- Welch-Test
-
Das Behrens-Fisher-Problem ist eine Problemstellung der mathematischen Statistik, deren exakte Lösungen nachgewiesenermaßen unerwünschte Eigenschaften haben, weswegen man Approximationen bevorzugt.
Gesucht ist ein nichtrandomisierter ähnlicher Test der Nullhypothese gleicher Erwartungswerte,
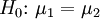 , zweier normalverteilter Grundgesamtheiten, deren Varianzen
, zweier normalverteilter Grundgesamtheiten, deren Varianzen 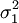 und
und 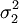 unbekannt sind und nicht als gleich vorausgesetzt werden. Die Ähnlichkeit des Tests besagt dabei, dass die Nullhypothese bei deren Gültigkeit exakt mit Wahrscheinlichkeit
unbekannt sind und nicht als gleich vorausgesetzt werden. Die Ähnlichkeit des Tests besagt dabei, dass die Nullhypothese bei deren Gültigkeit exakt mit Wahrscheinlichkeit 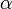 , dem vorgegebenen Signifikanzniveau, abgelehnt wird, wie groß und unterschiedlich auch immer die unbekannten Varianzen und sind. Aus Gründen der Macht des Tests bezieht man sich auf folgende „Behrens-Fisher“-Testgröße:
, dem vorgegebenen Signifikanzniveau, abgelehnt wird, wie groß und unterschiedlich auch immer die unbekannten Varianzen und sind. Aus Gründen der Macht des Tests bezieht man sich auf folgende „Behrens-Fisher“-Testgröße:wobei
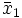 und
und 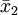 die Mittelwerte und
die Mittelwerte und 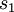 und
und 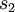 die Standardabweichungen der beiden Stichproben sind; mit
die Standardabweichungen der beiden Stichproben sind; mit 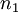 und
und 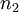 wird deren jeweiliger Umfang bezeichnet.
wird deren jeweiliger Umfang bezeichnet.Das Behrens-Fisher-Problem verallgemeinert den t-Test für zwei unabhängige Stichproben; dieser setzt nämlich voraus, dass die Varianzen beider Grundgesamtheiten übereinstimmen.
Inhaltsverzeichnis
Entstehung
Ronald Fisher führte 1935 die „fiducial inference“ zur Lösung diese Problems ein. Er bezog sich hierbei auf eine frühere Arbeit von W. V. Behrens aus dem Jahr 1929. Behrens und Fisher schlugen vor, die Verteilung der oben erwähnten Testgröße
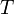 zu bestimmen.
zu bestimmen.Fisher approximierte diese Verteilung, indem er die Zufälligkeit der relativen Größe
![[(s_1^2/n_1) / (s_1^2/n_1 + s_2^2/n_2)]^{1/2}](/pictures/dewiki/48/09eafd7f2399a5fce3fba2d9540487ac.png) ignorierte. Folglich hatte der so entstandene Test nicht die gewünschte Eigenschaft, die Nullhypothese mit Wahrscheinlichkeit abzulehnen, wenn immer sie zutrifft. Das rief eine Kontroverse hervor, die gemeinhin als das Behrens-Fisher-Problem bekannt ist.
ignorierte. Folglich hatte der so entstandene Test nicht die gewünschte Eigenschaft, die Nullhypothese mit Wahrscheinlichkeit abzulehnen, wenn immer sie zutrifft. Das rief eine Kontroverse hervor, die gemeinhin als das Behrens-Fisher-Problem bekannt ist.Nichtexistenz einer wünschenswerten Lösung
Linnik (1968, Theorem 8.3.1) hat gezeigt, dass es für die Grenze zwischen Annahme und Ablehnbereich der eingangs genannten Behrens-Fisher-Testgröße
keine stetige Funktion gibt, die nur vom Quotienten der empirischen Varianzen der Mittelwerte, 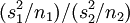 , (und natürlich Konstanten wie
, (und natürlich Konstanten wie 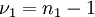 ,
, 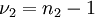 und dem Signifikanzniveau ) abhängt. Die Grenze zwischen Annahme- und Ablehnbereich jeder exakten Lösung des Behrens-Fisher-Problems ist notwendigerweise unstetig in diesem Quotienten. Mehr noch: Eine exakte Lösung fordert, dass der Ablehnbereich der Behrens-Fisher-Testgröße Umgebungen von Punkten enthält, für die
und dem Signifikanzniveau ) abhängt. Die Grenze zwischen Annahme- und Ablehnbereich jeder exakten Lösung des Behrens-Fisher-Problems ist notwendigerweise unstetig in diesem Quotienten. Mehr noch: Eine exakte Lösung fordert, dass der Ablehnbereich der Behrens-Fisher-Testgröße Umgebungen von Punkten enthält, für die 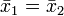 ist, eine untragbare Eigenschaft (Linnik, 1968). Dass sich Linnik anstatt auf und den genannten Varianzquotienten auf
ist, eine untragbare Eigenschaft (Linnik, 1968). Dass sich Linnik anstatt auf und den genannten Varianzquotienten auf 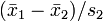 und
und 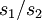 bezieht, ist nicht wesentlich, da mittels letzterer das Problem in äquivalenter Weise beschrieben wird.
bezieht, ist nicht wesentlich, da mittels letzterer das Problem in äquivalenter Weise beschrieben wird.Beste Approximation mittels eines nichtkonvergenten Reihenansatzes
Eine Arbeit, die Linnik (1968) nie erwähnt hat, ist die von B. L. Welch (1947). Schon zwei Jahrzehnte früher hat nämlich Welch (1947), der, wie Fisher, am University College London tätig war, einen Ansatz zur exakten Lösung des Behrens-Fisher-Problems gemacht, der die Grenze zwischen Annahme- und Ablehnbereich der Testgröße
als stetige Funktion in beschreiben würde. Welch (1947) gibt für gegebenes Signifikanzniveau diese Grenze zunächst für die empirische Mittelwertsdifferenz 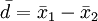 als Funktion
als Funktion 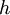 von den empirischen Varianzen
von den empirischen Varianzen 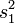 und
und 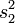 in Form einer partiellen Differentialgleichung unendlicher Ordnung exakt an. Auch beschreibt er die Methode, wie man die Lösung mittels dreier Taylor-Entwicklungen beliebig genau annähert. Die Reihenentwicklung dieser Funktion lässt erkennen, dass sie in ein Produkt aus der geschätzten Standardabweichung der Mittelwertsdifferenz,
in Form einer partiellen Differentialgleichung unendlicher Ordnung exakt an. Auch beschreibt er die Methode, wie man die Lösung mittels dreier Taylor-Entwicklungen beliebig genau annähert. Die Reihenentwicklung dieser Funktion lässt erkennen, dass sie in ein Produkt aus der geschätzten Standardabweichung der Mittelwertsdifferenz, 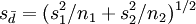 , und einer nur vom Varianzquotienten (und Konstanten) abhängigen Funktion faktorisiert werden kann. Die entsprechend der Testgröße standardisierte Funktion
, und einer nur vom Varianzquotienten (und Konstanten) abhängigen Funktion faktorisiert werden kann. Die entsprechend der Testgröße standardisierte Funktion 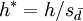 hängt also – wie gewünscht – nur vom Varianzquotienten ab. Konvergierte nun Welch's Reihenansatz gleichmäßig, sodass die Funktion unendlich oft differenzierbar, also auch stetig wäre, würde dies Linniks Beweis widersprechen, demgemäß es eine solche Funktion nicht gibt. Es folgt, dass Welchs Ansatz nicht gleichmäßig konvergieren kann. Graphische Darstellungen der Funktion
hängt also – wie gewünscht – nur vom Varianzquotienten ab. Konvergierte nun Welch's Reihenansatz gleichmäßig, sodass die Funktion unendlich oft differenzierbar, also auch stetig wäre, würde dies Linniks Beweis widersprechen, demgemäß es eine solche Funktion nicht gibt. Es folgt, dass Welchs Ansatz nicht gleichmäßig konvergieren kann. Graphische Darstellungen der Funktion 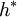 bis zu verschieden weit entwickelten Ordnungen, bei sehr kleinen wie auch etwas größeren
bis zu verschieden weit entwickelten Ordnungen, bei sehr kleinen wie auch etwas größeren 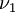 ,
, 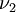 und lassen diese Schlussfolgerung durchaus glaubwürdig erscheinen, obwohl für nicht allzu kleine , und die Ergebnisse hinsichtlich der Glätte von und der Genauigkeit der numerisch errechneten Irrtumswahrscheinlichkeiten erster Art beachtlich sind. Aspins (1948) Weiterentwicklung des Reihenansatzes von Welch bis zur vierten Potenz in Kehrwerten von Freiheitsgraden liefert die mit Abstand genaueste Approximation, es sei denn , und seien viel kleiner als üblich. Der so entstandene Welch-Aspin-Test ist in Bachmaier (2000) ausführlich und in deutscher Sprache beschrieben.
und lassen diese Schlussfolgerung durchaus glaubwürdig erscheinen, obwohl für nicht allzu kleine , und die Ergebnisse hinsichtlich der Glätte von und der Genauigkeit der numerisch errechneten Irrtumswahrscheinlichkeiten erster Art beachtlich sind. Aspins (1948) Weiterentwicklung des Reihenansatzes von Welch bis zur vierten Potenz in Kehrwerten von Freiheitsgraden liefert die mit Abstand genaueste Approximation, es sei denn , und seien viel kleiner als üblich. Der so entstandene Welch-Aspin-Test ist in Bachmaier (2000) ausführlich und in deutscher Sprache beschrieben.Die Approximation im sogenannten Welch-Test
Approximative Ansätze zur Lösung des Behrens-Fisher-Problems gibt es mehrere. Eine der am meisten benutzten Approximationen (beispielsweise in Microsoft Excel) stammt ebenfalls von Welch. Man bezeichnet den auf dieser Welch-Approximation beruhenden Test auch als Welch-Test.
Die Varianz der Mittelwertsdifferenz
ist 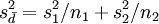 . Die Verteilung von
. Die Verteilung von 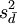 approximierte Welch (1938) durch diejenige Pearson-Kurve vom Typ III (eine skalierte Chi-Quadrat-Verteilung), deren erste beide Momente (Erwartungswert und Varianz) mit denen von übereinstimmen. Dies trifft bei folgender Anzahl
approximierte Welch (1938) durch diejenige Pearson-Kurve vom Typ III (eine skalierte Chi-Quadrat-Verteilung), deren erste beide Momente (Erwartungswert und Varianz) mit denen von übereinstimmen. Dies trifft bei folgender Anzahl 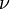 an Freiheitsgraden (degrees of freedom, d.f.) mit im Allgemeinen nichtganzzahligen Werten zu:
an Freiheitsgraden (degrees of freedom, d.f.) mit im Allgemeinen nichtganzzahligen Werten zu:Bei Gültigkeit der Nullhypothese gleicher Erwartungswerte,
, könnte die Verteilung der eingangs erwähnten Behrens-Fisher-Testgröße , die ein wenig vom Quotienten der Standardabweichungen, σ1 / σ2, abhängt, durch Students t-Verteilung mit diesen Freiheitsgraden approximiert werden. Nun enthält dieses aber auch die Varianzen 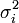 der Grundgesamtheiten, welche unbekannt sind. Es hat sich schließlich folgende Schätzung der Freiheitsgrade durchgesetzt, die einfach auf der Ersetzung der Grundgesamtheits-Varianzen durch die Stichproben-Varianzen beruht:
der Grundgesamtheiten, welche unbekannt sind. Es hat sich schließlich folgende Schätzung der Freiheitsgrade durchgesetzt, die einfach auf der Ersetzung der Grundgesamtheits-Varianzen durch die Stichproben-Varianzen beruht:Durch diese Schätzung wird aber
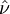 eine Zufallsvariable. Eine t-Verteilung mit einer zufälligen Anzahl von Freiheitsgraden gibt es aber nicht. Das ist jedoch kein Hinderungsgrund, die Testgröße mit entsprechenden Quantilswerten der t-Verteilung mit den geschätzten Freiheitsgraden zu vergleichen. Auf diese Weise entsteht eine unendlich oft differenzierbare von den empirischen Varianzen
eine Zufallsvariable. Eine t-Verteilung mit einer zufälligen Anzahl von Freiheitsgraden gibt es aber nicht. Das ist jedoch kein Hinderungsgrund, die Testgröße mit entsprechenden Quantilswerten der t-Verteilung mit den geschätzten Freiheitsgraden zu vergleichen. Auf diese Weise entsteht eine unendlich oft differenzierbare von den empirischen Varianzen 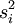 abhängige Funktion als Grenze zwischen Annahme- und Ablehnbereich der Teststgröße .
abhängige Funktion als Grenze zwischen Annahme- und Ablehnbereich der Teststgröße .Diese Methode hält das Signifikanzniveau nicht exakt, ist aber nicht allzu weit entfernt davon. Nur wenn die Grundgesamtheits-Varianzen,
und , identisch sind oder im Falle eher kleiner Stichprobenumfänge wenigstens als nahezu identisch angenommen werden können, ist der gewöhnliche t-Test von Student die bessere Wahl.Literatur
- A. A. Aspin: An Examination and Further Development of a Formula Arising in the Problem of Comparing Two Mean Values. Biometrika 35, 1948, S. 88–96.
- M. Bachmaier: Das Behrens-Fisher-Problem. In: M. Bachmaier: Klassische, robuste und nichtparametrische Bartlett-Tests und robuste Varianzanalyse bei heterogenen Skalenparametern. Shaker, Aachen 2000, S. 231–245.
- W. V. Behrens: Ein Beitrag zur Fehlerberechnung bei wenigen Beobachtungen Landwirtschaftliche Jahrbücher 68, 1929, S. 807–837.
- Juri Wladimirowitsch Linnik: Statistical problems with nuisance parameters. American Mathematical Society, Providence, Rhode Island, 1968.
- B. L. Welch: The Significance of the Difference between Two Means When the Population Variances Are Unequal. Biometrika 29, 1938, S. 350–362.
- B. L. Welch: The Generalization of Student's Problem When Several Different Population Variances Are Involved. Biometrika 34, 1947, S. 28–35.
Weblinks
- „On the Behrens-Fisher Problem: A Review“, von Seock-Ho Kim und Allan Cohen, University of Wisconsin, 1995. Dossier vorgestellt auf dem jährlichen Kongress der Psychometric Society, Minneapolis.
- „Distributional Property of the Generalized p-value for the Behrens-Fisher Problem with Applications to Multiple Testing“, von Kam-Wah Tsui and Shijie Tang, University of Wisconsin, 31. Oktober 2005
- „A simple conservative and robust solution of the Behrens-Fisher problem“, von Harold Ruben, The Indian Journal of Statistics Series A, Volume 64, Teil 1, S. 139–155, erschienen 2002
- Eine Lösung mit empirischer Wahrscheinlichkeit
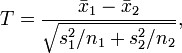
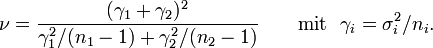
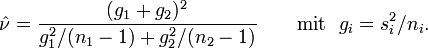
Wikimedia Foundation.