- Kreuzvalidierungsverfahren
-
Kreuzvalidierungsverfahren sind Testverfahren der Statistik bzw. der Datenanalyse, die z. B. im Data-Mining, oder bei der Überprüfung neu entwickelter Fragebögen zum Einsatz kommen. Es wird unterschieden zwischen der einfachen Kreuzvalidierung, der stratifizierten Kreuzvalidierung und der Leave-One-Out-Kreuzvalidierung.
Inhaltsverzeichnis
Problemstellung
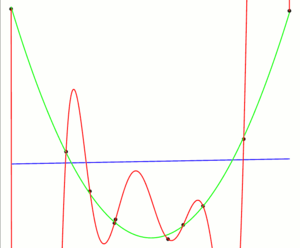 Das lineare Interpolationspolynom (blau) als Modell für die 10 Beobachtungen (schwarz) hat einen großen Fehler (underfitting). Das quadratische Interpolationspolynom (grün) war die Grundlage die Daten zu generieren. Das Interpolationspolynom der Ordnung 9 (rot) interpoliert die Daten selbst exakt, jedoch zwischen den Beobachtungen sehr schlecht (overfitting).
Das lineare Interpolationspolynom (blau) als Modell für die 10 Beobachtungen (schwarz) hat einen großen Fehler (underfitting). Das quadratische Interpolationspolynom (grün) war die Grundlage die Daten zu generieren. Das Interpolationspolynom der Ordnung 9 (rot) interpoliert die Daten selbst exakt, jedoch zwischen den Beobachtungen sehr schlecht (overfitting).
Um einen verlässlichen Wert für die Güte (Qualität) eines statistischen Modells zu bekommen, gibt es in der Statistik verschiedene Verfahren. In der Regel werden dafür Kennzahlen benutzt, z.B. das (korrigierte) Bestimmtheitsmaß in der linearen Regression oder das Akaike- oder Bayesianische Informationskriterium bei Modellen basierend auf der Maximum-Likelihood-Methode. Z.T. basieren solche Kennzahlen auf asymptotischer Theorie, d.h. sie können nur für große Stichprobenumfänge verlässlich geschätzt werden. Ihre Schätzung bei kleinen Stichprobenumfängen ist daher problematisch. Oft ist auch die exakte Zahl der zu schätzenden Parameter, die für die Kennzahl benötigt wird, nicht berechenbar; ein Beispiel hierfür ist die nicht-parametrische Statistik.
Des Weiteren gibt es das Problem, dass zu hoch parametrisierte Modelle dazu tendieren sich zu stark an die Daten anzupassen. Ein Beispiel ist die Polynominterpolation. Hat man N Beobachtungen (xi,yi) so kann man ein Interpolationspolynom y(x) = b0 + b1x + ... + bN − 1xN − 1 bestimmen, so dass y(xi) = yi für alle i gilt. Zwischen den Beobachtungspunkten werden die Daten jedoch sehr schlecht interpoliert (sog. overfitting). Würde man nun den Fehler (in-sample error) berechnen, so würde man die Modellqualität überschätzen.
Um den zuvor genannten Problemen zu entgehen, wird der Datensatz in zwei Teile geteilt. Mit dem ersten Teil werden nur die Modellparameter geschätzt und auf Basis des zweiten Teils wird der Modellfehler berechnet (out-of-sample error). Die Verallgemeinerung dieses Verfahrens sind die Kreuzvalidierungsverfahren.
Einfache Kreuzvalidierung
Die zur Verfügung stehende Datenmenge, bestehend aus N Elementen, wird in k möglichst gleich große Teilmengen (k ≤ N) T1,...,Tk aufgeteilt. Nun werden k Testdurchläufe gestartet, bei denen die jeweils i-te Teilmenge Ti als Testmenge und die verbleibenden k-1 Teilmengen {T1,...,Tk}\{Ti} als Trainingsmengen verwendet werden. Die Gesamtfehlerquote errechnet sich als Durchschnitt aus den Einzelfehlerquoten der k Einzeldurchläufe. Diese Testmethode nennt man k-fache Kreuzvalidierung.
Stratifizierte Kreuzvalidierung
Aufbauend auf der einfachen k-fachen Kreuzvalidierung, achtet die k-fache stratifizierte Kreuzvalidierung darauf, dass jede der k Teilmengen eine annähernd gleiche Verteilung besitzt. Dadurch wird die Varianz der Abschätzung verringert.
Leave-One-Out-Kreuzvalidierung
Bei der Leave-One-Out-Kreuzvalidierung (engl. leave-one-out cross validation) handelt es sich um einen Spezialfall der k-fachen Kreuzvalidierung, bei der k = N. Somit werden N Durchläufe gestartet und deren Einzelfehlerwerte ergeben als Mittelwert die Gesamtfehlerquote.
Nachteil dieser Methode ist, dass eine Stratifizierung der Teilmengen, wie bei der stratifizierten Kreuzvalidierung, nicht mehr möglich ist. Dadurch kann es in Extremfällen dazu kommen, dass dieses Testverfahren falsche Fehlerwerte liefert. Beispiel: Eine vollständig zufällige Datenmenge bei gleichmäßiger Verteilung und nur zwei Klassen würde zu einem LOO-CV von 100 % führen. Warum? Aus N Elementen werden zum Training N / 2 Elemente der Klasse K1 verwendet und N / 2 − 1 Elemente der Klasse K2. Da der Klassifikator immer die Mehrheitsklasse der Testdaten prognostiziert, liefert der Test mit dem Testelement der Klasse K2 einen Fehler von 100 %!
Ein weiterer Nachteil ist der sehr hohe Rechenaufwand.
Anwendungsbeispiel
Ein Psychologe entwickelt einen neuen Test, mit dem er Depressivität messen will.
Um zu überprüfen, wie gut der Test das zu messende Merkmal (Depressivität) misst, lässt er in einem ersten Schritt eine große Gruppe von Personen, bei denen die jeweilige Ausprägung des Merkmals bekannt ist (vorher durch Experten oder einen anderen Test bestimmt), an diesem Test teilnehmen.
Im nächsten Schritt unterteilt er die große Gruppe in zwei zufällig zusammengestellte Untergruppen (bzw. k-Teilmengen, siehe weiter unten), nennen wir sie Untergruppe A und Untergruppe B. Der Psychologe benutzt nun die Daten der Untergruppe A, um mit ihnen eine Vorhersagegleichung für das Merkmal, das der Test messen soll, zu erstellen. D. h. er bildet eine Regel, nach der aus den Testdaten einer Person Rückschlüsse auf die Ausprägung des gesuchten Merkmals bei ihr gezogen werden können. Diese Vorhersagegleichung wendet er nun auf alle Mitglieder der Untergruppe B an und versucht, aus den Testdaten von Untergruppe B, mithilfe der an Untergruppe A entwickelten Vorhersagegleichung, auf deren jeweilige Ausprägung des Merkmals zu schließen. Anschließend vergleicht er die vorhergesagten Ausprägungen mit den tatsächlich vorliegenden. Die Validierung des Tests erfolgt also kreuzweise, deswegen Kreuzvalidierung. Je höher die Übereinstimmung zwischen tatsächlicher und vorhergesagter Ausprägung, umso besser, valider, ist der Test.
In einem dritten möglichen Schritt wiederholt der Psychologe das Vorgehen mit vertauschten Untergruppen. Er entwickelt also aus den Daten der Untergruppe B eine Vorhersagegleichung, die er im Anschluss an Untergruppe A prüft.(=doppelte Kreuzvalidierung)
Wikimedia Foundation.