- Dateisystem
-
Das Dateisystem ist die Ablageorganisation auf einem Datenträger eines Computers. Dateien müssen gelesen, gespeichert oder gelöscht werden. Für den Nutzer müssen Dateiname und computerinterne Dateiadressen in Einklang gebracht werden. Das leichte Wiederfinden und das sichere Abspeichern sind wesentlich. Das Ordnungs- und Zugriffssystem berücksichtigt die Geräteeigenschaften und ist normalerweise Bestandteil des Betriebssystems.
Dateien haben in einem Dateisystem fast immer mindestens einen Dateinamen sowie Attribute, die nähere Informationen über die Datei geben. Die Dateinamen sind in speziellen Dateien, den Verzeichnissen, abgelegt. Über diese Verzeichnisse kann ein Dateiname und damit eine Datei vom System gefunden werden. Ein Dateisystem bildet somit einen Namensraum. Alle Dateien (oder dateiähnlichen Objekte) sind so über eine eindeutige Adresse (Dateiname inkl. Pfad oder URI) – innerhalb des Dateisystems – aufrufbar. Der Name einer Datei und weitere Informationen, die den gespeicherten Daten zugeordnet sind, werden als Meta-Daten bezeichnet.
Für unterschiedliche Datenträger (wie Magnetband, Festplatte, optische Datenträger (CD, DVD, …), Flashspeicher, …) gibt es spezielle Dateisysteme.
Das Dateisystem stellt eine bestimmte Schicht des Betriebssystems dar: Alle Schichten darüber (Rest des Betriebssystems, Anwendungen) können auf Dateien abstrakt über deren Klartext-Namen zugreifen. Erst im Dateisystem werden diese abstrakten Angaben in physische Adressen (Blocknummer, Spur, Sektor usw.) auf dem Speichermedium umgesetzt. In der Ebene darunter kommuniziert das Dateisystem dazu mit dem jeweiligen Gerätetreiber und der Firmware des Speichersystems, welche an zusätzlicher Organisation z. B. noch den Ersatz fehlerhafter Sektoren durch Reservesektoren erledigen.
Inhaltsverzeichnis
Geschichte
Historisch sind schon die ersten Lochstreifen- (auf Film- später auf Papierstreifen) und Lochkarten-Dateien Dateisysteme. Sie bilden ebenso wie Magnetbandspeicher lineare Dateisysteme. Die später für die Massenspeicherung und schnellen Zugriff entwickelten Trommel- und Festplattenspeicher ermöglichten dann erstmals wahlfreien Zugriff auf beliebige Positionen im Dateisystem und damit komplexere Dateisysteme. Diese Dateisysteme bieten die Möglichkeit, per Namen auf eine Datei zuzugreifen. Das Konzept der Dateisysteme wurde schließlich soweit abstrahiert, dass auch Zugriffe auf Dateien im Netz und auf Geräte, die virtuell als Datei verwaltet werden, über Dateisysteme durchgeführt werden können. Somit sind Anwendungsprogramme in der Lage, auf diese unterschiedlichen Datenquellen über eine einheitliche Schnittstelle zuzugreifen.
Organisation von Massenspeichern
Massenspeichergeräte wie Festplatten-, CD-ROM- und Diskettenlaufwerke haben normalerweise eine Blockstruktur, d. h. aus Betriebssystemsicht lassen sich Daten nur als ganze Datenblöcke lesen oder schreiben. Die Hardware der Speichergeräte präsentiert sich gegenüber dem Betriebssystem auf einer bestimmten Ebene lediglich als große lineare Fläche mit vielen nummerierten Blöcken.
Ein Block umfasst heute meistens 512 (=29) Bytes, auf optischen Medien (CD-ROM, DVD-ROM) 2048 (=211) Bytes. Moderne Betriebssysteme fassen aus Performance- und Verwaltungsgründen mehrere Blöcke zu einem Cluster fester Größe zusammen. Heute sind Cluster mit acht oder noch mehr Blöcken üblich, also 4096 Bytes pro Cluster. Die Clustergröße ist im allgemeinen eine Zweierpotenz (1024, 2048, 4096, 8192 usw.)
Eine Datei ist ein definierter Abschnitt eines Datenspeichers, die auf dem Gerät aus einem oder mehreren Clustern besteht. Jede Datei erhält außerdem eine Beschreibungsstruktur, die die tatsächliche Größe, Referenzen auf die verwendeten Cluster und evtl. weitere Informationen wie Dateityp, Eigentümer, Zugriffsrechte enthalten kann.
Für die Zuordnung von Clustern zu Dateien gibt es dabei mehrere Möglichkeiten.
- Die Referenz einer Datei besteht aus der Clusternummer des Anfangsclusters und der Anzahl der darauf (physikalisch sequenziell) folgenden Cluster. Nachteile: bei Vergrößerung muss ggf. die ganze Datei verschoben werden. Dies verkompliziert das Dateihandling und führt zu unzureichender Performance bei vielen großen Dateien. So kann es vorkommen, dass eine Datei nicht gespeichert werden kann, obwohl noch genügend freier Speicher auf dem Datenträger vorhanden ist.
- Die Referenz einer Datei besteht aus der ersten Clusternummer. In jedem Cluster der Datei wird die Clusternummer des Folgeclusters gespeichert. Es ergibt sich eine verkettete Liste. Nachteile: Will man die Datei nicht sequenziell lesen, sondern zum Beispiel nur das Ende, muss das Betriebssystem dennoch die ganze Datei einlesen, um das Ende zu finden.
- Freie Zuordnung von Dateiclustern zu Folgeclustern durch eine Tabelle auf dem Massenspeicher (Beispiel: FAT). Nachteile: sehr große Beschreibungsstruktur, sequenzielles Lesen oder Schreiben etwas langsamer als ideal, da Zuordnungsinformationen weder gebündelt noch bei den Daten vorliegen.
- Speicherung eines Feldes von Tupeln (Extent-Anfangscluster, Extentlänge) in der Beschreibungsstruktur der Datei. Ein Extent ist dabei eine Folge von sequentiellen Clustern. Heute in vielen Dateisystemen so umgesetzt.
Verzeichnisse enthalten Dateinamen und Referenzen zu den jeweiligen Beschreibungsstrukturen. Da Verzeichnisse auch Speicherflächen sind, werden meist speziell gekennzeichnete Dateien als Verzeichnisse verwendet. Die erste Beschreibungsstruktur kann dabei das Ausgangsverzeichnis enthalten.
Im allgemeinen ist der erste Block für einen so genannten Bootblock (z. B. Master Boot Record) reserviert, der für das Hochfahren des Systems verwendet werden kann. Er ist nicht Teil des eigentlichen Dateisystems.
Ein weiterer eigener Bereich auf dem Speichermedium dient der Buchführung, welche Blöcke oder Cluster schon belegt und welche noch frei sind. Ein oft dafür genutztes Mittel ist die Block Availability Map (BAM), in der für jeden Block ein Speicherbit angelegt ist, das anzeigt, ob der Block belegt oder frei ist.
Auf einem Speichermedium mit mehreren Partitionen stehen ganz am Anfang typischerweise die Daten zu diesen Partitionen, und die Ausführungen oben beziehen sich auf die einzelnen Partitionen, die sich eine nach der anderen an diese Partitionstabelle anschließen.
Boot Beschreibungsstrukturen Liste freier Cluster Cluster mit Dateien und Verzeichnissen Beispiel für die Aufteilung eines Massenspeichers für ein simples Dateisystem Aus Effizienzgründen, also vor allem zur Erhöhung der Leistung/Zugriffsgeschwindigkeit, wurden diverse Strategien entwickelt, wie diese Organisationsstrukturen innerhalb des zur Verfügung stehenden Speicherbereichs angeordnet werden. Da es beispielsweise in vielen Dateisystemen beliebig viele Unterverzeichnisse geben kann, verbietet es sich von vornherein, feste Plätze für diese Verzeichnisstrukturen zu reservieren, es muss alles dynamisch organisiert werden. Es gibt auch Dateisysteme wie einige von Commodore, die die grundlegenden Organisationsstrukturen wie Wurzelverzeichnis und BAM in der Mitte des Speicherbereichs (statt wie meist bei anderen an dessen Anfang) anordnen, damit die physischen Wege von dort zu den eigentlichen Daten und zurück im Mittel verringert werden. Allgemein kann es ein Strategieansatz sein, eigentliche Daten und ihre Organisationsdaten in möglichst großer physischer Nähe anzuordnen.
Zugriff auf Massenspeicher
Ein Programm greift auf die Massenspeicher über das Dateisystem zu. Unter Unix und ähnlichen Betriebssystemen werden dazu Systemaufrufe zur Verfügung gestellt. Die wichtigsten Systemaufrufe sind hier:
- Systemaufrufe für Verzeichnisse:
mkdir,rmdir
Erzeugen und Löschen eines Verzeichnissesopendir,closedir
Öffnen und Schließen eines Verzeichnissesreaddir
Lesen von Verzeichniseinträgenchdir
Wechseln in ein anderes Verzeichnis
- Systemaufrufe für Dateien:
creat,unlink
Erzeugen und Löschen einer Dateiopen,close
Öffnen und Schließen einer Dateiread,write
Lesen und Schreibenseek
Neupositionieren des Schreib-/Lese-Zeigers
Außerdem bietet das Betriebssystem Verwaltungsfunktionen, zum Beispiel für das Umbenennen, das Kopieren und Verschieben, Erzeugen eines Dateisystems auf einem neuen Datenträger, für Konsistenzprüfung, Komprimierung oder Sicherung (je nach Betriebssystem und Dateisystem verschieden).
Die Umsetzung der Systemaufrufe eines Programms werden oft vom Kernel eines Betriebssystems implementiert und unterscheiden sich bei den verschiedenen Dateisystemen. Der Kernel übersetzt die Zugriffe dann in die Blockoperationen des jeweiligen Massenspeichers. (Anmerkung: Tatsächlich trifft dies nur auf so genannte monolithische Kernel zu. Hingegen sind auf einem Mikrokernel oder Hybridkernel aufgebaute Systeme so konzipiert, dass die Dateisystemoperationen nicht vom Kernel selbst ausgeführt werden müssen.)
Wenn ein Programm eine Datei mittels open öffnet, wird der Dateiname im Verzeichnis gesucht. Die Blöcke auf dem Massenspeicher ermittelt das Betriebssystem aus den entsprechenden Beschreibungsstrukturen. Falls eine Datei im Verzeichnis gefunden wird, erhält man auch ihre Beschreibungsstruktur und damit die Referenzen zu den zugehörigen Clustern und gelangt über diese zu den konkreten Blöcken.
Mit read kann das Programm dann auf die Cluster der Datei (und damit auf die Blöcke auf dem Massenspeicher) zugreifen. Wird eine Datei aufgrund von write größer, wird bei Bedarf ein neuer Cluster aus der Freiliste entnommen und in der Beschreibungsstruktur der Datei hinzugefügt. Auch die anderen Systemaufrufe lassen sich so in Cluster- bzw. Blockzugriffe übersetzen.
Arten von Dateisystemen
Lineare Dateisysteme
Die historisch ersten Dateisysteme waren lineare Dateisysteme auf Lochband oder Lochkarte sowie die noch heute für die Sicherung von Daten eingesetzten Magnetbandsysteme.
Hierarchische Dateisysteme
Frühe Dateisysteme (CP/M, Apple DOS, Commodore DOS) hatten nur ein einzelnes Verzeichnis, das dann Verweise auf alle Dateien des Massenspeichers enthielt. Mit wachsender Kapazität der Datenträger wurde es immer schwieriger, den Überblick über hunderte und tausende Dateien zu bewahren, deshalb wurde das Konzept der Unterverzeichnisse eingeführt. So wurde dieses eine Verzeichnis in den meisten modernen Dateisystemen zum Wurzelverzeichnis, das neben normalen Dateien auch Verweise auf weitere Verzeichnisse, die Unterverzeichnisse, enthalten kann. Auch diese dürfen wieder Unterverzeichnisse haben.
Dadurch entsteht eine Verzeichnisstruktur, die oft als Verzeichnisbaum dargestellt wird. Das Festplattenlaufwerk C: unter Windows beinhaltet beispielsweise neben Dateien wie boot.ini und ntldr auch Verzeichnisse wie Programme, Dokumente und Einstellungen usw. Ein Verzeichnis wie zum Beispiel Eigene Dateien kann dann wieder Unterverzeichnisse wie Eigene Bilder oder Texte enthalten. In Texte können dann beispielsweise die normalen Dateien Brief1.txt und Brief2.txt stehen.
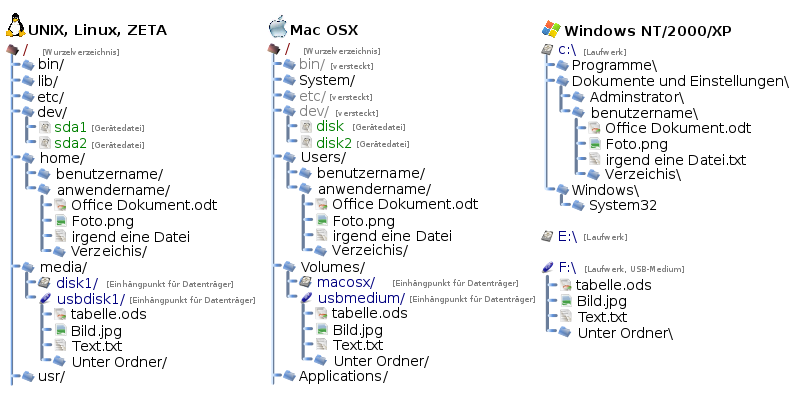
Die Verzeichnisse werden auch Ordner genannt und sind, je nach Betriebssystem, durch umgekehrten Schrägstrich (englisch Backslash) „\“ (DOS, Windows, TOS), Schrägstrich (englisch Slash) „/“ (Unix, Linux, Mac OS X, AmigaOS), Punkt „.“ (OpenVMS) oder Doppelpunkt „:“ (ältere Mac-OS-Versionen) getrennt. Da sich eine Hierarchie von Verzeichnissen und Dateien ergibt, spricht man hier von hierarchischen Dateisystemen. Den Weg durch das Dateisystem, angegeben durch Verzeichnisnamen, die mit den Trennzeichen voneinander getrennt werden, nennt man Pfad. Auf die Datei Brief1.txt kann man mit
C:\Dokumente und Einstellungen\benutzername\Eigene Dateien\Texte\Brief1.txt(Windows 2000/XP)/Users/benutzername/Texte/Brief1.txt(Mac OS X)/home/benutzername/Texte/Brief1.txt(Unix/Linux)Laufwerksname:verzeichnis/unterverzeichnis/Brief1.txt(AmigaOS)DISK$Laufwerksname:[USERS.benutzername]Brief1.TXT;1(OpenVMS)
zugreifen. Bei DOS/Windows gibt es Laufwerksbuchstaben gefolgt von einem Doppelpunkt, die den Pfaden innerhalb des Dateisystems vorangestellt werden. Jeder Datenträger bekommt seinen eigenen Buchstaben, zum Beispiel meist C: für die erste Partition der ersten Festplatte. Bei Unix gibt es keine Laufwerksbuchstaben, sondern nur einen einzigen Verzeichnisbaum. Die einzelnen Datenträger werden dort an bestimmten Stellen im Baum eingehängt (Kommando mount), so dass alle Datenträger zusammen den Gesamtbaum ergeben. Windows-Varianten, die auf Windows NT basieren, arbeiten intern ebenfalls mit einem solchen Baum, dieser Baum wird aber gegenüber dem Anwender verborgen.
Unter AmigaOS erfolgt eine Mischung der Ansätze von DOS und Unix. Die nach Unix-Nomenklatur bezeichneten Laufwerke werden mit Doppelpunkt angesprochen (df0:, hda1:, sda2:). Darüber hinaus können „logische“ Doppelpunkt-Laufwerksbezeichnungen wie
LIBS:perASSIGNunabhängig vom „physikalischen Datenträger“ vergeben werden.Die Verzeichnispfade von OpenVMS unterscheiden sich stark von Unix-, DOS- und Windows-Pfaden. Zuerst nennt OpenVMS die Geräteart, z. B. bezeichnet „
DISK$“ einen lokalen Datenträger. Der Laufwerksname (bis zu 255 Zeichen lang) wird angefügt und mit einem Doppelpunkt abgeschlossen. Der Verzeichnis-Teil wird in eckige Klammern gesetzt. Die Unterverzeichnisse werden durch Punkte getrennt, z. B. „[USERS.Verzeichis.Verzeichnis2]“. Am Ende des Pfads folgt der Dateiname, beispielsweise „Brief1.TXT;1“. Dessen erster Teil ist ein sprechender Name und bis zu 39 Zeichen lang. Nach einem Punkt folgt der dreistellige Dateityp, ähnlich wie bei Windows. Am Ende wird die Version der Datei, getrennt durch ein Semikolon „;“, angefügt.Häufig bezeichnet der Begriff Dateisystem nicht nur die Struktur und die Art, wie die Daten auf einem Datenträger organisiert werden, sondern allgemein den ganzen Baum mit mehreren verschiedenen Dateisystemen (Festplatte, CD-ROM, …). Korrekterweise müsste man hier von einem Namensraum sprechen, der von verschiedenen Teilnamensräumen (den Dateisystemen der eingebundenen Datenträger) gebildet wird, da aber dieser Namensraum sehr dateibezogen ist, wird häufig nur vom Dateisystem gesprochen.
Netzwerkdateisysteme
Die Systemaufrufe wie open, read usw. können auch über ein Netzwerk an einen Server übertragen werden. Dieser führt dann die Zugriffe auf seine Massenspeicher durch und liefert die angeforderte Information an den Client zurück.
Da dieselben Systemaufrufe verwendet werden, unterscheiden sich die Zugriffe aus Programm- und Anwendersicht nicht von der auf die lokalen Geräte. Man spricht hier von transparenten Zugriffen, weil der Anwender die Umlenkung auf den anderen Rechner nicht sieht, sondern scheinbar unmittelbar auf die Platte des entfernten Rechners schaut – wie durch eine transparente Glasscheibe. Für Netzwerkdateisysteme stehen spezielle Netzwerkprotokolle zur Verfügung.
Kann auf ein Dateisystem etwa in einem Storage Area Network (SAN) von mehreren Systemen parallel direkt zugriffen werden, spricht man von einem Globalen- oder Cluster-Dateisystem. Dabei sind zusätzliche Maßnahmen zu ergreifen, um Datenverlust (engl. data corruption) durch gegenseitiges Überschreiben zu vermeiden. Dazu wird ein Metadaten-Server eingesetzt. Alle Systeme leiten die Metadaten-Zugriffe – typischerweise über ein LAN – an den Metadaten-Server weiter, der diese Operationen wie Verzeichniszugriffe und Block- beziehungsweise Clusterzuweisungen vornimmt. Der eigentliche Datenzugriff erfolgt dann über das SAN, als ob das Dateisystem lokal angeschlossen wäre. Da der Zusatzaufwand (engl. „overhead“) durch die Übertragung an den Metadaten-Server insbesondere bei großen Dateien kaum ins Gewicht fällt, kann so eine Übertragungsgeschwindigkeit ähnlich der eines direkt angeschlossenen Dateisystems realisiert werden.
Eine Besonderheit stellt das WebDAV-Protokoll dar, das Filesystem-Zugriffe auf entfernt liegende Dateien via HTTP ermöglicht.
Spezielle virtuelle Dateisysteme
Das open-read-Modell lässt sich auch auf Geräte und Objekte anwenden, die normalerweise nicht über Dateisysteme angesprochen werden. Dadurch wird der Zugriff auf diese Objekte identisch mit dem Zugriff auf normale Dateien, was meist Vorteile bringt.
Unter den derzeitigen Linux-Kernels (u. a. Version 2.6) lassen sich System- und Prozessinformation über das virtuelle proc-Dateisystem abfragen und ändern. Die virtuelle Datei /proc/cpuinfo liefert zum Beispiel Informationen über den Prozessor.
Solche Pseudo-Dateisysteme wie proc gibt es unter Linux einige: Dazu zählen sysfs, usbfs oder devpts; unter einigen BSDs gibt es ein kernfs. All diese Dateisysteme enthalten nur rein virtuell vorhandene Dateien mit Informationen oder Geräten, die auf eine „Datei“ abgebildet werden.
Der Kernel gaukelt hier quasi die Existenz einer Datei vor, wie sie auch auf einem Massenspeicher vorhanden sein könnte.
Dateien in ramfs oder tmpfs und ähnlichen Dateisystemen existieren jedoch tatsächlich, werden aber nur im Speicher gehalten. Sie werden aus Geschwindigkeitsgründen und aus logisch-technischen Gründen während der Boot-Phase eingesetzt.
Besonderheiten
Viele moderne Dateisysteme haben das Prinzip der Datei verallgemeinert, so dass man in einer Datei nicht nur eine Folge von Bytes, einen so genannten Stream (engl. Strom), sondern mehrere solcher Folgen (Alternate Data Streams) abspeichern kann. Dadurch ist es möglich, Teile einer Datei zu bearbeiten, ohne eventuell vorhandene andere Teile, die sehr groß sein können, verschieben zu müssen.
Problematisch ist die mangelnde Unterstützung von multiplen Streams. Das äußert sich zum einen darin, dass alternative Daten beim Transfer auf andere Dateisysteme (ISO 9660, FAT, ext2) ohne Warnung verloren gehen, zum anderen darin, dass kaum ein Werkzeug diese unterstützt, weshalb man die dort gespeicherten Daten nicht ohne Weiteres einsehen kann und beispielsweise Virenscanner dort abgespeicherte Viren übersehen.
Dadurch dass der Hauptdatenstrom von Änderungen an den anderen Strömen nicht berührt wird, ergeben sich Vorteile für die Performance, den Platzbedarf und die Datensicherheit.
Unter Inode-basierten Dateisystemen sind Sparse-Dateien, Hardlinks und symbolische Verknüpfungen möglich. Auch technisch anders aufgebaute Dateisysteme kennen neuerdings zum Teil diese Eigenschaften.
Für Massenspeicher wie CD-ROM oder DVD gibt es eigene Dateisysteme, die Betriebssystem-übergreifend Anwendung finden, vor allem ISO 9660, weitere siehe unten bei Sonstige.
Dateisysteme aus dem Unix-Bereich kennen besondere Gerätedateien. Deren Namen sind dabei oft per Übereinkommen festgelegt, sie können nach Belieben umbenannt werden; so haben zum Beispiel auch die Tastatur, Maus und andere Schnittstellen spezielle Dateinamen, auf die mit open, read, write zugegriffen werden kann, sogar der Hauptspeicher hat einen Dateinamen (/dev/mem). (Die Unix-Philosophie dazu lautet: „Alles ist eine Datei, und wenn nicht, sollte es eine Datei sein.“)
In anderen Betriebssystemen (wie unter MS-DOS ab Version 2.0) gibt es Gerätenamen mit besonderen Bedeutungen, die dem System der Gerätedateien ähnlich sind: COM:, CON:, LPT:, PRN: und andere. Diese Geräte können analog zu einer Datei geöffnet und über eine Zugriffsnummer (Handle) gelesen und beschrieben werden. Sie haben aber verständlicherweise keinen Dateizeiger. Im Unterschied zu den Blockgeräten (auch „Laufwerke“ genannt: A:, B:, C: usw.) enthalten sie keine Dateien, sondern verhalten sich selbst – mit gewissen Einschränkungen – wie Dateien. Diese Pseudodateien existieren seit DOS 2, das stark von UNIX beeinflusst wurde. Unter Berücksichtigung der DOS-Gerätetreiberspezifikation[1] ist es dem Benutzer möglich, eigene Gerätetreiber zu schreiben, sie per DEVICE-Befehl zu laden und über ebensolche Pseudodateinamen anzusprechen. Diese besonderen Dateinamen waren in der Vergangenheit öfters Anlass von Sicherheitsproblemen, da die entsprechenden Namen zum Teil einigen Applikationen nicht bekannt waren und daher nicht herausgefiltert wurden, aber zum Teil auch weil der Zugriffsschutz auf die damit assoziierten Geräte unzureichend geregelt war.
Darüber hinaus existieren Dateisysteme, die mehrere darunterliegende Speichermedien („Volumes“) überspannen können, die eine Versionierung von Dateien schon inhärent ermöglichen (VMS), deren Größe zur Laufzeit geändert werden kann (AIX).
Manche Dateisysteme bieten Verschlüsselungsfunktionen an, Umfang und Sicherheit der Funktionen variieren dabei.
Assoziative Dateiverwaltung
Diese werden häufig fälschlicherweise als Datenbankdateisysteme oder SQL-Dateisysteme bezeichnet, hierbei handelt es sich eigentlich nicht um Dateisysteme, sondern um Informationen eines Dateisystems, die in aufgewerteter Form in einer Datenbank gespeichert und in, für den Anwender intuitiver Form, über das virtuelle Dateisystem des Betriebssystems dargestellt werden.
Hauptartikel: assoziative Dateiverwaltung
Sicherheitsaspekte
Das Dateisystem darf von sich aus keine Daten verlieren oder ungewollt überschreiben. Insbesondere zwei Fälle bringen Gefahren mit sich:
Wenn im Multitasking mehrere Aufgaben gleichzeitig anstehen, muss das Dateisystem die einzelnen Aktionen sauber auseinanderhalten, damit nichts durcheinanderkommt. Wenn die Aufgaben auch noch dieselbe Datei ansprechen, sei es nur lesend oder auch schreibend, werden typischerweise entsprechende Sperrmechanismen (Locks) zur Verfügung gestellt oder automatisch in Kraft gesetzt, um Konflikte zu vermeiden. Gleichzeitige Zugriffe von mehreren Seiten z. B. auf eine große Datenbankdatei sind aber auch der Normalfall, so dass man neben globalen, also die ganze Datei betreffenden, Sperren auch solche nur für einzelne Datensätze (Records) benutzen kann.
Wenn ein Laufwerk gerade auf ein Speichermedium schreibt und die Betriebsspannung in diesem Moment ausfällt, dann besteht die Gefahr, dass nicht nur die eigentlichen Daten unvollständig geschrieben werden, sondern dass vor allem die organisatorischen Einträge im Verzeichnis nicht mehr korrekt aktualisiert werden. Um diese Gefahr zumindest möglichst klein zu halten, wird einerseits per Hardware versucht, genug Energiepuffer (Kondensatoren in der Versorgung) bereitzuhalten, so dass ein Arbeitsvorgang noch zu Ende geführt werden kann, andererseits ist die Software so ausgelegt, dass die Arbeitsschritte möglichst „atomar“ ausgelegt sind, das heißt die empfindliche Zeitspanne mit unvollständigen Dateneinträgen so kurz wie irgend möglich gehalten wird. Wenn dies im Extremfall dann doch nicht hilft, gibt es als neuere Entwicklung sogenannte Journaling-Dateisysteme, die in einem zusätzlichen Bereich des Speichermediums Buch über jeden Arbeitsschritt führen, so dass im Nachhinein rekonstruiert werden kann, was noch erledigt werden konnte und was nicht mehr.
Eigene Gesichtspunkte gibt es bei Flash-Speichern, indem diese beim Löschen und Wiederbeschreiben einem Verschleiß ausgesetzt sind, der je nach Typ nur ca. 100.000 bis 1.000.000 Schreibzyklen zulässt. Dabei können in der Regel nicht einzelne Bytes für sich gelöscht werden, sondern meist nur ganze Blöcke (von je nach Modell variierender Größe) auf einmal. Das Dateisystem kann hier daraufhin optimiert werden, dass es die Schreibvorgänge möglichst gleichmäßig über den gesamten Speicherbereich des Flash-Bausteins verteilt und beispielsweise nicht einfach immer bei Adresse 0 anfängt zu schreiben. Stichwort: Wear-Leveling-Algorithmen, siehe bei Solid State Drive.
Dem Aspekt der Datensicherheit gegenüber Ausspähung durch Unberechtigte dienen Dateisysteme, die alle Daten verschlüsseln können, ohne dass andere Schichten des Betriebssystems dafür Aufwand zu treiben bräuchten.
Eine weitere Gefahrenquelle für die Integrität der Daten besteht in Schreibaktionen, die von irgendwelcher Software unter Umgehung des Dateisystems direkt auf physische Adressen auf dem Speichermedium erfolgen. Bei älteren Betriebssystemen war das ohne weiteres möglich und führte zu entsprechend häufigen Datenverlusten. Neuere Betriebssysteme können diese tieferen Ebenen wesentlich effektiver vor unautorisiertem Zugriff schützen, so dass mit den Rechten eines Normalbenutzers gar kein direkter Zugriff auf physische Medienadressen mehr erlaubt ist. Wenn bestimmte Diagnose- oder Reparatur-Dienstprogramme (Tools) so einen Zugriff doch benötigen, müssen sie mit Administratorrechten ausgestattet sein.
Lebenszyklusaspekte
Bei der Migration von Dateibeständen, etwa auf Grund einer Systemablösung, müssen häufig Dateien von einem Dateisystem auf ein anderes übernommen werden. Das ist im Allgemeinen ein schwieriges Unterfangen, denn viele Dateisysteme sind untereinander funktional nicht kompatibel, d. h. das Zieldateisystem kann nicht alle Dateien mit allen Attributen aufnehmen, die auf dem Quelldateisystem gespeichert sind. Ein Beispiel hierfür wäre die Migration von NTFS-Dateien mit Alternate Data Streams auf ein Dateisystem ohne Unterstützung für solche Streams. Unter diesem Aspekt ist das heutige Angebot an Dateisystemen erstaunlich stark fragmentiert. Es gibt nach wie vor keine allgemein akzeptierte und von allen Systemen unterstützte gemeinsame Auffassung dessen, was eine Datei ist.
Siehe auch
Einzelnachweise
Weblinks
 Commons: File systems – Sammlung von Bildern, Videos und Audiodateien
Commons: File systems – Sammlung von Bildern, Videos und Audiodateien

Wikimedia Foundation.