- Schätzgütemaße für ordinale Insolvenzprognosen
-
Schätzgütemaße für ordinale Insolvenzprognosen messen die Qualität ordinaler Insolvenzprognosen. Ordinale Insolvenzprognosen sind Prognosen über die relativen Ausfallwahrscheinlichkeiten der bewerteten Unternehmen wie „Unternehmen Y fällt mit größerer Wahrscheinlichkeit aus als Unternehmen X aber mit geringerer Wahrscheinlichkeit als Unternehmen Z“.[1]
Zwar könnten ordinale Insolvenzprognosen theoretisch beliebig differenziert sein, in der Praxis haben sich aber ordinale Ratingsysteme durchgesetzt, die ihre Ergebnisse auf eine diskreten, 7- oder 17-stufigen Skala[2] in einer von Standard & Poor’s (S&P) übernommen Notation kommunizieren.[3],[4]
Inhaltsverzeichnis
Bedeutung ordinaler Schätzgütemaße
Auch wenn ordinale Insolvenzprognosen allgemeiner als kategoriale Insolvenzprognosen sind, genügen für die meisten Anwendungen keine nur vergleichenden Aussagen über das relative Ausfallrisiko von Unternehmen. Benötigt werden vielmehr auch quantitative Ausfallprognosen, beispielsweise um angeben zu können, ob eine Risikoprämie von 1,5% p.a. für einen endfälligen, unbesicherten und vorrangigen Kredit mit drei Jahren Laufzeit bei einem Unternehmen angemessen ist, dessen Ratingeinstufung besagt, dass es „derzeit die Fähigkeit hat, seinen finanziellen Verpflichtungen nachzukommen. Allerdings würden ungünstige Geschäfts-, Finanz- oder gesamtwirtschaftliche Bedingungen vermutlich seine Fähigkeiten und Bereitschaft seinen finanziellen Verpflichtungen nachzukommen beeinträchtigen“.[5][6]
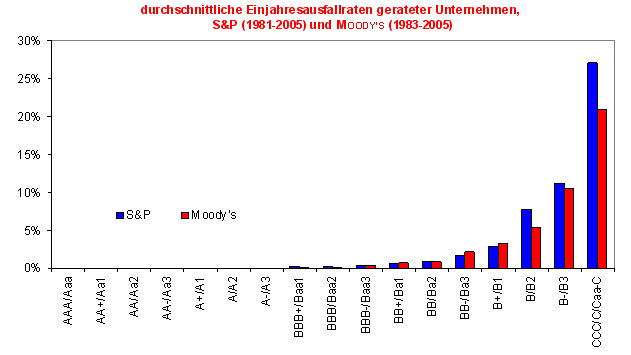
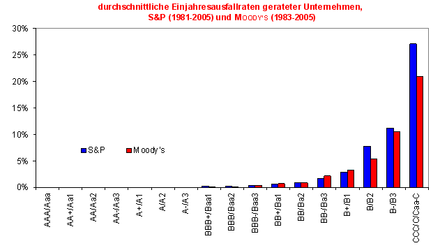 Durchschnittliche historische Einjahresausfallraten nach modifizierten Ratingklassen gemäß Standard and Poor's (1981-2005) und Moody's (1983-2005), Quelle: S&P (2006, S. 18), Moody's (2006, S. 35)
Durchschnittliche historische Einjahresausfallraten nach modifizierten Ratingklassen gemäß Standard and Poor's (1981-2005) und Moody's (1983-2005), Quelle: S&P (2006, S. 18), Moody's (2006, S. 35)
Trotzdem lohnt sich die Auseinandersetzung mit Schätzgütemaßen für ordinale Insolvenzprognosen:
- Sie entsprechen von der Intention her dem, was die Ratingagenturen zu liefern versprechen.[7][8]
- Sie stellen mittlerweile eine dominante Methode zur Beurteilung der Qualität von Ratingergebnissen dar.[9]
- Es existieren zahlreiche Möglichkeiten der grafischen Darstellung für die ordinale Schätzgüte von Ratingsystemen, was auch die Kommunizierbarkeit der aus diesen Darstellungen abgeleiteten Kennzahlen erleichtert.
- Eine hohe Trennschärfe, wie sie durch Gütemaße für ordinale Insolvenzprognosen gemessen wird, ist auch für die Qualität kardinaler Insolvenzprognosen wichtig – und zwar wichtiger als eine korrekte Kalibrierung. Es ist leichter, „richtige“ (kalibrierte) als trennscharfe Ausfallwahrscheinlichkeiten zu generieren.[10][11]
- Beim empirischen Vergleich verschiedener Ratingverfahren auf Basis identischer Stichproben entspricht die Reihenfolge der Güte der einzelnen Verfahren gemäß ordinaler Schätzgütemaße häufig auch der Reihenfolge der Güte bei Zugrundelegung kardinaler Schätzgütemaße.[12] Somit scheinen Qualitätsunterschiede verschiedener Verfahren weniger in einer unterschiedlich guten Befähigung zur Abgabe kalibrierter Ausfallprognosen zu liegen, was nur für kardinale Gütemaße relevant ist, sondern in einer unterschiedlich guten Befähigung zur Abgabe trennscharfer Prognosen, was sowohl für ordinale als auch kardinale Schätzgütemaße relevant ist.
- Für diejenigen Aspekte kardinaler Insolvenzprognosen, die nicht bereits mit dem Instrumentarium, das für die Beurteilung ordinaler Insolvenzprognosen entwickelt wurde, gemessen werden können, insbesondere für den Aspekt der Kalibrierung von Insolvenzprognosen, stehen derzeit keine aussagekräftigen Testverfahren zur Verfügung – wenn die Ausfallwahrscheinlichkeiten der verschiedenen Unternehmen nicht unkorreliert sind.[13][14] Die tatsächliche Relevanz dieses theoretischen Einwands ist jedoch noch umstritten. Es existieren empirische Hinweise darauf, dass die entsprechenden im Rahmen von Basel II unterstellten segmentspezifischen Korrelationsparameter um den Faktor 15 bis 120 (im Durchschnitt rund 50) zu hoch angesetzt werden.[15]
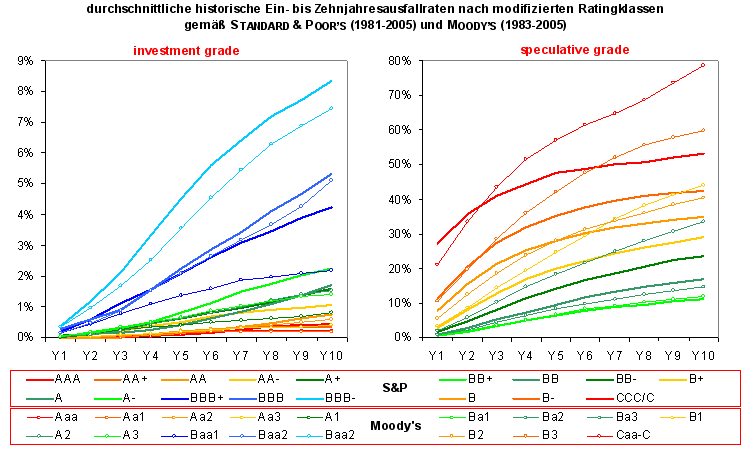
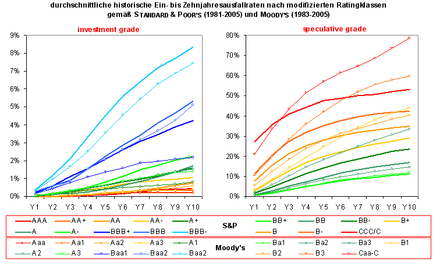 Durchschnittliche historische kumulierte Ein- bis Zehnjahresausfallraten nach modifizierten Ratingklassen gemäß Standard and Poor's (1981-2005) und Moody's (1983-2005) Quelle: S&P (2006, S. 18), Moody's (2006, S. 35)
Durchschnittliche historische kumulierte Ein- bis Zehnjahresausfallraten nach modifizierten Ratingklassen gemäß Standard and Poor's (1981-2005) und Moody's (1983-2005) Quelle: S&P (2006, S. 18), Moody's (2006, S. 35)Auch wenn die Ratingagenturen ex-ante mit den von ihnen vergebenen, ordinalen Ratingnoten keine kardinalen Ausfallprognosen für irgendeinen spezifizierten Zeitraum abgeben wollen[16], demonstrieren sie die Güte ihrer Ratingeinschätzungen u.a. mit deren Fähigkeit, Unternehmen mit deutlich unterschiedlichen, monoton steigenden Ausfallhäufigkeiten identifizieren zu können (siehe die beiden folgenden Abbildungen für die durchschnittlichen ratingklassenspezifischen Ein- und Mehrjahresausfallraten nach S&P und Moody's.
Die beiden Abbildung zeigen, dass die Ratingagenturen in der Lage waren, mit ihren ex-ante vergebenen Ratingnoten, ex-post Gruppen von Unternehmen mit sehr unterschiedlichen realisierten Ausfallquoten zu separieren.[17]
Dies ist eine notwendige Voraussetzung, um trennscharfe Ausfallprognosen treffen zu können, aber keine hinreichende. Kompatibel mit den Darstellungen in obigen Abbildungen wären beispielsweise die folgenden Extremfälle[18]:
- Extremfall I: Das Ratingsystem ordnet fast alle Unternehmen in eine mittlere Ratingstufe (siehe die erste Abbildung) ein, beispielsweise BB, bzw. Ba2, und nur sehr wenige Unternehmen in andere Ratingstufen.
- Extremfall II: Das Rating ordnet fast alle Unternehmen in die extremen Ratingstufen, d.h. entweder AAA oder CCC/C, ein und nur wenige in die mittleren Ratingstufen.
Im Fall I wäre das Rating nahezu wertlos, da es praktisch keine Differenzierung zwischen den verschiedenen Schuldnern erlaubte. Im Fall II hingegen wäre der Informationsnutzen erheblich: das Rating würde stets „extreme Prognosen“ stellen – also entweder eine extrem niedrige oder eine extrem hohe Ausfallwahrscheinlichkeit vorhersagen – und die Prognosen würden meist zutreffen - einem AAA-Rating würde innerhalb eines Jahres fast nie und einem CCC/CRating würde zumindest in 25%-30% aller Fälle ein Ausfall folgen.
Um die ordinale Qualität eines Ratingsystems zu bestimmen, müssen somit nicht nur die ratingklassenspezifischen Ausfallquoten bekannt sein, sondern auch die Verteilung der Unternehmen auf die einzelnen Ratingklassen.
Grafische Schätzgütebestimmung
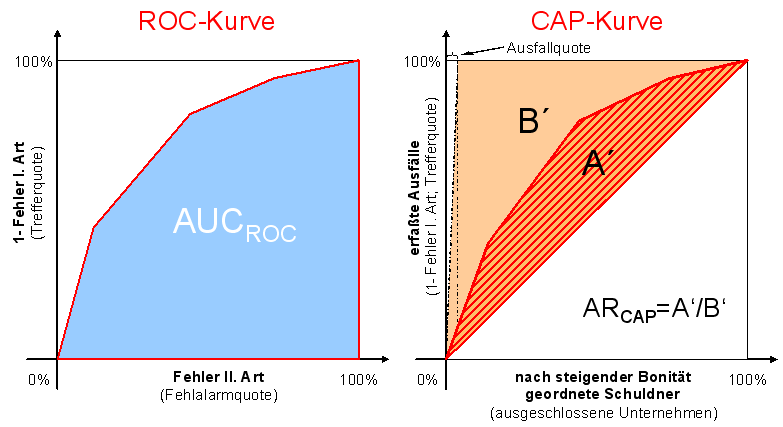
Die Fähigkeit eines Ratingsystems, „gute“ und „schlechte“ Schuldner mit großer Zuverlässigkeit zu trennen, kann durch ROC (receiver operating characteristic)-[19] oder CAP-Kurven (cumulative accuracy profile) visualisiert und durch verschiedene hierauf basierende und ineinander überführbare Kennzahlen quantifiziert werden. Weitere Bezeichnungen für ROC- oder CAP-Kurven sind Aufklärungsprofil, Powerkurve, Lorenzkurve, Ginikurve, lift-curve, dubbed-curve oder ordinal dominance graph.[20]
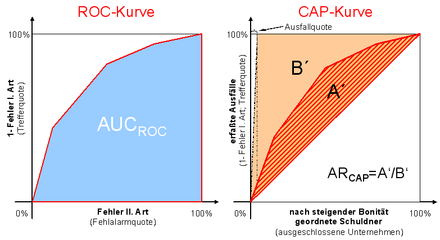 ROC- und CAP-Kurven
ROC- und CAP-KurvenDie ROC-Kurve eines Verfahrens ergibt sich aus der Menge sämtlicher Kombinationen von Trefferquoten (100% - Fehler I. Art) und „Fehlalarmquoten“ (Fehler II. Art), die ein Insolvenzprognoseverfahren bei Zugrundelegung verschiedener Trennwerte (cut-off scores), d.h. bei Überführung von kardinalen oder ordinalen in kategoriale Insolvenzprognosen, liefern kann. Bei einem „zu scharf gestellten“ Trennwert würden sämtliche Unternehmen als voraussichtlich insolvent prognostiziert (100% Trefferquote (= 0 % Fehler I. Art); 100% Fehlalarmquote (=100% Fehler II. Art)), bei einem „zu lax eingestellten“ Trennwert, würde keines der Unternehmen als voraussichtlich insolvent prognostiziert (0% Trefferquote; 0% Fehlalarmquote). Auch zwischen diesen Extremfällen gibt es einen Ausgleich zwischen Treffer- und Fehlalarmquoten. Die Qualität ordinaler Insolvenzprognosen zeigt sich gerade in der Art dieses Ausgleichs. Ein perfektes Prognoseverfahren müsste keinen einzigen Schuldner „zu Unrecht“ ausschließen, um 100% aller Ausfälle zu erfassen (vertikaler Verlauf der ROC-Kurve von (0%; 0%) nach (0%; 100%)), eine anschließende Verschärfung des Trennwertes würde nur zu einer Erhöhung der Fehlalarmquote führen (horizontaler Verlauf der ROC-Kurve von (0%; 100%) nach (100%; 100%)). Die ROC-Kurve eines Ratingverfahrens hingegen, dessen Bewertungen rein zufällig erfolgten, würde entlang der Hauptdiagonalen verlaufen – jeder Prozentpunkt bei der Verbesserung der Trefferquote müsste mit einem Prozentpunkt bei der Verschlechterung der Fehlalarmquote erkauft werden.
ROC-Kurven realer Insolvenzprognoseverfahren weisen eine konkave Form auf.[21] Die Konkavität einer ROC-Kurve impliziert, dass die realisierten Ausfallraten mit besserer Bonität geringer werden, d.h. dass das zugrundeliegende Ratingsystem „semi-kalibriert“ ist.[22]
CAP-Kurven resultieren aus der Anwendung eines gegenüber ROC-Kurven nur geringfügig modifizierten Konstruktionsprinzips. Auf der X-Achse werden hier nicht die „Fehlalarmquoten“ (Fehler II. Art) abgetragen, sondern der Anteil von Unternehmen, die vom Prognoseverfahren ausgeschlossen werden müssen - unabhängig davon, ob es sich um tatsächliche Ausfälle oder Nicht-Ausfälle handelt, um eine bestimmte „Trefferquote“ (100%-Fehler I. Art) zu erzielen. Die CAP-Kurve eines perfekten Ratings verläuft ausgehend vom Punkt (0%; 0%) steil nach rechts oben – jedoch nicht vertikal, da mindestens PD% aller Unternehmen ausgeschlossen werden müssen, um alle Ausfälle zu erfassen (siehe die Grafik oben, rechts).
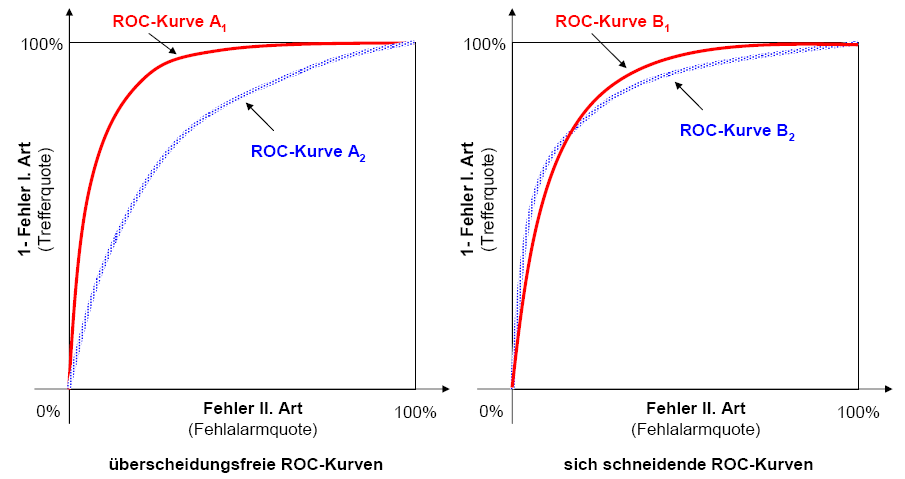
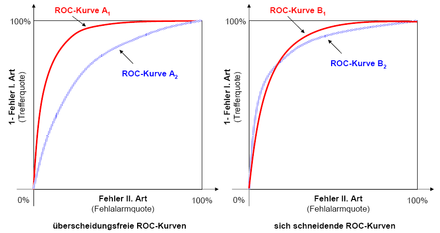 überschneidungsfreie und sich schneidende ROC-Kurven
überschneidungsfreie und sich schneidende ROC-KurvenLiegt die ROC-/CAP-Kurve eines Verfahrens A1 bei Beurteilung der gleichen Unternehmen regelmäßig links oberhalb der ROC-/CAP-Kurve eines anderen Verfahrens A2, so liefert Verfahren A1 für jeden denkbaren Trennwert bessere Prognosen als Verfahren A2 (siehe die Grafik oben). Falls die relative Vorteilhaftigkeit eines Verfahrens nur von dessen relativer Schätzgüte abhinge[23], wäre Verfahren A1 damit Verfahren A2 stets vorzuziehen - unabhängig von individuellen Spezifika des Entscheidungsträgers, beispielsweise hinsichtlich seiner Kosten für Fehler I. und II. Art. Schneiden sich hingegen die ROC-Kurven zweier Verfahren B1 und B2 (siehe die Abbildung oben, rechts), so ist keines der beiden Verfahren dem anderen objektiv überlegen.[24] Im gewählten Beispiel ist Verfahren B1 besser als B2 in der Lage, innerhalb der „guten Unternehmen“ zu differenzieren, während Verfahren B2 im Bereich der „schlechten Unternehmen“ eine höhere Trennschärfe aufweist.[25] Ist der Entscheider nicht gezwungen, entweder nur das eine oder nur das andere Verfahren zu verwenden, kann er möglicherweise die Verfahren B1 und B2 so zu einem dritten Verfahren B3 kombinieren, dass dieses sowohl B1 als auch B2 überlegen ist. Gleiches gilt auch für die Verfahren A1 und A2: Obwohl A2 strikt von A1 dominiert wird, lässt sich aus der Kombination von A1 und A2 möglicherweise ein Verfahren A3 generieren, das nicht nur A2, sondern auch A1 überlegen ist. So ließ sich in empirischen Studien beispielsweise die Prognosequalität von ausschließlich kennzahlenbasierten Bankenratings durch die Einbeziehung von „weichen Faktoren“ verbessern, obwohl die Prognosegüte der kennzahlenbasierten Ratings besser war als die Prognosegüte der Softfaktorratings.[26]
Neben grafischen Darstellungen werden für den praktischen Einsatz bei der Messung der Schätzgüte von Insolvenzprognosen auch Kennzahlen benötigt, um die in CAP- oder ROC-Kurven enthaltenen Informationen möglichst kompakt darzustellen. Als Mindestanforderung an eine derartige Kennzahl ist zu stellen, dass diese Kennzahl für alle ROC-Kurven definiert sein muss und dass, wenn die ROC-Kurve eines Verfahrens A1 links oberhalb der ROC-Kurve A2 liegt, das A1 zugehörige Gütemaß einen größeren Wert aufweisen muss als das A2 zugehörige Gütemaß.[27]
Quantitative Schätzgütebestimmung
Das üblicherweise im Zusammenhang mit ROC-Kurven verwendete Gütemaß ist der Inhalt der Fläche unter der ROC-Kurve:
Die Fläche unter der ROC-Kurve entspricht der Wahrscheinlichkeit, mit der für zwei zufällig ausgewählte Individuen, wobei jeweils eines aus den Ausfall- und eines aus den Nicht- Ausfallunternehmen gezogen wurde, das Nicht-Ausfall-Unternehmen einen besseren Scorewert als das Ausfallunternehmen aufweist.[30] Bei einem perfekten Ratingsystem beträgt AUC stets 100%, bei einer rein zufälligen Scorevergabe (naives Ratingsystem) liegt der Erwartungswert für AUC bei 50%.[31] Um den Wertebereich des Gütemaßes auf das Intervall [-100%; +100%] anstelle [0%; 100%] zu skalieren und um „naive Prognosen“ mit einem Erwartungswert von 0% anstelle von 50% auszuweisen, wird auf Basis von AUCROC die Kenngröße Accuracy Ratio (ARROC) wie folgt ermittelt:
Formel 2:

Die Kenngröße AR lässt sich auch als ein Spezialfall anderer, gebräuchlicher ordinaler Kenngrößen darstellen.[32] Im Gegensatz zum Vorgehen bei ROC-Kurven ist es aber nicht üblich, die auf Basis von CAP-Kurven berechneten AUC-Maße auszuweisen. Üblich ist hier nur die gegenüber der ROC-Kurve leicht modifizierte Berechnung der CAP-Accuracy Ratio mit:
Formel 3:

Formel 3b:

wobei A´ für die Fläche zwischen CAP-Kurve und Diagonale steht und B´ für die Fläche zwischen der Diagonale und der CAP-Kurve, die ein perfektes Ratingverfahren maximal erzielen könnte, siehe die rechte Grafik in obiger Abbildung. Es lässt sich zeigen, dass ARROC und ARCAP identisch sind.[33]
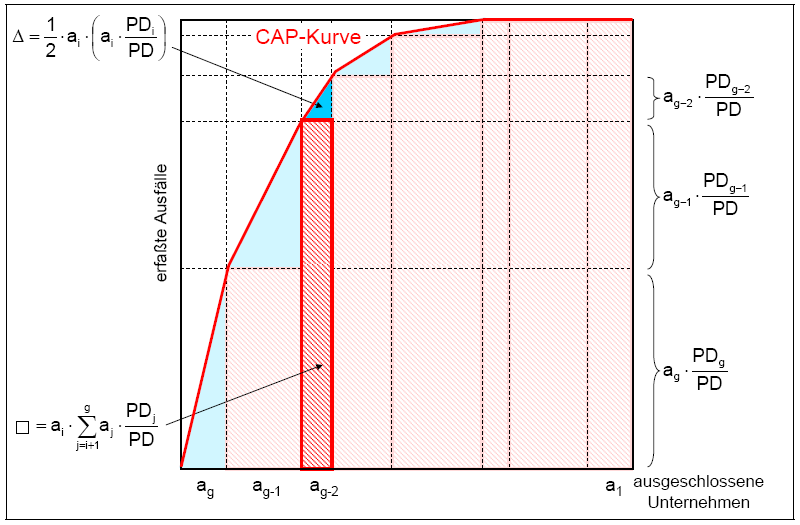
Für ein Ratingsystem mit g diskreten Klassen lässt sich das Integral ∫CAP(x)dx in je g drei- und rechteckige Teilflächen mit bekannten Seitenlängen zerlegen (siehe die folgende Abbildung). In der Abbildung wird der Flächeninhalt für jeweils eine rechteckige und eine dreieckige Fläche angegeben.
Formel 4:

- Legende
- g...Anzahl der diskreten Ratingklassen,
- aj...Anteil der Unternehmen in Ratingklasse j,
- PDj...realisierte Ausfallhäufigkeit in Ratingklasse j,
- PD...durchschnittliche Ausfallwahrscheinlichkeit
 vertikale Dekomposition der Fläche unter der CAP-Kurve, Quelle: Bemmann (2005, S. 22)
vertikale Dekomposition der Fläche unter der CAP-Kurve, Quelle: Bemmann (2005, S. 22)
Durch Umstellen und Einsetzen in Formel 3b ergibt sich[34]:Formel 5:
 mit
mitFormel 5b:

wobei kumPDi für den Anteil der Ausfaller in den Ratingklassen 1..i an der Gesamtheit aller Ausfaller steht. Die vorgestellten Gütemaße sind gleichermaßen für kontinuierliche Scores wie für Scores mit einer endlichen Anzahl möglicher Ausprägungen (Ratingklassen) definiert. Die Zusammenfassung kontinuierlicher Scores zu diskreten Ratingklassen ist mit nur mit geringfügigen Informationsverlusten verbunden [35], so dass die Qualität ordinaler Insolvenzprognosen allein anhand der relativen Häufigkeiten der einzelnen Ratingklassen sowie der Angaben zu den realisierten Ausfallquoten je Ratingklasse bestimmt werden kann. Diese Daten werden beispielsweise von den Ratingagenturen S&P und Moody's veröffentlicht, sind aber auch für andere Ratingverfahren, beispielsweise den Bonitätsindex von Creditreform[36] verfügbar.
Quellen
- ↑ Dieser Artikel basiert auf Bemmann (2005).
- ↑ 17-stufige Skala: 1=“AAA“, 2=“AA+“, 3=“AA“, 4 =“AA-“,5=“A+“, 6=“A“, 7=“A-“, 8=“BBB+“, 9=“BBB“, 10=“BBB-“, 11=“BB+“, 12=“BB“, 13=“BB-“, 14=“B+“, 15=“B“, 16 = „B-“, 17 = „CCC/C“, 7-stufige Skala: “AAA“, “AA“, “A“, „BBB“, „BB“, “B“, “C“.
- ↑ In Basler Ausschuss (2000c, S. 23f) werden die Ratingsymbole von 30 Ratingverfahren unterschiedlicher internationalen Ratingagenturen untersucht. 22 Agenturen verwenden Buchstabenkombinationen, um ihr Ratingurteil auszudrücken (ca. 75%), 6 Agenturen kommunizieren ihre Ratings in Form von Noten (20%), nur zwei Agenturen geben ihr Urteil in Form von Ausfallwahrscheinlichkeiten an. Von den 22 „Buchstaben-Ratings“ entsprechen 14 exakt der ausführlichen S&P-Notation (17-stufige Skala), 2 der verkürzten S&P-Notation (7-stufige Skala). Bei Banken überwiegen hingegen numerische Ratingklassenbezeichnungen (ca. 85%) anstelle von Buchstabenkombinationen (ca. 15%), siehe Englisch, Nelson (1998, S. 4).
- ↑ Standard & Poor's verwendet seit 1974 die um Plus- und Minuszeichen modifizierte Ratingklassendarstellung. Moody's hingegen erst seit 1982, siehe Cantor, Packer (1994, S.2)
- ↑ Siehe die Definition für die Ratingstufe B gemäß S&P (2003b, S.7, eigene Übersetzung)
- ↑ Siehe auch Frerichs, Wahrenburg (2003, S. 13): „Under what circumstances is such a measure Area Under the ROC-curve useful? The ranking of borrowers is sufficient for credit risk management if banks are not able to charge different credit risk premiums for different customers in the market. In this case, banks maximize their risk-adjusted returns by not granting credit to customers with negative expected returns which is equivalent to defining a minimum credit score. Yet, this line of thought does not lead us to the AUC as a measure of system quality, but to the concept of minimized expected error costs. The AUC measures the quality of the complete ranking and not only of one threshold. Only if the threshold is difficult to define in practice, the AUC may be a sensible measure.“- oder kurz und prägnant: „There are no bad loans, only bad prices.“, siehe Falkenstein, Boral, Kocagil (2000, S. 5).
- ↑ Cantor, Mann (2003, S. 6): „Moody's primary objective is for its ratings to provide an accurate relative (i.e., ordinal) ranking of credit risk at each point in time, without reference to an explicit time horizon.“ und Cantor, Mann (2003, S. 1): „Moody’s does not target specific default rates for the individual rating categories.“, allerdings auch: „Moody’s also tracks investment-grade default rates and the average rating of defaulting issuers prior to their defaults. These metrics measure Moody’s success at meeting a secondary cardinal or absolute rating system objective, namely that ratings be useful to investors who employ simple rating ‘cutoffs’ in their investment eligibility guidelines.“, siehe ebenda.
- ↑ Basler Ausschuss (2000c, S. 2) „Most firms report that they rate risk on a relative – rather than absolute – scale, and most indicate that they rate ‘across the business cycle’, suggesting that ratings should in principle not be significantly affected by purely cyclical influences.“ Von den 15 Ratingagenturen, die hierzu Angaben machten, gaben 13 an, mit ihrem Rating das „relative Risiko von Unternehmen zu messen, nur 2 Agenturen messen nach eigenen Angaben das „absolute Risiko“ von Unternehmen (KMV Corporation und Upplysningscentralen AB), siehe ebenda (S. 23f).
- ↑ Siehe beispielsweise McQuown (1993, S.5ff), Keenan, Sobehart (1999, S. 5ff), Stein (2002, S. 5ff.), Fahrmeir, Henking, Hüls (2002, S. 22f), Engelmann, Hayden, Tasche (2003, S. 3ff), Deutsche Bundesbank (2003a, S. 71ff.), OeNB (2004a, S. 113ff.). Auch die Ratingagenturen Standard and Poor's (2006, S. 48) und Moody's (2006, S. 11ff.) messen die Qualität ihrer Ratingsysteme mittels der in diesem Abschnitt vorgestellten Methoden und Kennzahlen.
- ↑ Blochwitz, Liebig, Nyberg (2000, S.3): „It is usually much easier to recalibrate a more powerful model than to add statistical power to a calibrated model. For this reason, tests of power are more important in evaluating credit models than tests of calibration. This does not imply that calibration is not important, only that it is easier to carry out.“, analog Stein (2002, S.9)
- ↑ Die Kalibrierung eines Ratingsystems wird in Sobehart et al (2000, S. 23f.) oder Stein (2002, S. 8ff.) beschrieben.
- ↑ Siehe beispielsweise Krämer, Güttler (2003) für den Vergleich der Schätzgüte der Ausfallprognosen von S&P und Moody's oder Sobehart, Keenan, Stein (2000, S. 14) für den Vergleich der Schätzgüte von sechs unterschiedlichen Verfahren mittels ordinaler und kardinaler Schätzgütekennzahlen.
- ↑ siehe Basler Ausschuss (2005a, S. 31f.): „These [cardinal] measures appear to be of limited use only for validation purposes as no generally applicable statistical tests for comparisons are available. [...] The [Basle Committee's Validation] Group has found that the Accuracy Ratio (AR) and the ROC measure appear to be more meaningful than the other above-mentioned indices because of their statistical properties. For both summary statistics, it is possible to calculate confidence intervals in a simple way. [...] However, due to the lack of statistical test procedures applicable to the Brier score, the usefulness of this metric for validation purposes is limited.“ und ebenda, S. 34: „At present no really powerful tests of adequate calibration are currently available. Due to the correlation effects that have to be respected there even seems to be no way to develop such tests. Existing tests are rather conservative […] or will only detect the most obvious cases of miscalibration […]“
- ↑ Schon bei moderaten Ausfallkorrelationen (zumindest verglichen mit den aufsichtsrechtlich unterstellten Benchmarkwerten) können die realisierten Ausfallquoten - selbst bei beliebig großen Portfolien - erheblich von den erwarteten Ausfallquoten abweichen, siehe hierzu Huschens, Höse (2003, S. 152f.) oder Blochwitz et al (2004, S. 10).
- ↑ Siehe hierzu Scheule (2003, S. 149). Die Untersuchungen basieren auf einem Datensatz der Deutsche Bundesbank, der den Zeitraum 1987-2000 umfasst und über 200.000 Jahresabschlüsse von über 50.000 (westdeutschen) Unternehmen enthält, von denen 1.500 insolvent wurden, siehe ebenda (S. 113ff.). Die auf Basis der von Scheule (2003, S. 156) ermittelte Portfolioverlustverlustverteilung (eines konkreten Modellportfolios mit einer erwarteten Ausfallrate von 1,34%) ist weitgehend symmetrisch und unterscheidet sich erheblich von dem typischen linkssteilen-rechtsschiefen Verteilungstyp, der sich bei starken Ausfallkorrelationen ergibt. Das 99,9%-Quantil beider Verteilungen, welches gemäß dem Basel II-Regelwerk für die Ermittlung der Eigenkapitalanforderungen herangezogen wird, unterscheidet sich im gewählten Beispiel um den Faktor 5 bis 6!
- ↑ S&P (2005, S. 28): „Many practitioners utilize statistics from this default study and CreditPro® to estimate probability of default and probability of rating transition. It is important to note that Standard & Poor's ratings do not imply a specific probability of default; however, Standard & Poor's historical default rates are frequently used to estimate these characteristics.
- ↑ Den Ausfallstudien von S&P und Moody's liegen Emittentenratings (auch issuer ratings, corporate credit ratings, implied senior-most rating, default ratings, natural ratings, estimated senior ratings) zugrunde, welche ein Maß für die erwartete Ausfallwahrscheinlichkeit der Unternehmen darstellen sollen, ohne jedoch einen expliziten Prognosehorizont anzugeben, siehe S&P (2003b, S. 3ff., 61ff.), Cantor, Mann (2003, S. 6f.), Moody's (2004b, S. 8) und Moody's (2005, S. 39). Die Ratings konkreter Verbindlichkeiten von Unternehmen, sogenannte Emissionsratings (issue rating), berücksichtigen neben der Ausfallwahrscheinlichkeit auch die erwartete Ausfallschwere und können deshalb als ein Maß für die erwarteten Ausfallkosten interpretiert werden. Je nach Rang der bewerteten Verbindlichkeit innerhalb der Kapitalstruktur des Unternehmens, gewährten Sicherheiten und weiteren Einflussfaktoren ergibt sich das Emissionsrating durch Zu- oder Abschläge (von meist 1 bis 2 Punkten) aus dem Emissionsrating. Das Emittentenrating eines Unternehmens entspricht in der Regel dem Emissionsrating erstrangiger, unbesicherter Verbindlichkeiten, siehe ebenda.
- ↑ siehe Cantor, Mann (2003, S. 14)
- ↑ ROC-Kurven werden bereits seit Anfang der 1950er Jahre im Bereich der experimentellen Psychologie verwendet, siehe Swets (1988, S. 1287).
- ↑ siehe Blochwitz, Liebig, Nyberg (2000, S. 33): power curve, lift-curve, dubbed-curve, receiver-operator curve; Falkenstein, Boral, Kocagil (2000, S.25): Gini curve, Lorenz curve, ordinal dominance graph; Schwaiger (2002, S. 27): Aufklärungsprofil
- ↑ Siehe Bemmann (2005, Anhang I) für zahlreiche Beispiele von ROC-Kurven realer Insolvenzprognoseverfahren.
- ↑ siehe Krämer (2003, S. 403)
- ↑ Ein weiteres Kriterium für die relative Vorteilhaftigkeit der Verfahren könnte in den Kosten der Verfahren selbst begründet liegen. Während Banken für die Einstufung von kleineren Krediten häufig auf automatisierte (und tendenziell wenige trennscharfe) Verfahren zurückgreifen, lohnen sich bei größeren Krediten auch arbeitsintensivere Bewertungsverfahren, siehe Treacy, Carey (2000, S. 905) und Basler Ausschuss (2000b, S.18f.)
- ↑ siehe Blochwitz, Liebig, Nyberg (2000, S. 7f.)
- ↑ Nach Krämer (2003, S. 402) besteht beim Vergleich von Ratingsystemen der Normalfall“ in sich schneidenden ROC- bzw. CAP-Kurven: „Insofern hilft das Konzept der Ausfalldominanz in vielen Anwendungen nicht weiter. [...] Das Konzept der Ausfalldominanz [empfiehlt] sich vor allem zum Aussortieren von Substandard-Systemen.“ Trennschwächere (ausfalldominierte) Prognosen lassen sich aus trennstärkeren Prognosen ableiten, siehe Krämer (2003, S. 397f.)
- ↑ Siehe die Studie von Lehmann (2003, S. 21) in Abschnitt 3.4. Siehe Grunert, Norden, Weber (2005), die allerdings nur aggregierte Kennzahlen für die unterschiedlichen Modelle (Kennzahlenrating, Softfaktorrating, kombiniertes Rating) ausweisen und keine CAP- oder ROC-Kurven. n letzterer Studie war die Prognosefähigkeit des Softfaktorratings sogar größer als die des Kennzahlenratings (siehe ebenda, S. 519).
- ↑ Die Umkehrung der Mindestforderung („Wenn A1 > A2, dann liegt die ROC-Kurve von A1 links oberhalb von A2“) gilt nicht. Ausgeschlossen wird lediglich, dass die A1 zugehörige CAP-/ROC-Kurve rechts unterhalb der A2 zugehörigen CAP-/ROC-Kurve liegt. Denkbar ist auch, dass sich die CAP-/ROC-Kurven von A1 und A2 schneiden, wenn A1>A2. Cantor, Mann (2003, S. 12): „Although the accuracy ratio is a good summary measure, not every increase in the accuracy ratio implies an unambiguous improvement in accuracy.“
- ↑ siehe Deutsche Bundesbank (2003a, S.71ff.)
- ↑ Für weitere, gut interpretierbare Kennzahlen siehe Lee (1999).
- ↑ siehe Lee (1999, S. 455)
- ↑ Der niedrigste mögliche Wert, 0%, würde von einem Ratingsystem erzielt, dessen Prognosen immer falsch sind. Durch die Negation der Prognosen ließe sich dieses Rating in ein perfektes Rating überführen.
- ↑ Siehe Hamerle, Rauhmeier, Rösch (2003, S. 21f.), die zeigen, dass die Accuracy Ratio ein Spezialfall der allgemeineren Kennzahl Somer's D ist, die auch für zu erklärende Variablen mit mehr als zwei möglichen Ausprägungen (Ausfall vs. Nichtausfall) definiert ist. Siehe Somer (1962, S. 804f.) für eine Darstellung der Relation von Somer's D zu anderen ordinalen Gütemaßen wie Kendall's Tau oder Goodman and Kruskal’s Gamma.
- ↑ siehe Engelmann, Hayden, Tasche (2003, S. 23)
- ↑ siehe Bemmann (2005, S. 22f.)
- ↑ siehe Bemmann (2005, Abschnitt 2.3.4)
- ↑ siehe Lawrenz, Schwaiger (2002)
Literatur
- Basler Ausschuss: siehe Basler Ausschuss für Bankenaufsicht
- Basler Ausschuss für Bankenaufsicht (Hrsg.)(2000b): Range of Practice in Banks’ Internal Ratings systems, Diskussionspapier, Bank für internationalen Zahlungsausgleich (BIS), http://www.bis.org/publ/bcbs66.pdf (18. Oktober 2006), 01/2000
- Basler Ausschuss für Bankenaufsicht (Hrsg.)(2000c): Credit Ratings and Complementary Sources of Credit Quality Information, Working Paper #3, http://www.bis.org/publ/bcbs_wp3.pdf (18. Oktober 2006), 2000
- Basler Ausschuss für Bankenaufsicht (Hrsg.)(2005a): Studies on the Validation of Internal Rating Systems, Working Paper No. 14, http://www.bis.org/publ/bcbs_wp14.pdf (24. Oktober 2005), überarbeitete Version, 05/2005
- Bemmann, M. (2005): Verbesserung der Vergleichbarkeit von Schätzgüteergebnissen von Insolvenzprognosestudien, in Dresden Discussion Paper Series in Economics 08/ 2005, http://ideas.repec.org/p/wpa/wuwpfi/0507007.html (8. November 2006) und http://papers.ssrn.com/sol3/papers.cfm?abstract_id=738648 (27. November 2006), 2005
- Blochwitz, S., Liebig, T., Nyberg, M. (2000): Benchmarking Deutsche Bundesbank’s Default Risk Model, the KMV® Private Firm Model® and Common Financial Ratios for German Corporations, Workshop on Applied Banking Research, Basler Ausschuss für Bankenaufsicht, http://www.bis.org/bcbs/events/oslo/liebigblo.pdf (16. August 2004), 2000
- Blochwitz, S., Hohl, S., Tasche, D., Wehn, C.S. (2004): Validating Default Probabilities on Short Time Series, http://www.chicagofed.org/publications/capital_and_market_risk_insights/2004/validating_default_probabilities.pdf (27. November 2006), Working Paper, Federal Reserve Bank of Chicago, 05/2004
- Cantor, R., Mann, C. (2003): Measuring the Performance of Corporate Bond Ratings, Special Comment, Report #77916, Moody’s Investor’s Service, 04/2003
- Deutsche Bundesbank (Hrsg.) (2003a): Validierungsansätze für interne Ratingsysteme, in: Monatsbericht September 2003, S. 61-74, http://www.bundesbank.de/download/volkswirtschaft/mba/2003/200309mba_validierung.pdf (30. Oktober 2006), 09/2003
- Engelmann, B., Hayden, E., Tasche, D. (2003): Measuring the Discriminative Power of Rating Systems, Deutsche Bundesbank, Discussion Paper, Series 2: Banking and Financial supervision, http://www.bundesbank.de/download/bankenaufsicht/dkp/200301dkp_b.pdf (30. Oktober 2006), 01/2003
- Englisch, W. B., Nelson, W. R. (1998): Bank Risk Rating of Business Loan, Board of Governors of the Federal Reserve System FEDS Paper No. 98-51, http://ssrn.com/abstract=148753 (18. Oktober 2006), 12/1998
- Fahrmeir, L., Henking, A., Hüls, R. (2002): Methoden zum Vergleich verschiedener Scoreverfahren am Beispiel der SCHUFA-Scoreverfahren, Risknews, 11/2002, S. 20-29, 2002
- Falkenstein, E., Boral, A., Kocagil, A. E. (2000): RiskCalcTM for Private Companies II: More Results and the Australian Model, Moody’s Investors Service, Rating Methodology, Report # 62265, http://riskcalc.moodysrms.com/us/research/crm/62265.pdf (30. Oktober 2006), 12/2000
- Frerichs, H., Wahrenburg, M. (2003): Evaluating internal credit rating systems depending on bank size, Working Paper Series: Finance and Accounting, Johann Wolfgang Goethe-Universität Frankfurt Am Main, No. 115, http://ideas.repec.org/p/fra/franaf/115.html (14. November 2006), 09/2003
- Grunert, J., Norden, L., Weber, M. (2005): The role of non-financial factors in internal credit ratings, in Journal of Banking and Finance, Bd. 29, S. 509-531, 2005
- Hamerle, A., Rauhmeier, R., Rösch, D. (2003): Uses and Misuses of Measures for Credit Rating Accuracy, Version 04/2003, Working Paper, University of Regensburg, http://www.defaultrisk.com/pp_test_25.htm (30. Oktober 2006), 2003
- Huschens, S., Höse, S. (2003): Sind interne Ratingsysteme im Rahmenvon Basel II evaluierbar? – Zur Schätzung von Ausfallwahrscheinlichkeiten durch Ausfallquoten, in: Zeitschrift für Betriebswirtschaft (ZfB), Bd. 73 (2), S. 139-168, 2003
- Keenan, S.C., Sobehart, J.R. (1999): Performance Measures for Credit Risk Models, Moody’s Investors Service, Research Report # 1-10-10-99, http://www.riskmania.com/pdsdata/PerformanceMeasuresforCreditRiskModels.pdf (6. November 2006), 1999
- Krämer, W. (2003): Die Bewertung und der Vergleich von Kreditausfall-Prognosen, in: Kredit und Kapital, Bd. 36 (3), S. 395-410, 2003
- Krämer, W., Güttler, A. (2003): Comparing the accuracy of default predictions in the rating industry: The case of Moody’s vs. S&P, Technical Report-Reihe des SFB 475 Nr. 23 (Universität Dortmund), http://www.wiwi.uni-frankfurt.de/schwerpunkte/finance/wp/332.pdf (6. November 2006), 2003
- Lawrenz, J., Schwaiger, W.S.A. (2002): Bank Deutschland: Aktualisierung der Quantitative Impact Study (QIS2) von Basel II, in: Risknews 01/2002, S. 5-30, 2002
- Lee, W.-C. (1999): Probabilistic Analysis of Global Performances of Diagnostic Tests: Interpreting the Lorenz Curve-Based Summary Measures, in Statistics in Medicine, Bd. 18, S. 455-471, 1999
- Lehmann, B. (2003): Is It Worth the While? The Relevance of Qualitative Information in Credit Rating, EFMA 2003 Helsinki Meetings, http://ssrn.com/abstract=410186 (26. Oktober 2006), 04/2003
- McQuown, J. A. (1993): A Comment on Market vs. Accounting-Based Measures of Default Risk, KMV Working Paper, http://www.moodyskmv.com/research/whitepaper/A_Comment_on_Market_vs_Accounting_Based_Measures_of_Default_Risk.pdf (23. Oktober 2006), KMV Corporation, 1993
- Moody's (Hrsg.)(2004b): Moody’s Rating Symbols & Definitions, Moody’s Investors Service, Report #79004, 08/2004
- Moody's (Hrsg.)(2005): Default and Recovery Rates of Corporate Bond Issuers, 1920-2004, Moody’s Investors Service, 01/2005
- Moody's (Hrsg.)(2006): Default and Recovery Rates of Corporate Bond Issuers, 1920-2005, Moody’s Investors Service, 01/2006
- OeNB: siehe Österreichische Nationalbank
- Österreichische Nationalbank (Hrsg.)(2004a): Ratingmodelle und -validierung, Leitfadenreihe zum Kreditrisiko, http://www.nationalbank.at/de/img/leitfadenreihe_ratingmodelle_tcm14-11172.pdf (18. Oktober 2006), Wien, 2004
- S&P: siehe Standard and Poor's
- Scheule, H. (2003): Prognose von Kreditausfallrisiken, zugelassene Dissertation Universität Regensburg, Uhlenbruch Verlag, Bad Soden/Ts., 2003
- Schwaiger, W.S.A. (2002): Auswirkungen von Basel II auf den österreichischen Mittelstand nach Branchen und Bundesländern, in Österreichisches Bankarchiv, 06/2002, S. 433-446, 2002
- Standard and Poor's (Hrsg.)(2003b): Corporate Ratings Criteria, The McGraw Hills Companies, 2003
- Standard and Poor's (Hrsg.)(2005): Annual Global Corporate Default Study: Corporate Defaults Poised to Rise in 2005, Global Fixed Income Research, The McGraw Hills Companies, 2005
- Sobehart, J. R., Stein, R. M., Mikityanska, V., Li, L. (2000): Moody’s Public Firm Risk Model: A Hybrid Approach to Modeling Short Term Default Risk, Moody’s Investors Service, Rating Methodology, Report #53853, 03/2000
- Sobehart, J.R., Keenan, S.C., Stein, R.M. (2000): Benchmarking Quantitative Default Risk Models: A Validation Methodology, Moody’s Investors Service, Rating Methodology, Report # 53621, http://www.moodysqra.com/us/research/crm/53621.pdf (6. November 2006), 03/2000
- Somers, R. H. (1962): A new asymmetric measure of association for ordinal variables, American Sociological Review, Bd. 27 (6), S. 799-811, 1962
- Standard and Poor's (Hrsg.)(2006): Annual 2005 Global Corporate Default Study And Rating Transitions, Global Fixed Income Research, The McGraw Hills Companies, 2006
- Stein, R. M. (2002): Benchmarking Default Prediction Models, Pitfalls and Remedies in Model Validation, Moody’s KMV, Report #030124, http://www.defaultrisk.com/pp_test_20.htm (30. Oktober 2006), 2002
- Swets, J. A. (1988): Measuring the Accuracy of Diagnostic Systems, in Science, Bd. 240, S. 1285-1293, 1988
- Treacy, W. F., Carey, M. S. (2000): Credit Risk Rating at Large U.S. Banks, in Journal of Banking and Finance, Bd. 24 (1-2), S. 167-201, 2000

Wikimedia Foundation.