- Summenhäufigkeitsfunktion
-
Eine Empirische Verteilungsfunktion F(t) - auch Summenhäufigkeitsfunktion oder Verteilungsfunktion der Stichprobe genannt - ist definiert als die Summe der relativen Häufigkeiten derjenigen Stichprobenwerte/Merkmalsausprägungen, die kleiner oder gleich t sind.
Die Definition der Empirischen Verteilungsfunktion kann in verschiedenen Schreibweisen erfolgen. Dabei ist die eine Variante mehr an die Bedürfnisse der deskriptiven Statistik und die andere mehr an die der Wahrscheinlichkeitstheorie angepasst. Die Definition in der deskriptiven Variante stellt quasi eine praxistaugliche Version dar, während die wahrscheinlichkeitstheoretische Variante zusammen mit einem Satz von Glivenko-Cantelli eine mathematische Begründung dafür liefert, warum es überhaupt Sinn hat mit einer Empirischen Verteilungsfunktion zu arbeiten.Inhaltsverzeichnis
Definition (deskriptive Variante)
Seien
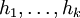 die relativen Häufigkeiten der reellen Merkmalsausprägungen
die relativen Häufigkeiten der reellen Merkmalsausprägungen 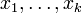 einer Stichprobe
einer Stichprobe 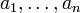 vom Umfang
vom Umfang 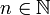 . Dann heißt die durch
. Dann heißt die durch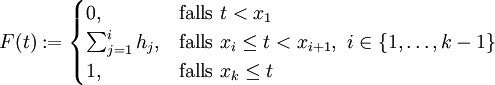
für alle
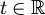 definierte Funktion
definierte Funktion ![F : \mathbb{R} \rightarrow [0,1]](/pictures/dewiki/99/cf3baffd063fb93293bd8cf660372a23.png) die Empirische Verteilungsfunktion (zur Stichprobe ).
die Empirische Verteilungsfunktion (zur Stichprobe ).
Die Empirische Verteilungsfunktionist eine Funktion aus der Deskriptiven Statistik. Sie dient der Visualisierung einer Stichprobe x. Die Funktion ordnet jeder Reellen Zahl t die Summe der Relativen Häufigkeiten hx(aj) derjenigen Zahlen aus der Stichprobe zu, die kleiner oder gleich groß wie t sind.
Definition (wahrscheinlichkeitstheoretische Variante)
Seien
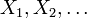 reelle Zufallsvariablen, also messbare Abbildung von einem Wahrscheinlichkeitsraum (Ω,Σ,P) in den Maßraum
reelle Zufallsvariablen, also messbare Abbildung von einem Wahrscheinlichkeitsraum (Ω,Σ,P) in den Maßraum 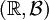 . Dann heißt die Abbildung
. Dann heißt die Abbildung![F_n(t,\omega) := \frac{1}{n} \sum_{j=1}^n 1_{(-\infty, t ]} \left( X_j(\omega) \right), \qquad t \in \mathbb{R}, ~ \omega \in \Omega,](/pictures/dewiki/101/e9979e7328c36db74f38ae6a6aa5d2b8.png)
die Empirische Verteilungsfunktion von X1,...,Xn.
Quellen
- ↑ Prof. Dr. N. Henze, Priv.-Doz. Dr. D. Kadelka. Skript zur Vorlesung Wahrscheinlichkeitstheorie und Statistik für Studierende der Informatik. Universität Karlsruhe, S. 11
- Bauer, Heinz: Wahrscheinlichkeitstheorie. Berlin - New York 2002
- Mayer, Horst: Beschreibende Statistik. München - Wien 1995
Siehe auch
![F_x : \mathbb{R} \rightarrow [0,1],\quad
t \rightarrow F_x(t) = \sum_{j:a_j \leq t} {h_x(a_j)}](/pictures/dewiki/97/a5ebb90b17320cb8de3636c3f09818af.png)
Wikimedia Foundation.