- Fehlerrechnung
-
Es ist grundsätzlich nicht möglich, fehlerfrei zu messen. Die Abweichungen der Messwerte von ihren wahren Werten wirken sich auf ein Messergebnis aus, so dass dieses ebenfalls von seinem wahren Wert abweicht. Die Fehlerrechnung versucht, die Einflussnahme der Messfehler auf das Messergebnis quantitativ zu bestimmen.
Inhaltsverzeichnis
Abgrenzung
Der Begriff Fehlerrechnung kann verschieden verstanden werden.
- Häufig will man ein Messergebnis
 aus einer Messgröße
aus einer Messgröße  oder im allgemeinen Fall aus mehreren Messgrößen
oder im allgemeinen Fall aus mehreren Messgrößen  mittels einer bekannten Gleichung berechnen. Bei fehlerhafter Bestimmung der Eingangsgröße(n) wird auch die Ausgangsgröße falsch bestimmt, denn die Einzelabweichungen werden mit der Gleichung
mittels einer bekannten Gleichung berechnen. Bei fehlerhafter Bestimmung der Eingangsgröße(n) wird auch die Ausgangsgröße falsch bestimmt, denn die Einzelabweichungen werden mit der Gleichung  bzw.
bzw.  übertragen und führen zu einer Abweichung des Ergebnisses. Man nennt dieses Fehlerfortpflanzung. Unter diesem Stichwort werden Formeln angegeben getrennt für die Fälle, dass die Abweichungen bekannt sind als
übertragen und führen zu einer Abweichung des Ergebnisses. Man nennt dieses Fehlerfortpflanzung. Unter diesem Stichwort werden Formeln angegeben getrennt für die Fälle, dass die Abweichungen bekannt sind als
-
- systematische Fehler bzw. systematische Abweichungen,
- Fehlergrenzen oder
- Unsicherheiten infolge zufälliger Fehler bzw. zufälliger Abweichungen.
- Kennzeichnend ist hier: Man hat im allgemeinen Fall mehrere Größen xi und zu jeder Größe einen Messwert.
- Wenn man die Messung einer der Größen xi unter gleichen Bedingungen wiederholt, stellt man häufig fest, dass sich die Einzelmesswerte unterscheiden; sie streuen. Sie haben dann
-
- zufällige Fehler bzw. zufällige Abweichungen.
- Nachfolgend werden Formeln angegeben zur Berechnung eines von diesen Fehlern möglichst befreiten Wertes und zu dessen verbleibender Messunsicherheit.
- Kennzeichnend ist hier: Man hat zu einer Größe xi mehrere Messwerte.
Normalverteilung
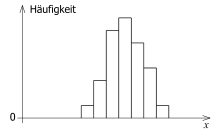 Häufigkeitsverteilung streuender Messwerte
Häufigkeitsverteilung streuender Messwerte
Die Streuung von Messwerten kann man sich in einem Diagramm veranschaulichen. Man teilt den Bereich der möglichen Werte in kleine Bereiche mit der Breite b ein und trägt zu jedem Bereich auf, wie viele gemessene Werte in diesem Bereich vorkommen, siehe Beispiel in nebenstehendem Bild.
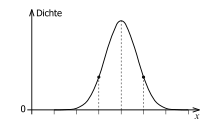 Normalverteilung streuender Messwerte
Normalverteilung streuender MesswerteBei der Gauß– oder Normalverteilung (nach Carl Friedrich Gauß) lässt man die Anzahl der Messungen N → ∞ gehen und zugleich b → 0. Bei dem Diagramm geht der gestufte Verlauf über in eine stetige Kurve. Diese beschreibt
- die Dichte der Messwerte in Abhängigkeit vom gemessenen Wert und außerdem
- für eine zukünftige Messung, welcher Wert mit welcher Wahrscheinlichkeit zu erwarten ist.
Mit der mathematischen Darstellung der Normalverteilung lassen sich viele statistisch bedingte natur-, wirtschafts- oder ingenieurwissenschaftliche Vorgänge beschreiben. Auch zufällige Messabweichungen können in ihrer Gesamtheit durch die Parameter der Normalverteilung beschrieben werden. Diese Kenngrößen sind
- der arithmetische Mittelwert über alle Messwerte, genannt Erwartungswert. Dieser ist so groß wie die Abszisse des Maximums der Kurve. Zugleich liegt er an der Stelle des wahren Wertes.
- die Standardabweichung als Maß für die Breite der Streuung der Messwerte. Sie ist so groß wie der horizontale Abstand eines Wendepunktes vom Maximum. Im Bereich zwischen den Wendepunkten liegen etwa 68 % aller Messwerte.
Unsicherheit einer einzelnen Messgröße
Das Folgende gilt bei Abwesenheit von systematischen Fehlern und bei normalverteilten zufälligen Fehlern.
Schätzwerte der Parameter
Hat man von der Größe
mehrere mit zufälligen Fehlern behaftete Werte  mit j = 1 ... N, so bekommt man gegenüber dem Einzelwert zu einer verbesserten Aussage durch Bildung des arithmetischen Mittelwertes
mit j = 1 ... N, so bekommt man gegenüber dem Einzelwert zu einer verbesserten Aussage durch Bildung des arithmetischen Mittelwertes 
Die (empirische) Standardabweichung
 ergibt sich aus
ergibt sich ausDiese Größen sind Schätzwerte für die Parameter der Normalverteilung. Durch die endliche Zahl der Messwerte unterliegt auch der Mittelwert noch zufälligen Fehlern. Ein Maß für die Breite der Streuung des Mittelwertes ist die Unsicherheit

Diese wird umso kleiner, je größer N wird. Sie kennzeichnet zusammen mit dem Mittelwert einen Wertebereich
 , in dem der wahre Wert der Messgröße erwartet wird.
, in dem der wahre Wert der Messgröße erwartet wird.Vertrauensniveau
Diese Erwartung wird nur mit einer gewissen Wahrscheinlichkeit erfüllt. Will man letztere auf ein konkretes Vertrauensniveau festlegen, so muss man einen Bereich (ein Konfidenzintervall)
 festlegen, in dem der wahre Wert mit dieser Wahrscheinlichkeit liegt. Je höher die Wahrscheinlichkeit gewählt wird, desto breiter muss der Bereich sein. Der Faktor t berücksichtigt das gewählte Vertrauensniveau und die Anzahl der Messungen insoweit, als mit einer kleinen Zahl N die statistische Behandlung noch nicht aussagekräftig ist. Wählt man die oben genannte Zahl 68 % als Vertrauensniveau und N > 12, so ist t = 1,0. Für das in der Technik vielfach verwendete Vertrauensniveau von 95 % und für N > 30 ist t = 2,0. Eine Tabelle mit Werten von t (Studentsche t-Verteilung) befindet sich in DIN 1319-3.
festlegen, in dem der wahre Wert mit dieser Wahrscheinlichkeit liegt. Je höher die Wahrscheinlichkeit gewählt wird, desto breiter muss der Bereich sein. Der Faktor t berücksichtigt das gewählte Vertrauensniveau und die Anzahl der Messungen insoweit, als mit einer kleinen Zahl N die statistische Behandlung noch nicht aussagekräftig ist. Wählt man die oben genannte Zahl 68 % als Vertrauensniveau und N > 12, so ist t = 1,0. Für das in der Technik vielfach verwendete Vertrauensniveau von 95 % und für N > 30 ist t = 2,0. Eine Tabelle mit Werten von t (Studentsche t-Verteilung) befindet sich in DIN 1319-3.Siehe auch
Weblinks
- Measurement Uncertainties in Science and Technology, Springer 2005
- Proposal for a New Error Calculus
- Estimation of Measurement Uncertainties — an Alternative to the ISO Guide
- Bestimmung der Varianz-Kovarianz-Matrix nach dem Varianzfortpflanzungsgesetz und mittels Monte-Carlo-Simulation (Online-Rechner)
- Häufig will man ein Messergebnis





Wikimedia Foundation.