- Backpropagation
-
Backpropagation oder auch Backpropagation of Error bzw. auch Fehlerrückführung[1] (auch Rückpropagierung) ist ein verbreitetes Verfahren für das Einlernen von künstlichen neuronalen Netzen. Formuliert wurde es zuerst 1974 durch Paul Werbos. Bekannt wurde es allerdings erst 1986 durch die Arbeit von David E. Rumelhart, Geoffrey E. Hinton und Ronald J. Williams und führte zu einer „Renaissance“ der Erforschung künstlicher neuronaler Netze.
Es gehört zur Gruppe der überwachten Lernverfahren und wird als Verallgemeinerung der Delta-Regel auf mehrschichtige Netze angewandt. Dazu muss ein externer Lehrer existieren, der zu jedem Zeitpunkt der Eingabe die gewünschte Ausgabe, den Zielwert, kennt. Die Rückwärtspropagierung ist ein Spezialfall eines allgemeinen Gradientenverfahrens in der Optimierung, basierend auf dem mittleren quadratischen Fehler.
Inhaltsverzeichnis
Fehlerminimierung
Beim Lernproblem wird für beliebige Netze eine möglichst genaue Abbildung von gegebenen Eingabevektoren auf gegebene Ausgabevektoren angestrebt. Dazu wird die Qualität der Abbildung durch eine Fehlerfunktion beschrieben, die hier durch den quadratischen Fehler definiert wird:
 .
.Dabei ist
- E der Fehler,
- n die Anzahl der Muster, die dem Netz vorgestellt werden,
- ti die gewünschte Soll-Ausgabe oder Zielwert (target) und
- oi die errechnete Ist-Ausgabe (output).
Der Faktor
 wird dabei lediglich zur Vereinfachung bei der Ableitung hinzugenommen.
wird dabei lediglich zur Vereinfachung bei der Ableitung hinzugenommen.Das Ziel ist nun die Minimierung der Fehlerfunktion, wobei aber im Allgemeinen lediglich ein lokales Minimum gefunden wird. Das Einlernen eines künstlichen neuronalen Netzes erfolgt bei dem Backpropagation-Verfahren durch die Änderung der Gewichte, da die Ausgabe des Netzes – außer von der Aktivierungsfunktion – direkt von ihnen abhängig ist.
Algorithmus
Der Backpropagation-Algorithmus läuft in folgenden Phasen:
- Ein Eingabemuster wird angelegt und vorwärts durch das Netz propagiert.
- Die Ausgabe des Netzes wird mit der gewünschten Ausgabe verglichen. Die Differenz der beiden Werte wird als Fehler des Netzes erachtet.
- Der Fehler wird nun wieder über die Ausgabe- zur Eingabeschicht zurück propagiert. Dabei werden die Gewichtungen der Neuronenverbindungen abhängig von ihrem Einfluss auf den Fehler geändert. Dies garantiert bei einem erneuten Anlegen der Eingabe eine Annäherung an die gewünschte Ausgabe.
Der Name des Algorithmus ergibt sich aus dem Zurückpropagieren des Fehlers (engl. error back-propagation).
Herleitung
Die Formel des Backpropagation-Verfahrens wird durch Differenziation hergeleitet: Für die Ausgabe eines Neurons abhängig zweier Eingaben x und y erhält man eine zweidimensionale Hyperebene, wobei der Fehler des Neurons abhängig von den Gewichtungen wx der Eingabe x und wy der Eingabe y ist. Diese Fehleroberfläche enthält Minima, die es zu finden gilt. Dies kann nun durch das Gradientenverfahren erreicht werden, indem von einem Punkt auf der Oberfläche aus in Richtung des stärksten Abfallens der Fehlerfunktion abgestiegen wird.
Neuronenausgabe
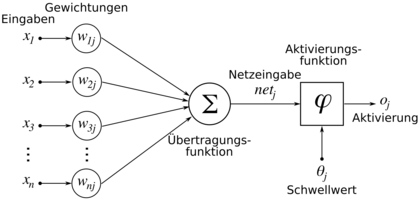 Künstliches Neuron mit Index j
Künstliches Neuron mit Index j
Für die Herleitung des Backpropagation-Verfahrens sei die Neuronenausgabe eines künstlichen Neurons kurz dargestellt. Die Ausgabe oj eines künstlichen Neurons j lässt sich definieren durch
- oj = φ(netj)
und die Netzeingabe netj durch
Dabei ist
- φ eine differenzierbare Aktivierungsfunktion,
- n die Anzahl der Eingaben,
- xi die Eingabe i und
- wij die Gewichtung zwischen Neuron i und Neuron j.
Auf einen Schwellwert θj wird hier verzichtet. Dieser wird meist durch ein immer "feuerndes" on-Neuron realisiert und das Gewicht zu diesem entsprechend mit dem konstanten Wert 1 belegt. Auf diese Weise entfällt eine Unbekannte.
Ableitung der Fehlerfunktion
Die partielle Ableitung der Fehlerfunktion E ergibt sich durch Verwendung der Kettenregel:
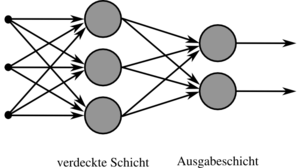 Einfaches Netz mit verdeckter Schicht und Ausgabeschicht mit jeweils drei bzw. zwei Neuronen.
Einfaches Netz mit verdeckter Schicht und Ausgabeschicht mit jeweils drei bzw. zwei Neuronen.Aus den einzelnen Termen kann nun die folgende Formel berechnet werden. Dabei ist die Herleitung im Gegensatz zur einfachen Delta-Regel abhängig von zwei Fällen:
- Liegt das Neuron in der Ausgabeschicht, so ist es direkt an der Ausgabe beteiligt,
- liegt es dagegen in einer verdeckten Schicht, so kann die Anpassung nur indirekt berechnet werden.
Konkret:
- mit
Dabei ist
- Δwij die Änderung des Gewichts wij der Verbindung von Neuron i zu Neuron j,
- η eine feste Lernrate, mit der die Stärke der Gewichtsänderungen bestimmt werden kann,
- δj das Fehlersignal des Neurons j,
- xi die Ausgabe des Neurons i,
- tj die Soll-Ausgabe des Ausgabeneurons j,
- oj die Ist-Ausgabe des Ausgabeneurons j und
- k der Index der nachfolgenden Neuronen von j.
Modifizierung der Gewichte
Die Variable δj geht dabei auf die Unterscheidung der Neuronen ein: Liegt das Neuron in einer verdeckten Schicht, so wird seine Gewichtung abhängig von dem Fehler geändert, den die nachfolgenden Neuronen erzeugen, welche wiederum ihre Eingaben aus dem betrachteten Neuron beziehen.
Die Änderung der Gewichte kann nun wie folgt vorgenommen werden:
 .
.
Dabei ist
 der neue Wert des Gewichts,
der neue Wert des Gewichts, der alte Wert des Gewichts und
der alte Wert des Gewichts und- Δwij die oben berechnete Änderung des Gewichts (basierend auf walt)
Erweiterung
Die Wahl der Lernrate η ist wichtig für das Verfahren, da ein zu hoher Wert eine starke Veränderung bewirkt, wobei das Minimum verfehlt werden kann, während eine zu kleine Lernrate das Einlernen unnötig verlangsamt.
Verschiedene Optimierungen von Rückwärtspropagierung, z. B. Quickprop, zielen vor allem auf die Beschleunigung der Fehlerminimierung; andere Verbesserungen versuchen vor allem die Zuverlässigkeit zu erhöhen.
Backpropagation mit variabler Lernrate
Um eine Oszillation des Netzes, d. h. alternierende Verbindungsgewichte zu vermeiden, existieren Verfeinerungen des Verfahrens bei dem mit einer variablen Lernrate η gearbeitet wird.
Backpropagation mit Trägheitsterm
Durch die Verwendung eines variablen Trägheitsterms (Momentum) α kann der Gradient und die letzte Änderung gewichtet werden, so dass die Gewichtsanpassung zusätzlich von der vorausgegangenen Änderung abhängt. Ist das Momentum α gleich 0, so hängt die Änderung allein vom Gradienten ab, bei einem Wert von 1 lediglich von der letzten Änderung.
Ähnlich einer Kugel, die einen Berg hinunter rollt und deren aktuelle Geschwindigkeit nicht nur durch die aktuelle Steigung des Berges, sondern auch durch ihre eigene Trägheit bestimmt wird, lässt sich der Backpropagation ein Trägheitsterm hinzufügen:
- Δwij(t + 1) = ηδjxi + αΔwij(t)
Dabei ist
- Δwij(t + 1) die Änderung des Gewichts wij(t + 1) der Verbindung von Neuron i zu Neuron j zum Zeitpunkt (t+1),
- η eine Lernrate,
- δj das Fehlersignal des Neurons j und
- xi die Eingabe des Neurons i,
- α der Einfluss des Trägheitsterms Δwij(t). Dieser entspricht der Gewichtsänderung zum vorherigen Zeitpunkt.
Damit hängt die aktuelle Gewichtsänderung (t + 1) sowohl vom aktuellen Gradienten der Fehlerfunktion (Steigung des Berges, 1. Summand), als auch von der Gewichtsänderung des vorherigen Zeitpunktes ab (eigene Trägheit, 2. Summand).
Durch den Trägheitsterm werden unter anderem Probleme der Backpropagation-Regel in steilen Schluchten und flachen Plateaus vermieden. Da zum Beispiel in flachen Plateaus der Gradient der Fehlerfunktion sehr klein wird, käme es ohne Trägheitsterm unmittelbar zu einem "Abbremsen" des Gradientenabstiegs, dieses "Abbremsen" wird durch die Addition des Trägheitsterms verzögert, so dass ein flaches Plateau schneller überwunden werden kann.
Sobald der Fehler des Netzes minimal wird, kann das Einlernen abgeschlossen werden und das mehrschichtige Netz ist nun bereit, die erlernten Muster zu klassifizieren.
Literatur
- David E. Rumelhart, Geoffrey E. Hinton und Ronald J. Williams: Learning representations by back-propagating errors. In: Nature, Band 323, S. 533-536
- Raúl Rojas Theorie der Neuronalen Netze, Springer 1996, ISBN 3-540-56353-9 E-Book der englischen Version, S. 151 ff
- Burkhard Lenze, Einführung in die Mathematik neuronaler Netze. Logos-Verlag, Berlin, 2003, ISBN 3-89722-021-0
- Robert Callan, Neuronale Netze im Klartext, Pearson Studium, München, 2003.
- Andreas Zell, Simulation neuronaler Netze, R. Oldenbourg Verlag, München, 1997, ISBN 3-486-24350-0
Weblinks
- Backpropagator's Review (lange nicht gepflegt)
- Ein kleiner Überblick über Neuronale Netze (D. Kriesel) - Größtes kostenloses Skriptum (knapp 200 Seiten, PDF, 4,6MB) in Deutsch zu Neuronalen Netzen. Sehr reich illustriert und anschaulich. Enthält ein Kapitel über Backpropagation samt Motivation, Herleitung und Variationen wie z.B. Trägheitsterm, Lernratenvariationen u.a.
- Membrain: freier Neuronale-Netze-Editor-und-Simulator für Windows
- Leicht verständliches Tutorial über Backpropagation mit Implementierungen (Englisch)
- Backpropagation in Ruby
Quellen
- ↑ Werner Kinnebrock: Neuronale Netze: Grundlagen, Anwendungen, Beispiele. R. Oldenbourg Verlag, München 1994, ISBN 3-486-22947-8




Wikimedia Foundation.