend zu berücksichtigen.
- stellvertretender Schlüssel (Surrogatschlüssel) Ein künstlich erzeugtes, im Tupel zuvor gar nicht vorkommendes Attribut, das die Tupel der Relation identifiziert, das häufig als Primärschlüssel herangezogen wird. Triviales Beispiel: Fortlaufende Belegnummer. Surrogatschlüssel werden etwa in der OLAP-Technologie angewendet, wo sehr breite, zusammengesetzte Schlüssel auf einen kompakteren, künstlichen Surrogatekey umgeschlüsselt werden. In heterogenen Anwendungssystemen wird der Surrogatekey für eine bestimmte Entität vom hierzu gekennzeichneten führenden System vergeben. Werden Datensätze über Schnittstelle an Zweitsysteme durchgereicht, so müssen neben dem Schlüsselattribut, welches beispielsweise in einer Bewegungstabelle verwendet wird, allenfalls auch die zugehörige Entität mit den Stammdaten ans Zweitsystem übergeben werden.
Siehe auch
Literatur
- Andreas Heuer, Gunter Saake: Datenbanken. Konzepte und Sprachen. MITP Verlag, ISBN 3-8266-0619-1
- A. Eickler, A. Kemper: Datenbanksysteme. Oldenbourg Verlag, ISBN 3-486-27392-2

Wikimedia Foundation.