- Übersetzungsspeicher
-
Ein Übersetzungsspeicher (auch Übersetzungsarchiv; engl. translation memory, abgekürzt TM) ist eine Datenbank mit strukturierten Übersetzungen, die die Hauptkomponente von Anwendungen zur rechnerunterstützten Übersetzung (Computer-aided translation, abgekürzt CAT) darstellt.
Inhaltsverzeichnis
Funktionsweise
Der menschliche Übersetzer speichert seine Übersetzungen und die dazugehörigen Ausgangstexte manuell in der Datenbank ab und die Verwaltungssoftware des Übersetzungsspeichers schlägt ihm zu einem späteren Zeitpunkt aus diesem Archiv Formulierungen vor, wenn sie mittels statistischer Analyse einen bestimmten Grad an Übereinstimmung erkennt (ab 70% aufwärts). Der menschliche Übersetzer entscheidet, ob er diesen Vorschlag übernimmt oder eine andere Formulierung wählt. Damit unterscheidet sich ein Übersetzungsspeicher von einer eigentlichen Übersetzungssoftware, die mit intelligenten Algorithmen aus einem internen Wörterbuch neue Übersetzungsformulierungen schafft – wenn auch derzeit in einer Qualität, die sich mit Humanübersetzungen nicht messen kann.
Ein Übersetzungsspeicher erfordert eine aufwändige Vor- und Nachbereitung sowie Datenpflege und bietet daher nur dann eine Erleichterung und Effizienzsteigerung, wenn immer wieder längere und gleichlautende Gebrauchstexte übersetzt werden (zum Beispiel Verträge, Bedienungsanleitungen, Wetterberichte). Bei kurzen Gelegenheitsübersetzungen und wechselnden Formulierungen ist der Aufwand für Vor- und Nachbereitung zu hoch und die Ausbeute an verwertbaren Datenbankeintragungen zu gering. TM-Systeme, die Funktionen zum Projektmanagement enthalten, erlauben das gleichzeitige Übersetzen langer Texte durch verschiedene Übersetzer unter Wahrung der terminologischen und stilistischen Konsistenz (Einheitlichkeit).
Die TM-Software fasst die bearbeiteten Texte zu Einheiten zusammen, die Segmente genannt werden und bei den meisten Systemen einen (Ab)satz umfassen. Daraus ergibt sich die Problematik, dass identische Phrasen nicht als solche erkannt werden, wenn die Übereinstimmung des gesamten gespeicherten Segments weniger als 70% beträgt. Beim nachträglichen Einspeichern vorhandener Übersetzungen müssen die vorhandenen Ausgangs- und Zieltexte per Hand segmentweise strukturiert werden, dieser Vorgang wird „alignieren“ genannt (nach dem englischen „to align“ - anpassen, abgleichen). Es gibt dafür zwar eigene Programmteile zur Unterstützung, diese arbeiten jedoch nicht vollautomatisch. Eine neu formulierte Übersetzung kann automatisch in den Übersetzungsspeicher übernommen werden, allerdings wird dann bei immer wiederkehrenden Formulierungen die Datenbank mit einer Unzahl identischer Segmente befüllt, obwohl ein einziges als Referenztext ausreichen würde.
Datenbankstruktur
Beim Aufbau der Datenbank gibt es zwei grundsätzliche Typen:
- Zum einen gibt es Datenbanken, bei denen die gespeicherten Segmente zusammengehörige Texte sind (getrennt nach Ausgangs- und Zielsprache). Diese Systeme haben den Vorteil, dass keine isolierten Sätze gespeichert werden, sondern jeder Satz im Kontext. Außerdem kann die Datenbankabfrage auf bestimmte Themen eingeschränkt und damit Anzeige der Treffer beschleunigt werden.
- Zum anderen gibt es Datenbanken, bei denen die Segmente Sätze oder Absätze sind, die isoliert, also ohne den Kontext der Quelltexte gespeichert werden. Die Antwortzeiten hängen aber nicht so sehr von der Größe der Einheiten ab als von der effizienten Indizierung in der Datenbank.
Praktisches Arbeiten
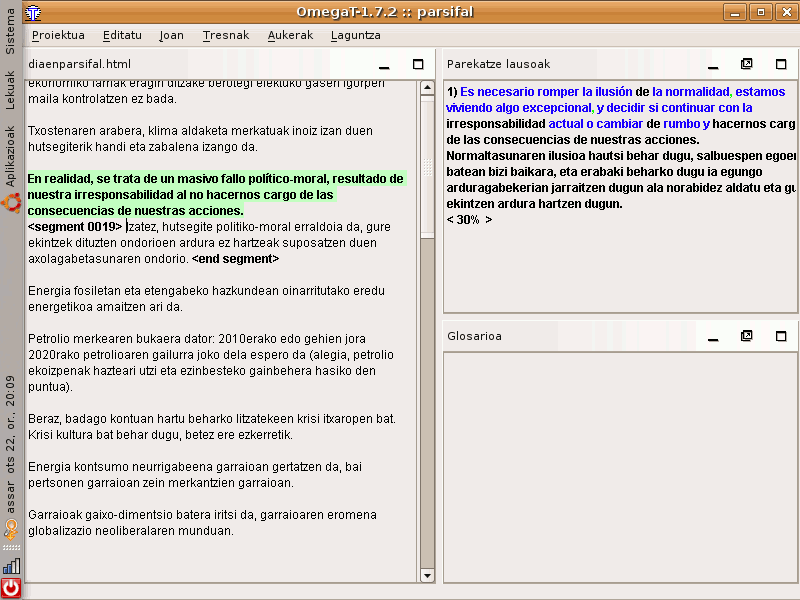
 Beispiel für einen Übersetzungsprozess mit Unterstützung eines Übersetzungsspeichers in der freien Software OmegaT.
Beispiel für einen Übersetzungsprozess mit Unterstützung eines Übersetzungsspeichers in der freien Software OmegaT.
In der Praxis beginnt die Arbeit mit einem Übersetzungsspeicher damit, dass ein Quelltext bei bestimmten Programmen wie Wordfast direkt aus der Textverarbeitung heraus aufgerufen wird oder bei eigenständigen TM-Programmen importiert wird (bestimmte Dateiformate wie PDF können meist direkt über Filter eingelesen werden, bei anderen Formaten muss der Text aber zunächst in eine Textverarbeitungsdatei kopiert werden und als solche importiert werden). Die Software stellt diesen Quelltext als linke Spalte auf der Arbeitsoberfläche dar und ordnet ihm rechts segmentweise leere Tabellenspalten zu, die der Übersetzer anwählt. Das Programm sucht dann im Speicher nach Formulierungen, die zu mindestens 70 % übereinstimmen und bietet sie als Übersetzung an. Diese Übersetzungen können vom Bearbeiter übernommen, abgelehnt oder angepasst werden. Werden keine passenden Segmente gefunden, gibt der Bearbeiter eine neue Übersetzung ein, die er dann mit dem Ausgangssegment speichern lassen kann. Wenn es das tut, wird sie ab dann beim Auftreten ähnlicher Segmente vorgeschlagen. Wenn der Übersetzer die Segmente vor der Übernahme in den Übersetzungsspeicher mit Zusatzangaben versieht, ist das zwar aufwändig, kann ihm aber später die Auswahl zwischen mehreren Vorschlägen erleichtern. Zu solchen Angaben gehören:
- Benutzer, von dem die gespeicherte Übersetzung stammt (angelegtes/geändertes Segment)
- Datum der Erstellung/Änderung des Segments
- Häufigkeit der Formulierung
- Kontext der Formulierung
- Weitere klassifizierende Angaben
- Angaben zur fach- oder nutzerspezifischen Terminologie
Neben der Auswahl mehrerer Vorschläge können die Produkte auch so eingestellt werden, dass sie eine Übersetzung (nach bestimmten Kriterien) vollautomatisch vorschlagen („Vorübersetzung“) und der Übersetzer dann wie bei einer dezidierten Übersetzungssoftware (Prompt oder Personal Translator) den vorgegebenen Text bearbeitet. Die Zeitersparnis ist allerdings relativ, denn der Benutzer muss trotzdem jedes Segment durchlesen, mit dem Ausgangstext vergleichen und so die Übersetzung auf Richtigkeit überprüfen.
Die Navigationsmöglichkeiten im Programm, das Dateimanagement und der Bedienungskomfort ist bei TM-Software, die in sich geschlossene Programme darstellen (zum Beispiel Trados Studio), mangelhaft und kommt an den Standard von Microsoft Windows nicht heran (etwa die Autokorrekturfunktion für eine automatische Tippfehlerbereinigung bzw. das Ersetzen von Abkürzungen durch Langformen, oder das Übernehmen von Formatierungen). Oft sind bewährte Bedienungsschritte komplizierter angelegt. Statt einer Schaltfläche zum Aktivieren und Deaktivieren der Fett-Darstellung gibt es zum Beispiel bei SDL Trados Studio deren zwei, eine zum Aktivieren ganz links und eine zum Deaktivieren in der Mitte der Menüleiste. Bei Programmen wie zum Beispiel Wordfast, das sich als Makro in die Textverarbeitung integrieren lässt, kann der Übersetzer hingegen mit den gewohnten Textverarbeitungsfunktionen und Tastaturkürzeln arbeiten.
Bei der Erkennung, ob es sich um einen ähnlichen Ausgangstext handelt, wertet die Software Satzzeichen, Leerzeichen, Absatzmarken und Formatierungen genauso wie Text, leicht abweichende Formatierungen führen daher dazu, dass ähnliche Texte nicht als solche erkannt werden.
Programmtechnische Eigenschaften
Üblicherweise verfügen TM-Systeme über Funktionen, die das Erkennen einer verwertbaren Übersetzung unabhängig von variablen Elementen wie Zahlen, Datumsangaben, Maßeinheiten oder Eigennamen ermöglichen.
Die Suche nach ähnlichen Quellsegmenten erfolgt mittels unterschiedlich aufwändiger Suchalgorithmen (unscharfe Suche), die dann auch einen meist prozentualen Ähnlichkeitswert angeben.
Um Texte aus Textverarbeitungs- und DTP-Programmen für die TM-Systeme verfügbar zu machen, gibt es Filter- und Extraktionsprogramme, die den Quelltext aus den jeweiligen Dateien herauslösen. Im Ergebnis erhält man dann eine markierte („getaggte“) Datei, in welcher der zu übersetzende Text zwischen speziellen Steuercodes (Tags) verfügbar ist. Diese Layout-Tags werden vom System geschützt bzw. ausgeblendet, sodass sie nicht versehentlich überschrieben oder verändert werden können. Bei der Übersetzung von Software (Lokalisierung) kann der Programmcode auf diese Weise vor unbeabsichtigter Veränderung geschützt werden. Nach der Übersetzung dienen die Steuercodes dem Filterprogramm dazu, die Texte wieder an die korrekte Stelle in der DTP-Datei einzufügen und dabei auch Formatierungen (zum Beispiel Fettdruck, Kursiv, …) auf die entsprechenden Stellen der Übersetzung anzuwenden.
Die meisten TM-Systeme verfügen über spezielle Editoren, um die Arbeit mit diesen „getaggten“ Dateien zu erleichtern.
Beim Austausch zwischen verschiedenen TM-Systemen kann man Translation Memories über das TMX-Format (Translation Memory eXchange) und Projekte über das XML Localization Interchange File Format (XLIFF) austauschen. Es sind offene Standards, die von den meisten professionellen Anbietern unterstützt werden. Da der Inhalt eines Systems jedoch stark von der Art der jeweiligen Segmentierung abhängt und die Definition des TMX-Formats breiten Interpretationsspielraum lässt, ist der Austausch in der Regel nicht verlustfrei.
Weblinks
- Forum Open Language Tools
- Advantages and Disadvantages of Translation Memory: A Cost/Benefit Analysis (englisch)
- Translation Memory Survey 2003 (im Internet Archive) (englisch)
- Translation Memory eXchange (englisch)
- Proz CAT Center (englisch)
- „Integration von automatischer Übersetzung und Translation-Memorys“ – Vortrag von Hubert Lehman
Wikimedia Foundation.