- Survival Analysis
-
Ereigniszeitanalyse ist eine statistische Analyse, bei der die Zeit bis zu einem bestimmten Ereignis ("time to event") zwischen zwei oder mehr Gruppen verglichen wird, um die Wirkung von prognostischen Faktoren, medizinischer Behandlung oder schädlichen Einflüssen zu schätzen. Das Ereignis kann dabei Tod sein, jedoch auch beliebige andere Endpunkte, wie Heilung, Erkrankung oder Eintreten einer Komplikation. Beispiele für eine solche Analyse sind der Kaplan-Meier-Schätzer oder die Cox-Regression. Eine zentrale Größe ist die Hazardrate.
Für dieses Verfahren gibt es ungewöhnlich viele verschiedene Bezeichnungen.
Inhaltsverzeichnis
Bezeichnungen für dieses Verfahren
Das Verfahren wurde von unterschiedlichen Autoren abweichend bezeichnet. Weil es verschiedene Anwendungszwecke gibt, sind heute noch verschiedene Begriffe in Gebrauch, die gleichwertig sind und oft synonym verwendet werden. Das Grundverfahren ist immer gleich.
- In der Statistik meist Überlebensanalyse, Überlebenszeitanalyse.
- In der empirischen Sozialforschung kennt man die Methode als Verweildaueranalyse (auch: Verlaufsdatenanalyse, Ereignisanalyse), wo sie sich mit Veränderungen in einem sozialen Zustand (z.B. Dauer der Ehe) beschäftigt.
- In den Ingenieurwissenschaften wird das Verfahren auch Zuverlässigkeitsanalyse genannt (engl. Reliability Theory).
- In englischen Programmen wird es als Survival Analysis, Analysis of Failure Times oder auch Event History Analysis bezeichnet.
Anwendungsbereiche
Dieses Verfahren kann immer eingesetzt werden, wenn eine Mortalität vorliegt, d.h. ein sukzessives Ausscheiden von Messobjekten aus der statistischen Erfassung. Es muss sich dabei nicht um den Tod handeln, sondern auch um den Ausfall mechanischer Systeme oder Eintritt in den Ruhestand. Auch beim Eintreten positiver Ereignisse, d.h. neuer Ereignisse für die es bisher keine Messgrundlage gab, kann das Verfahren angewendet werden. (Geburt des ersten Kindes, auftreten erster technischer Probleme oder Garantiefälle)
Beispiele für eine Ereigniszeitanalyse: Welcher Anteil einer Population wird nach einer gegebenen Zeit noch leben? Mit welcher Rate werden die Überlebenden dann sterben? Welche Eigenschaften oder Einflüsse erhöhen oder verringern die Überlebenswahrscheinlichkeit?
Zuerst ist es notwendig Ereigniszeit (Lebenszeit) zu definieren. Für biologische Systeme endet die Lebenszeit mit dem Tod. Schwieriger ist es mit der mechanischen Zuverlässigkeit. Ausfälle sind oft nicht klar definiert und können partiell sein. Oft ist es nur graduelles Versagen, das sich nicht so leicht zeitlich festlegen lässt. Ähnliche Schwierigkeiten treten bei anderen biologischen Ereignissen auf. Beispielsweise sind ein Herzanfall oder ein Organversagen schwierig zeitlich festzulegen.
Üblicherweise werden nur Ereignisse untersucht, die höchstens ein Mal pro Subjekt auftreten können. Eine Erweiterung auf wiederholt auftretende Ereignisse ist möglich.
Allgemeines
Überlebensfunktion
Die zentrale Funktion ist die Überlebensfunktion (engl.: Survival Function, Survivor Function). Sie wird üblicherweise mit S bezeichnet und ist definiert als
- S(t) = P(T > t)
dabei ist t eine beliebige Zeit, T ist die Zeit bis zum Tod, und P bezeichnet die Wahrscheinlichkeit. Die Überlebensfunktion beschreibt die Wahrscheinlichkeit dafür, dass die Zeit bis zum Tod länger als t ist. Im Bereich technischer Systeme wird für diese Funktion auch die Bezeichnung Zuverlässigkeitsfunktion (engl.: Reliability Function) verwendet. Dann bezeichnet man sie mit R(t).
Im allgemeinen geht man davon aus, dass S(0) = 1 ist. Falls ein sofortiger Tod oder Ausfall möglich ist, dann kann dieser Startwert auch kleiner als 1 sein. Die Überlebensfunktion muss monoton fallend sein: S(u) <= S(t) falls u > t. Ist diese Funktion bekannt, dann sind auch die Verteilungsfunktion F und die Dichtefunktion f eindeutig definiert.
Üblicherweise geht man davon aus, dass die Überlebensfunktion mit wachsendem Alter gegen Null fällt: S(t) → 0 falls t → ∞. Ist diese Grenze größer als Null, so ist ewiges Leben möglich.
Ereigniszeit-Verteilungsfunktion und Ereignisdichtefunkton
Aus der Überlebensfunktion lassen sich verwandte Größen ableiten. Die Ereigniszeit-Verteilungsfunktion, bezeichnet mit "F", ist die komplementäre Funktion zur Überlebensfunktion,
und die erste Ableitung von F, die Ereignisdichtefunktion, wird mit f bezeichnet.
Die Ereignisdichtefunktion ist die Rate des betrachteten Ereignisses pro Zeiteinheit.
Hazardfunktion und kumulierte Hazardfunktion
Die Hazardfunktion h(t) ist definiert als die Wahrscheinlichkeit, mit der ein Ereignis zum Zeitpunkt T eintritt unter der Voraussetzung, dass es bis zum Zeitpunkt t noch nicht eingetreten ist.
Force of mortality ist ein Synonym für "Hazardfunktion" welches speziell in der Demografie verwendet wird.
Die Hazardfunktion muss stets positiv sein, h(t) > 0 und das Integral über [0,∞) muss unendlich sein. Die Hazardfunktion kann anwachsen oder fallen, sie braucht weder monoton noch stetig zu sein.
Alternativ kann die Hazardfunktion auch durch die kumulative Hazardfunktion H ersetzt werden.
damit ist
H heißt kumulative Hazardfunktion da
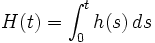 gilt.
gilt.
Sie beschreibt die "Ansammlung" von Hazard (Risiko) im Laufe der Zeit.
Aus H(t) = − logS(t) folgt, dass H(t) mit wachsender Zeit t unbegrenzt wächst falls S(t) gegen Null geht. Weiter folgt, dass h(t) nicht zu stark fallen darf, weil sonst die kumulierte Hazardfunktion gegen einen endlichen Wert konvergiert. Beispielsweise ist exp( − t) keine Hazardfunktion irgendeiner Ereigniszeitverteilung, da das Integral konvergiert.
Aus der Überlebensfunktion abgeleitete Größen
Die verbleibende Lebenszeit zu einem Zeitpunkt t0 ist die bis zum Tod verbleibende Zeit also T − t0. Die zukünftige Lebenserwartung ist der Erwartungswert der verbleibenden Lebenszeit. Die Ereignisdichtefunktion für den Zeitpunkt t + t0 unter der Voraussetzung des Überlebens bis t0 ist gerade
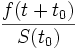 .
.
Damit ist die zukünftige Lebenserwartung
 oder
oder
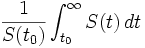 .
.
Für t0 = 0 reduziert sich dies auf die Lebenserwartung bei der Geburt.
In Zuverlässigkeitsanalysen wird die Lebenserwartung mean time to failure und die zukünftige Lebenserwartung "mean residual lifetime" genannt.
Das Alter in dem der Anteil der Überlebenden einen vorgegebenen Wert q erreicht, kann man über die Gleichung S(t) = q ermitteln. t ist das gesuchte Quantil. Meist ist man an Größen wie dem Median der Lebensdauer q = 1/2 oder anderen Quantilen wie q = 0,90 oder q = 0,99 interessiert.
Beispiele für Überlebensfunktionen
Für Ereigniszeitmodelle wählt man zuerst eine grundlegende Überlebensfunktion aus. Es ist relativ einfach eine Verteilungsfunktion durch eine andere zu ersetzen um die Auswirkungen zu studieren. An der grundlegenden Theorie ändert sich nichts.
Bei der Wahl der konkreten Verteilung spielen Vorkenntnisse über den konkreten Prozess ein große Rolle. Es ist in etwa analog zur Auswahl der Linkfunktion in verallgemeinerten linearen Modellen (vergl. dazu.: Generalisierte Lineare Modelle oder engl.: Generalized linear model nicht zu verwechseln mit dem engl.: General linear model). Einige häufig verwendete Funktionen sind im Folgenden aufgelistet.
Schätzen der Parameter
Ereigniszeitmodelle kann man als normale Regressionsmodelle betrachten in der die Ergebnisvariable die Zeit ist. Die Berechnung der Likelihood-Funktion ist kompliziert, da nicht zu jeder Zeit alle Informationen zur Verfügung stehen.
Wenn Geburt und Tod bekannt sind, dann ist in diesem Fall der Lebensverlauf eindeutig. Wenn man dagegen nur weiß, dass die Geburt vor einem bestimmten Zeitpunkt stattfand, dann nennt man diesen Datensatz links zensiert. Genauso könnte nur bekannt sein, dass der Tod nach einem bestimmten Datum eintrat. Das ist dann einen rechts zensierter Datensatz. Ein Lebenslauf kann auf diese Weise auch rechts und links zensiert sein (intervallzensiert). Falls eine Person die ein bestimmtes Alter nicht erreicht, überhaupt nicht beobachtet wird, dann ist der Datensatz abgeschnitten (engl.: truncated). Bei einem links zensierten Datensatz wissen wir dagegen zumindest, dass das Individuum existierte.
Es gibt einige Standardfälle für zensierte und abgeschnittene Datensätze. Üblich ist ein rechts zensierter Datensatz. Betrachten wir eine Gruppe lebender Subjekte, dann wissen wir, dass sie heute am Leben sind. Wir wissen aber nicht ihren in der Zukunft liegenden Todestag. Links zensierte Daten sind auch üblich. Wir könnten für jedes Subjekt wissen, dass es heute lebt, aber wir kennen nicht den genauen Geburtstag. Abgeschnittene Daten treten in Studien mit verzögertem Anfang auf. Rentner könnten beispielsweise ab dem Alter 70 Jahre beobachtet werden. Über die Personen die vorher gestorben sind ist nicht einmal deren Existenz bekannt.
Die Likelihood-Funktion für ein Ereigniszeitmodell mit zensierten Daten kann wie folgt definiert werden. Definitionsgemäß ist die Likelihood-Funktion die gemeinsame Wahrscheinlichkeit der Daten bei vorgegebenen Modellparametern. Es ist üblich anzunehmen, dass die Daten unabhängig von den Parametern sind. Dann ist die Likelihood-Funktion das Produkt der Wahrscheinlichkeiten für jede Ereigniszeit. Wir teilen die Daten in vier Kategorien ein: unzensierte, links zensierte, rechts zensierte und intervallzensierte Daten. Wir unterscheiden sie in den Formeln mit "unz.", "l.z.", "r.z." und "i.z.".
Für eine unzensierte Ereigniszeit mit dem Todesalter ti verwenden wir
- P(T = ti | θ) = f(ti | θ).
Für links zensierte Daten wissen wir nur, dass der Tod vor einer Zeit ti eintrat
- P(T < ti | θ) = F(ti | θ) = 1 − S(ti | θ).
Für ein rechts zensiertes Individuum wissen wir das der Tod nach der Zeit ti eintritt, also ist
- P(T > ti | θ) = S(ti | θ)
Und für intervallzensierte Ereignisse wissen wir, dass der Tod zwischen Ti,r und Ti,l eintritt
- P(ti,l < T < ti,r | θ) = S(ti,l | θ) − S(ti,r | θ)
Siehe auch
Literatur
- Regina Elandt-Johnson und Norman Johnson. Survival Models and Data Analysis. New York: John Wiley & Sons. 1980/1999.
- Jerald F. Lawless. Statistical Models and Methods for Lifetime Data, 2nd edition. John Wiley and Sons, Hoboken. 2003.
- Terry Therneau. "A Package for Survival Analysis in S". http://mayoresearch.mayo.edu/mayo/research/biostat/upload/survival.pdf, zu finden unter http://mayoresearch.mayo.edu/mayo/research/staff/therneau_tm.cfm .
Weblinks
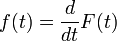
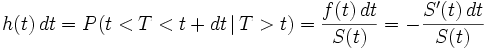
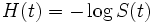
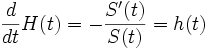
![\begin{matrix}
&amp; S(t) \\
\\
\text{Exponentialverteilung} &amp; e^{-t} \\
\\
\text{Weibull} &amp; e^{-(t/\lambda)^k} \\
\\
\text{Lognormal} &amp; \frac{1}{2}\left(1-\operatorname{erf}\left[\frac{\ln(t)-\mu}{\sigma\sqrt{2}} \right]\right)
\end{matrix}](/pictures/dewiki/98/b2728286377bff008f9708eb588e162b.png)
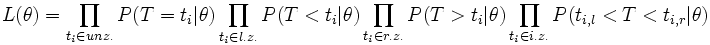
Wikimedia Foundation.