- Topologische Ordnung
-
Topologische Sortierung bezeichnet eine Reihenfolge von Dingen, bei der vorgegebene Abhängigkeiten erfüllt sind. Der Name „topologische Sortierung“ leitet sich von den griechischen Wörtern τόπος (tópos = „Ort“/„Platz“) und λόγος (lógos = eigentlich „Wort“, im weiteren Sinn „Lehre von ...“) ab, hat aber nichts mit der mathematischen Disziplin Topologie zu tun.
Anstehende Tätigkeiten einer Person etwa unterliegen einer Halbordnung: es existieren Bedingungen wie „Tätigkeit A muss vor Tätigkeit B erledigt werden“. Eine Reihenfolge, welche alle Bedingungen erfüllt, nennt man topologische Sortierung der Menge anstehender Tätigkeiten. Im Gegensatz zur Sortierung einer Totalordnung ist die Reihenfolge nicht eindeutig, sondern es kann mehrere Möglichkeiten geben. Wenn gegenseitige Abhängigkeiten bestehen, ist eine topologische Sortierung unmöglich.
Die topologische Sortierung ist bei vielen Anwendungen der Informatik ein wichtiges Konzept. Bereits 1961 wurde von Daniel J. Lasser ein Algorithmus entwickelt, mit dem eine topologische Sortierung ganz allgemein erstellt werden kann. Zuvor waren allerdings schon Algorithmen für spezielle Anwendungen bekannt.
Des Weiteren spielt die topologische Sortierung in der Graphentheorie bei der Untersuchung von gerichteten Graphen auf Zyklenfreiheit eine große Rolle. 1930 zeigte Edward Szpilrajn, dass sich jede partielle Ordnung topologisch sortieren lässt.
Inhaltsverzeichnis
- 1 Das Problem
- 2 Algorithmus
- 3 Beispiele
- 4 Siehe auch
- 5 Literatur
- 6 Weblinks
Das Problem
Verschiedene Objekte können nach messbaren Größen, zum Beispiel Städte nach Einwohnerzahlen, Schuhe nach Schuhgrößen, aber auch alphabetisch nach Namen eindeutig sortiert werden. Oft gelingt dies jedoch nicht mehr, wenn nur Beziehungen der Form Vorgänger/Nachfolger angegeben werden und solche Beziehungen nicht für jedes Paar von Objekten vorhanden sind. Gegenseitige Abhängigkeiten können darüber hinaus eine Sortierung unmöglich machen (etwa beim Schachspiel: Anton gewinnt gegen Bernd, Bernd gewinnt gegen Clemens und Clemens gewinnt gegen Anton). Gelingt es, die Objekte in eine Reihenfolge zu bringen, bei der Vorgänger stets vor Nachfolgern auftreten, so ist diese Reihenfolge eine topologische Sortierung der Objekte.
Je nach Art der Beziehungen kann es keine, nur eine oder mehrere verschiedene topologische Sortierungen geben. Wenn gegenseitige (zyklische) Abhängigkeiten bestehen, ist eine topologische Sortierung nicht möglich. In der Tat ist ein Anwendungsgebiet der topologischen Sortierung die Überprüfung, ob zyklische Abhängigkeiten bestehen.
Beispiel: Anziehreihenfolge von Kleidungsstücken
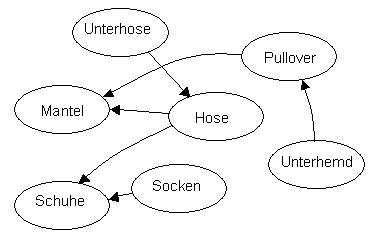
Beim Anziehen von Kleidungsstücken müssen manche Teile unbedingt vor anderen angezogen werden. So muss ein Pullover vor einem Mantel angezogen werden.
Hat man zum Beispiel eine Hose, ein Unterhemd, Pullover, Mantel, Socken, eine Unterhose und ein Paar Schuhe, so kann man die folgenden Beziehungen für das Anziehen angeben.
- Das Unterhemd vor dem Pullover
- Die Unterhose vor der Hose
- Den Pullover vor dem Mantel
- Die Hose vor dem Mantel
- Die Hose vor den Schuhen
- Die Socken vor den Schuhen
Um eine sinnvolle Reihenfolge zu bestimmen, können die sieben Kleidungsstücke topologisch sortiert werden, also etwa
- Erst die Unterhose, dann die Socken, Hose, Unterhemd, Pullover, Mantel, Schuhe.
Aber auch
- Erst das Unterhemd, dann die Unterhose, dann Pullover, Socken, Hose, Schuhe, Mantel.
Jedoch nicht
- Erst den Pullover,
da das Unterhemd vorher angezogen werden muss.
Mathematische Beschreibung des Problems
Die zu sortierende Menge
Die zu sortierenden Objekte müssen bezüglich der Beziehung teilweise angeordnet werden können, damit sie topologisch sortierbar sind. Mathematisch bilden die Objekte die Elemente einer Menge M, die bezüglich einer Relation (Beziehung) R die folgenden Eigenschaften hat:
Für jeweils beliebige Elemente a,b,c der Menge M und der Relation R gilt:
- Irreflexivität:
 (a steht nicht mit a in Relation)
(a steht nicht mit a in Relation) - Transitivität: Wenn
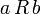 und
und 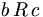 , dann gilt
, dann gilt  .
.
Übersetzt heißt dies:
- Ich kann die Hose nicht vor der Hose anziehen.
- Wenn ich das Unterhemd vor dem Pullover anziehen muss und den Pullover vor dem Mantel, so folgt daraus, dass ich das Unterhemd vor dem Mantel anziehen muss.
Die Menge M bildet dann bezüglich der Relation R eine strenge Halbordnung. Oft schreibt man statt R auch einfach < , weil die Relation ähnliche Eigenschaften hat wie die Kleiner-Relation für Zahlen. (Allerdings hat die Kleiner-Relation noch ein paar weitere Eigenschaften, die man hier nicht unbedingt hat. So kann man bei der Kleiner-Relation von zwei verschiedenen Zahlen immer entscheiden, welche der beiden kleiner ist. Hier ist dies nicht verlangt. Im Beispiel wäre dies der Vergleich von Socken und Unterhemd: Man kann nicht sagen, dass eines davon zuerst angezogen werden muss.)
Üblicherweise wird jedoch nicht die ganze Relation R angegeben, sondern nur eine ausreichende Teilmenge von direkten Vorgänger-Nachfolger-Paaren. Die Relation R ist dann über den transitiven Abschluss der durch die übergebenen Paare definierten Relation gegeben. Beispielsweise besagt die komplette Relation R für das Beispielproblem auch, dass das Unterhemd vor dem Mantel angezogen werden muss (wegen „Unterhemd vor Pullover“ und „Pullover vor Mantel“ folgt aus der Transitivität auch „Unterhemd vor Mantel“). Der transitive Abschluss besteht nun darin, diese Paare der Relation R hinzuzufügen. Bei der Implementierung eines entsprechenden Sortieralgorithmus wird allerdings die vollständige Relation nicht explizit generiert.
Die topologisch sortierte Menge
Eine bestimmte Reihenfolge hingegen wird mathematisch durch eine strenge Totalordnung definiert: Für je zwei verschiedene Elemente a,b aus M ist festgelegt, ob a vor b oder b vor a kommt (Es steht z. B. fest, ob ich heute Morgen zuerst die Unterhose oder zuerst das Unterhemd angezogen habe). Die strenge Totalordnung ist also mathematisch definiert durch das zusätzliche Axiom der
- Trichotomie: Für beliebige Elemente a,b aus M gilt entweder aRb oder a = b oder bRa.
Die Aufgabe des topologischen Sortierens ist nun, zu einer gegebenen strengen Halbordnung R eine Totalordnung
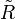 zu finden, so dass für alle a,b mit aRb auch gilt
zu finden, so dass für alle a,b mit aRb auch gilt 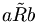 .
.Definition der topologischen Sortierung
Motiviert durch die Untersuchungen der beiden vorhergehenden Abschnitte kann man nun den mathematischen Begriff einer topologischen Sortierung einführen:
Sei M eine Menge und
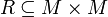 . Eine Menge
. Eine Menge 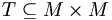 heißt genau dann eine topologische Sortierung von M für R, wenn T eine strenge Totalordnung auf M ist und
heißt genau dann eine topologische Sortierung von M für R, wenn T eine strenge Totalordnung auf M ist und 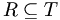 gilt.
gilt.Diese Definition beschränkt den Begriff einer topologischen Sortierung ausdrücklich nicht auf endliche Mengen, obwohl im Zusammenhang mit einer algorithmischen Untersuchung eine solche Beschränkung sinnvoll ist.
Azyklische Graphen und topologische Sortierungen
Den bereits erwähnten Zusammenhang von topologischen Sortierungen und azyklischen Graphen kann man in folgendem Satz zusammenfassen:
Sei M eine Menge und
. Dann sind äquivalent:- Es gibt eine topologische Sortierung T von M für R
- (M,R) ist ein azyklischer Digraph
Darstellung als gerichteter Graph
Stellt man eine Beziehung als Pfeil zwischen zwei Elementen dar, entsteht ein gerichteter Graph:
Die Kleidungsstücke kann man topologisch sortieren, indem man sie linear anordnet und darauf achtet, dass alle Pfeile nur von links nach rechts weisen:
Sortierbare Graphen
-
 Graph 1
Graph 1
Graph 1 ist topologisch sortierbar. Es existieren mehrere Lösungen (zum Beispiel A B C G D E F). Dabei spielt es keine Rolle, dass mehrere Elemente ohne Vorgänger existieren (A und G), dass manche Elemente mehrere Nachfolger haben (B hat zum Beispiel drei Nachfolger) und manche mehrere Vorgänger (D und E).
-
 Graph 2
Graph 2
Graph 2 ist ebenfalls topologisch sortierbar (zum Beispiel A C B D E), obwohl er nicht zusammenhängend ist.
Alle Graphen, die keine Zyklen enthalten (so genannte azyklische Graphen, siehe auch Baum), sind topologisch sortierbar.
Nicht sortierbare Graphen
-
 Graph 3
Graph 3
Graph 3 ist nicht topologisch sortierbar, da er einen Zyklus, also eine gegenseitige Abhängigkeit enthält (Elemente B, C, E und D).
-
 Graph 4
Graph 4
Auch wenn wie in Graph 4 nur zwei Elemente gegenseitig voneinander abhängen oder wenn ein Element sich auf sich selbst bezieht (Graph 5), ist eine topologische Sortierung unmöglich.
-
 Graph 5
Graph 5
Alle Graphen, die zyklische Abhängigkeiten enthalten, sind nicht topologisch sortierbar. Die topologische Sortierung kann daher auch zur Prüfung eines gerichteten Graphen auf Zyklen verwendet werden.
Algorithmus
Entfernung von Elementen ohne Vorgänger
Der Algorithmus geht von einem gerichteten Graphen aus. Er entfernt solange Elemente ohne Vorgänger aus dem Graphen, bis keine Elemente mehr übrig sind.
Zunächst werden alle Elemente mit der Vorgängerzahl, also der Anzahl von Pfeilspitzen, die zum jeweiligen Element führen, versehen:
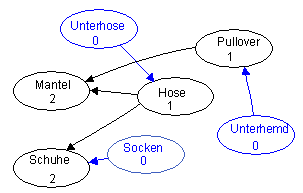
Elemente mit Vorgängerzahl 0 (blau markiert) haben keine anderen Vorgänger. Sie werden aus dem Graph entfernt. Hier können also die Socken, die Unterhose und das Unterhemd mit den zugehörigen Pfeilen entfernt werden. Dadurch ändern sich auch die Vorgängerzahlen von anderen Elementen:
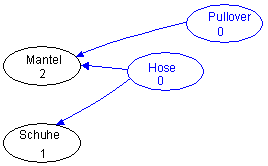
- Entfernte Elemente:
- Socken Unterhose Unterhemd
Jetzt haben der Pullover und die Hose keine Vorgänger mehr, sie können also entfernt werden:
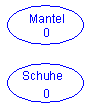
- Entfernte Elemente:
- Socken Unterhose Unterhemd Hose Pullover
Nun bleiben nur noch Mantel und Schuhe übrig, die ebenfalls entfernt werden. Die Topologische Sortierung ist fertig, wenn alle Elemente entfernt werden konnten:
- Topologische Sortierung:
- Socken Unterhose Unterhemd Hose Pullover Mantel Schuhe
Repräsentation im Rechner
Die Objekte (Elemente) selbst werden normalerweise in die
- Datenstruktur einer Liste mit Objektattributen (Name, Index, ...)
eingetragen. Um die Beziehungen darzustellen, genügt für jedes Element jeweils eine zusätzliche
- Liste mit Verweisen (Referenzen oder Zeiger) auf die Nachfolger eines Objekts. Die Objekte enthalten einen Verweis auf ihre jeweilige Nachfolgerliste.
Für den Sortieralgorithmus wird Platz für weitere Daten benötigt, die vom Algorithmus beschrieben und verwendet werden:
- Für jedes Objekt Platz für eine Zahl, die die Anzahl der Vorgänger aufnimmt.
- Optional eine Hilfsliste, die Objekte ohne Vorgänger aufnimmt.
Beispiel:
Für das Ankleidebeispiel weiter oben sähe die Objektliste z. B. folgendermaßen aus:
- Hose
- Mantel
- Pullover
- Schuhe
- Socken
- Unterhemd
- Unterhose
Die Nachfolgerlisten sähen dann folgendermaßen aus:
- 2, 4
- (leere Liste)
- 2
- (leere Liste)
- 4
- 3
- 1
Dabei besagt die erste Liste (für die Hose), dass Mantel (Objekt 2) und Schuhe (Objekt 4) erst nach der Hose angezogen werden können. Die zweite Liste (für den Mantel) besagt, dass es kein Kleidungsstück gibt, das erst nach dem Mantel angezogen werden kann.
Die Liste der Vorgängerzahlen hat 7 Elemente (eins pro Objekt), anfänglich sind alle Einträge 0.
Algorithmus für das Topologische Sortieren
Einfache Version mit Markierung von Elementen
Der Sortieralgorithmus benötigt die Information, wie viele Vorgänger ein Element enthält (Vorgängeranzahl). Bereits gefundene Elemente müssen aus der Liste entfernt oder markiert werden. Man kann Elemente dadurch markieren, indem man die Vorgängeranzahl auf –1 setzt.
- 1. Berechne die Vorgängeranzahl:
-
- Setze die Vorgängeranzahl aller Elemente auf 0.
- Für alle Elemente durchlaufe die Nachfolgerliste und erhöhe die Vorgängeranzahl jedes dieser Elemente um 1.
(Jetzt sind alle Vorgängerzahlen berechnet)
-
Im Beispiel hat z. B. die Hose (Element 1) nur einen Vorgänger (die Unterhose), daher taucht die 1 nur einmal in den Nachfolgerlisten auf. Der Mantel (Element 2) hat hingegen 2 Vorgänger (Pullover und Hose), weshalb die 2 zweimal in den Nachfolgerlisten auftaucht. Insgesamt ergibt sich also für die Vorgängerliste:
- 1
- 2
- 1
- 2
- 0
- 0
- 0
- 2. Solange (nicht markierte) Elemente in der Liste sind:
-
- Suche ein Element mit Vorgängeranzahl 0.
Falls kein solches Element gefunden wird, ist eine topologische Sortierung nicht möglich, da gegenseitige Abhängigkeiten (Zyklen) bestehen. Der Algorithmus bricht mit einem Fehler ab. - Gib das gefundene Element aus und entferne es aus der Liste oder markiere es (Setze zum Beispiel die Vorgängeranzahl gleich –1 als Markierung)
- Gehe die Liste der Nachfolger des gefundenen Elements durch und verringere die Vorgängeranzahl um 1. Das Element ist jetzt effektiv aus der Elementliste entfernt. Durch die Verringerung der Vorgängeranzahl können neue Elemente ohne Vorgänger entstehen.
- Suche ein Element mit Vorgängeranzahl 0.
-
- Sind alle Elemente ausgegeben bzw. markiert, so war die topologische Sortierung erfolgreich.
Im Beispiel ist Element 5 (Socken) ein solches vorgängerloses Element. Daher wird dieses Element ausgegeben und mit –1 markiert (wir hätten aber genauso gut mit Element 6 oder 7 anfangen können). Einziges Nachfolgerobjekt der Socken sind die Schuhe (Element 4), daher wird die Vorgängeranzahl von Element 4 verringert. Nach diesem Schritt lautet die Vorgängeranzahlliste also
- 1
- 2
- 1
- 1
- –1
- 0
- 0
und die bisherige Ausgabe lautet: Socken
Im nächsten Schritt stellen wir fest, dass auch Element 6 (Unterhemd) keine Vorgänger hat. Wiederum gibt es nur ein einziges Nachfolgerelement, den Pullover (Nummer 3). Somit lautet die Vorgängerzahlliste nach dem zweiten Schritt:
- 1
- 2
- 0
- 1
- –1
- –1
- 0
und die Ausgabe bis hierhin lautet: Socken, Unterhemd
Durch die Verringerung um 1 wurde die Vorgängerzahl des Pullovers (Element 3) zu 0. Nehmen wir also als nächstes den Pullover, so finden wir in seiner Nachfolgerliste nur Element 2 (den Mantel), dessen Vorgängerzahl wir somit ebenfalls verringern müssen, so dass die Liste nun
- 1
- 1
- –1
- 1
- –1
- –1
- 0
lautet, und die bisherige Ausgabe: Socken, Unterhemd, Pullover.
Jetzt haben wir zum ersten Mal keine Wahl mehr über das nächste Element: Nur die Unterhose hat jetzt die Vorgängerzahl 0. Deren Entfernung führt dann im nächsten Schritt zu einer 0 bei der Hose (Element 1), und deren Entfernung führt schließlich dazu, dass sowohl Element 2 (Mantel) als auch Element 4 (Schuhe) keine Vorgänger mehr haben. Wählen wir nun den Mantel vor den Schuhen, so ergibt sich insgesamt die Sortierung
Socken, Unterhemd, Pullover, Unterhose, Hose, Mantel, Schuhe,
die unschwer als korrekte topologische Sortierung dieser Elemente erkannt werden kann.
Erweiterte Version mit einer zusätzlichen Hilfsliste
Um Elemente ohne Vorgänger schnell zu finden, kann eine zusätzliche Hilfsliste erzeugt werden. Diese wird nach der Berechnung der Vorgängerzahlen mit allen anfangs vorgängerlosen Elementen, also mit Vorgängerzahl gleich Null, gefüllt. In Phase 2 wird anstatt der Suche eines Elements mit Vorgängeranzahl Null einfach eines aus der Hilfsliste entnommen. Wird die Vorgängerzahl eines Elements während der Phase 2 bei der Verringerung um 1 gleich Null, so wird es in die Hilfsliste eingefügt. Der Algorithmus endet, wenn keine Elemente mehr in der Hilfsliste sind. Auf die Markierung kann dann ebenfalls verzichtet werden.
Zeitverhalten (Komplexität)
Die Komplexität des Algorithmus beschreibt das zeitliche Verhalten bei großen Datenmengen, genauer das Verhältnis der Ausführungsdauern bei Vergrößerung der Eingabedaten. Braucht ein Algorithmus also z. B. für N Datensätze N2 + 10000 Schritte, so ist die Komplexität
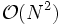 , da für hinreichend große Datenmengen die 10000 zusätzlichen Schritte nicht mehr ins Gewicht fallen.
, da für hinreichend große Datenmengen die 10000 zusätzlichen Schritte nicht mehr ins Gewicht fallen.Average- und Worst-Case
Beim topologischen Sortieren mit n Elementen und m Beziehungen zwischen diesen gilt für „normale“ (Average-Case) Probleme
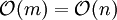 , da jedes Element im Schnitt nur eine konstante Zahl von Beziehungen hat. Im Extremfall (Worst-Case) können in einem gerichteten azyklischen Graphen jedoch
, da jedes Element im Schnitt nur eine konstante Zahl von Beziehungen hat. Im Extremfall (Worst-Case) können in einem gerichteten azyklischen Graphen jedoch 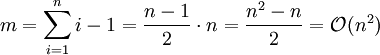 Beziehungen auftreten.
Beziehungen auftreten.Erste Phase: Aufbau der Vorgängerzahlen
Die erste Phase setzt die Vorgängerzahlen auf 0 und benötigt n Schleifendurchläufe (
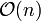 ). Für das Durchlaufen der m Nachfolger benötigt sie eine Zeit der Größenordnung (Average-Case) oder
). Für das Durchlaufen der m Nachfolger benötigt sie eine Zeit der Größenordnung (Average-Case) oder 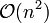 (Worst-Case).
(Worst-Case).Hilfsliste für vorgängerlose Elemente
Vor der zweiten Phase wird eine Hilfsliste aufgebaut, die alle vorgängerlosen Elemente enthält (
). Danach werden nur noch neue vorgängerlose in die Hilfsliste eingefügt (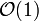 ) und entnommen (). Die Suche nach vorgängerlosen Elementen beeinflusst das Zeitverhalten nicht. Gleiches kann man erreichen, indem man gefundene vorgängerlose Elemente „nach vorne“ verlagert (mit möglich).
) und entnommen (). Die Suche nach vorgängerlosen Elementen beeinflusst das Zeitverhalten nicht. Gleiches kann man erreichen, indem man gefundene vorgängerlose Elemente „nach vorne“ verlagert (mit möglich).Zweite Phase: Entnahme von vorgängerlosen Elementen
Die zweite Phase behandelt im Erfolgsfall alle n Elemente und verringert die Vorgängerzahl von im Schnitt
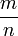 Nachfolgern, das Zeitverhalten ist also
Nachfolgern, das Zeitverhalten ist also 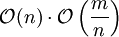 .
.Gesamtverhalten
Beziehungen m
und Objekte nZeitverhalten
(mit Hilfsliste)Average-Case Worst-Case 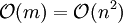
Ungünstiger Aufbau der Listen
Der Algorithmus in Wirths Buch (siehe Literatur) enthält eine Einlesephase, in der er die Beziehungspaare in eine Liste einfügt, die wiederum Listen für die Nachfolger enthalten. Die jeweilige Nachfolgerliste ermittelt er durch eine lineare Suche (
), die für jedes eingelesene Paar (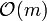 ) durchgeführt wird, insgesamt also
) durchgeführt wird, insgesamt also 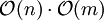 (quadratisch). Dies verschlechtert das gesamte Zeitverhalten. Der Aufbau der Listen könnte zum Beispiel über einen Bucketsort-Algorithmus aber auch in linearer Zeit bewerkstelligt werden.
(quadratisch). Dies verschlechtert das gesamte Zeitverhalten. Der Aufbau der Listen könnte zum Beispiel über einen Bucketsort-Algorithmus aber auch in linearer Zeit bewerkstelligt werden.Programm in der Programmiersprache Perl
In der Programmiersprache Perl können Listen besonders einfach mit Hilfe von dynamisch wachsenden Feldern (zum Beispiel
@Elemente) implementiert werden. Das angegebene Programm liest zunächst Beziehungspaare der Form Vorgänger Nachfolger, jeweils in einer Zeile und mit Leerzeichen getrennt, ein:Katze Hund Hahn Katze Hund Esel
Als Ausgabe erhält man
Hahn Katze Hund Esel
Beim Einlesen der Beziehungspaare dient ein Perl-Hash zum Auffinden des numerischen Indexes von bestehenden Elementen. Elemente ohne Index werden erzeugt. Dazu wird ein neuer Index vergeben, der Name gespeichert und eine leere Nachfolgerliste angelegt. Diese Liste nimmt dann die Indizes der Nachfolgerelemente für die jeweiligen Vorgänger auf.
Der Algorithmus verwendet nur noch Indizes und läuft wie oben beschrieben. Erst bei der Ausgabe wird der unter dem Index gespeicherte Name wieder verwendet.
Das Perlskript sieht folgendermaßen aus:
#!/usr/bin/perl # Topologisches Sortierprogramm in [[Perl (Programmiersprache)|Perl]] # Lizenzstatus: GNU FDL, für Wikipedia # # ================================================================= # Unterprogramm zum Finden bzw. Neuanlegen eines Elements # ================================================================= sub finde_oder_erzeuge_element { my ($str)=@_; my ($idx)=$hashindex{$str}; if (!defined($idx)) { # Neues Element ... $idx=$objektzahl++; $hashindex{$str}=$idx; $name[$idx]=$str; @{$nachfolgerliste[$idx]}=(); } return $idx; } # ================================================================= # Einlesen, Aufbau der Elementliste und der Nachfolgerlisten # ================================================================= $objektzahl=0; %hashindex=(); while (<>) { chomp; /^\s*(\S+)\s*(\S+)\s*$/ || die "Bitte "Vorgänger Nachfolger" eingeben\n"; ($vorgaenger,$nachfolger)=($1,$2); $v=finde_oder_erzeuge_element($vorgaenger); $n=finde_oder_erzeuge_element($nachfolger); push @{$nachfolgerliste[$v]},$n; } # ================================================================= # Topsort 1: Berechne Vorgängerzahlen # ================================================================= for $n (0..$objektzahl-1) { $vorgaengerzahl[$n]=0; } for $v (0..$objektzahl-1) { for $n (@{$nachfolgerliste[$v]}) { ++$vorgaengerzahl[$n]; } } # ================================================================= # Erzeuge die Hilfsliste für die Elemente mit Vorgängerzahl 0 # ================================================================= @hilfsliste=(); for $n (0..$objektzahl-1) { push(@hilfsliste,$n) if ($vorgaengerzahl[$n]==0) } # ================================================================= # Topsort 2: Gib solange möglich ein Element der Hilfsliste aus # Verringere Vorgängerzahl der Nachfolger des Elements # Neue Elemente mit Vorgängerzahl 0 in die Hilfsliste # ================================================================= $ausgabe=0; while (defined($v=pop(@hilfsliste))) { print "$name[$v]\n"; ++$ausgabe; for $n (@{$nachfolgerliste[$v]}) { --$vorgaengerzahl[$n]; push(@hilfsliste,$n) if ($vorgaengerzahl[$n]==0); } } die "Zyklen gefunden\n" if $ausgabe<$objektzahl;
Beispiele
Unterprogrammaufrufe und Rekursion
In Computerprogrammen können Unterprogramme weitere Unterprogramme aufrufen. Falls keine gegenseiten Aufrufe oder Selbstaufrufe auftreten, kann eine total geordnete Reihenfolge mit Hilfe der topologischen Sortierung ermittelt werden. Andernfalls rufen sich Unterprogramme rekursiv auf.
Unterprogramme mit Rekursion Unterprogramme ohne Rekursion Prozedur a() { Aufruf von b() Aufruf von c() } Prozedur b() { Aufruf von c() } Prozedur c() { Aufruf von b() Aufruf von d() }
Prozedur a() { Aufruf von b() Aufruf von c() } Prozedur b() { Aufruf von d() } Prozedur c() { Aufruf von b() Aufruf von d() }
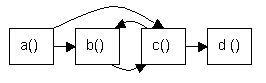
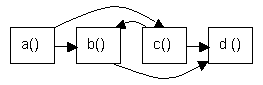
Topologisches Sortieren nicht möglich, da Prozedur b die Prozedur c aufruft und Prozedur c die Prozedur b (Zyklus). Topologische Sortierung: a c b d Hauptkategorien und Unterkategorien
Manche Kategoriensysteme sind hierarchisch angeordnet. Die oberste Ebene enthält die Hauptkategorien, die wiederum Unterkategorien enthalten. Unterkategorien können weitere Unterkategorien enthalten, bis zu einer beliebigen Tiefe. Normalerweise fügt man eine neue Kategorie in eine bestehende ein, wenn die Anzahl der Objekte in einer Kategorie eine bestimmte Grenze überschreitet. Andere, bereits bestehende Kategorien werden je nach Angemessenheit in die neue Kategorie verschoben. Dabei kann versehentlich eine übergeordnete Kategorie oder eine Kategorie aus einer anderen Hauptkategorie in die neue Kategorie eingeordnet werden, wodurch gegenseitige Abhängigkeiten entstehen und die Hierarchie des Systems zerstört wird. Ein Benutzer, der durch den (vermeintlichen) Kategoriebaum navigiert, kann sich unter Umständen ewig „im Kreis“ drehen, was durch die geforderte Hierarchie ja verhindert werden soll.
Durch topologisches Sortieren des Kategorienbaums kann man nachweisen, dass keine Zyklen vorhanden sind. Alle Hauptkategorien werden dazu zunächst in einen hypothetischen Wurzelbaum eingeordnet. Die Beziehung ist die Bedingung, dass eine Kategorie direkte Unterkategorie einer anderen Kategorie ist; diese Information ist ohnehin vorhanden. Schlägt der topologische Sortieralgorithmus fehl, sind zyklische Abhängigkeiten vorhanden, und das System ist nicht mehr hierarchisch.
tsort-Kommando unter Unix und Linux
Unix-ähnliche Betriebssysteme besitzen oft ein Programm namens tsort, das eine topologische Sortierung durchführt. Es war früher nötig, um übersetzte Objektdateien, die voneinander abhängen, in korrekter Reihenfolge in eine Programmbibliothek einzufügen, kann aber auch für andere Zwecke eingesetzt werden:
$ tsort <<Ende > Unterhemd Pullover > Unterhose Hose > Pullover Mantel > Hose Mantel > Hose Schuhe > Socken Schuhe > Ende Socken Unterhemd Unterhose Pullover Hose Schuhe Mantel
Eingabe sind die Abhängigkeiten in der Form vor nach. Ausgabe ist eine topologische Sortierung der Elemente.
Siehe auch
- Schnittregel
- Gentzenscher Hauptsatz
- Plankalkül
- Resolutionskalkül
- Anwendungsbeispiel für topologische Sortierung: Einfüge-Reihenfolge bei Tabellen mit referentieller Integrität ermitteln
Literatur
- Thomas Ottmann, Peter Widmayer: Algorithmen und Datenstrukturen. 4. Auflage. Spektrum Verlag, Heidelberg 2002, ISBN 3-8274-1029-0.
- Niklaus Wirth: Algorithmen und Datenstrukturen, Pascal Version. 4. Auflage. Teubner Verlag, Stuttgart 1995, ISBN 3519122502.
- Donald E. Knuth: The Art of Computer Programming. 3. Auflage. Bd. 1: Fundamental Algorithms, Addison Wesley, 1997, ISBN 0201896834.
- Edmund Szpilrajn: Sur l'extension de l'ordre partiel. In: Fundamenta Mathematicae. 16, Warschau 1930, S. 386–389. , ISSN 0016-2736
- Daniel J. Lasser: Topological Ordering of a List of Randomly-Numbered Elements of a Network. In: Communications of the ACM. 4, New York NY 1961, S. 167–168. , ISSN 0001-0782
- A. B. Kahn: Topological Sorting of Large Networks. In: Communications of the ACM. New York NY 5 1962, S. 558–562. , ISSN 0001-0782
Weblinks




Wikimedia Foundation.