- Berkeleys offene Infrastruktur für verteiltes Rechnen
-
BOINC 
Der BOINC-Client für LinuxBasisdaten Entwickler: Universität Berkeley Aktuelle Version: 6.6.20
(9. April 2009)Aktuelle Vorabversion: 6.6.26
(1. Mai 2009)Betriebssystem: Windows, Mac OS X, Linux, Solaris, diverse Unix-Derivate Kategorie: Bereitstellung von Rechenleistung Lizenz: GPL/LGPL Deutschsprachig: ja boinc.berkeley.edu Die Berkeley Open Infrastructure for Network Computing (kurz BOINC) ist eine Software-Plattform für verteiltes Rechnen.
Die BOINC-Plattform wird an der Universität Berkeley entwickelt und ermöglicht es, die ungenutzte Rechenleistung von vielen tausend Computern über das Internet oder Intranet, zum Beispiel in Unternehmen und Institutionen, verfügbar zu machen.
Inhaltsverzeichnis
Details
Bei der Entwicklung von BOINC wurden Erfahrungen des Distributed-Computing-Projekts SETI@home genutzt. Das Hauptziel der Plattform ist die Trennung der Projektverwaltung von den wissenschaftlichen Inhalten.
Anwender dieser Plattform installieren sich ein Clientprogramm und können damit ihre freie Rechenzeit auf mehrere Projekte verteilen. Dies stellt eine wichtige Verbesserung gegenüber an nur ein Projekt gebundenen Clients dar, da viele Distributed-Computing-Projekte nicht über genügend Arbeit verfügen, um eine große Benutzerbasis ausreichend zu versorgen. Wenn ihre Rechner leerlaufen, werden die teilweise sehr enthusiastischen Teilnehmer unzufrieden. SETI@home classic umging dieses Problem, indem manche Arbeitspakete bis zu zwölfmal zur Berechnung herausgegeben wurden, obwohl zur Sicherung von akkuraten wissenschaftlich verwertbaren Resultaten nur drei Ergebnisse notwendig wären. Mit einem an mehreren Projekten teilnehmenden BOINC-Client kann die zur Verfügung stehende Rechenleistung somit effektiver verwendet werden.
Seit dem 18. November 2003 steht BOINC unter der GNU General Public License. Das Ziel der Freigabe des Programmcodes ist eine noch breitere Unterstützung verschiedener Plattformen durch aktive Mithilfe der freien Softwaregemeinde und eine erhöhte Sicherheit.
Seit der Version 6.4.5 wird die CUDA-Technologie von Nvidia unterstützt. Damit ist es möglich, die Rechenleistung von Grafikkarten des Herstellers mit CUDA-Unterstützung zu nutzen.
Bestandteile
Teilnehmerseitig
- Core-Client: Der Core-Client ist ein auf dem Teilnehmerrechner im Hintergrund laufendes Kommandozeilen-Programm. Er steuert und überwacht die wissenschaftlichen Anwendungen gemäß den Vorgaben des Teilnehmers, puffert Arbeitspakete und kommuniziert mit den Schedulern und Datenservern der Projekte. Der Core-Client kann, neben Windows, theoretisch auch auf jedes Unix-artige Betriebssystem portiert werden, ist für sich allein genommen jedoch recht nutzlos, wenn für die jeweilige Plattform keine wissenschaftlichen Anwendungen zur Verfügung stehen.
- BOINC Manager: Der BOINC Manager ist eine grafische Oberfläche zur Konfiguration und Überwachung des Core-Clients. Er basiert auf dem wxWidgets-Toolkit und ist damit auf allen Plattformen lauffähig, die von wxWidgets unterstützt werden.
- Boinc-Commandline-Interface: das Programm boinc_cmd erlaubt es, den Core-Clienten über die Kommandozeile zu steuern, beispielsweise wenn keine grafische Oberfläche verfügbar ist (wie bei Servern).
- Projektanwendungen: Jedes Projekt stellt Anwendungen bereit, die vom Core-Client heruntergeladen und zur Berechnung der Arbeitspakete verwendet werden. Diese werden zur Laufzeit vom Core-Client mittels Shared Memory überwacht. Die Funktionen für diese Überwachung werden in der von BOINC mitgelieferten Programmierschnittstelle (BOINC-API) bereitgestellt.
Bei älteren Programmversionen ist der Core-Client sowohl in den grafischen BOINC-Manager, als auch in das Kommandozeilen-Interface integriert. Bei aktuellen Versionen kommuniziert der separate Core-Client über Shared Memory mit den Steuerungsprogrammen.
Serverseitig
Das vom jeweiligen Projekt zur Verfügung gestellte Backend basiert auf einem Webserver, PHP als Skriptsprache und einer MySQL-Datenbank. Bei großen Projekten können die Backend-Dienste auf mehrere Server verteilt sein. Einige Projekte verwenden Perl oder ASP anstelle von PHP für das Backend, dies sind Eigenentwicklungen der Projekte, die das von Berkeley vorgegebene Kommunikationsprotokoll nachbilden.
- Scheduler: Der Scheduler ist ein CGI-Programm auf dem Webserver des Projekts. Er teilt den Teilnehmer-Clients ihre Arbeitspakete zu und nimmt nach getaner Arbeit eine kurze Meldung über Erfolg/Misserfolg entgegen. Über alle Aktivitäten führt er in der Datenbank Buch.
- Datenserver: Ein einfacher HTTP-Server, von dem die Clients ihre vom Scheduler zugeteilten Arbeitspakete herunterladen und die Ergebnisdateien hochladen.
- Validator: Der Validator (ein für jedes Projekt unterschiedliches Programm) prüft die von den Clients zurückgelieferten Ergebnisdateien auf Korrektheit. Meist geschieht dies dadurch, dass ein Arbeitspaket von mehreren Teilnehmern redundant bearbeitet wird. Der Validator vergleicht dann die Ergebnisse. Idealerweise sind sie identisch.
- Assimilator: Ein projektspezifisches Programm. Nimmt validierte Ergebnisdateien und bereitet sie zur weitergehenden wissenschaftlichen Analyse auf. Dazu können die Ergebnisse beispielsweise in eine weitere Datenbank archiviert werden.
- File-Deleter: Nachdem die Ergebnisse „assimiliert“ wurden, sind die Input- und Output-Dateien der Clients unnötiger Ballast für den Datenserver, die durch ihre Anzahl auch seine Performance beeinträchtigen können. Mit dem File-Deleter werden nicht mehr benötigte Dateien vom Server gelöscht.
- Transitioner: Der Transitioner überwacht den Fortschritt der Arbeitspakete entlang einer gedachten Pipeline. So stößt er beispielsweise den Validator an, wenn er feststellt, dass zu einem Arbeitspaket genügend redundante Ergebnisse vorliegen, so dass mit der Validierung begonnen werden kann.
Funktionen
Das Verhalten des BOINC-Frameworks kann an die Bedürfnisse verschiedener Projekte angepasst werden. Zu den Funktionen, die nur von einigen Projekten genutzt werden, gehören:
- Homogene Redundanz: Einige wissenschaftliche Anwendungen reagieren empfindlich auf numerische Differenzen, die sich auf unterschiedlichen Teilnehmerrechnern ergeben können. Die Ursachen dafür können in den Betriebssystemen, den Prozessoren oder den verwendeten Compilern liegen. Kleine Unterschiede in der Rundung oder Gleitkomma-Implementation können dabei zu völlig unterschiedlichen Ergebnissen führen. Im Falle von Predictor@home stellte man beispielsweise fest, dass Intel- und AMD-Prozessoren häufig unterschiedliche Proteinfaltungen errechneten. Keiner der Prozessoren hatte dabei „falsch“ gerechnet, da man Proteinstrukturen ohnehin nur statistisch annähern kann, aber die Unterschiede waren signifikant genug, um den Validator aus dem Tritt zu bringen. LHC@home hat das Problem für sich durch eine neue plattformunabhängige Mathe-Bibliothek lösen können. BOINC-seitig besteht die Möglichkeit, ein Arbeitspaket jeweils nur identischen Plattformen zuzuteilen. Ein Arbeitspaket für „Windows/AMD“ wird dann nur von Rechnern mit dieser Ausstattung bearbeitet.
- Locality Scheduling: Bei einigen Projekten sind die Input-Dateien der Arbeitspakete sehr groß. Das belastet die Netzwerkanbindung des Projekts. Manche Projekte haben jedoch den Vorteil, dass für viele Arbeitspakete die gleichen Input-Dateien benötigt werden. Dann kann durch Locality Scheduling der Netzwerkverkehr reduziert werden. Ein Client bekommt in diesem Fall bevorzugt Arbeitspakete zugeteilt, zu denen er angibt, dass er die benötigten Input-Dateien bereits vorliegen hat. Diese Technik wird derzeit vor allem von Einstein@home verwendet.
- Trickles (engl. für Tröpfchen) sind kleine XML-Dateien, mit denen die Projektanwendung den Scheduler über den Fortschritt von sehr lange laufenden Berechnungen unterrichten kann. ClimatePrediction.net benutzt zum Beispiel Arbeitspakete, deren Fertigstellung Wochen oder sogar Monate dauern kann. So lange möchten die Benutzer aber nicht auf Creditpunkte warten. Durch diese Trickles unterrichtet der Core-Client den Scheduler über den Arbeitsfortschritt, so dass bereits Creditpunkte vergeben werden können, während das Paket noch in Arbeit ist.
- Datenarchivierung: Bis zu einer vom Teilnehmer festlegbaren Grenze können Projekte die Festplatte des Teilnehmerrechners zur Archivierung alter Input- oder Output-Daten verwenden. Das Projekt kommt an die Daten jedoch nicht ohne Kooperation des Teilnehmers heran. Diese Möglichkeit wurde zeitweise von ClimatePrediction.net verwendet, es handelte sich um Datenmengen im Bereich von einigen 100 MB. Inzwischen gibt es Projektkonzepte, die sich ausschließlich mit der verteilten Archivierung mit BOINC befassen, bisher ist aber kein derartiges Projekt öffentlich verfügbar.
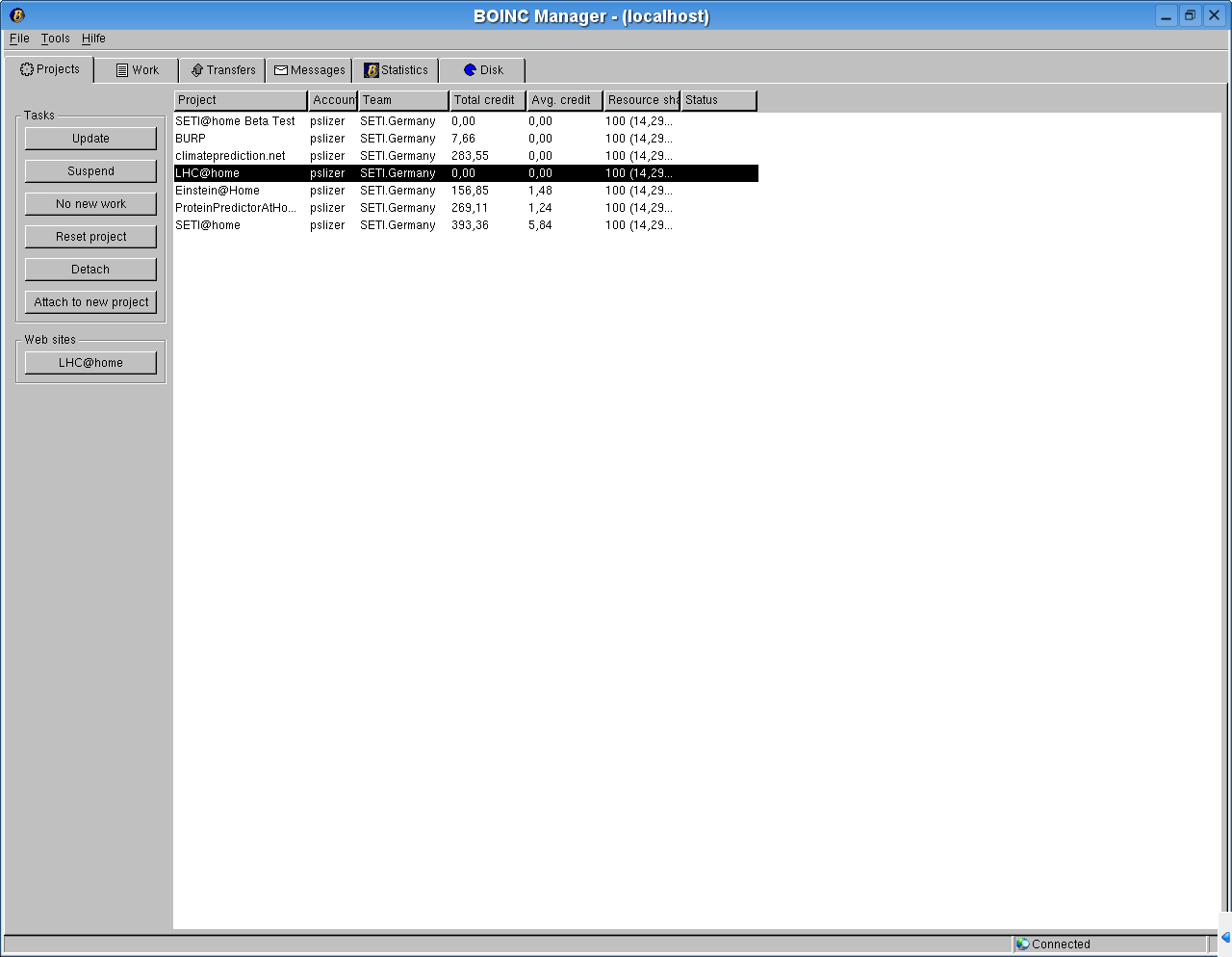
Projekte
Auf dem Rechner muss lediglich die BOINC-Software installiert werden. Nach der Registrierung bei einem oder mehreren der Projekte lädt BOINC sich selbständig die benötigte Projektsoftware herunter und beginnt den eigentlichen Rechenprozess. Inzwischen steht eine breite Auswahl an Projekten zur Verfügung oder wird gerade entwickelt:
Die Projekte wie SETI@home und weitere sind in der Liste der Projekte verteilten Rechnens zu finden.
Kritik an der Leistungsbewertung
Die faire Bewertung der geleisteten Arbeit in Form von sogenannten Credit-Punkten (englisch: credit) hat sich als nicht trivial herausgestellt. Die Einheit der Credit-Punkte ist der nach Jeff Cobb vom SETI@home-Projekt benannte Cobblestone (zu deutsch: Kopfsteinpflaster). 100 Cobblestones entsprechen 24 Stunden Rechenzeit einer hypothetischen VAX mit je 1000 Whetstone- oder Dhrystone-MIPS. Der Core-Client prüft periodisch die Leistung des jeweiligen Rechners mit entsprechenden Benchmarks und errechnet daraus bei Fertigstellung eines Arbeitspakets (englisch: Workunit) den Claimed Credit – das ist die Anzahl von Credit-Punkten, welche nach seiner Meinung vom Projekt für ein Arbeitspaket gutgeschrieben werden müssten. Dieser Ansatz leidet bereits darunter, dass der Core-Client auf zahlreichen Rechnerarchitekturen laufen kann und dabei mit unterschiedlichen Compilern gebaut wird, welche die Benchmarks im Client unterschiedlich optimieren. Der Claimed Credit ist für dasselbe Arbeitspaket auf unterschiedlichen Rechnern nie der gleiche. Darüber hinaus ist es möglich, die Benchmark-Routinen auf Ebene des Quelltexts so zu manipulieren, dass der Client einen höheren Claimed Credit einfordert. Die Projektsoftware kann dies teilweise dadurch abfangen, dass bei drei identischen Ergebnissen zu einem Arbeitspaket die höchste und die niedrigste Credit-Forderung gestrichen wird und allen drei Teilnehmern der mittlere Claimed Credit gutgeschrieben wird. Projekte mit Arbeitspaketen von bekannter Länge sind inzwischen teilweise dazu übergegangen, den Claimed Credit völlig zu ignorieren und pro Arbeitspaket eine feste, zum Beispiel auf einem Test-Rechner ermittelte Anzahl Credits gutzuschreiben. Dabei ergibt sich allerdings das Phänomen, dass für den gleichen Zeitaufwand bei verschiedenen Projekten eine unterschiedliche Zahl von Credits gutgeschrieben wird, so dass es aus Teilnehmersicht Projekte gibt, welche sich unter Credit-Gesichtspunkten mehr lohnen als andere.[1]
Weblinks
- Offizielle BOINC-Webseite (englisch)
Externe Quellen
- ↑ Project credit comparison (englisch, sehr groß) – Relative Credit-Vergabe der Projekte, bei BOINCstats
Wikimedia Foundation.