- Entscheidungsfunktion
-
Ein allgemeiner Test oder Entscheidungsverfahren ist ein abstraktes Instrument der mathematischen Statistik. Fast alle statistischen Tests, wie bspw. Hypothesentests oder Parameterpunktschätzungen, lassen sich in der Form eines allgemeinen Tests mathematisch erfassen. Ziel eines allgemeinen Tests ist es aufgrund der (beobachteten) Realisation einer oder mehrerer zuvor definierter Zufallsgrößen, deren genaue Wahrscheinlichkeitsverteilung i.d.R. nicht bekannt ist, bzgl. einer betrachteten Fragestellung eine Entscheidung zu treffen.
Inhaltsverzeichnis
Beispiel: Ein Pharmaunternehmen möchte ein neu entwickeltes Medikament auf seine (unbekannte) Wirksamkeit testen. Hierfür bekommt eine bestimmte Anzahl von Patienten das Medikament verabreicht. Aufgrund der gemessenen Wirkung des Medikaments auf die Patienten muss sich das Pharmaunternehmen nun entscheiden, ob man das neue Medikament auf dem Markt einführt oder lieber weiter auf ein alt bewährtes Medikament zurückgreift.Entscheidet sich das Pharmaunternehmen für die Markteinführung des neues Medikaments, so besteht die Gefahr, dass dieses durch das verwendete Entscheidungsverfahren nur fälschlicherweise als besser als das alte Medikament eingestuft wurde. In diesem Fall entstünde dem Pharmaunternehmen ein unnötiger Schaden. Um einen solchen zu vermeiden liegt jedem allgemeinen Test eine sog. Schadensfunktion zugrunde, mit Hilfe derer man versucht durch die Wahl einer "geeigneten" Entscheidungsfunktion das Risiko einer Entscheidung zu minimieren.
Definition
Gegeben sei ein Messraum
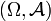 und eine Familie von Wahrscheinlichkeitsmaßen
und eine Familie von Wahrscheinlichkeitsmaßen 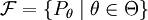 auf
auf 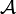 . Ω umfasst hierbei gerade alle möglichen Realisationen oder Beobachtungen. Weiter sei
. Ω umfasst hierbei gerade alle möglichen Realisationen oder Beobachtungen. Weiter sei 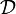 eine Menge von möglichen Entscheidungen.
eine Menge von möglichen Entscheidungen.- Eine Abbildung
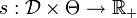 heißt Schadensfunktion.
heißt Schadensfunktion.
- Eine Abbildung
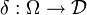 heißt genau dann allgemeiner Test, Entscheidungsfunktion oder auch Entscheidungsverfahren, wenn für jedes
heißt genau dann allgemeiner Test, Entscheidungsfunktion oder auch Entscheidungsverfahren, wenn für jedes 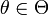 die Abbildung
die Abbildung 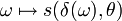 gerade
gerade 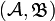 -messbar ist. Hierbei bezeichnet
-messbar ist. Hierbei bezeichnet 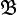 die Borelsche σ-Algebra über
die Borelsche σ-Algebra über 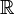 .
.
Gütekriterien
Risiko
Es sei
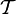 eine Klasse von Entscheidungsfunktionen. Für eine Element
eine Klasse von Entscheidungsfunktionen. Für eine Element 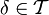 bezeichnet man
bezeichnet man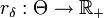 vermöge
vermöge 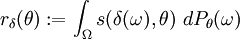
als Risikofunktion. Diese gibt an, welcher Schaden durch die Anwendung des Tests δ im Mittel unter der Verteilung Pθ entsteht. Wegen
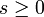 existiert diese immer, evtl. jedoch uneigentlich. Weiter bezeichnet man
existiert diese immer, evtl. jedoch uneigentlich. Weiter bezeichnet manals das Risiko von δ.
Hat man nun weiter eine σ-Algebra
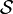 über Θ und ein Wahrscheinlichkeitsmaß μ auf
über Θ und ein Wahrscheinlichkeitsmaß μ auf 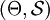 gegeben, so definiert μ eine a-priori-Verteilung oder (subjektive) Vorbewertung auf der Parametermenge. Ist die Risikofunktion
gegeben, so definiert μ eine a-priori-Verteilung oder (subjektive) Vorbewertung auf der Parametermenge. Ist die Risikofunktion 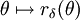 messbar bzgl. , so lässt sich hiermit das sog. Bayesrisiko des Tests δ bzgl. μ einführen, und zwar setzt man dann
messbar bzgl. , so lässt sich hiermit das sog. Bayesrisiko des Tests δ bzgl. μ einführen, und zwar setzt man dann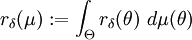 .
.
Effizienz
Mit Hilfe des Risikos und der Risikofunktion lassen sich nun zwei allgemeine Tests
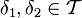 miteinander vergleichen. Man sagt δ1 ist mindestens so effizient wie δ2, wenn
miteinander vergleichen. Man sagt δ1 ist mindestens so effizient wie δ2, wenn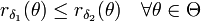 .
.
Im Falle einer Vorbewertung μ lassen sich die Tests außerdem mit Hilfe des Bayesrisikos vergleichen. Man sagt dann δ1 ist mindestens so effizient wie δ2, wenn
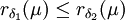 .
.Optimalität
Die Optimalität eines Tests lässt sich auf verschiedenste Weisen einführen. Man bezeichnet einen Test
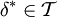 als
als- höchsteffizient in , wenn
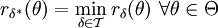 gilt.
gilt. - Minimaxverfahren in , wenn
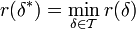 gilt.
gilt. - Bayeslösung in bzgl. μ, wenn
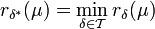 gilt.
gilt. - multisubjektiv optimal oder
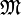 -Minimaxverfahren in , wenn eine Familie von Wahrscheinlichkeitsmaßen auf ist und gilt
-Minimaxverfahren in , wenn eine Familie von Wahrscheinlichkeitsmaßen auf ist und gilt 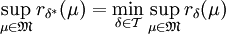 .
.
Bei festem Parameter θ ist
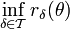 der unvermeidbare Schaden für jeden Test in . Für einen guten Test wird man deshalb verlangen, dass
der unvermeidbare Schaden für jeden Test in . Für einen guten Test wird man deshalb verlangen, dassmöglichst klein wird ("minimal regret"). Deshalb bezeichnet man δ * weiter als
- strengsten Test in , wenn
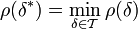 gilt.
gilt.
Zusammenhang: Bei den hier aufgeführten Optimalitätskriterien lässt sich die Höchsteffizienz als stärkste Forderung einstufen, denn ist ein Test δ * höchsteffizient in
, so ist er bereits Minimaxverfahren, Bayeslösung, multisubjektiv optimal und auch strengster Test.Beispiele
Hypothesentest
Bei einem Hypothesen- oder Signifikanztest betrachtet man zwei sich gegenseitig ausschließende Hypothesen H0 und H1, von denen man in der Regel eine, bspw. H0, versucht aufgrund einer Beobachtung
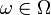 zu verwerfen. Die Menge der möglichen Entscheidungen ist deshalb von der Form
zu verwerfen. Die Menge der möglichen Entscheidungen ist deshalb von der Form 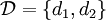 , wobei man definiert:
, wobei man definiert:- d1: = "Hypothese H0 kann verworfen werden."
- d2: = "Hypothese H0 kann nicht verworfen werden, es lässt sich also keine Folgerung aus dem Experiment ziehen."
Parameterpunktschätzung
Gegeben sei eine Zufallsgröße
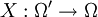 bzgl. zweier Messräume
bzgl. zweier Messräume 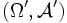 und , die der Verteilungsfamilie unterliegt. Unbekannt sei hierbei der "wahre" Parameter θ. Diesen, bzw. allgemeiner einen von θ abhängenden Wert λ(θ), gilt es zu schätzen. Als Entscheidungsraum betrachtet man deshalb
und , die der Verteilungsfamilie unterliegt. Unbekannt sei hierbei der "wahre" Parameter θ. Diesen, bzw. allgemeiner einen von θ abhängenden Wert λ(θ), gilt es zu schätzen. Als Entscheidungsraum betrachtet man deshalb 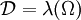 . Als Schadensfunktion verwendet man häufig
. Als Schadensfunktion verwendet man häufig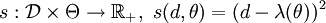 .
.
Damit ergibt sich für einen Test
als Risikofunktion die mittlere quadratische Abweichung der Schätzung von dem zu schätzenden Wert, denn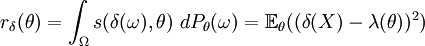 .
.
Parameterbereichsschätzung
Betrachtet wird wieder die Zufallsgröße X. Schätzen möchte man einen Bereich, in dem man den "wahren" Parameter θ vermutet. Man setzt hierfür
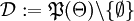 . Die Leere Menge schließt man als Entscheidung aus, da das Schätzen dieser nicht sinnvoll wäre. Als Schadensfunktion bietet sich die Abbildung mit
. Die Leere Menge schließt man als Entscheidung aus, da das Schätzen dieser nicht sinnvoll wäre. Als Schadensfunktion bietet sich die Abbildung mit 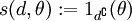 an. Mit ihr erhält man für einen Test die Risikofunktion
an. Mit ihr erhält man für einen Test die Risikofunktiond.h. rδ(θ) ist gerade die Wahrscheinlichkeit, mit welcher der Paramater θ nicht in der geschätzten Menge liegt. Man nennt rδ(θ) deshalb auch die Irrtumswahrscheinlichkeit des Verfahrens δ für den Parameter θ. Das Risiko
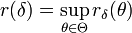 bezeichnet man als Signifikanzschranke von δ.
bezeichnet man als Signifikanzschranke von δ. - Eine Abbildung
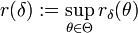
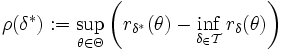
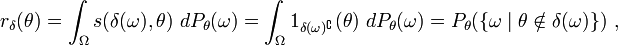
Wikimedia Foundation.