- Sensorfusion
-
Die Informationsfusion umfasst Methoden, um Daten aus unterschiedlichen Sensoren oder Informationsquellen zu verknüpfen mit dem Ziel, neues und präziseres Wissen über Messwerte und Ereignisse zu gewinnen.
Verwandte Disziplinen sind die Sensorfusion, die Datenfusion sowie das verteilte Messen.
Inhaltsverzeichnis
Geschichte
Die theoretischen Ursprünge der Informationsfusion gehen auf das Ende der sechziger Jahre zurück. Allerdings wurden diese mathematischen Prinzipien erst später auf die Technik übertragen - zunächst im Bereich der Künstlichen Intelligenz (KI). In dieser Disziplin wurde oftmals die Biologie, insbesondere das menschliche Gehirn, als Vorbild zur Modellierung technischer Systeme herangezogen. Berücksichtigt man die Leistungsfähigkeit des Gehirns bei der Fusion von Daten aus den unterschiedlichen Sinnesorganen, so ist es nicht verwunderlich, dass die ersten Ansätze gerade aus der KI stammen.
Inzwischen ist der Einsatz von Informationsfusion sehr breit und umfasst viele unterschiedliche Disziplinen - darunter Robotik, Mustererkennung, Medizin, zerstörungsfreie Prüfung, Geowissenschaften, Verteidigung und Finanzen. Obwohl die Literatur dazu sehr umfangreich ist, sind viele der darin angegebenen Verfahren jedoch wenig systematisch.
Methoden
In den letzten Jahren haben sich einige systematische Fusionsansätze herauskristallisiert, von denen an dieser Stelle die wichtigsten kurz erörtert werden sollen. Dafür sei zunächst das Fusionsproblem als Parameterschätzmodell formuliert. Von einer Quelle wird ein Parameter r emittiert, der eine Realisierung der Zufallsgröße R darstellt. Bei der Zielgröße r kann es sich um eine Messgröße handeln, aber auch um latente Konstrukte, die keinen Anspruch auf physikalische Realität haben müssen. Im letzteren Fall kann die Größe r im platonischen Sinne als eine Idealisierung der Sensordaten di verstanden werden, bei der gewünschte oder bekannte Eigenschaften der Zielgröße selbst berücksichtigt werden. Mit Hilfe mehrerer Sensoren werden die Daten
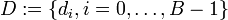 erfasst, welche ebenfalls als Realisierungen eines Zufallsprozesses D aufzufassen sind. Die Messung entspricht einer Abbildung
erfasst, welche ebenfalls als Realisierungen eines Zufallsprozesses D aufzufassen sind. Die Messung entspricht einer Abbildung 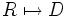 , die sich mathematisch mittels der bedingten Wahrscheinlichkeitsverteilung (WV) von D | R beschreiben lässt. Im Folgenden sei angenommen, dass es sich bei r und d um kontinuierliche Größen handelt, die WV anhand einer Wahrscheinlichkeitsdichtefunktion (WDF) beschrieben wird.
, die sich mathematisch mittels der bedingten Wahrscheinlichkeitsverteilung (WV) von D | R beschreiben lässt. Im Folgenden sei angenommen, dass es sich bei r und d um kontinuierliche Größen handelt, die WV anhand einer Wahrscheinlichkeitsdichtefunktion (WDF) beschrieben wird.Klassische Statistik
Der klassischen Statistik liegt eine empirische, frequentistische Interpretation von Wahrscheinlichkeiten zugrunde, bei der zwar die Sensordaten als Zufallsgrößen angesehen werden, nicht jedoch die Messgröße r selbst. Die Schätzung von r anhand der Sensordaten di stützt sich auf die sogenannte Wahrscheinlichkeitsfunktion pD | R(D | r), die dafür als Funktion von r aufgefasst und maximiert wird:
Der zugehörige Wert
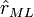 heißt Maximum-Likelihood- oder ML-Schätzwert.
heißt Maximum-Likelihood- oder ML-Schätzwert.Bayessche Statistik
In der Bayesschen Statistik wird auch die Messgröße r als Realisierung einer Zufallsgröße R aufgefasst, weshalb die a priori WDF pR(r) zur Bestimmung der a posteriori WDF pR | D(r | D) herangezogen wird:
Durch Maximierung dieser Gleichung erhält man die Maximum a posteriori (MAP) Lösung für den zu schätzenden Parameter r:
Diese Vorgehensweise hat den wesentlichen Vorteil, dass sie die Angabe der WV für den zu schätzenden Parameter r bei gegebenen Messdaten D zulässt, wohingegen die Klassische Vorgehensweise lediglich die Angabe der WV für die Sensordaten D bei gegebenem Parameterwert r erlaubt.
Dempster-Shafer-Evidenztheorie
Die Evidenztheorie wird oftmals als eine Erweiterung der Wahrscheinlichkeitstheorie oder als eine Verallgemeinerung der Bayesschen Statistik betrachtet. Sie basiert auf zwei nichtadditiven Maßen – dem Grad des Dafürhaltens (englisch: degree of belief) und der Plausibilität – und bietet die Möglichkeit, Ungewissheit detaillierter auszudrücken. In praktischen Aufgabenstellungen ist es jedoch nicht immer möglich, das verfügbare Wissen über die relevanten Größen derart differenziert darzustellen und somit die theoretischen Möglichkeiten dieses Ansatzes voll auszuschöpfen.
Fuzzy-Logik
Die Fuzzy-Logik basiert auf der Verallgemeinerung des Mengenbegriffes mit dem Ziel, eine unscharfe Wissensrepräsentation zu erlangen. Dies erfolgt anhand einer sogenannten Zugehörigkeitsfunktion, die jedem Element einen Grad der Zugehörigkeit zu einer Menge zuordnet. Aufgrund der Willkür bei der Wahl dieser Funktion stellt die Fuzzy-Mengentheorie eine sehr subjektive Methode dar, die sich daher besonders zur Repräsentation von menschlichem Wissen eignet. In der Informationsfusion werden Fuzzy-Methoden eingesetzt, um Ungewissheit und Vagheit im Zusammenhang mit den Sensordaten zu handhaben.
Neuronale Netze
Eine weitere Methode zur Fusion von Information sind die künstlichen Neuronalen Netze (KNN). Diese können auf durch Software simulierten Verarbeitungseinheiten basieren, die zu einem Netzwerk verschaltet werden, oder in Hardware realisiert sein, um bestimmte Aufgaben zu lösen. Ihr Einsatz ist besonders vorteilhaft, wenn es schwer oder nicht möglich ist, einen Algorithmus zur Kombination der Sensordaten zu spezifizieren. In solchen Fällen wird dem neuronalen Netz in einer Trainingsphase mit Hilfe von Testdaten das gewünschte Verhalten beigebracht. Nachteilig an neuronalen Netzen sind die mangelnden Möglichkeiten zur Einbindung von a priori Wissen über die an der Fusion beteiligten Größen.
Weblinks
- http://www.elsevier.com/locate/inffus Information Fusion Journal
- http://www.informationsfusion.de Sensor- und Informationsfusion, Technische Universität München
- http://www.mrt.uni-karlsruhe.de/fus.html Informationsfusion, Universität Karlsruhe (TH)
- http://www.isif.org/ International Society of Information Fusion
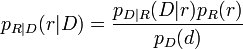
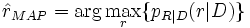
Wikimedia Foundation.