- Gütefunktion
-
Die Operationscharakteristik (auch OC-Kurve oder OC-Funktion genannt) ist ein Begriff aus der statistischen Testtheorie.
Gegeben ist eine Zufallsvariable X mit einer Verteilungsfunktion F(x|θ), die von einem unbekannten Parameter θ abhängt. Für die Schätzung des Parameters werden n Beobachtungen der Zufallsvariablen gemacht. Der Parameter kann dann durch eine Schätzfunktion
geschätzt werden. Es soll eine Vermutung bezüglich des wahren, unbekannten Parameters statistisch überprüft werden. Es wird also eine Hypothese bezüglich dieses Parameters aufgestellt, die sogenannte Nullhypothese H0. Man geht nun davon aus, dass bei Wahrheit der Nullhypothese
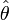 in der Nähe des wahren Parameter θ liegen müsste und lehnt H0 ab, wenn die Distanz zu groß ist, wenn also in den Ablehnungsbereich des Tests fällt. Der Ablehnungsbereich AB wird so festgelegt, dass 100%-α aller Stichproben abgelehnt werden, wenn H0 wahr ist.
in der Nähe des wahren Parameter θ liegen müsste und lehnt H0 ab, wenn die Distanz zu groß ist, wenn also in den Ablehnungsbereich des Tests fällt. Der Ablehnungsbereich AB wird so festgelegt, dass 100%-α aller Stichproben abgelehnt werden, wenn H0 wahr ist.Man kann im Hypothesentest zwei Arten von Fehlern begehen:
- Man lehnt H0 ab, obwohl θ0 der wahre Parameter ist. Es handelt sich also bei α um einen Fehler, den α-Fehler oder Fehler erster Art.
- Man lehnt H0 nicht ab, obwohl ein anderer Parameter θ1 der wahre Parameter ist. Das ist der β-Fehler oder Fehler zweiter Art.
α wird in der Testprozedur festgelegt, β hängt aber vom wahren Parameter θ1 ab und ist in aller Regel unbekannt. Man kann für eine Risikoabschätzung einer falschen Entscheidung die β-Fehler für verschiedene alternative Parameterwerte θ1 berechnen. Der β-Fehler für einen alternativen Parameter θ1 berechnet sich als Wahrscheinlichkeit, dass
in den Nichtablehnungsbereich (NAB) fällt, wenn in Wahrheit θ1 die Verteilung von regiert:β hängt also von θ1 ab und kann als Funktion von θ1 dargestellt werden: β = f(θ1). Diese Funktion wird als Operationscharakteristik (häufig auch als OC) bezeichnet. Die Gegenwahrscheinlichkeit zu β ist die Wahrscheinlichkeit, dass H0 abgelehnt wird, wenn θ1 der wahre Parameter ist. Hier ist die Ablehnung erwünscht und die entsprechende Funktion γ(θ1) = 1 – OC(θ1) wird daher als Gütefunktion bezeichnet.
Die Gütefunktion und die Operationscharakteristik stellen beide vollständige Charakterisierungen des zugehörigen Tests dar. Man erkennt an ihnen bspw., ob der Test mit wachsender Beobachtungszahl immer besser wird (Konsistenz) und ob die Wahrscheinlichkeit, H0 abzulehnen größer ist, wenn H1 zutrifft als wenn H0 zutrifft (Unverfälschtheit).
Beispiel
Ein Forellenzüchter liefert seinem Großabnehmer Forellen, die im Durchschnitt mindestens 260 g wiegen sollen. Bei Lieferung wird getestet, ob das Durchschnittsgewicht mindestens 260 Gramm beträgt. Wird die Hypothese abgelehnt, wird die Lieferung beanstandet. Es sei bekannt, dass das Gewicht X der Forellen normalverteilt ist mit der Varianz σ2 = 64 g2 und einem unbekannten Erwartungswert μ. Es werden in einer Stichprobe n = 16 Forellen gewogen, wobei die i-te Forelle xi g wiegt. Das Durchschnittsgewicht
dieser Forellen wird ermittelt. Da der Mittelwert bei jedem Versuch anders ausfällt, ist diese Größe ebenfalls eine Zufallsvariable X und normalverteilt mit den Parametern
- μ und
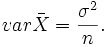
Die Hypothesen lauten nun H0:
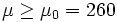 und H1: μ < 260
und H1: μ < 260Soll der Fehler erster Art beispielsweise α = 0,05 betragen, ergibt sich der kritische Wert für die Prüfgröße X als
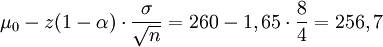
mit z(1 - α) als (1-α)-Quantil der Standardnormalverteilung.
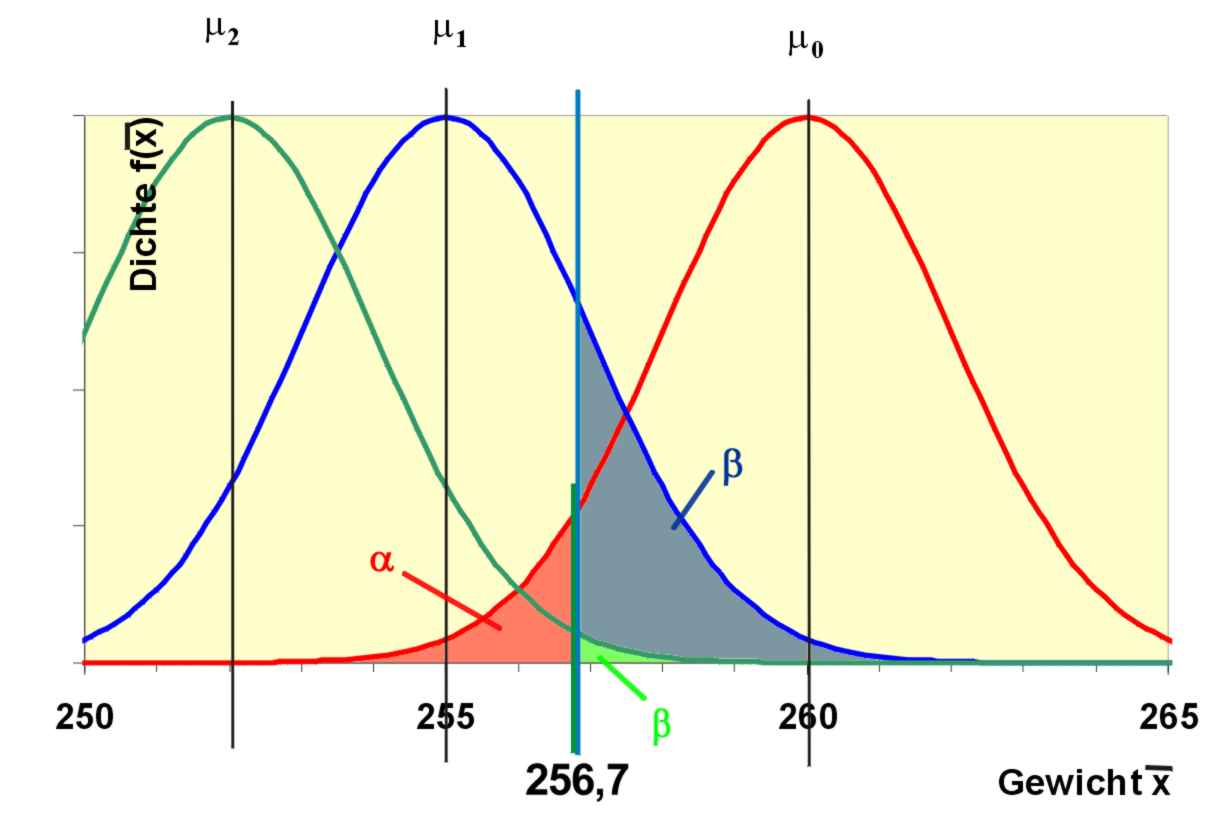
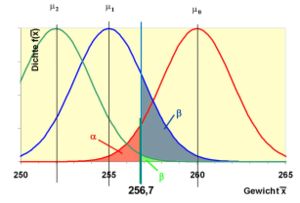 β-Fehler: Die rote Normalverteilungskurve gibt an, wie X verteilt wäre, wenn μ = 260 g ist. Die rote Fläche ist der α-Fehler 0,05. Die blaue Kurve zeigt die Verteilung von X, wenn μ in Wahrheit 255 ist. Die blaue Fläche ist dann die Wahrscheinlichkeit, dass X ≥ 256,7 ist, dass also H0 nicht abgelehnt wird. Entsprechendes gilt für μ = 252.
β-Fehler: Die rote Normalverteilungskurve gibt an, wie X verteilt wäre, wenn μ = 260 g ist. Die rote Fläche ist der α-Fehler 0,05. Die blaue Kurve zeigt die Verteilung von X, wenn μ in Wahrheit 255 ist. Die blaue Fläche ist dann die Wahrscheinlichkeit, dass X ≥ 256,7 ist, dass also H0 nicht abgelehnt wird. Entsprechendes gilt für μ = 252.H0 wird also abgelehnt, wenn x < 256,7 ist, der Ablehnungsbereich ist (- ∞; 256,7). Ist jetzt tatsächlich μ0 = 260 g wahr, würde in 5% aller Stichproben x in den Ablehnungsbereich fallen, es würde die Lieferung zu Unrecht zurückgeschickt werden.
Es kann aber beispielsweise auch vorkommen, dass das Durchschnittsgewicht in Wahrheit μ1 = 255 g beträgt, dass aber zufällig x > 256,7 g ist. Das ist der β-Fehler für μ1 = 255g. Die Prüfgröße X ist nun bei unveränderter Varianz in Wahrheit normalverteilt wie
Die Wahrscheinlichkeit, dass die Nullhypothese nicht abgelehnt wird, ist dann
und berechnet sich mit Hilfe der Normalverteilung als
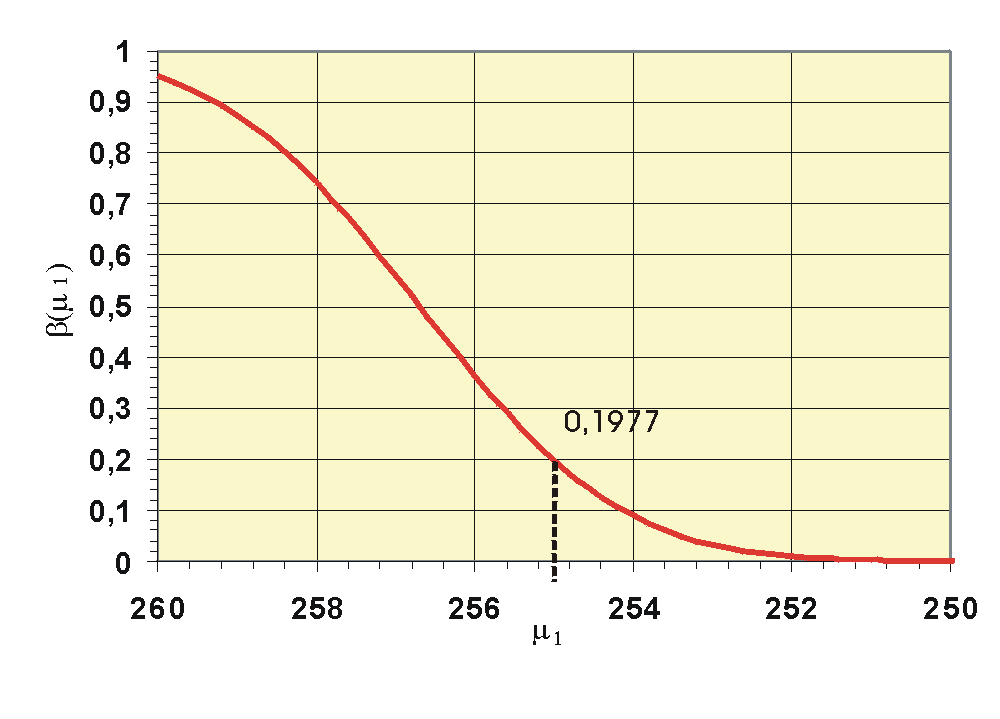
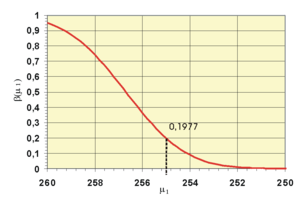 Operationscharakteristik. Der Ordinatenwert der Grafik gibt den β-Fehler in Abhängigkeit vom unbekannten Parameter μ1 an. Für μ = 260 ist der Wert 0,95, also gerade 1 - α.
Operationscharakteristik. Der Ordinatenwert der Grafik gibt den β-Fehler in Abhängigkeit vom unbekannten Parameter μ1 an. Für μ = 260 ist der Wert 0,95, also gerade 1 - α.wobei Φ(256,7|255;2) der Wert der Normalverteilungsfunktion mit den Parametern 255 und 2 an der Stelle 256,7 ist und Φz der entsprechende Wert der Standardnormalverteilung. Es würde also in ca. 20 % aller Stichproben die Lieferung akzeptiert werden, obwohl die Forellen im Durchschnitt untergewichtig sind. Beträgt dagegen in Wahrheit μ1 = 252, ergibt sich der β-Fehler als
hier ist die Gefahr einer falschen Entscheidung nur noch sehr gering. Die Grafik der Operationscharakteristik zeigt, wie mit wachsender Entfernung von μ0 der β-Fehler sinkt. Man ist bestrebt, möglichst schnell in den Bereich eines kleinen β-Fehlers zu kommen. Mit der Erhöhung des Stichprobenumfangs kann man den β-Fehler reduzieren. Einen Test mit kleinem β-Fehler nennt man auch trennscharf, weil hier die Verteilungen stark getrennt sind.
Siehe auch
Literatur
- Hartung, Joachim/Elpelt, Bärbel/Klösener, Karl-Heinz: Statistik - Lehr- und Handbuch der angewandten Statistik. 9., durchges. Aufl., Oldenbourg, München 1993, insbesondere Seite 135ff und 381ff.
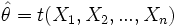
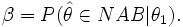
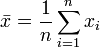
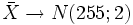
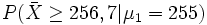
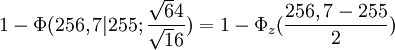
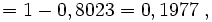
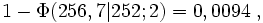
Wikimedia Foundation.