- Verwerfungsmethode
-
Die Verwerfungsmethode (auch Acceptance-Rejection-Verfahren; engl. rejection sampling) ist eine Methode zur Erzeugung von Zufallszahlen zu einer vorgegebenen Verteilung und geht auf John von Neumann zurück.[1] Sie kann genutzt werden, wenn die Anwendung der Inversionsmethode aufgrund der Komplexität der behandelten Funktion zu schwierig wäre.
Inhaltsverzeichnis
Idee
 sei hierbei die Verteilungsfunktion der Verteilung, zu der Zufallszahlen erzeugt werden sollen.
sei hierbei die Verteilungsfunktion der Verteilung, zu der Zufallszahlen erzeugt werden sollen.  sei eine Hilfsverteilungsfunktion, zu der sich auf einfachem Weg – etwa über die Inversionsmethode – Zufallszahlen erzeugen lassen. Es seien ferner
sei eine Hilfsverteilungsfunktion, zu der sich auf einfachem Weg – etwa über die Inversionsmethode – Zufallszahlen erzeugen lassen. Es seien ferner  und
und  die zugehörigen Dichten.
die zugehörigen Dichten.Um die Verwerfungsmethode anwenden zu können, muss ferner ein konstantes
 existieren, so dass
existieren, so dass  für jedes
für jedes  erfüllt ist. Das k wird benötigt, da die Fläche unter einer Dichtefunktion immer 1 ist. Ohne den Vorfaktor k gäbe es deshalb zwangsläufig Stellen mit f(x) > g(x).
erfüllt ist. Das k wird benötigt, da die Fläche unter einer Dichtefunktion immer 1 ist. Ohne den Vorfaktor k gäbe es deshalb zwangsläufig Stellen mit f(x) > g(x).Seien nun
 Standardzufallszahlen und
Standardzufallszahlen und  Zufallszahlen, die der Verteilungsfunktion genügen.
Zufallszahlen, die der Verteilungsfunktion genügen.Dann genügt mit
 die Zufallszahl x: = vj der Verteilungsfunktion F. Man wartet gewissermaßen auf einen ersten Treffer, der unterhalb von f liegt.
die Zufallszahl x: = vj der Verteilungsfunktion F. Man wartet gewissermaßen auf einen ersten Treffer, der unterhalb von f liegt.Anders gesagt: Es werden Zufallszahlen vi nach der Verteilungsfunktion G erzeugt, und die Zahl vn wird jeweils mit der Wahrscheinlichkeit
akzeptiert (Acceptance), also dann, wenn erstmals un < p ist. Die vorhergehenden Zufallszahlen werden dagegen verworfen (Rejection).
Einfaches Beispiel
Um eine Zufallszahl aus {1,2,3,4,5} zu wählen, wobei jede Zahl mit der gleichen Wahrscheinlichkeit
 auftreten soll, kann man einen herkömmlichen Spielwürfel werfen. Erscheint eine 6, wirft man ein erneutes Mal. Meist wird aber bereits beim ersten Wurf eine Zahl zwischen 1 und 5 (einschließlich) erscheinen.
auftreten soll, kann man einen herkömmlichen Spielwürfel werfen. Erscheint eine 6, wirft man ein erneutes Mal. Meist wird aber bereits beim ersten Wurf eine Zahl zwischen 1 und 5 (einschließlich) erscheinen.Implementierung
Programmiertechnisch wird die Verwerfungsmethode allgemein wie folgender Pseudocode realisiert:
function F_verteilte_Zufallszahl() var x, u repeat x := G_verteilte_Zufallszahl() u := gleichförmig_verteilte_Zufallszahl() until u * k * g(x) < f(x) return x end
Der Erwartungswert für die Anzahl der Schleifendurchläufe ist k (siehe unten, Effizienz).
Grafische Veranschaulichung
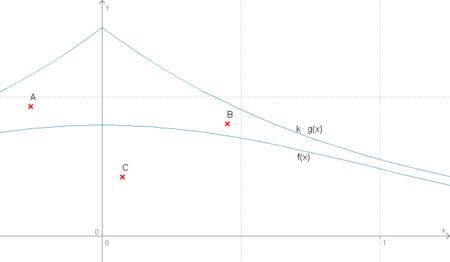 Beispiel: Der erste Treffer ist hier durch C angedeutet
Beispiel: Der erste Treffer ist hier durch C angedeutet
Man kann sich die Methode so vorstellen, dass in der x-y-Ebene zwischen der x-Achse und dem Graph von
 gleichmäßig auf der Fläche verteilte Zufallspunkte verstreut werden. Als x-Koordinate des Punkts i nimmt man die G-verteilte Zufallszahl vi, und die y-Koordinate erhält man aus der standardverteilten Zahl ui:
gleichmäßig auf der Fläche verteilte Zufallspunkte verstreut werden. Als x-Koordinate des Punkts i nimmt man die G-verteilte Zufallszahl vi, und die y-Koordinate erhält man aus der standardverteilten Zahl ui:  .
.Von diesen Zufallspunkten werden diejenigen verworfen, die oberhalb des Graphs von f(x) liegen (yi > f(vi)). Die x-Koordinaten der übrigen Punkte sind dann nach der Dichtefunktion f(x) verteilt.
Um eine Zufallszahl nach dieser Verteilung zu erzeugen, werden also solange neue Zufallspunkte erzeugt, bis einer unterhalb von f(x) liegt (im Bild der Punkt C). Dessen x-Koordinate ist die gesuchte Zufallszahl.
Effizienz
Die Fläche unter der Dichtefunktion f(x) ist 1, und unter
ist die Fläche entsprechend k. Deshalb müssen im Mittel k Standardzufallszahlen und k Zufallszahlen, die G genügen, verbraucht werden, bis der erste Treffer erzielt wird. Daher ist es von Vorteil, wenn die Hilfsdichte g die Dichte f möglichst gut approximiert, damit man k klein wählen kann.Literatur
- Donald E. Knuth: The Art of Computer Programming. Volume 2: Seminumerical Algorithms. 3. Auflage. Addison-Wesley, Reading MA u. a. 1997, ISBN 0-201-89684-2, S. 120ff. (Addison-Wesley Series in Computer Science and Information Processing).
- Luc Devroye: Non-Uniform Random Variate Generation. Springer-Verlag, New York NY u. a. 1986, ISBN 0-387-96305-7, S. 41ff.
Einzelnachweise
- ↑ John von Neumann: Various techniques used in connection with random digits. Monte Carlo methods. In: Nat. Bureau Standards, 12 (1951), S. 36–38.

Wikimedia Foundation.