- Kkt
-
Die Konvexe Optimierung ist ein Teilgebiet der mathematischen Optimierung.
Es ist eine bestimmte Größe zu minimieren, die sogenannte Zielfunktion, welche von einem Parameter, welcher mit x bezeichnet wird, abhängt. Außerdem sind bestimmte Nebenbedingungen einzuhalten, d.h. die Werte x, die man wählen darf, sind gewissen Einschränkungen unterworfen. Diese sind meist in Form von Gleichungen und Ungleichungen gegeben. Sind für einen Wert x alle Nebenbedingungen eingehalten, so sagt man, dass x zulässig ist. Man spricht von einem konvexen Optimierungsproblem oder einem konvexen Programm, falls sowohl die Zielfunktion als auch die Menge der zulässigen Punkte konvex ist. Viele Probleme der Praxis sind konvexer Natur. Oft wird zum Beispiel auf Quadern optimiert, welche stets konvex sind, und als Zielfunktion finden oft quadratische Formen Verwendung, die unter bestimmten Voraussetzungen ebenfalls konvex sind (siehe Definitheit). Ein anderer wichtiger Spezialfall ist die Lineare Optimierung, bei der eine lineare Zielfunktion über einem konvexen Polyeder optimiert wird.
Eine wichtige Eigenschaft der konvexen Optimierung im Unterschied zur nicht-konvexen Optimierung ist, dass jedes lokale Optimum auch ein globales Optimum ist. Anschaulich bedeutet dies, dass eine Lösung, die mindestens so gut ist wie alle anderen Lösungen in einer Umgebung, auch mindestens so gut ist wie alle zulässigen Lösungen. Dies erlaubt es, einfach nach lokalen Optima zu suchen.
Inhaltsverzeichnis
Einleitung
Es gibt viele mögliche Formulierungen eines konvexen Programms. An dieser Stelle soll eine möglichst allgemeine Form gewählt werden. Der Eingabeparameter x sei aus dem
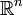 , d.h. das Problem hängt von n Einflussparametern ab. Die Zielfunktion
, d.h. das Problem hängt von n Einflussparametern ab. Die Zielfunktion 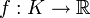 sei konvex. Weiterhin seien die konvexen Funktionen
sei konvex. Weiterhin seien die konvexen Funktionen 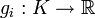 mit
mit 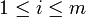 und die affinen Funktionen
und die affinen Funktionen 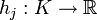 mit
mit 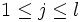 gegeben. Hierbei ist K eine konvexe Teilmenge des .
gegeben. Hierbei ist K eine konvexe Teilmenge des .Konvexes Programm:
Minimiere f(x) mit
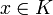 unter den Nebenbedingungen
unter den NebenbedingungenEine Restriktion mit gi(x) = 0 bezeichnet man als aktiv. Die Funktionen gi stellen die sogenannten Ungleichungsnebenbedingungen und die Funktionen hj stellen die sogenannten Gleichungsnebenbedingungen dar.
Geschichte
 Carl Friedrich Gauß
Carl Friedrich GaußDie Disziplin der konvexen Optimierung entstand unter anderem aus der konvexen Analysis. Die erste Optimierungs-Technik, welche als Verfahren des steilsten Abstiegs bekannt ist, geht auf Gauß zurück. Im Jahre 1947 wurde das Simplex-Verfahren durch George Dantzig eingeführt. Des Weiteren wurden im Jahr 1968 erstmals Innere-Punkte-Verfahren durch Fiacco und McCormick vorgestellt. In den Jahren 1976 und 1977 wurde die Ellipsoid-Methode von David Yudin und Arkadi Nemirovski und unabhängig davon von Naum Shor zur Lösung konvexer Optimierungsprobleme entwickelt. Narendra Karmarkar beschrieb im Jahr 1984 zum ersten Mal einen polynomialen potentiell praktisch einsetzbaren Algorithmus für lineare Probleme. Im Jahr 1994 entwickelten Arkadi Nemirovski und Yurii Nesterov Innere-Punkte-Verfahren für die konvexe Optimierung, welche große Klassen von konvexen Optimierungsproblemen in polynomialer Zeit lösen konnten.
Bei den Karush-Kuhn-Tucker-Bedingungen wurden die notwendigen Bedingungen für die Ungleichheits-Einschränkung zum ersten Mal in der Master-Arbeit von W. Karush veröffentlicht. Bekannter wurden diese jedoch erst nach einem Konferenz-Paper von Harold W. Kuhn und Albert W. Tucker.
Vor 1990 lag die Anwendung der konvexen Optimierung hauptsächlich im Operations Research und weniger im Bereich der Ingenieure. Seit 1990 boten sich jedoch immer mehr Anwendungsmöglichkeiten in der Ingenieurwissenschaft. Hier lässt sich unter anderem die Kontroll- und Signal-Steuerung, die Kommunikation und der Schaltungsentwurf nennen. Außerdem entstanden neue Problemklassen wie semidefinite und Kegel-Optimierung 2. Ordnung und robuste Optimierung.
Beispiel

Als Beispiel wird ein eindimensionales Problem ohne Gleichungsnebenbedingungen und mit nur einer Ungleichungsnebenbedingung betrachtet:
Minimiere f(x) = (x − 1)2 mit
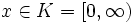 unter der Nebenbedingung:
unter der Nebenbedingung:Der zulässige Bereich ist gegeben durch die konvexe Menge
![\{x\in K:g(x)\leq 0\}=[0,1]](/pictures/dewiki/100/dc5e816cd07d3720fedfb8c473182be3.png) .
.
Der Zeichnung entnimmt man, dass für x = 1 der Optimalwert 0 angenommen wird.
Optimalitätsbedingungen
Zunächst werden notwendige Optimalitätsbedingungen vorgestellt. Dies sind Kriterien, die auf jeden Fall im Optimum
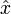 erfüllt sein müssen. Danach werden hinreichende Optimalitätsbedingungen formuliert. Diese zeigen, dass eine Lösung wirklich optimal ist.
erfüllt sein müssen. Danach werden hinreichende Optimalitätsbedingungen formuliert. Diese zeigen, dass eine Lösung wirklich optimal ist.Fritz-John-Bedingungen
Sei
optimal für das obige konvexe Programm. Dann gibt es Multiplikatoren 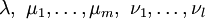 , die nicht sämtlich den Wert 0 haben, mit den folgenden Eigenschaften:
, die nicht sämtlich den Wert 0 haben, mit den folgenden Eigenschaften: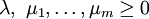
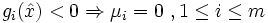 (Complementary slackness condition)
(Complementary slackness condition)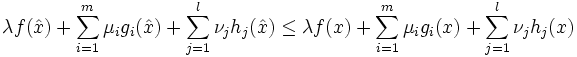 für alle
für alle
Die Fritz-John-Bedingungen sind ein notwendiges Optimalitätskriterium. Für λ > 0 sind sie hinreichend. In diesem Fall darf man sogar λ = 1 setzen. Die complementary slackness condition wird im Deutschen auch Bedingung vom komplementären Schlupf genannt. Hierbei kann man beweisen, dass falls
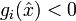 für alle gilt, dass dann alle Multiplikatoren μi = 0 für alle sein müssen. Diese Bedingung ist somit für den Aufbau und den Entwurf von Algorithmen von hoher Bedeutung.
für alle gilt, dass dann alle Multiplikatoren μi = 0 für alle sein müssen. Diese Bedingung ist somit für den Aufbau und den Entwurf von Algorithmen von hoher Bedeutung.Karush-Kuhn-Tucker-Bedingungen
Die Karush-Kuhn-Tucker-Bedingungen (auch bekannt als die KKT-Bedingungen) sind notwendig für die Optimalität einer Lösung in der nichtlinearen Optimierung. Sie sind die Verallgemeinerung der Lagrange-Multiplikatoren für die dynamische Optimierung und finden in der fortgeschrittenen neoklassischen Theorie Anwendung.
Notwendige Bedingungen
Sei
die Zielfunktion und die konvexen Funktionen mit und die affinen Funktionen mit sind Nebenbedingungs-Funktionen. Es sei ein zulässiger Punkt, d.h. es gilt 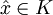 . Des Weiteren nimmt man an, dass die aktiven Funktionen gi differenzierbar im Punkt sind, die Funktionen hj sind stetig differenzierbar im Punkt . Falls ein lokales Minimum ist, dann existieren Konstanten
. Des Weiteren nimmt man an, dass die aktiven Funktionen gi differenzierbar im Punkt sind, die Funktionen hj sind stetig differenzierbar im Punkt . Falls ein lokales Minimum ist, dann existieren Konstanten 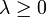 ,
, 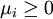 mit und νj mit
mit und νj mit 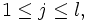 so dass
so dass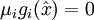 für alle
für alle 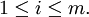
Außerdem gilt
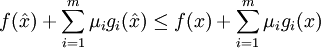 für alle
für alle
und die Komplementaritätsbedingung ist erfüllt:Regularitäts-Bedingungen
Für die obige notwendige Bedingung darf das duale Skalar λ gleich Null sein. In solchen Fällen spricht man von degeneriert oder abnormal. Dann spielt die notwendige Bedingung keine Rolle für die Eigenschaften der Funktion, nur die Geometrie der Nebenbedingungen ist relevant.
Es existieren mehrere Bedingungen, welche sicherstellen sollen, dass die Lösung nicht-degeneriert ist, d.h.
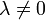 . Diese werden Constraint Qualifications genannt.
. Diese werden Constraint Qualifications genannt.Hinreichende Bedingungen
Sei
die Zielfunktion und die konvexen Funktionen mit und die affinen Funktionen mit sind Nebenbedingungs-Funktionen. Es sei ein zulässiger Punkt, d.h. es gilt . Des Weiteren nimmt man an, dass die aktiven Gradienten 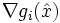 und die Gradienten
und die Gradienten 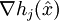 linear unabhängig sind. Falls ein lokales Minimum ist, dann existieren Konstanten , mit und νj mit so dass
linear unabhängig sind. Falls ein lokales Minimum ist, dann existieren Konstanten , mit und νj mit so dass- für alle
dann ist der Punkt
ein globales Minimum.Constraint Qualifications
Ein Kriterium, welches sicherstellt, dass λ > 0 gilt, nennt man Constraint Qualification. Mit anderen Worten, eine Bedingung, die sicherstellt, dass die Fritz-John-Bedingungen auch die Karush-Kuhn-Tucker-Bedingungen erfüllen, nennt man Constraint Qualification.
Beispiele für Constraint Qualifications sind:
- Slater: Es treten keine Gleichungsnebenbedingungen auf. Des weiteren gibt es einen Punkt
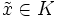 , so dass
, so dass 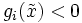 für alle . An dieser Stelle sei erwähnt, dass die Constraint Qualification von Slater im Allgemeinen als die wichtigste angesehen wird.
für alle . An dieser Stelle sei erwähnt, dass die Constraint Qualification von Slater im Allgemeinen als die wichtigste angesehen wird. - Lineare Unabhängigkeit - Linear independence constraint qualification (LICQ): Die Gradienten der aktiven Ungleichungsbedingungen und die Gradienten der Gleichungsbedingungen sind linear unabhängig im Punkt .
- Mangasarian-Fromowitz - Mangasarian-Fromowitz constraint qualification (MFCQ): Die Gradienten der aktiven Ungleichungsbedingungen und die Gradienten der Gleichungsbedingungen sind positiv-linear unabhängig im Punkt .
- Konstanter Rang - Constant rank constraint qualification (CRCQ): Für jede Untermenge der Gradienten der Ungleichungsbedingungen, welche aktiv sind, und der Gradienten der Gleichungsbedingungen ist der Rang in der Nähe von konstant.
- Konstante positive-lineare Abhängigkeit - Constant positive-linear dependence constraint qualification (CPLD): Für jede Untermenge der Gradienten, der Ungleichungsbedingungen, welche aktiv sind, und der Gradienten der Gleichungsbedingungen, und falls eine positive-lineare Abhängigkeit im Punkt vorliegt, dann gibt es eine positiv-lineare Abhängigkeit in der Nähe von .
Man kann zeigen, dass die folgenden beiden Folgerungsstränge gelten
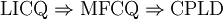 und
und 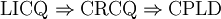 ,
,
obwohl MFCQ nicht äquivalent zu CRCQ ist. In der Praxis werden schwächere Constraint Qualifications bevorzugt, da diese stärkere Optimalitäts-Bedingungen liefern.
Konkretes Vorgehen
Lagrange-Funktion
Zunächst wird die folgende abkürzende Schreibweise eingeführt:
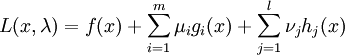 ,
,
wobei λ der Vektor aus allen Multiplikatoren ist.
Lagrangesche Multiplikatorenregel für das konvexe Problem
Vergleiche hierzu auch mit Lagrangesche Multiplikatorenregel. Konkretes Vorgehen:
- Überprüfe, ob alle auftretenden Funktionen stetig partiell differenzierbar sind. Falls nein, ist diese Regel nicht anwendbar.
- Gibt es einen zulässigen Punkt , für den gilt:
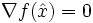 ? Falls ja, dann ist optimal. Sonst fahre mit dem nächsten Schritt fort.
? Falls ja, dann ist optimal. Sonst fahre mit dem nächsten Schritt fort. - Bestimme den Gradienten
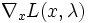 der Lagrange-Funktion.
der Lagrange-Funktion. - Löse das System
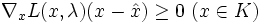 , wobei kein Multiplikator negativ sein darf. Falls eine Restriktion aktiv ist, muss der zugehörige Multiplikator sogar gleich 0 sein. Findet man eine Lösung , so ist diese optimal.
, wobei kein Multiplikator negativ sein darf. Falls eine Restriktion aktiv ist, muss der zugehörige Multiplikator sogar gleich 0 sein. Findet man eine Lösung , so ist diese optimal.
Literatur
- Avriel, Mordecai: Nonlinear Programming: Analysis and Methods. Dover Publishing, 2003, ISBN 0-486-43227-0.
- R. Andreani, J. M. Martínez, M. L. Schuverdt: On the relation between constant positive linear dependence condition and quasinormality constraint qualification. Journal of optimization theory and applications, vol. 125, no2, 2005, pp. 473-485.
- F. Jarre, J. Stoer: Optimierung. Springer, Berlin 2003, ISBN 3-540-43575-1.
Weblinks
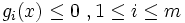
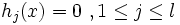
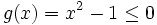
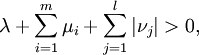
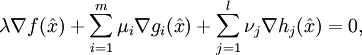
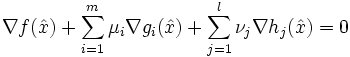
Wikimedia Foundation.