- Key-to-Address Transform Techniques
-
In der Informatik bezeichnet man eine spezielle Indexstruktur als Hashtabelle (englisch hash table oder hash map) bzw. Streuwerttabelle. Hashtabellen eignen sich vor allem dazu, Datenelemente in einer großen Datenmenge aufzufinden. Hashtabellen stehen dabei in Konkurrenz zu Baumstrukturen (wie etwa ein B*-Baum) und der Skip-List, die ebenfalls als Indexstruktur dienen können. Beim Einsatz einer Hashtabelle zur Suche in Datenmengen spricht man auch von einem Hashverfahren oder Streuspeicherverfahren.
Inhaltsverzeichnis
Hashverfahren
Das Hashverfahren ist ein Algorithmus zum Suchen von Datenobjekten in großen Datenmengen. Es basiert auf der Idee, dass eine mathematische Funktion die Position eines Objektes in einer Tabelle berechnet. Dadurch erübrigt sich die Durchsuchung vieler Datenobjekte, bis das Zielobjekt gefunden wurde.
Der Algorithmus
Beim Hashverfahren werden die Zieldaten in einer Hashtabelle gespeichert. Eine Hashfunktion berechnet zu jedem Datenobjekt einen Hashwert, der als Index in der Tabelle verwendet wird. Zum Berechnen dieses Hashwertes wird ein Schlüssel benötigt, der dieses Objekt eindeutig identifiziert. Dieser Schlüssel wird von der Hashfunktion zum Berechnen des Hashwertes verwendet. Das Datenobjekt wird an einer durch den Hashwert festgelegten Stelle (Bucket genannt) in der Tabelle gespeichert. Im Idealfall bekommt jedes Objekt einen eigenen Bucket. Hashfunktionen müssen jedoch nicht eindeutig sein, so dass sich in der Praxis mehrere Objekte einen Bucket teilen müssen. Diesen Fall nennt man Kollision, er benötigt eine spezielle Behandlung durch das Verfahren.
Bei einer Suche in der Hashtabelle wird nun ähnlich vorgegangen. Zunächst wird aus einem Suchschlüssel wieder ein Hashwert berechnet, der den Bucket des gesuchten Datenobjektes bestimmt. Befinden sich im Bucket mehrere Objekte, muss jetzt nur noch durch direkten Vergleich des Suchschlüssels mit den Objekten das gesuchte Ziel bestimmt werden.
In der Praxis wird die Tabelle als ein Array implementiert. Wegen der möglichen Kollisionen werden die Daten aber nicht direkt im Array gespeichert, sondern lediglich die Verweise auf den zugehörigen Bucket. Buckets können nun selbst wiederum so organisiert sein, um eine schnelle Suche der im Bucket enthaltenen Objekte zu ermöglichen.
Ist die Hashtabelle ausgewogen, befinden sich nur wenige Datensätze in einem Bucket und der letzte Schritt hat einen geringen Aufwand. Im Worst-Case können Kollisionen zu einer Entartung der Hashtabelle führen, wenn wenige Buckets sehr viele Objekte enthalten, während andere Buckets leer bleiben.
Hashtabellen ermöglichen so eine sehr schnelle Suche in großen Datenmengen, da mit der Berechnung des Hashwertes in einem einzigen Schritt die Anzahl der möglichen Zielobjekte eingeschränkt wird. Damit gehören Hashtabellen zu den effizientesten Indexstrukturen. Ein großer Nachteil ist jedoch die Gefahr der Entartung durch Kollisionen, die bei einem stetigen Wachstum der Datenmenge unausweichlich sind. Siehe dazu Kollision. Daher werden in Datenbanksystemen häufig Hashtabellen zu Gunsten von B*-Bäumen vermieden.
Hash-Tabellen unterstützen nicht die Bewegung zum nächsten oder zum vorherigen Datensatz, entlang eines Sortierschlüssels. Sie unterstützen auch keine Abfragekriterien mit Ungleichheitsverknüpfungen ("größer als", "kleiner als"), denn sie ordnen nicht die Datenmenge.
Kollisionen
Da Hash-Funktionen im Allgemeinen nicht injektiv sind, können zwei unterschiedliche Schlüssel zum selben Hash-Wert, also zum selben Feld in der Tabelle führen. Dieses Ereignis wird als Kollision bezeichnet. In diesem Fall muss die Hashtabelle mehrere Werte an derselben Stelle aufnehmen. Um dieses Problem zu handhaben, gibt es diverse Kollisionsauflösungsstrategien.
Eine Möglichkeit wird offenes Hashing genannt. Wenn dabei ein Eintrag an eine schon belegte Stelle in der Tabelle abgelegt werden soll, wird stattdessen eine andere freie Stelle genommen. Es wird häufig zwischen drei Varianten unterschieden:
- lineares Sondieren – es wird um ein konstantes Intervall verschoben nach einer freien Stelle gesucht. Meistens wird die Intervallgröße auf 1 festgelegt.
- quadratisches Sondieren – Nach jedem erfolglosem Suchschritt wird das Intervall quadriert.
- doppeltes Hashen – eine weitere Hash-Funktion liefert das Intervall.
Eine weitere Möglichkeit ist Kollisionsauflösung durch Verkettung. Anstelle der gesuchten Daten enthält die Hashtabelle hier Behälter (Buckets), die alle Daten mit gleichem Hash-Wert aufnehmen. Bei einer Suche wird also zunächst der richtige Zielbehälter gesucht. Damit wird die Menge der möglichen Ziele erheblich eingeschränkt. Dennoch müssen abschließend die verbliebenen Elemente im Behälter durchsucht werden. Im schlimmsten Fall (Worst Case) kann es passieren, dass alle Elemente gleiche Hash-Werte haben und damit im gleichen Bucket abgelegt werden. In der Praxis kann das aber durch die Wahl einer geeigneten Größe für die Hashtabelle sowie einer geeigneten Hash-Funktion vermieden werden. Oft wird die Verkettung durch eine lineare Liste pro Behälter realisiert.
Vorteile
Trotz der Schwierigkeiten, die sich beispielsweise aus der Kollisionsbehandlung ergeben, bieten Hashtabellen wegen der Vorzüge beim sofortigen Zugriff durch den Hash-Wert auf die Inhalte in einer Tabelle im Vergleich zu der Suche nach dem Schlüssel und wegen der im Idealfall fehlenden Beziehung zweier Hash-Werte, die aus ähnlichen Schlüsseln berechnet wurden, oft Vorteile sowohl in der Zugriffszeit als auch im benötigten Speicherplatz gegenüber gewöhnlichen Arrays.
Nachteile
Hat die Tabelle einen gewissen Füllgrad überschritten, wird sie zwangsläufig entarten. Dann kann nur eine Vergrößerung der Tabelle mit nachfolgender Restrukturierung wieder zu akzeptablem Laufzeitverhalten führen.
Um den Nachteil der Nicht-Injektivität zu konterkarieren, bietet es sich an, die Funktion für den Schlüsselgenerator ein weiteres Mal aufzurufen. Schlüsselgeneratorfunktionen sind höchst performant.
Komplexität
Wurden Hash-Funktion und Größe der Hashtabelle geeignet gewählt, ist der Aufwand für die Suche in der Tabelle (Look-Up) O(1). Wegen der möglichen Kollisionen hat eine Hashtabelle allerdings im so genannten Worst-Case ein sehr viel schlechteres Verhalten. Dieser wird mit O(n) abgeschätzt, wobei das n der Anzahl der in der Hashtabelle gespeicherten Einträge entspricht. Es werden dabei also alle Einträge in der Tabelle durchsucht.
Varianten des Hashverfahrens
Es gibt mehrere Varianten des Hashverfahrens, die sich für bestimmte Daten besser eignen. Ein wichtiger Faktor hierbei ist die Dynamik, mit der sich die Anzahl der Elemente ändert. Das offene Hashing löst dieses Problem, nimmt aber Einbußen bei den Zugriffszeiten in Kauf. Das geschlossene Hashing ist hingegen auf explizite Strategien zur Kollisionsbehandlung angewiesen. Vorsicht: Die Bezeichnungen „offenes“ bzw. „geschlossenes Hashing“ werden auch in genau umgekehrter Bedeutung verwendet.
Hashing mit Verkettung
Beim Hashing mit Verkettung (engl. Separate Chaining) ist die Hash-Tabelle so strukturiert, dass jeder Behälter eine dynamische Datenstruktur aufnehmen kann – beispielsweise eine Liste oder einen Baum. Jeder Schlüssel wird dann in dieser Datenstruktur eingetragen oder gesucht. So ist es problemlos möglich, mehrere Schlüssel in einem Behälter abzulegen, was allerdings zu mehr oder weniger verlängerten Zugriffszeiten führt. Die Effizienz des Zugriffs wird dabei davon bestimmt, wie schnell Datensätze in die gewählte Datenstruktur eingefügt und darin wiedergefunden werden können. Hashing mit Verkettung ist bei Datenbanken eine sehr gängige Indizierungsvariante, wobei sehr große Datenmengen mittels Hashtabellen indiziert werden. Die Größe der Buckets ist in Datenbanksystemen ein Vielfaches der Sektorengröße des Speichermediums. Der Grund dafür ist, dass die Datenmenge nicht mehr im Hauptspeicher gehalten werden kann. Bei einer Suchanfrage muss das Datenbanksystem die Buckets sektorenweise einlesen.
Hashing mit offener Adressierung
Dieses Verfahren wird abgekürzt auch offenes Hashing, bezogen auf die offene Adressierung, aber auch geschlossenes Hashing, bezogen auf die begrenzte Anzahl möglicher Schlüssel im Behälter, genannt.
Beim Hashing mit offener Adressierung kann jedem Behälter nur eine feste Anzahl von Schlüsseln zugewiesen werden. Häufig wählt man einfach einen einzigen möglichen Schlüssel pro Behälter. Im Kollisionsfall muss dann nach einem alternativen Behälter gesucht werden. Dabei geht man so vor, dass man für m Behälter eine ganze Folge von m Hash-Funktionen definiert. Führt die Anwendung der ersten Hash-Funktion, nennen wir sie h0, zu einer Kollision, so wendet man h1 an. Führt diese ebenfalls zu einer Kollision (d. h. der entsprechende Behälter ist bereits belegt), so wendet man h2 an, und so weiter bis hm − 1. Die Bezeichnung „offene Adressierung“ ergibt sich aus der Eigenschaft, dass durch Kollisionen gleiche Schlüssel unterschiedliche Adressen zugewiesen bekommen können.
Cuckoo Hashing
Cuckoo Hashing ist ein weiteres Verfahren, Kollisionen in einer Tabelle zu vermeiden. Das Prinzip ist, zwei Hash-Funktionen einzusetzen. Das ergibt zwei mögliche Speicherorte in einer Hashtabelle. Ein neuer Schlüssel wird in eines der zwei möglichen Orte gespeichert. Sollten beide Plätze besetzt sein, wird der bereits vorhandene Schlüssel auf der Zielposition auf seine alternative Position versetzt und an seiner Stelle der neue Schlüssel gespeichert. Sollte die alternative Position besetzt sein, so wird wiederum der Schlüssel auf dieser Position auf seine alternative Position transferiert, und so fort. Wenn diese Prozedur zu einer unendlichen Schleife führt, wird die Hashtabelle mit zwei neuen Hash-Funktionen neu aufgebaut. Die Wahrscheinlichkeit für ein solches Rehashing liegt in der Größenordnung von O(1/n) für jedes Einfügen.
Anm.: Der Name leitet sich vom Verhalten des Kuckucks ab, Eier aus einem Nest zu entfernen, um ein eigenes Ei hineinzulegen.Algorithmen
Lineares Sondieren
Die einfachste Möglichkeit zur Definition einer solchen Folge besteht darin, so lange den jeweils nächsten Behälter zu prüfen, bis man auf einen freien Behälter trifft. Die Definition der Folge von Hash-Funktionen sieht dann so aus:
hi(x) = (h(x) + i)mod m
Die Anwendung des Modulo hat mit der begrenzten Zahl von Behältern zu tun: Wurde der letzte Behälter geprüft, so beginnt man wieder beim ersten Behälter. Das Problem dieser Methode ist, dass sich so schnell Ketten oder Cluster bilden und die Zugriffszeiten im Bereich solcher Ketten schnell ansteigen. Das lineare Sondieren ist daher wenig effizient.
Implementierung einer Hashtabelle in Java 5
/** Implementierung einer Hashtabelle mit linearer Sondierung Autor: Andreas Solymosi, 2007 Quelle: Solymosi/Grude: Grundkurs Algorithmen und Datenstrukturen, Vieweg Verlag, ISBN 3-528-05743-2 */ public class HashTabelle<Element, Schluessel extends Comparable<Schluessel>> { // Tabelleneintrag private class Eintrag<E, S extends Comparable < S > > { E element; S schluessel; boolean belegt; } private Eintrag<Element, Schluessel>[] tabelle; // die eigentliche Hashtabelle private int anzahl; // der eingetragenen Elemente, anfänglich 0 public HashTabelle(int groesse) { tabelle = new Eintrag[groesse]; for (int i = 0; i < tabelle.length; i++) { tabelle[i] = new Eintrag<Element, Schluessel>(); tabelle[i].belegt = false; } anzahl = 0; } // von vorhanden beschrieben (Nebeneffekt!); von eintragen, suchen und vorhanden gelesen private int index; public boolean vorhanden(Schluessel schluessel) { index = schluessel.hashCode() % tabelle.length; // Nebeneffekt! while (tabelle[index].belegt && schluessel != tabelle[index].schluessel) index = (index + 1) % tabelle.length; // lineare Sondierungsfunktion // Platz gefunden: // index zeigt auf den Platz, wo der letzte Schluessel steht if (schluessel == tabelle[index].schluessel) return true; else // ! inhalt[index].belegt, index zeigt auf einen freien Platz return false; } // ein Element mit vorhandenem Schlüssel wird überschrieben (kein Doppeleintrag) public void eintragen(Schluessel schluessel, Element element) throws VollException { if (anzahl == tabelle.length) throw new VollException(); // Nebeneffekt: vorhanden() hat index auf einen freien Platz positioniert else if (! vorhanden(schluessel)) { // neu eintragen, da ! vorhanden(): tabelle[index].schluessel = schluessel; tabelle[index].belegt = true; anzahl++; } tabelle[index].element = element; // wenn vorhanden(), dann wird überschrieben } public Element suchen(Schluessel schluessel) throws NichtVorhandenException { if (! vorhanden(schluessel)) // Nebeneffekt: vorhanden() hat index positioniert throw new NichtVorhandenException(); else // vorhanden hat index auf den Platz von schluessel positioniert return tabelle[index].element; } } public class VollException extends Exception { } public class NichtVorhandenException extends Exception { }
Quadratisches Sondieren
Wie beim linearen Sondieren wird nach einem neuen freien Speicher gesucht, allerdings nicht sequenziell, sondern mit stetig quadratisch wachsender Schrittweite und in beide Richtungen. Verursacht h(k) eine Kollision, so werden nacheinander h(k) + 1,h(k) − 1,h(k) + 4,h(k) − 4,h(k) + 9 usw. probiert. In Formeln ausgedrückt:
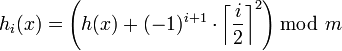
Den ständigen Wechsel des Vorzeichens bei dieser Kollisionsstrategie nennt man auch „alternierendes quadratisches Sondieren“ oder „quadratisches Sondieren mit Verfeinerung“. Wählt man die Anzahl der Behälter geschickt (nämlich
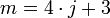 , m ist Primzahl), so erzeugt jede Sondierungsfolge h0(x) bis hm − 1(x) eine Permutation der Zahlen 0 bis m − 1; so wird also sichergestellt, dass jeder Behälter getroffen wird.
, m ist Primzahl), so erzeugt jede Sondierungsfolge h0(x) bis hm − 1(x) eine Permutation der Zahlen 0 bis m − 1; so wird also sichergestellt, dass jeder Behälter getroffen wird.Quadratisches Sondieren ergibt keine Verbesserung bei Primärkollisionen h0(x) = h0(y), kann aber die Wahrscheinlichkeit der Bildung von längeren Ketten bei Sekundärkollisionen h0(x) = hk(y) herabsetzen, d. h. Clusterbildung wird vermieden.
Doppel-Hashing
Beim Doppel-Hashing werden zwei unabhängige Hash-Funktionen h und h' angewandt. Diese heißen unabhängig, wenn die Wahrscheinlichkeit für eine sogenannte Doppelkollision, d. h.
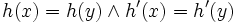 gleich 1 / m2 und damit minimal ist. Die Folge von Hash-Funktionen, die nun mittels h und h' gebildet werden, sieht so aus:
gleich 1 / m2 und damit minimal ist. Die Folge von Hash-Funktionen, die nun mittels h und h' gebildet werden, sieht so aus: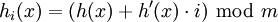
Die Kosten für diese Methode sind nahe den Kosten für ein ideales Hashing.
Dynamisches Hashing
Bei steigendem Füllgrad der Tabelle steigt die Wahrscheinlichkeit von Kollisionen deutlich an. Spätestens wenn die Anzahl der indizierten Datensätze größer ist, als die Kapazität der Tabelle, werden Kollisionen unvermeidbar. Das bedeutet, dass das Verfahren einen zunehmenden Aufwand zur Kollisionslösung aufwenden muss. Um dies zu vermeiden, wird beim Dynamischen Hashing die Hashtabelle bei Bedarf vergrößert. Dies hat jedoch zwangsläufig Auswirkungen auf den Wertebereich der Hash-Funktion, der nun ebenfalls erweitert werden muss. Eine Änderung der Hash-Funktion wiederum hat jedoch den nachteiligen Effekt, dass sich ebenfalls die Hash-Werte für bereits gespeicherte Daten ändern. Für das dynamische Hashing wurde dafür eigens eine Klasse von Hash-Funktionen entwickelt, deren Wertebereich vergrößert werden kann, ohne die bereits gespeicherten Hash-Werte zu verändern.
Vorteile
- Es gibt keine obere Grenze für das Datenvolumen
- Einträge können ohne Probleme gelöscht werden
- Adresskollisionen führen nicht zur Clusterbildung.
Nachteile
- effektives Durchlaufen der Einträge nach einer Ordnung
- effektive Suche nach dem Eintrag mit dem kleinsten oder größten Schlüssel
Anwendung
Ein Anwendungsfall ist das Assoziative Array (auch Map, Lookup Table, Dictionary oder Wörterbuch). Das Nachschlagen der mit einem Schlüssel assoziierten Daten kann mittels einer Hashtabelle schnell und elegant implementiert werden.
Wichtig sind Hashtabellen auch für Datenbanken. Hier werden sie als Index für Tabellen verwendet. Ein sogenannter Hashindex kann unter günstigen Bedingungen zu idealen Zugriffszeiten führen.
Des Weiteren finden Hashtabellen Einsatz in praktisch jeder modernen Applikation. Hier werden sie zur Implementierung von Mengen (Sets) oder eines Caches verwendet. Symboltabellen, die bei Compilern oder Interpretern Verwendung finden, werden meistens auch als Hashtabelle realisiert.
Beispiel
Bildlich kann eine Hashtabelle als ein Telefonbuch betrachtet werden. Suchschlüssel sind die Namen, nach denen gesucht werden soll. Als Hash-Funktion wird die Abbildung des Namens auf seinen Anfangsbuchstaben verwendet. Daraus leitet sich im Idealfall genau die Seite des Namens im Telefonbuch ab. Der Idealfall ist aber nur dann gegeben, wenn es zu jedem Anfangsbuchstaben genau einen Namen geben würde. Dies ist offensichtlich falsch (siehe Schubfachprinzip) und die Folge sind Kollisionen. Als Ausweg kann man versuchen eine geeignetere Hash-Funktion zu finden.
Siehe auch
- Bloomfilter
- B*-Baum – Schnelles und sehr robustes Indexverfahren bei Datenbanken.
- R*-Baum – Effektives Indexverfahren für mehrdimensionale Daten.
- Verteilte Hashtabelle
Weblinks
- Umfangreiche Hashbibliothek mit weitreichender Analysefunktionalität
- Einfache Implementation einer Hashtabelle (mit Kollision)
- Cuckoo Hashing
Literatur
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest – Introduction to Algorithms. 1184 Seiten; The MIT Press 2001, ISBN 0-262-53196-8
- Christian Ullenboom – Java ist auch eine Insel, 1444 Seiten; Galileo Press 2007, ISBN 3-89842-838-9; online als Openbook verfügbar.
Wikimedia Foundation.