- Gradientenverfahren
-
Das Verfahren des steilsten Abstiegs, auch Gradientenverfahren genannt, ist ein Verfahren, das in der Numerik eingesetzt wird, um allgemeine Optimierungsprobleme zu lösen. Dabei geht man (am Beispiel eines Minimierungsproblemes) von einem Näherungswert aus. Von diesem schreitet man in Richtung des negativen Gradienten (der die Richtung des steilsten Abstiegs von diesem Näherungswert angibt) fort, bis man keine numerische Verbesserung mehr erzielt.
Das Verfahren konvergiert oftmals sehr langsam, da es sich dem Optimum entweder mit einem starken Zick-Zack-Kurs nähert oder der Betrag des Gradienten in der Nähe des Optimums sehr klein ist, wodurch die Länge der Iterationsschritte dann ebenfalls sehr klein ist. Für die Lösung von symmetrisch positiv definiten linearen Gleichungssystemen bietet das Verfahren der konjugierten Gradienten hier eine immense Verbesserung. Der Gradientenabstieg ist dem Bergsteigeralgorithmus (hill climbing) verwandt.
Inhaltsverzeichnis
Das Optimierungsproblem
Das Gradientenverfahren ist einsetzbar, wenn es um die Minimierung einer reellwertigen, differenzierbaren Funktion
 geht; also um das Optimierungsproblem
geht; also um das OptimierungsproblemHierbei handelt es sich um ein Problem der Optimierung ohne Nebenbedingungen, auch unrestringiertes Optimierungsproblem genannt.
Das Verfahren
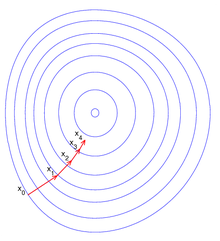 Illustration des Gradientenverfahrens
Illustration des Gradientenverfahrens
Ausgehend von einem Anfangspunkt x(0) wird die Richtung des steilsten Abstiegs durch die Ableitung
 bestimmt, wobei
bestimmt, wobei  den Nabla-Operator bezeichnet, dh. den Vektor der partiellen Ableitungen von f(x(j)) nach den Variablen
den Nabla-Operator bezeichnet, dh. den Vektor der partiellen Ableitungen von f(x(j)) nach den Variablen  . Dann wird wie folgt iteriert:
. Dann wird wie folgt iteriert:Hier ist
der negative Gradient von f, also die Abstiegsrichtung dieses Verfahrens, und α(j) bezeichnet die Schrittweite. Diese Schrittweite muss in jedem Schritt des Iterationsverfahrens bestimmt werden; hierfür gibt es unterschiedliche Möglichkeiten. Eine Methode besteht darin, α(j) durch die Minimierung der Funktion auf dem (eindimensionalen) "Strahl" x(j)(α) zu bestimmen, der ausgehend von x(j) in Richtung des negativen Gradienten zeigt:Man berechnet in diesem Fall also die Schrittweite durch
 . Dies ist ein einfaches eindimensionales Optimierungsproblem, für das es spezielle Verfahren der Schrittweitenbestimmung gibt.
. Dies ist ein einfaches eindimensionales Optimierungsproblem, für das es spezielle Verfahren der Schrittweitenbestimmung gibt.Das Verfahren wird auf dem Bild rechts illustriert. Hier ist
 auf der Ebene definiert (also eine Funktion von zwei Variablen), und der Graph der Funktion hat die Gestalt einer Schüssel mit einem minimalen Punkt. Die blauen Linien sind die Niveaulinien, d.h., die Linie, auf denen konstant ist. Ein roter Pfeil, der in einem Punkt beginnt, zeigt in die Richtung des negativen Gradienten in diesem Punkt; der Pfeil steht senkrecht auf der Niveaulinie, die durch den Punkt geht. Wir sehen, dass das Gradientenverfahren in dem illustrierten Fall an den tiefsten Punkt der "Schüssel" führt, das heißt an den Punkt, an dem der Wert der Funktion minimal ist.
auf der Ebene definiert (also eine Funktion von zwei Variablen), und der Graph der Funktion hat die Gestalt einer Schüssel mit einem minimalen Punkt. Die blauen Linien sind die Niveaulinien, d.h., die Linie, auf denen konstant ist. Ein roter Pfeil, der in einem Punkt beginnt, zeigt in die Richtung des negativen Gradienten in diesem Punkt; der Pfeil steht senkrecht auf der Niveaulinie, die durch den Punkt geht. Wir sehen, dass das Gradientenverfahren in dem illustrierten Fall an den tiefsten Punkt der "Schüssel" führt, das heißt an den Punkt, an dem der Wert der Funktion minimal ist.Spezialfall: Quadratische Funktionale
Typischerweise wird ein Energiefunktional der Form
minimiert. Dabei ist A eine symmetrisch positiv definite Matrix. Ausgehend von einem Anfangspunkt x(0) wird die Richtung des steilsten Abstiegs natürlich durch die Ableitung
 bestimmt, wobei den Nabla-Operator bezeichnet. Dann wird wie folgt iteriert
bestimmt, wobei den Nabla-Operator bezeichnet. Dann wird wie folgt iteriertα(j) bezeichnet die Schrittweite des Verfahrens und kann durch
berechnet werden. Das Verfahren konvergiert dann für einen beliebigen Startwert gegen einen Wert x * , so dass J(x * ) minimal ist.
Algorithmus in Pseudocode
Eingabe: geeigneter Startvektor

For k = 0 To n
end
Ausgabe: Minimum des Energiefunktionals.
Konvergenzgeschwindigkeit
Das Gradientenverfahren liefert eine Folge
 mit
mitDabei bezeichnet κ2 die Kondition der Matrix A.
Literatur
- Andreas Meister: Numerik linearer Gleichungssysteme. 2. Auflage. Vieweg, Wiesbaden 2005, ISBN 3-528-13135-7.










Wikimedia Foundation.