- Bayes-Netz
-

Dieser Artikel wurde auf der Qualitätssicherungsseite des Portals Mathematik eingetragen. Dies geschieht, um die Qualität der Artikel aus dem Themengebiet Mathematik auf ein akzeptables Niveau zu bringen. Dabei werden Artikel gelöscht, die nicht signifikant verbessert werden können. Bitte hilf mit, die Mängel dieses Artikels zu beseitigen, und beteilige dich bitte an der Diskussion!
Bayes'sche Netze dienen der Repräsentation von nicht beobachtbaren Ereignissen und daraus möglichen Schlussfolgerungen. Sie stellen eine spezielle Form der Formulierung von wahrscheinlichkeitstheoretischen Modellen dar.
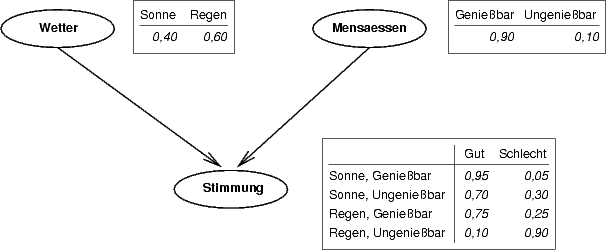
Ein Bayes'sches Netz ist ein gerichteter azyklischer Graph (DAG), in dem die Knoten Zufallsvariablen und die Kanten bedingte Abhängigkeiten zwischen den Variablen beschreiben. Jedem Knoten des Netzes ist eine bedingte Wahrscheinlichkeitsverteilung der durch ihn repräsentierten Zufallsvariable gegeben, die Zufallsvariablen an den Elternknoten zuordnet. Sie werden durch Wahrscheinlichkeitstabellen beschrieben. Diese Verteilung kann beliebig sein, jedoch wird häufig mit diskreten oder Normalverteilungen gearbeitet. Eltern eines Knotens v sind diejenigen Knoten, von denen eine Kante zu v führt.
Ein Bayes'sches Netz dient dazu, die gemeinsame Wahrscheinlichkeitsverteilung aller beteiligten Variablen unter Ausnutzung bekannter bedingter Unabhängigkeiten möglichst kompakt zu repräsentieren. Dabei wird die bedingte (Un)Abhängigkeit von Untermengen der Variablen mit dem a-priori Wissen kombiniert.
Sind X1, ..., Xn einige der im Graphen vorkommenden Zufallsvariablen (die abgeschlossen sind unter hinzufügen von Elternvariablen), so berechnet sich deren gemeinsame Verteilung als
Hat ein Knoten keine Eltern, so handelt es sich bei der assoziierten Wahrscheinlichkeitsverteilung um eine unbedingte Verteilung.
Inhaltsverzeichnis
Beispiel
Schließen in Bayes'schen Netzen
Ist von manchen der Variablen, etwa E1, ..., Em, der Wert bekannt, d. h. liegt Evidenz vor, so kann mit Hilfe verschiedener Algorithmen auch die bedingte Wahrscheinlichkeitsverteilung von X1, ..., Xn gegeben E1, ..., Em berechnet und damit Inferenz betrieben werden.
Das Inferenzproblem, sowohl das exakte wie auch das approximative, in Bayes'schen Netzen ist NP-schwer. In größeren Netzen bieten sich jedoch approximative Verfahren an. Exakte Verfahren sind zwar etwas genauer als approximative, dies spielt aber in der Praxis oft nur eine unwesentliche Rolle, da Bayes'sche Netze zur Entscheidungsfindung eingesetzt werden wo die genauen Wahrscheinlichkeiten nicht benötigt werden. Des Weiteren sind auch Implementierungen exakter Inferenzverfahren, bedingt durch die limitierte Gleitkommaarithmetik heutiger Rechner, nicht zwangsläufig genau.
Exakte Inferenz
Zur exakten Inferenz in Bayes'schen Netzen eignen sich u.a. folgende Algorithmen:
- Variablenelimination
- Clustering-Algorithmen
Approximative Inferenz
- Rejection sampling
- Likelihood weighting
- Self-Importance
- Adaptive Importance
- Markow-Ketten
- Monte-Carlo-Algorithmus, z.B. Gibbs-Sampling
Inferenztypen
- Diagnostisch: Von Effekten zu Ursachen
- Kausal: Von Ursachen zu Effekten
- Interkausal: Zwischen Ursachen eines gemeinsamen Effekts
- Gemischt: Kombination der Vorangegangenen
Lernen Bayes'scher Netze
Soll aus vorliegenden Daten automatisch ein Bayes'sches Netz generiert werden, das die Daten möglichst gut beschreibt, so stellen sich zwei mögliche Probleme: Entweder ist die Graphenstruktur des Netzes bereits gegeben und man muss sich nicht mehr um die Ermittlung bedingter Unabhängigkeiten, sondern nur noch um die Berechnung der bedingten Wahrscheinlichkeitsverteilungen an den Knoten des Netzes kümmern, oder man muss neben den Parametern auch eine Struktur eines geeigneten Netzes lernen.
Parameterlernen
Geht man nicht von einem vollen (Bayes'schen) Wahrscheinlichkeitsmodell aus, wählt man im allgemeinen
als Schätzmethode. Für den Fall eines vollständigen (Bayes'schen) Wahrscheinlichkeitsmodells bietet sich zur Punktschätzung die
an. Lokale Maxima der Likelihood- bzw. A-Posteriorifunktionen können im Fall von vollständigen Daten und vollständig beobachteten Variablen üblicherweise mit gängigen Optimierungsalgorithmen wie
gefunden werden. Für den (als die Regel anzusehenden) Fall fehlender Beobachtungen wird üblicherweise der mächtige und weit verbreitete
- Expectation-Maximization-Algorithmus (EM), bzw. der
- Generalisierte Expectation-Maximization-Algorithmus (GEM)
verwendet.
Strukturlernen
Strukturlernen kann u.a. mit dem K2-Algorithmus (approximativ, unter Verwendung einer geeigneten Zielfunktion) oder dem PC-Algorithmus erfolgen.
Bedingte Unabhängigkeit
Zur Ermittlung bedingter Unabhängigkeiten zweier Variablenmengen gegeben eine dritte solche Menge genügt es, die Graphenstruktur des Netzes zu untersuchen. Man kann zeigen, dass der (graphentheoretische) Begriff der d-Separation mit dem Begriff der bedingten Unabhängigkeit zusammenfällt.
Anwendung
Bayes'sche Netze werden als Form probabilistischer Expertensysteme eingesetzt, wobei die Anwendungsgebiete unter anderem in Bioinformatik, Musteranalyse, Medizin und Ingenieurswissenschaften liegen. In der Tradition der Künstlichen Intelligenz liegt der Fokus Bayes'scher Netze auf der Ausnutzung derer graphischen Strukturen zur Ermöglichung abduktiver und deduktiver Schlüsse, die in einem unfaktorisierten Wahrscheinlichkeitsmodell undurchführbar wären. Realisiert wird dies durch die verschiedenen Inferenzalgorithmen.
Es ist jedoch zu betonen, dass die Grundidee Bayes'scher Netze, nämlich die graphische Faktorisierung eines Wahrscheinlichkeitsmodells auch in anderen Traditionen eingesetzt wird wie in der Bayesschen Statistik und der Tradition der sogenannten Graphischen Modelle zu Zwecken der Datenmodellierung. Anwendungsgebiete sind hier vor allem Epidemiologie, Medizin und Sozialwissenschaften.
Literatur
- Enrique Castillo, Jose Manuel Gutierrez, Ali S. Hadi: Expert Systems and Probabilistic Network Models. Springer-Verlag, New York 1997, ISBN 0-3879-4858-9.
- Finn V. Jensen: Bayesian Networks and Decision Graphs. Springer-Verlag, New York 2001, ISBN 0-3879-5259-4.
- Richard E. Neapolitan: Learning Bayesian Networks. Prentice Hall, 2003, ISBN 0-13-012534-2.
- Judea Pearl: Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference. Morgan Kauffmann Publishers, San Francisco 1988, ISBN 0-9346-1373-7.
- Judea Pearl: Causality. Cambridge University Press, Cambridge 2000, ISBN 0-5217-7362-8.
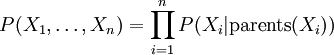
Wikimedia Foundation.