- Richardson-Iteration
-
Das Richardson-Verfahren ist in der numerischen Mathematik ein Algorithmus zur näherungsweisen Lösung von linearen Gleichungssystemen. Es zählt wie das Gauß-Seidel-Verfahren zur Klasse der Splitting-Verfahren. Als iteratives Verfahren nähert es sich schrittweise einer Lösung des linearen Gleichungssystems Ax = b an.
Inhaltsverzeichnis
Richardson-Verfahren
Durch Wahl von B = I (Einheitsmatrix) erhält man aus der allgemeinen Fixpunktgleichung
- x = Φ(x): = Ix − B − 1Ax + B − 1b
das Richardsonverfahren.
- xk + 1 = (I − A)xk + b
Dieses Verfahren konvergiert wie jede Fixpunktiteration dieser Art, falls der Spektralradius der Iterationsmatrix G: = I − A echt kleiner eins ist.
Relaxiertes Richardsonverfahren
Die Iterationsformel des relaxierten Richardson-Verfahrens lautet
- xk + 1 = (I − ωA)xk + ωb
Dabei wird in jedem Schritt das Residuum mit einem Faktor ω gewichtet. Falls A eine symmetrisch positiv definite Matrix ist so gilt für den optimalen Relaxionsparameter
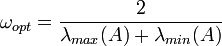 .
.
Dabei bezeichnen λmax(A) und λmin(A) den maximalen und minimalen Eigenwert von A. Für den Konvergenzradius (gleichbedeutend zum Spektralradius) gilt
dabei bezeichnet κ2(A) die Kondition der Matrix A. Das relaxierte Richardson-Verfahren konvergiert dann genauso "schnell" wie das Gradientenverfahren bei symmetrischen Matrizen, wofür man jedoch keinen Relaxionsparameter berechnen muss. Dafür kann man mit dem Richardsonverfahren auch bei unsymmetrischen Matrizen mit komplexen Eigenwerten noch Konvergenz erzwingen, solange deren Realteile alle positiv sind.
Das Verfahren ist als Glätter in Mehrgitterverfahren geeignet.
Zyklisches Richardsonverfahren
Die Konvergenz lässt sich erheblich verbessern, wenn man mehrere Schritte der Iteration mit unterschiedlichen Parametern ωk betrachtet. Man führt dazu jeweils m Schritte
zyklisch durch. Das Verfahren konvergiert, wenn der Spektralradius des Matrixpolynoms
kleiner als eins ist, und umso besser je kleiner er ist. Für eine Matrix A mit reellen und positiven Eigenwerten kann der Spektralradius durch das Maximum des reellen Polynoms
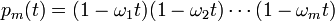 im Intervall [λmin,λmax] abgeschätzt werden. Besonders klein wird dieses Maximum, wenn man die Relaxationsparameter so wählt, dass ihre Kehrwerte gerade die Nullstellen des geeignet verschobenen Tschebyschow-Polynoms sind,
im Intervall [λmin,λmax] abgeschätzt werden. Besonders klein wird dieses Maximum, wenn man die Relaxationsparameter so wählt, dass ihre Kehrwerte gerade die Nullstellen des geeignet verschobenen Tschebyschow-Polynoms sind,Dann verbessert sich die Konvergenzaussage für symmetrische Matrizen und einen Zyklus der Länge m zu
Für realistische Probleme mit
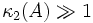 stellt dies eine große Verbesserung gegenüber dem einfachen relaxierten Verfahren dar, da nur noch die Wurzel der Konditionszahl eingeht.
stellt dies eine große Verbesserung gegenüber dem einfachen relaxierten Verfahren dar, da nur noch die Wurzel der Konditionszahl eingeht.Für symmetrisch-definite Matrizen bietet dieses Verfahren kaum Vorteile gegenüber dem Verfahren der konjugierten Gradienten, da es die Schätzung der Eigenwerte λmin,λmax erfordert. Im unsymmetrischen Fall können aber die Parameter auch für komplexe Eigenwerte gut angepasst werden, vgl. Literatur. In den meisten Fällen ist aber die Tschebyschow-Iteration vorzuziehen, da sie die gleiche Fehlerschranke für jeden Iterationsschritt und nicht nur für Vielfache der Zykluslänge
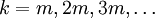 erreicht.
erreicht.Literatur
- Andreas Meister: Numerik linearer Gleichungssysteme. 2. Auflage. Vieweg 2005, ISBN 3-528-13135-7
- Bernd Fischer, Lothar Reichel: A stable Richardson iteration method for complex linear systems. Numer. Math. 54 (1988), 225-242.
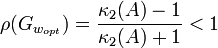
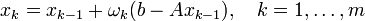
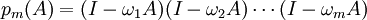
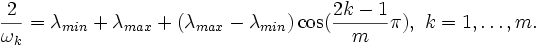
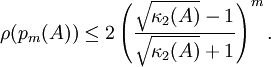
Wikimedia Foundation.