- Multiple Imputation
-
Unter dem Begriff Imputation werden in der Mathematischen Statistik Verfahren zusammengefasst, mit denen fehlende Daten in statistischen Erhebungen – die sogenannten Item non responses – in der Datenmatrix vervollständigt werden.
Inhaltsverzeichnis
Allgemeines
Die Imputation gehört zu den sogenannten Missing-Data-Techniken, also Verfahren, die bei Auswertung unvollständiger Stichprobendatensätze angewendet werden. Dieses Problem tritt in Umfragen und anderen Erhebungen relativ häufig auf, beispielsweise wenn einige befragte Personen aufgrund mangelnden Wissens oder unzureichender Antwortmotivation auf bestimmte Fragen bewusst keine Antwort geben, denkbar sind aber auch unvollständige Datensätze aufgrund technischer Pannen oder eines Datenverlustes.
Neben Imputation zählen vor allem die sogenannten Eliminierungsverfahren (auch: Complete-case analysis) zu den gängigen Missing-Data-Techniken. Dabei werden sämtliche Datensätze, bei denen eines oder mehrere Erhebungsmerkmale fehlende Werte aufweisen, aus der Datenmatrix gestrichen, so dass im Endeffekt eine vollständige Datenmatrix für Auswertungszwecke verbleibt. Dieses Verfahren ist zwar sehr einfach, hat aber erhebliche Nachteile: Insbesondere bei einer größeren Anzahl von Item non responses hat es einen erheblichen Informationsverlust zur Folge. Ferner kann diese Technik zu einer Verfälschung der verbleibenden Stichprobe führen, wenn die Systematik des Datenausfalls von den Ausprägungen des unvollständig erhobenen Merkmals abhängt. Als häufiges Beispiel gelten Umfragen bezüglich des Einkommens, bei denen es durchaus vorkommen kann, dass gerade Personen mit einem relativ hohen Einkommen dieses ungerne angeben und es daher in solchen Fällen tendenziell zu Missing Data kommt. Um dieses Problem möglichst in den Griff zu bekommen, wurden Imputationsverfahren entwickelt, bei denen versucht wird, fehlende Daten nicht einfach zu ignorieren, sondern statt dessen durch plausible Werte zu ersetzen, die unter anderem mit Hilfe der beobachteten Werte des gleichen Datensatzes geschätzt werden können.
Ausgewählte Imputationsverfahren
Es existiert eine Vielzahl von Verfahren, mit denen fehlende Werte vervollständigt werden. Dabei unterscheidet man grob zwischen der singulären und der multiplen Imputation. Bei der ersteren wird ein jeder fehlender Wert durch jeweils einen bestimmten Schätzwert ersetzt, während bei der multiplen Imputation für jedes Item non response gleich mehrere Werte geschätzt werden, in der Regel mittels einer Simulation unter Zugrundelegung eines oder mehrerer Verteilungsmodelle.
Singuläre Imputation
Substitution durch Lagemaße
Eines der einfachsten Imputationsverfahren besteht darin, sämtliche fehlenden Ausprägungen eines Erhebungsmerkmals durch das empirische Lagemaß der beobachteten Ausprägungen – meist also den Mittelwert, bzw. bei nichtquantitativen Merkmalen Median oder Modus – zu ersetzen. Dieses Verfahren hat jedoch zum Nachteil, dass dabei – ähnlich wie bei einem Eliminierungsverfahren – Verzerrungen auftreten, sofern der Datenausfall von der Ausprägung des betreffenden Merkmals abhängt. Ferner weist die resultierende Stichprobe eine systematisch unterschätzte Standardabweichung auf, da die imputierten Werte konstant sind und daher unter sich keine Streuung aufweisen. Diese Probleme können teilweise entschärft werden, wenn das Verfahren nicht einheitlich für die gesamte Stichprobe, sondern getrennt nach bestimmten Merkmalsklassen angewendet wird, in welche die Datensätze gemäß den Ausprägungen eines bestimmten, vollständig erhobenen Merkmals eingeteilt werden. Demnach kann für jede dieser Klassen separat ein Klassenmittel errechnet werden, durch den Missing Values innerhalb der Klasse ersetzt werden.
Substitution durch Verhältnisschätzer
Die Ersetzung durch einen Verhältnisschätzer ist ein relativ einfaches Verfahren, das bei der Schätzung der Imputationswerte einen eventuell bestehenden funktionalen Zusammenhang zwischen zwei Stichprobenmerkmalen auszunutzen versucht, von denen eines vollständig beobachtet werden konnte. Seien X und Y zwei Zufallsvariablen, die in einer Stichprobe vom Umfang n erhoben werden, wobei X vollständig erhoben werden konnte und bei
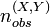 von n Untersuchungsobjekten auch der Y-Wert vorliegt. Jede der fehlenden Y-Ausprägungen kann dann durch einen Verhältnisschätzer geschätzt werden:
von n Untersuchungsobjekten auch der Y-Wert vorliegt. Jede der fehlenden Y-Ausprägungen kann dann durch einen Verhältnisschätzer geschätzt werden: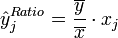 für alle
für alle 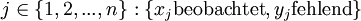
Dabei sind
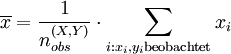
bzw.
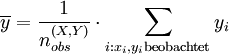
Zu beachten ist, dass dieser Schätzer nur in Spezialfällen sinnvoll anwendbar ist, in der Regel dann, wenn zwischen X und Y eine starke Korrelation angenommen werden kann.
Hot-Deck- und Cold-Deck-Techniken
Die Verfahren, die als Hot Deck bzw. Cold Deck bezeichnet werden, haben allesamt die Besonderheit, dass hierbei fehlende Stichprobenwerte durch beobachtete Ausprägungen desselben Merkmals ersetzt werden. Sie unterscheiden sich nur in Bezug auf das Verfahren, mit denen die Imputationswerte bestimmt werden. Während bei den Cold-Deck-Techniken die Schätzwerte aus anderen Erhebungen (beispielsweise aus historischen, „kalten“ Befragungen) verwendet werden, nutzen die deutlich gängigeren Hot-Deck-Verfahren die aktuelle Datenmatrix. Üblicherweise werden Deck-Techniken innerhalb von Imputationsklassen angewandt, also Merkmalsklassen, in welche die Datensätze gemäß den Ausprägungen eines vollständig erhobenen Merkmals eingeteilt werden können.
Ein bekanntes Hot-Deck-Verfahren ist das sogenannte sequentielle oder auch traditionelle Hot-Deck. Die Vorgehensweise ist hierbei die folgende: In der unvollständigen Datenmatrix wird zunächst innerhalb jeder Imputationsklasse für jede unvollständig beobachtete Variable jeweils ein Imputationswert als Startwert festgelegt. Dabei unterscheiden sich die sequentiellen Verfahren darin, wie die Startwerte bestimmt werden; denkbar ist z.B. der Mittelwert der vorhandenen Klassenausprägungen, ein Zufallswert aus der jeweiligen Klasse, oder auch ein Cold-Deck-Schätzwert. Nachdem die Startwerte festgelegt sind, geht man nun alle Elemente der Datenmatrix durch. Ist bei einem Objekt die Ausprägung vorhanden, wird sie zum neuen Imputationswert für das jeweilige Merkmal in derselben Imputationsklasse, andernfalls wird an die Stelle der fehlenden Ausprägung der für dieses Merkmal jeweils aktuelle Imputationswert gesetzt. So wird mit allen Elementen der Datenmatrix verfahren, bis diese keine Lücken mehr aufweist.
Regressionsverfahren
Den Imputationsverfahren, die auf Regressionsanalyse basieren, ist allen gemein, dass sie bei der Schätzung der Missing Values etwaige funktionale Zusammenhänge zwischen zwei oder mehreren Stichprobenmerkmalen auszunutzen versuchen. Bei den oben beschriebenen Imputationen durch den Stichprobenmittelwert oder einen Verhältnisschätzer handelt es sich ebenfalls um eine vereinfachte Form der Regressionsimputation. Im allgemeinen kommen dabei sowohl verschiedene Anzahlen der einzubeziehenden Merkmale, als auch verschiedene Regressionsverfahren in Frage. Bei quantitativen Merkmalen bedient man sich oft der linearen Regression nach der Methode der kleinsten Quadrate. Seien X und Y zwei Zufallsvariablen, die in einer Stichprobe vom Umfang n gemeinsam erhoben werden, und sei Y nur
-mal erhoben worden. Besteht zwischen den beiden Variablen annahmegemäß eine Korrelation, kann aus den beobachteten (x,y)-Wertepaaren eine Regressionsgleichung von Y auf X der folgenden Form errechnet werden: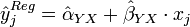 für alle
für alle Dabei sind Alpha und Beta die Regressionskoeffizienten, die aus den beobachteten (x,y)-Wertepaaren mittels ihrer Kleinstquadrateschätzer
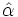 und
und 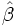 geschätzt werden:
geschätzt werden: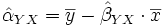
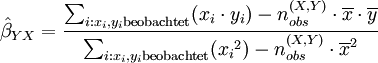
Die Regressionsschätzung mit mehr als einem Regressormerkmal – die sogenannte multiple Regression – geht analog, ist allerdings auch weitaus rechenaufwendiger. Sie ist aber standardmäßig in statistischen Softwarepaketen wie SPSS implementiert.
Ist ein unvollständig beobachtetes Merkmal nicht quantitativ, lässt sich mittels linearer Regression kein Schätzwert ausrechnen. Für bestimmte kategoriale Variablen existieren jedoch spezielle Regressionsverfahren, von denen die logistische Regression das wohl bekannteste ist.
Multiple Imputation
Bei der multiplen Imputation handelt es sich um ein vergleichsweise anspruchsvolles Missing-Data-Verfahren. Prinzipiell bedeutet „multipel“, dass dieses Verfahren für jeden fehlenden Wert gleich mehrere Schätzwerte in mehreren Imputationsschritten liefert. Diese können anschließend zu einem Schätzwert gemittelt werden, oder es kann für jeden Imputationsschritt jeweils eine neue vervollständigte Datenmatrix aufgestellt werden. Eine häufige Vorgehensweise der Schätzwertbestimmung ist die Simulation aus einem als plausibel erachteten multivariaten Verteilungsmodell. Wenn beispielsweise die beiden Zufallsvariablen X und Y als gemeinsam normalverteilt mit festgelegten Parametern unterstellt werden, können bei Wertepaaren mit beobachtetem X-Wert und fehlendem Y-Wert jeweils die bedingte Verteilung von Y, gegeben den beobachteten X-Wert, hergeleitet werden – in diesem einfachen Fall eine univariate Normalverteilung. Anschließend besteht die Möglichkeit, für jeden fehlenden Y-Wert die möglichen Imputationswerte im Zuge der mehrfachen Simulation aus der jeweiligen Verteilung zu generieren.
Siehe auch
Literatur
- U. Bankhofer: Unvollständige Daten- und Distanzmatrizen in der Multivariaten Datenanalyse. Dissertation, Universität Augsburg, Verlag Josef Eul, Bergisch Gladbach 1995
- O. Lüdtke, A. Robitzsch, U. Trautwein, O. Köller: Umgang mit fehlenden Werten in der psychologischen Forschung. Probleme und Lösungen. Psycholog. Rundschau 58 (2) 103-117 (2007). Dazu Kommentar und Replik:
- J. Wuttke: Erhöhter Dokumentationsbedarf bei Imputation fehlender Daten. Psycholog. Rundschau 59 (3) 178-179 (2008).
- O. Lüdtke et al.: Steht Transparenz einer adäquaten Datenauswertung im Wege? ebda, 180-181 (2008).
- J. L. Schafer: Analysis of Incomplete Multivariate Data. Chapman & Hall, London 1997, ISBN 0-412-04061-1
Weblinks
- http://www.multiple-imputation.com (Englisch)
Wikimedia Foundation.