- EM-Algorithmus
-
Der Expectation-Maximization-Algorithmus (kurz EM-Algorithmus, selten auch Estimation-Maximization-Algorithmus) ist ein Algorithmus der mathematischen Statistik.
Inhaltsverzeichnis
Kernidee
Die Kernidee des EM-Algorithmus ist es, mit einem zufällig gewählten Modell zu starten, und abwechselnd die Zuordnung der Daten zu den einzelnen Teilen des Modells (Expect-Schritt) und die Parameter des Modells an die neueste Zuordnung (Maximization-Schritt) zu verbessern.
In beiden Schritten wird dabei die Qualität des Ergebnisses verbessert: im E-Schritt werden die Punkte besser zugeordnet, im M-Schritt wird das Modell so verändert, dass es besser zu den Daten passt. Findet keine wesentliche Verbesserung mehr statt, beendet man das Verfahren.
Das Verfahren findet typischerweise nur „lokale“ Optima. Dadurch ist es oft notwendig, das Verfahren mehrfach aufzurufen und das beste so gefundene Ergebnis auszuwählen.
Mathematische Formulierung
Funktionsweise
Es liegen Objekte mit einer gewissen Anzahl von Eigenschaften vor. Die Eigenschaften nehmen zufällige Werte an. Einige Eigenschaften können gemessen werden, andere jedoch nicht. Formal gesehen sind die Objekte Instanzen einer mehrdimensionalen Zufallsvariablen X, die einer unbekannten Wahrscheinlichkeitsverteilung p(x) unterliegt; einige Dimensionen sind „beobachtbar“, andere sind „versteckt“. Ziel ist es, die unbekannte Wahrscheinlichkeitsverteilung zu bestimmen.
Zunächst nimmt man an, p(x) sei bis auf einige Parameter bekannt. Meist wählt man p als Mischverteilung, also als gewichtete Summe von so vielen Standardverteilungen, wie beobachtbare Eigenschaften vorliegen. Wählt man beispielsweise als Standardverteilung die Normalverteilung, so sind die unbekannten Parameter jeweils der Mittelwert μ und die Varianz σ2. Ziel ist es nun, die Parameter Θ der vermuteten Wahrscheinlichkeitsverteilung zu bestimmen. Wählt man eine Mischverteilung, so enthält Θ auch die Gewichtungsfaktoren der Summe.
Für gewöhnlich geht man ein solches Problem mit der Maximum-Likelihood-Methode an. Dies ist hier jedoch nicht möglich, da die gesuchten Parameter von den versteckten Eigenschaften abhängen – und diese sind unbekannt. Um trotzdem zum Ziel zu kommen, wird also eine Methode benötigt, die gleichzeitig mit den gesuchten Endparametern die versteckten Parameter schätzt. Diese Aufgabe erfüllt der EM-Algorithmus.
Der EM-Algorithmus arbeitet iterativ und führt in jedem Durchgang zwei Schritte aus:
- Versteckte Parameter Y schätzen. Zunächst werden die versteckten Parameter aus den im vorherigen Durchgang bestimmten Endparametern Θ und den beobachteten Daten X geschätzt. Dazu wird die sogenannte Q-Funktion verwendet, die einen vorläufigen Erwartungswert der gesuchten Verteilung berechnet.
- Endparameter Θ bestimmen. Jetzt, wo die versteckten Parameter abgeschätzt sind, wird die Maximum-Likelihood-Methode angewandt, um die eigentlich gesuchten Parameter zu bestimmen.
Der Algorithmus endet, wenn sich die bestimmten Parameter nicht mehr wesentlich ändern.
Bewiesenermaßen konvergiert die Folge der bestimmten Θ, d. h. der Algorithmus terminiert auf jeden Fall. Zudem bilden die bestimmten Parameter Θ ein lokales Optimum; das bedeutet, sie sind im Allgemeinen gut, es könnte jedoch unter Umständen (viel) bessere geben.
Formulierung als Zufallsexperiment
Rein formal wird beim EM-Algorithmus angenommen, dass die Werte der beobachteten stochastischen Größe auf folgende Art und Weise zustandekommen: Wähle zuerst eine der eingehenden Zufallsvariablen aus und übernimm deren Wert als Endergebnis. Das bedeutet, dass genau ein Gewicht den Wert eins annimmt und alle anderen null sind. Bei der Approximation der Gewichte durch den EM-Algorithmus ist dies normalerweise aber nicht mehr der Fall. Die Wahrscheinlichkeitsdichte eines Zielwertes lässt sich bei Normalverteilungsannahme und konstanter Varianz der einzelnen Zufallsvariablen darstellen als:

Dabei besitzen die verwendeten Bezeichnungen folgende Bedeutungen:
- wij: Gewicht der j-ten Zufallsvariable für den i-ten Wert der Zielgröße
- n: Anzahl der Gewichte
- yi: Wert der i-ten Zielgröße
- h: Stichprobe
- μj: Erwartungswert der j-ten Zufallsvariable
- σ2: Varianz
EM-Clustering
Das EM-Clustering ist ein Verfahren zur Clusteranalyse, das die Daten mit einem „Mixture of Gaussians“-Modell – also als Überlagerung von Normalverteilungen – repräsentiert. Dieses Modell wird zufällig oder heuristisch initialisiert und anschließend mit dem allgemeinen EM-Prinzip verfeinert.
Das EM-Clustering besteht aus mehreren Iterationen der Schritte Expectation und Maximization.
- Im Initialisierungs-Schritt muss das μ frei gewählt werden. Nehme dazu an, dass genau eine beliebige Zufallsvariable (genau eine beliebige Trainingsinstanz yk) diesem Erwartungswert μ entspricht, d.h. setze μ1,appr = yk.
- Im Expectation-Schritt werden die Erwartungswerte der Gewichte berechnet unter der Annahme, dass die Erwartungswerte der eingehenden Zufallsvariablen den in Schritt zwei berechneten entsprechen. Dies ist allerdings nur möglich, falls es sich nicht um die erste Iteration handelt.
Die Erwartungswerte lassen sich darstellen als![E[w_{ij}]=p(X_j=y_i |\mu _j = \mu _{j,\mathrm{appr}})/ \sum _{k=1}^n p(X_k=y_i|\mu_k = \mu_{k,\mathrm{appr}})](9/31991aa0142ef4eb5cb76851de06f731.png)
- Im Maximization-Schritt werden die Erwartungswerte der Wahrscheinlichkeitsverteilungen der einzelnen Zufallsvariablen bestimmt, bei denen die Wahrscheinlichkeit für das Eintreffen des Stichprobenergebnisses maximiert wird. Dies geschieht unter der Annahme, dass die exakten Werte der Gewichte jeweils ihren Erwartungswerten entsprechen. (Maximum-Likelihood-Algorithmus). Die auf diese Weise geschätzten Erwartungswerte ergeben sich bei Normalverteilungsannahme durch
![\mu_{j,\mathrm{appr}}=\frac{1}{n} \sum_{i=1}^n E[w_{ij}] y_i](d/b0df037725eea3d478564d78c57dba05.png)
- Durch wiederholung der Expectation und Maximization-Schritte werden die Parameter ihren tatsächlichen Werten weiter angenähert.
Vorteile des EM-Clusterings
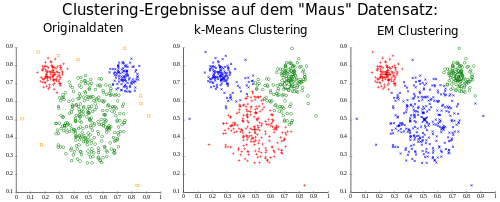 Vergleich k-Means und EM auf einem künstlichen Datensatz, visualisiert mit ELKI. Durch Verwendung von Varianzen kann EM die unterschiedlichen Normalverteilungen akkurat beschreiben, während k-Means die Daten in ungünstige Voronoi-Zellen ungünstig aufteilt. Die Clusterzentren sind durch größere, blassere Symbole gekennzeichnet.
Vergleich k-Means und EM auf einem künstlichen Datensatz, visualisiert mit ELKI. Durch Verwendung von Varianzen kann EM die unterschiedlichen Normalverteilungen akkurat beschreiben, während k-Means die Daten in ungünstige Voronoi-Zellen ungünstig aufteilt. Die Clusterzentren sind durch größere, blassere Symbole gekennzeichnet.
- Mathematisches Modell der Daten mit Normalverteilungen
- Erlaubt Cluster unterschiedlicher Größe (im Gegensatz zu k-Means)
- Kann korrellierte Cluster erkennen und repräsentieren durch die Kovarianzmatrix
- Kann mit unvollständigen Beobachtungen umgehen
K-Means als EM-Verfahren
Auch der k-Means-Algorithmus kann als EM-Algorithmus verstanden werden, der die Daten als Voronoi-Zellen modelliert.
Eine EM-Variante des k-Means-Algorithmus sieht wie folgt aus:
- Im Initialisierungs-Schritt werden die Clusterzentren μi zufällig oder mit einer Heuristik gewählt.
- Im Expectation-Schritt werden Datenobjekte ihrem nächsten Clusterzentrum zugeordnet, d.h.
![E[w_{ij}]=\begin{cases}
1, & \text{wenn }||\mu_i - X_j|| = \min_i{||\mu_i - X_j||}\\
0, & \text{andernfalls}
\end{cases}](1/7a12ef262d67dde6d0f579d59a9030d8.png)
- Im Maximization-Schritt werden die Clusterzentren neu berechnet als Mittelwert der ihnen zugeordneten Datenpunkte:
![\mu_j=\frac{1}{\sum_i^n E[w_{ij}]} \sum_{i=1}^n E[w_{ij}] y_i](4/13481e8e3bbfcbf9f11a9db5d79e3d09.png)
Weitere Instanzen des EM-Algorithmus
- Schätzen der Parameter einer Mischverteilung
- Baum-Welch-Algorithmus zum Schätzen der Parameter eines Hidden-Markov-Modells
- Lernen eines Bayes’schen Netzes mit versteckten Variablen
Beweis für den Maximization-Schritt bei Normalverteilungsannahme
Bewiesen werden soll:
![\mathrm{maxarg}_{\mu_k}\prod_{i=1}^m P\left( y|h \right)
=^? \frac{1}{m} \sum_{i=1}^{m} \frac{1}{2\sigma ^2} E[w_{ik}] y_i](8/67879e3cd2919c27e03820967fee8429.png)
Anstatt P(y | h) zu maximieren, kann auch ln P(y | h) maximiert werden, da der Logarithmus eine streng monoton steigende Funktion ist.

![= \mathrm{maxarg}_{\mu} \left( \sum_{i=1}^m
\left( \ln \frac{1}{\sqrt{2\pi^2}}
- \sum_{j=1}^n \frac{1}{2\sigma ^2} E[w_{ij}] (y_i-\mu_j)^2 \right) \right)](b/95b72c149beadcdafda693b0f3cd2474.png)
![= \mathrm{maxarg}_{\mu} \left( m \ln \frac{1}{\sqrt{2\pi^2}}
- \frac{1}{2\sigma^2} \sum_{i=1}^m \sum_{j=1}^n E[w_{ij}] (y_i-\mu_j)^2 \right)](b/46beb7aabea1a16b9cb4861b50a19c5a.png)
Der Minuend ist eine Konstante, deswegen ist es ausreichend, den Subtrahend zu minimieren:
![\mathrm{minarg}_{\mu} \left( \frac{1}{2\sigma^2} \sum_{i=1}^m \sum_{j=1}^n E \left[w_{ij} \right] \left(y_i-\mu_j \right)^2 \right)=](a/5fa5e130d90fbeb2c70db33c79bb59c9.png)
![\mathrm{minarg}_{\mu} \left(\sum_{i=1}^m \sum_{j=1}^n E[w_{ij}] (y_i-\mu_j)^2 \right)](0/180e04ee5dd0e6e179832e7a73720977.png)
Eine quadratische Summe ergibt stets einen nichtnegativen Wert. Daher ist das absolute Minimum durch 0 beschränkt und somit auch ein lokales Minimum. Man setze die 1. Ableitung für diesen Term t nach jedem μk auf 0:
![\frac{\mathrm{d}t}{\mathrm{d}\mu_k} = -2\sum_{i=1}^m E \left[w_{ik} \right] \left(y_i-\mu_k \right) = 0](8/3f87ccc037c0592c7008cefc442eab4c.png) ,
,denn die Ableitung aller Summanden der Summe über j sind 0, außer für j=k. Folglich:
![\sum_{i=1}^m E[w_{ik}] y_i= m\mu_k \quad \Rightarrow \quad
\mu_k=\frac{1}{m} \sum_{i=1}^m E\left[w_{ik} \right] y_i](6/9068df121804723b80a91ff6e91e4b25.png)
q.e.d.
Literatur
- Dempster, A.P., Laird. N.M., Rubin, D.B.: Maximum-Likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society, 1977
- Mitchell, Tom M.: Machine Learning. The Mc-Graw-Hill Companies, Inc., 1997
- Duda et al.: Pattern Classification. John Wiley & Sons, Inc.
- Stuart Russell, Peter Norvig: Artificial Intelligence: A Modern Approach, 2. Auflage, 2002, Prentice Hall.
- Stuart Russell, Peter Norvig: Künstliche Intelligenz: Ein moderner Ansatz, August 2004, Pearson Studium, ISBN 3-8273-7089-2 (deutsche Übersetzung der 2. Auflage)

Wikimedia Foundation.