- Page Rank
-
Der PageRank-Algorithmus ist ein Verfahren, eine Menge verlinkter Dokumente, wie beispielsweise das World Wide Web, anhand ihrer Struktur zu bewerten bzw. zu gewichten. Dabei wird jedem Element ein Gewicht, der PageRank, aufgrund seiner Verlinkungsstruktur zugeordnet. Der Algorithmus wurde von Larry Page (daher der Name PageRank) und Sergey Brin an der Stanford University entwickelt und von dieser zum Patent angemeldet.[1] Er diente der Suchmaschine Google des von Brin und Page gegründeten Unternehmens Google Inc. als Grundlage für die Bewertung von Seiten.
Der PageRank-Algorithmus ist eine spezielle Methode, die Linkpopularität einer Seite bzw. eines Dokumentes festzulegen. Das Grundprinzip lautet: Je mehr Links auf eine Seite verweisen, umso höher ist das Gewicht dieser Seite. Je höher das Gewicht der verweisenden Seiten ist, desto größer ist der Effekt. Das Ziel des Verfahrens ist es, die Links dem Gewicht entsprechend zu sortieren, um so eine Ergebnisreihenfolge bei einer Suchabfrage herzustellen, d.h. Links zu wichtigeren Seiten weiter vorne in der Ergebnisliste anzuzeigen.
Der PageRank-Algorithmus bildet einen zufällig durch das Netz surfenden User nach. Die Wahrscheinlichkeit, mit der dieser auf eine Webseite stößt, korreliert mit dem PageRank.
Inhaltsverzeichnis
Der PageRank-Algorithmus
Das Prinzip des PageRank-Algorithmus ist, dass jede Seite ein Gewicht (PageRank) besitzt, das umso größer ist, je mehr Seiten (mit möglichst hohem eigenem Gewicht) auf diese Seite verweisen. Das Gewicht PRi einer Seite i berechnet sich also aus den Gewichten PRj der auf i verlinkenden Seiten j. Verlinkt j auf insgesamt Cj verschiedene Seiten, so wird das Gewicht von PRj anteilig auf diese Seiten aufgeteilt. Folgende rekursive Formel kann als Definition des PageRank-Algorithmus angesehen werden:
Dabei ist N die Gesamtanzahl der Seiten und d ein Dämpfungsfaktor zwischen 0 und 1, mit dem ein kleiner Anteil des Gewichts (1 − d) einer jeden Seite abgezogen und gleichmäßig auf alle vom Algorithmus erfassten Seiten verteilt wird. Dies ist notwendig, damit das Gewicht nicht zu Seiten „abfließt“, die auf keine andere Seite verweisen. Oft wird die obige Formel auch ohne den Normierungsfaktor 1 / N angegeben.
Die Gleichung kann sowohl als Eigenvektorproblem der Matrix
als auch (für d < 1) als Lösung des linearen Gleichungssystems
mit
interpretiert werden, wobei δij das Kronecker-Delta bezeichnet. Die Lösung des linearen Gleichungssystems
kann analytisch oder numerisch erfolgen. Für d < 1 ist die Lösung des Gleichungssystems eindeutig. Durch Verwendung der Jacobi-Iteration zur numerischen Lösung ergibt sich obige rekursive Gleichung. Andere numerische Verfahren zur Matrixinvertierung, wie das Minimale-Residuum-Verfahren oder die Gauss-Seidel-Methode, konvergieren jedoch in der Regel schneller.
Der heute von Google verwendete Algorithmus hat vermutlich nicht mehr exakt diese Form, geht aber auf diese Formel zurück. Alternative Algorithmen sind das Verfahren der Hubs und Authorities von Jon Kleinberg, der Hilltop- und der TrustRank-Algorithmus.
Zufallssurfer-Modell
Normiert man den PageRank auf 1, so kann man das Gewicht einer Seite als Wahrscheinlichkeit interpretieren, dass ein zufälliger Surfer (siehe Zufallspfad) sich auf dieser Seite befindet. Ein zufälliger Surfer bewegt sich durch das Netz, indem er mit der Wahrscheinlichkeit d zufällig einen der ausgehenden Links der aktuellen Seite wählt. Mit Wahrscheinlichkeit 1 − d wählt er eine beliebige neue Seite. Um Probleme mit Seiten ohne ausgehende Links zu vermeiden, können bei diesen Links zu allen vorhandenen Seiten hinzugefügt werden.
Toolbar- und Verzeichnis-Werte
Informationen über den PageRank lassen sich aus der Google-Toolbar und dem Google-Verzeichnis entnehmen. Der von Google in der Toolbar angezeigte PageRank liegt zwischen 0 und 10. Der im Google-Verzeichnis angegebene Wert lag bis Anfang 2008 zwischen 0 und 7, entspricht inzwischen aber dem in der Toolbar angezeigten Wert. Die angezeigten Werte bilden den realen PageRank auf einer logarithmischen Skala ab und geben das Ergebnis als gerundeten ganzzahligen Wert wieder.
Der in der Google-Toolbar angezeigte PageRank wurde früher alle dreißig Tage aktualisiert. Inzwischen ist das Intervall zwischen den Updates angestiegen, auf teilweise mehr als hundert Tage.
Manipulation
Aufgrund der wirtschaftlichen Bedeutung ist es inzwischen zu gezielten Manipulationen und Fälschungen gekommen. So wurde dieses sinnvolle System in der Praxis von Suchmaschinenoptimierern durch Spamming in Gästebüchern, Blogs und Foren, dem Betreiben von Linkfarmen und anderen unseriösen Methoden unterlaufen. Durch Weiterleitung auf bestehende Seiten mit hohem PageRank wird gezielt versucht, den PageRank-Algorithmus zu manipulieren.
Anfang 2005 implementierte Google mit rel="nofollow" ein neues Attribut für Verweise, als Versuch, gegen Spam vorzugehen. Links, die mit diesem Attribut versehen werden, werden nicht für die PageRank-Berechnung berücksichtigt. Durch Kennzeichnung ausgehender Links kann so beispielsweise dem Gästebuch-, Blog- und Forum-Spamming entgegengewirkt werden. Allerdings ist diese Methode umstritten.
Geschichte
Die Idee des PageRank-Algorithmus stammt ursprünglich aus der Soziometrie und lässt sich in der Fachliteratur erstmalig 1953 bei Katz nachweisen. Bereits 1949 verwendete Seeley das Verfahren zur Erklärung des Zustandekommens des Status eines Individuums, allerdings gibt es in seiner Beschreibung noch keine Normierung auf die Anzahl der ausgehenden Kanten und keinen Dämpfungsterm. Letzterer wurde 1965 von Charles H. Hubbell eingeführt.
Kritik
Die Nachteile von PageRank im Überblick:
- Finanziell kräftige Seitenbetreiber können sich Backlinks erkaufen und werden dadurch in Suchergebnissen höher positioniert. Dies führt dazu, dass statt qualitativ hochwertigem Inhalt oft die finanziellen Möglichkeiten über die Reihenfolge der Suchergebnisse entscheiden.
- Webmaster sehen oft im PageRank das einzige Bewertungskriterium für den Linktausch. Der Inhalt der verlinkten Seiten gerät in den Hintergrund.
- Der PageRank liefert keinen Beitrag zur qualitativen Messung von Webseiten.
Siehe auch
Einzelnachweise
- ↑ Patent US 6285999 Lawrence Page: „Method for node ranking in a linked database“ angemeldet am 10. Januar 1997
Literatur
- Langville, Amy N; Meyer, Carl D: Google's pagerank and beyond: the science of search engine rankings, Princeton, N.J: Princeton University Press 2006.
- Arasu, Arvind; Cho, Junghoo; Garcia-Molina, Hector; Paepcke, Andreas und Raghavan, Sriram (2000), Searching the Web, Technical Report, Stanford University, USA, Online: http://oak.cs.ucla.edu/~cho/papers/cho-toit01.pdf
- Sergey Brin, Lawrence Page: The Anatomy of a Large-Scale Hypertextual Web Search Engine. In: Computer Networks and ISDN Systems 1998
- Charles H. Hubbell: An input-output approach to clique identification. In: Sociometry, Nummer 28, Seite 377-399, 1965
- L. Katz: A new status index derived from sociometric analysis. In: Psychmetrika, Nummer 18(1), Seite 39-43, 1953
- J. Seeley: The net of reciprocal influence: A problem in treating sociometric data, Canadian Journal of Psychology, 3, 234-240, 1949.
Weblinks
- eFactory: Erläuterungen und Berechnungsbeispiele zum PageRank-Verfahren
- Franz Embacher (Universität Wien): Bewertung von Webseiten durch Google
- Suchmaschinen-Doktor: Der PageRank-Algorithmus - Geschichte, Mathematik, Beispiele und Erweiterungen
- Links zum Thema PageRank im Open Directory Project

Suchen: (PageRank) • Books • Desktop • Produkte • Maps • Scholar • Groups • Web
Werbung: AdSense • AdWords • Analytics • DoubleClick
Kommunikation und Publishing: App Engine • Blogger • iGoogle • Kalender • Text & Tabellen • Knol • Gmail • Groups • Health • orkut • Panoramio • Reader • YouTube
Software: Browser Sync • Chrome • Desktop • Earth • Gears • Pack • Picasa • SketchUp • Talk • Toolbar • Updater
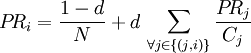
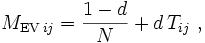

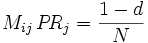
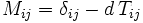
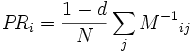
Wikimedia Foundation.