- Blue Gene/P
-
 Ein BlueGene/L-Schrank
Ein BlueGene/L-SchrankBlueGene ist ein Projekt, eine High-End-Computertechnik zu entwerfen und zu bauen. Laut IBM sowohl zur Erforschung der Grenzen des Supercomputing: in der Computerarchitektur, der zur Programmierung und Kontrolle massiv paralleler Systeme nötigen Software und um die Rechenkraft zur Erlangung eines besseren Verständnisses biologischer Prozesse wie etwa der Proteinfaltung zu nutzen [1]. Letzteres war auch für die Namensgebung verantwortlich.
Im Dezember 1999 kündigte IBM ein auf fünf Jahre angelegtes Programm an, einen massiv parallelen Computer zu bauen, der bei der Erforschung biomolekularer Phänomene wie der Proteinfaltung helfen soll. Zielvorgabe war dabei, Geschwindigkeiten im Peta-FLOPS-Bereich zu erreichen.
Es handelt sich um ein kooperatives Projekt zwischen dem US-Energieministerium (welches das Projekt teilweise auch finanziert), der Industrie (insbesondere IBM), und den Hochschulen. In der Entwicklung befinden sich fünf BlueGene-Projekte, darunter BlueGene/L, BlueGene/P und BlueGene/Q (siehe Advanced Simulation and Computing Program).
Als erste Architektur war BlueGene/L vorgesehen. Die Vorgaben lagen bei einem System mit einer Spitzenleistung von 360 TFLOPS auf 65.536 Nodes und Fertigstellung 2004/2005. Die darauffolgenden Maschinen sollen bis zu 1000 TFLOPS (Blue Gene/P, 2006/2007) beziehungsweise 3000 TFLOPS (Blue Gene/Q, 2007/2008) erreichen. Die Dauerleistung dieser Nachfolgesysteme von Blue Gene/L soll bei 300 TFLOPS beziehungsweise 1000 TFLOPS liegen.
Inhaltsverzeichnis
BlueGene/L
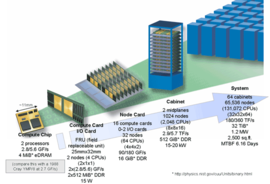 Diagramm des Systemaufbaus am Beispiel des BlueGene/L
Diagramm des Systemaufbaus am Beispiel des BlueGene/LBei BlueGene/L handelt es sich um eine Familie sehr gut skalierbarer Supercomputer. Das Projekt wird von IBM gemeinsam mit dem Lawrence Livermore National Laboratory finanziert.
Die Architektur besteht aus einem Basisbaustein (Knoten oder Compute-Chip), der immer wieder wiederholt werden kann, ohne dass Flaschenhälse entstehen. Jeder Knoten des BG/L besteht aus einem ASIC mit zugehörigem DDR-SDRAM-Speicher. Jeder ASIC wiederum enthält zwei 0,7 GHz PowerPC Embedded 440 Prozessorkerne, zwei „Double Hummer“ FPU[2], ein Cachesubsystem und ein Kommunikationssubsystem.
Die doppelten GFlops-Raten (2,8 bzw. 5,6 GFLOPS) auf verschiedenen Zeichnungen im Netz rühren von der Tatsache her, dass ein ASIC mit zwei Prozessoren in zwei Modi betrieben werden kann, welche entweder beide Prozessoren für Rechenaufgaben verwenden, oder nur einen für Rechenaufgaben und den anderen als Coprozessor für Kommunikationsaufgaben. Für die Kommunikation zwischen den Prozessoren steht ein Hochgeschwindigkeitsnetzwerk mit einer 3D-Torus-Topologie, sowie ein hierarchisches Netzwerk für kollektive Operationen zur Verfügung.
Der Zugriff auf das Torus-Netzwerk erfolgt über speicher-gemappte Netzwerkadapter, um ähnlich wie bei InfiniBand sehr niedrige Latenzzeiten zu erzielen. Für die Kommunikation wurde eine modifizierte MPICH2-Implementierung entwickelt. Auf den Rechenknoten läuft ein speziell hierfür programmierter, sehr kleiner POSIX-Kernel, welcher kein Multitasking unterstützt – das laufende Programm ist also der einzige Prozess auf dem System.
In der Ausgabe November 2004 der TOP500-Liste übernahm das noch im Aufbau befindliche System Blue Gene/L am Lawrence Livermore National Laboratory mit 16 Racks (16 384 Knoten, 32 768 Prozessoren) den Spitzenplatz. Seitdem wurde es schrittweise ausgebaut und erreichte am 27. Oktober 2005 mit 65 536 Knoten über 280 TFLOPS, was ihm die Führung in der TOP500 11/2005 einbrachte. Zwar war diese Ausbaustufe ursprünglich als Endausbau deklariert worden, er wurde 2007 jedoch noch einmal erweitert und erbringt seitdem mit 212 992 Prozessoren in 104 Racks über 478 TFLOPS. Damit ist er das momentan (Mitte 2008) viertschnellste System weltweit, nach IBM Roadrunner, Cray Januar und SGI Altix Pleiades.
Die Architektur taugt jedoch auch für andere Installationen wie den Watson Blue Gene (BGW) am IBM-eigenen Thomas J. Watson Research Center (Platz 25 in der TOP500 11/2008), JUBL (Jülicher Blue Gene/L am Forschungszentrum Jülich) und drei weiteren Einträgen in den Top 100. Diese fallen alle unter die Bezeichnung eServer Blue Gene Solution.
BlueGene/P
 Eine Knotenkarte des BlueGene/P
Eine Knotenkarte des BlueGene/PDie BlueGene/P-Serie wurde erstmalig im Juni 2007 auf der ISC in Dresden vorgestellt. Zu den Änderungen gegenüber BG/L zählen die Verwendung von mit 850 MHz getakteten PowerPC 450 Kernen von denen jetzt vier in einem Knoten enthalten sind. Auf jeder Compute-Card sitzt jetzt zwar nur noch ein statt zweier solcher Knoten, jedoch enthält eine Node-Card als nächstgrößere Einheit 32 statt 16 solcher Compute-Cards.
Ansonsten sind die Baueinheiten gleich geblieben und ein Rack enthält somit doppelt soviele Prozessoren wie ein BG/L. Bei einer zur Taktratenerhöhung parallelen Leistungssteigerung jedes Prozessors von rund 21 % (jedenfalls beim Linpack) leistet jedes Rack nun 14 statt 5,6 TFLOPS (jeweils Rpeak). Die Speicherbandbreite wuchs im gleichen Maße, die Bandbreite des Torus-Netzwerks wurde von 2,1 GB/s auf 5,1 GB/s mehr als verdoppelt und die Latenzzeiten halbiert. Der Energiebedarf hat sich dabei laut Hersteller nur um 35 % erhöht. Für ein aus 72 Racks bestehendes System, das die Peta-FLOPS-Grenze erreichen soll, sind das ca. 2,3 Megawatt.
Eine der ersten Auslieferungen ging ins Forschungszentrum Jülich, wird dort unter dem Namen JUGENE betrieben und steht mit 180 TFLOPS in der TOP500-Liste Ende 2008 auf Platz 11[3] erste Messungen für die TOP500. Im November 2008 sind sieben BlueGene/P-Systeme unter den 100 weltweit schnellsten Systemen vertreten.
Weblinks
- IBM Research: Blue Gene (englisch)
- IBM REDP-4247-00: Evolution of the IBM System Blue Gene Solution (englisch)
- Installation am LLNL mit vielen Infos (englisch)
Referenzen
- ↑ www.research.ibm.com
- ↑ IBM PowerPC 440 FPU with complex-arithmetic extensions
- ↑ Schnellster Rechner Europas kommt nach Jülich. IBM Deutschland, 25. Juni 2007. Abgerufen am 23. Juni 2007.


Wikimedia Foundation.