- S²
-
Die korrigierte Stichprobenvarianz (s2) ist eine Schätzfunktion für die Varianz einer Zufallsvariablen aus Beobachtungswerten, die einer Stichprobe der Grundgesamtheit entstammen. Diese Varianz wird auch in der deskriptiven Statistik als Maß für die Streubreite von Daten verwendet.
Die korrigierte Stichprobenvarianz ist definiert als
Die korrigierte Stichprobenvarianz wird oft auch als empirische Varianz oder einfach als Stichprobenvarianz bezeichnet. Diese Bezeichnung ist aber nicht eindeutig; manche Autoren bezeichnen mit empirischer Varianz bzw. Stichprobenvarianz die Größe
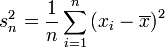 ,
,
dies ist der Maximum-Likelihood-Schätzer der Varianz unter Annahme normalverteilter Fehler.
Inhaltsverzeichnis
Berechnung ohne vorherige Mittelwertbildung
Mit dem Verschiebungssatz lässt sich die korrigierte Stichprobenvarianz in einem Durchlauf auch ohne vorherige Mittelwertbildung berechnen:
Der Verzicht der vorausgehenden Mittelwertbereinigung hat aber eine numerische Instabilität zur Folge, falls der quadrierte Mittelwert der Daten wesentlich größer als deren Varianz ist.
Erwartungstreue Schätzung der Varianz der Grundgesamtheit
Der Nenner n − 1 in der korrigierten Stichprobenvarianz erklärt sich folgendermaßen: Sind die xi unabhängig identisch verteilte Zufallsvariablen mit Varianz σ2 und ist der Mittelwert μ der Grundgesamtheit bekannt, so ist
eine erwartungstreue Schätzung für die Varianz σ2 der Grundgesamtheit.[1]
Üblicherweise kennt man aber den Mittelwert μ der Grundgesamtheit nicht und schätzt ihn daher durch den Stichprobenmittelwert
Setzt man diesen Schätzwert unbekümmert in obige Formel ein, so erhält man für die Varianz σ2 der Grundgesamtheit die Schätzfunktion
Um zu entscheiden, ob dieser Schätzer erwartungstreu ist, betrachtet man ihn als Zufallsvariable und berechnet wie folgt den Erwartungswert:
wobei beim vorletzten Gleichheitszeichen die Definition der Varianz und die Formel zur Berechnung des Standardfehlers aus Varianz der Grundgesamtheit und Stichprobenumfang benutzt wurden. Daraus ergibt sich, dass die Schätzfunktion
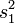 nicht erwartungstreu ist, und dass man einen erwartungstreuen Schätzer für die Varianz erhält, wenn man mit dem Faktor
nicht erwartungstreu ist, und dass man einen erwartungstreuen Schätzer für die Varianz erhält, wenn man mit dem Faktor 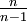 multipliziert. So gelangt man zur korrigierten Stichprobenvarianz
multipliziert. So gelangt man zur korrigierten StichprobenvarianzFür diese gilt nun unabhängig von der genauen Verteilung der xi
Der Erwartungswert der korrigierten Stichprobenvarianz ist also gleich der Varianz der Grundgesamtheit. Die korrigierte Stichprobenvarianz ist somit eine erwartungstreue Schätzung für die Varianz.[1]
Darstellung mit paarweisen Differenzen
Die Formel der korrigierten Stichprobenvarianz lässt sich auch so darstellen, dass sie keinen Bezug auf ein Lage-Maß wie den Mittelwert beinhaltet:
Insbesondere gilt für eine Stichprobe des Umfangs n = 2:
Diese Formel liefert den gleichen Wert wie obige Formel, wie sich beispielsweise folgendermaßen erkennen lässt:
denn
Diese folgt nämlich aus
Die Formel
lässt deutlich die Absicht der korrigierten Stichprobenvarianz erkennen. Paare i = j werden nicht berücksichtigt; die Differenz der entsprechenden x-Werte wäre ohnehin nur null. Berücksichtigte man sie, was übrigens dem Ersetzen des Divisors n − 1 durch n in der eingangs erwähnten Definition entspräche, dann unterläge die Stichprobenvarianz einer groben Verzerrung hinsichtlich der Datenzahl n. Bei nur zwei Daten gäbe es vier Paare, wovon zwei, nämlich (x1,x1) und (x2,x2) stets die Differenz null aufwiesen, was die Stichprobenvarianz kräftig nach unten drücken würde. Hat man dagegen viele Daten, dann ginge der Anteil der (xi,xi)-Paare drastisch zurück. Deshalb berücksichtigt man bei der Definition der korrigierten Stichprobenvarianz nur Paare (xi,xj) mit
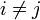 . Nur wenn deren Differenzen sich zu null ergeben (wenn also xi = xj ist) oder wenigstens nicht groß sind, ist es ein Indiz für eine kleine Streuung der Daten.
. Nur wenn deren Differenzen sich zu null ergeben (wenn also xi = xj ist) oder wenigstens nicht groß sind, ist es ein Indiz für eine kleine Streuung der Daten.Die ausschließliche Berücksichtigung von Paaren (xi,xj) mit
bei der Berechnung der korrigierten Stichprobenvarianz entspricht der eingangs erwähnten Varianz-Definition und rechtfertigt so die Division der dortigen Summe durch n − 1.Die sich auf paarweise Differenzen beziehende Definition der korrigierten Stichprobenvarianz in diesem Abschnitt bildet auch die Grundlage[2] der Definition empirischer Variogrammwerte, die in Unkenntnis der Bedeutung des Faktors
 oft Semivarianzen genannt werden.
oft Semivarianzen genannt werden.Stichprobenstandardabweichung
Die Wurzel aus der korrigierten Stichprobenvarianz, s, ist die Stichprobenstandardabweichung. Da die Erwartungstreue bei Anwendung einer nichtlinearen Funktion in den meisten Fällen verloren geht, ist die Stichprobenstandardabweichung im Gegensatz zur korrigierten Stichprobenvarianz kein erwartungstreuer Schätzer für die Standardabweichung.
Einzelnachweise
- ↑ a b Marek Fisz: Wahrscheinlichkeitsrechnung und mathematische Statistik. VEB Deutscher Verlag der Wissenschaften, Elfte Auflage, Berlin 1989, Beispiel 13.3.2, Seite 538f.
- ↑ Martin Bachmaier & Matthias Backes: Variogram or Semivariogram - Explaining the Variances in a Variogram. Article DOI: 10.1007/s11119-008-9056-2, Precision Agriculture, Springer Verlag, Berlin, Heidelberg, New York, 2008.
Weblink
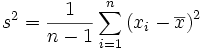
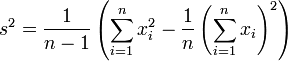
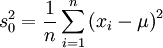
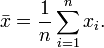
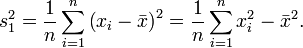
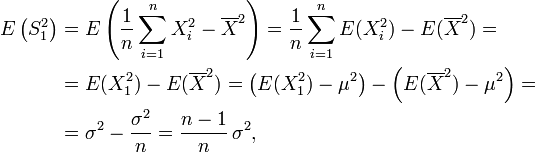
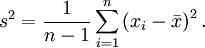
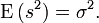
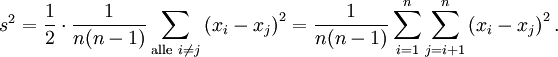
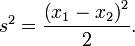
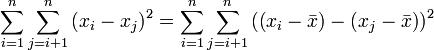
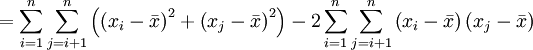
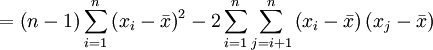
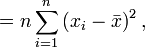
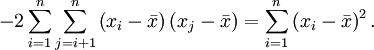
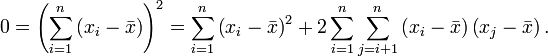
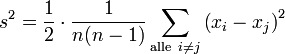
Wikimedia Foundation.