- Datenflussgraph
-
Eine Datenfluss-Architektur ist eine alternative Rechnerarchitektur zur sog. von-Neumann-Architektur, nach der die allermeisten heute gängigen Rechner implementiert sind. Ein nach der Datenfluss-Architektur implementierter Rechner heißt Datenflussrechner. Datenflussrechner versuchen, die Möglichkeiten der Parallelverarbeitung ihrer Rechenaufträge durch das nebenläufige Ausführen einer Vielzahl von Threads auszunutzen. Implementierungen dieser Architektur waren experimentelle Multiprozessorrechner, einen kommerziellen Erfolg konnten Rechner dieser Art nicht verbuchen. Nachteilige Eigenschaften der Datenfluss-Architektur veranlassten die Entwicklung hybrider Rechner, welche die Vorteile sowohl der Datenfluss-Architektur als auch der von-Neumann-Architektur vereinten; viele Konzepte, die typisch für die Datenfluss-Architektur sind, „überlebten“ auf diese Weise und sind aufgrund dieser Entwicklung in den allermeisten heutigen Rechnern wiederzufinden.
Motivation für die Entwicklung der Datenfluss-Architektur
Ein von-Neumann-Rechner arbeitet einen sequenziellen Prozess in einem linearen Adressraum ab; der Grad an Nebenläufigkeit, der dabei ausgenutzt werden kann, ist ziemlich gering. Im Unterschied dazu verarbeitet ein Datenflussrechner im Allgemeinen mehrere Threads von Maschinenbefehlen, die einen sog. Datenflussgraphen beschreiben, die in der Regel einen hohen Grad an Nebenläufigkeit besitzen.
Multiprozessorsysteme im von-Neumann-Kontext bringen zwei zentrale Probleme mit sich: Die Latenzzeit beim Speicherzugriff, also die Zeit die vergeht zwischen einer Speicheranfrage und der Antwort des Speichersystems, und das Problem der Synchronisation; damit ist die Notwendigkeit des ordnungserhaltenden Ausführens der Maschineninstruktionen gemäß der Datenabhängigkeiten gemeint. Als Alternative wurde das Datenfluss-Modell entwickelt; Rechner, die es implementieren sollten nach der Vorstellung ihrer Entwickler eher imstande sein, mit den genannten Problemen umzugehen [1] .
Unterschiede zur von-Neumann-Architektur
Das Prinzip des Datenflusses wurde in den frühen 1970er Jahren von Jack Dennis und James Rumbaugh entwickelt. Der früheste Architekturentwurf stammt von 1975[2]. Ein Datenflussrechner kommt ohne zwei zentrale Merkmale der von-Neumann-Architekturen aus: er bedarf keines Programmzählers und keines zentralen Speichers, der fortlaufend aktualisiert wird und zu einem Flaschenhals beim Ausnutzen von Parallelität wurde[1]; im Gegensatz zur von-Neumann-Architektur werden berechnete Ergebnisse, die Inputwerte für weitere Berechnungen sind, nicht zwischengespeichert, sondern existieren lediglich als temporäre „Nachrichten“ zwischen den Ausführungseinheiten.
Alle Mikroprozessoren, die nach dem gängigen von-Neumann-Prinzip arbeiten, folgen einem streng sequenziellen Verarbeitungsmodell. Die Befehlsabfolge folgt dem von-Neumann-Zyklus, das heißt, nach dem Laden der gegenwärtigen Instruktion wird implizit die Adresse der nachfolgenden Instruktion angesteuert, diese wird geladen und ausgeführt. Das Laden des entsprechenden Befehls erfolgt unter der Kontrolle eines Programmzählers, was das reihenfolgeerhaltende Laden der einzelnen Maschinenbefehle impliziert.
Zwar zielt auch das dynamische Scheduling superskalarer Prozessoren, welches alle modernen Prozessoren der von-Neumann-Rechner implementieren, auf das Ausführen der Maschinenbefehle in Datenflussreihenfolge ab. Dabei wird der sequenziell gelesene Befehlsstrom zeitweise während des Bearbeitens in der Pipeline semantikerhaltend umgeordnet. Das Ergebnis der Bearbeitung des Befehlsstromes muss letztendlich jedoch dem sequenziellen Abarbeiten des Befehlsstroms äquivalent sein.
Die Maschineninstruktionen werden beim von-Neumann-Prinzip stets reihefolgeerhaltend geladen und das Speichern der Ergebnisse in den Registern nach Beendigung des jeweiligen Befehls muss reihenfolgeerhaltendend vorgenommen werden; so kann beispielsweise das Ergebnis des auf einen Sprungbefehl folgenden Befehls erst gespeichert werden, wenn die Sprungbedingung ausgewertet wurde und klar ist, ob der entsprechende Befehl überhaupt hätte ausgeführt werden sollen; die Berechnung des besagten Ergebnisses kann dagegen durchaus vor dem Auswerten der Sprungbedingung erfolgen. Das von-Neumann-Prinzip erfordert also die Abarbeitung der Maschineninstruktionen unter Berücksichtigung von Kontrollflussabhängigkeiten.
Die Abarbeitung des Programms eines Datenflussrechners wird von Datenabhängigkeiten bestimmt; das heißt, der Kontrollfluss ist hier mit dem Datenfluss der einzelnen Instruktionen identisch. Das bedeutet, jede Maschineninstruktion kann geladen, ausgeführt und das Ergebnis der Berechnung gespeichert werden, sobald ihre Operanden vorliegen; das zugrunde liegende Modell ist damit inhärent asynchron. Das Konzept bringt es mit sich, dass es einige Herausforderungen der von-Neumann-Architektur, wie die Sprungvorhersage - bei den verarbeiteten Datenflussgraphen gibt es keine Sprünge - und das reihenfolgeerhaltende Ausführen von Lade- und Speicherbefehle des abzuarbeitenden Programmes hier nicht gibt.
Compiler im von-Neumann-Kontext analysieren ihren Quellcode in bezug auf Datenabhängigkeiten, um die Instruktionen im erzeugten Bytecode in sequenzieller Reihenfolge richtig anordnen zu können. Welche Datenabhängigkeiten der Compiler konkret ermittelt hat, wird im Bytecode jedoch nicht vermerkt. Ein Datenflusscompiler hingegen vermerkt in dessen Binärcode ermittelte Datenabhängigkeiten. Jede Abhängigkeit wird zur Unterscheidung von den übrigen mit einer eindeutigen Markierung versehen, dies ermöglicht der ausführenden Datenflussmaschine das nebenläufige Abarbeiten unterschiedlich markierter Code-Segmente.
Datenflussrechner
Grundlagen
Datenflusssprachen
Zum Schreiben der abzuarbeitenden Programme für einen Datenflussrechner bedarf es einer Programmiersprache, deren kompiliertes Maschinenprogramm zur seiner Abarbeitung nicht eines Programmzählers bedarf und mit der man sehr einfach nebenläufige Vorgänge beschreiben kann.
Einige Beispiele für solche Sprachen sind:
- Id (Irvine data flow language)
- Lucid
- Lustre
- SISAL
Datenfluss-Programmiersprachen sind deklarativ; sie sind mit funktionalen Programmiersprachen verwandt, ihre Programme sind nichts anderes als Funktionen, die Eingabewerte auf Ausgabewerte abbilden. Beide befolgen das so genannte Einmalzuweisungsprinzip: Einer Variablen kann nicht in der gleichen Funktion mehrmals nacheinander ein Wert zugewiesen werden, was der eigentlichen mathematischen Bedeutung einer Variablen gerecht wird.
Datenflussgraphen
Programme, die in einer Datenfluss-Programmiersprache geschrieben sind, können mithilfe eines sog. Datenflussgraphen modelliert bzw. mithilfe eines Compilers in Maschineninstruktionen übersetzt werden, die einen solchen beschreiben. Datenflussgraphen beschreiben in der Regel nebenläufige Prozesse, die von einem Datenflussrechner mehrfädig berechnet werden können.
Ein Datenflussgraph ist ein gerichteter Graph, dessen Knoten Instruktionen darstellen; die Kanten zwischen den Knoten beschreiben die zugrunde liegenden Datenabhängigkeiten; Inputwerte für die Instruktionen werden in Form von Datenpaketen, genannt Tokens, auf den Kanten entlang propagiert. Zwei zentrale Charakteristika eines Datenflussgraphen sind Funktionalität, das heißt, die Auswertung des Graphen ist dem Auswerten einer mathematischen Funktion äquivalent, und die Kompositionseigenschaft, das heißt Graphen können beliebig kombiniert werden und damit einen neuen Graphen bilden.
Die Abarbeitung des Datenflussgraphen wird vermöge der gerichteten Kanten von Datenabhängigkeiten kontrolliert. Wenn genügend Tokens auf den Eingangskanten eines Knotens vorhanden sind, kann dieser feuern, das heißt, einige der Tokens auf den Eingangskanten werden konsumiert und neue Tokens auf den Ausgangskanten produziert, was es nachfolgenden Knoten ermöglichen kann, zu feuern.
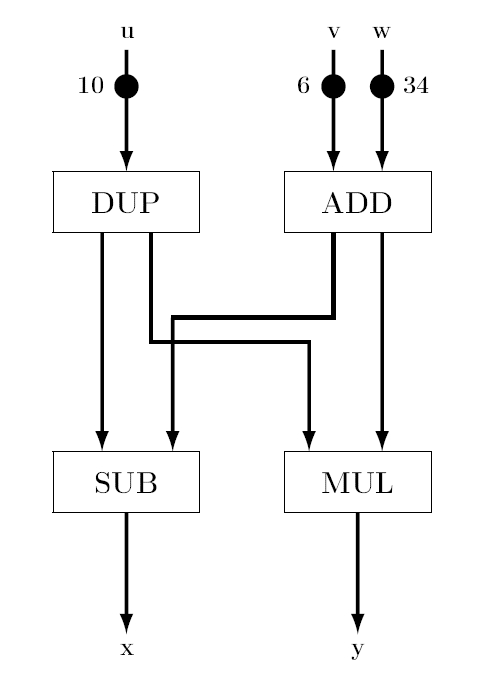
 Einfacher Datenflussgraph
Einfacher DatenflussgraphDer Datenflussgraph zur Rechten entspricht dem Programm:
Input: u, v, w; x = u - (v + w); y = u * (v + w); Output: x, y;Dies ist kein sequenzielles Programm. Beim Abarbeiten des Graphen wandern die mit Werten markierten Tokens durch den Graphen; die Funktion des Knotens DUP ist es, das Token auf der Eingangskante auf beide Ausgangskanten zu duplizieren. Zu Beginn könnten die Knoten ADD und DUP feuern, entweder ein Knoten nach dem anderen oder beide gleichzeitig; das Feuern geht hier in Form einer asynchronen Nebenläufigkeit vonstatten. Wenn beide Knoten gefeuert haben, sind ihre beiden Nachfolgeknoten MUL und SUB imstande, zu feuern. Die Ausführungsreihenfolge beeinflusst eventuell die Laufzeit beim Abarbeiten, hat aber keinen Einfluss auf das Ergebnis. Die Abarbeitung des Programms ist also deterministisch.
Konzeptuell verschiedene Datenflussgraphen sind denkbar. Solche Graphen unterscheiden sich in ihrem Verhalten und ihrer Ausdrucksmächtigkeit. Im Folgenden sind einige architektonische Variationen der Datenflussrechner geführt, die den zeitlichen Ablauf ihrer Entwicklung widerspiegelt und denen zum Teil verschiedene Typen eines Datenflussgraphen zugrunde liegen.
Statische Datenflussrechner
Die Architektur, die Graphen mit einem Knoten pro Kante verarbeitet, eine statische Architektur, wurde im Wesentlichen von Jack Dennis entwickelt. Hauptvorteil dieses Modells ist die Tatsache, dass es recht einfach ist, Knoten zu ermitteln, die imstande sind, zu feuern. Ein unerwünschter Effekt dieses Modells besteht darin, dass aufeinanderfolgende Iterationen einer Schleife nur teilweise überlappen können und der Grad der Nebenläufigkeit, der erreicht werden kann, auf diese Weise gemindert wird. Ein weiterer Nachteil des Modells ist das Fehlen von unterstützenden Programmierkonstrukten bei modernen Programmiersprachen[1]. Dennoch wurden einige Rechner dieser Architektur gebaut, die die Grundlage für nachfolgende Generationen von Datenflussrechnern bildeten; im Folgenden sind einige Beispiele gelistet:
- MIT Static Dataflow Architecture (Massachusetts Institute of Technology)
- NEC Image Pipelined Processor (NEC Electronics)
- Hughes Dataflow Multiprocessor (Hughes Aircraft)
Dynamische Datenflussrechner
Die Leistung eines Datenflussrechners kann bedeutend gesteigert werden, wenn Schleifendurchläufe und Unterprogrammaufrufe parallel verarbeitet werden können. Um dies zu erreichen, sollte jeder Schleifendurchlauf und jeder Unterprogrammaufruf imstande sein, eine separate eintrittsinvariante Instanz des korrespondierenden Teilgraphen auszuführen. Da diese Replikation eines solchen Teilgraphen in der Praxis sehr aufwändig ist, wird tatsächlich nur eine Instanz des Graphen im Speicher gehalten; deshalb muss jedes Token mit einem Tag versehen, der den Prozesskontext identifiziert. Die Regel zum Feuern wird für die Knoten dahingehend geändert, dass der Knoten genau dann feuert, wenn hinreichend viele Tokens mit identischen Tags auf den Inputkanten verfügbar sind. Datenfluss-Architekturen, die diese Methode implementieren, heißen auch dynamische Datenfluss-Architekturen. Die ersten Experimente mit dem dynamischen Datenflussprinzip wurden Ende der 1970er unternommen[2].
Der Vorteil dieser Architektur ist eine gesteigerte Performance aufgrund dessen, dass nun mehrere Tokens auf den Kanten propagiert werden können. Ein Problem dieser Architektur ist das effiziente Synchronisieren zweier Operationen. Dies wirft das so genannte Token-Matching-Problem auf, bei dem es festzustellen gilt, ob zwei Token dasselbe Tag tragen, also zum selben Prozesskontext gehören. Diese Vergleichsoperation erfordert einen assoziativen Speicherzugriff. Da Assoziativspeicher sehr teuer waren, wurde in der Regel ein in Hardware implementiertes Hash-Verfahren angewandt, das sich in vielerlei Hinsicht als ineffektiv erwies[2]. Im Folgenden sind einige Beispiele für Implementierungen dieser Architektur gelistet:
- Manchester Dataflow Computer (Universität Manchester)
- MIT Tagged-Token Dataflow Machine (Massachusetts Institute of Technology)
- PATTSY – Processor Array Tagged-Token System (Universität von Queensland)
Dynamische Datenflussrechner mit explizitem Token-Speicher
Um das Token-Matching-Problem zu lösen und keines teuren assoziativen Speichers zu bedürfen, wurde das Konzept des expliziten Token-Speichers entwickelt. Grundidee dabei ist es, bei einer Schleifeniteration dynamisch einen so genannten „Aktivierungsrahmen“ im Token-Speicher bereitzustellen, der eine Speicherstelle für dasjenige Token bietet, welches zuerst bei der Vergleichseinheit ankommt. Die Adresse der Speicherstelle kann durch den Compiler errechnet werden. Trifft das zweite Token bei der Vergleichseinheit ein, wird das erste Token wieder aus dem Speicher gelesen und der Vergleich vorgenommen, so dass bei dieser Technik nur zwei Speicherzugriffe notwendig sind, anstatt einen Teil des Tokenspeicher nach einem passenden Token durchsuchen zu müssen, wie zuvor. Allerdings wird die Anzahl der gleichzeitig ausführbaren Schleifen- und Unterprogramminstanzen durch dieses Vorgehen beschränkt[1]. Experimente mit dieser Architektur wurden Ende der 1980er unternommen[2]; ein Beispiel für eine Implementierung ist:
- Monsoon (Massachusetts Institute of Technology in Zusammenarbeit mit Motorola)
Vor- und Nachteile von Datenflussrechnern
Vorteile
- Ein Datenflussrechner kann viele Threads auf einem oder mehreren Prozessoren ausführen; seine Performance steigt dabei beinahe linear mit der Anzahl seiner Prozessoren
- Programmierer müssen sich weniger um explizite Nebenläufigkeit beim Programmieren kümmern; Datenflussrechner nutzen implizite Nebenläufigkeit aus, die zur Übersetzungszeit vom Compiler entdeckt wird
- Lange Zeit waren Datenflussrechner solchen der von-Neumann-Architektur in puncto Speicherlatenz und Synchronisation überlegen
Nachteile
- Kein Nutzen von Registern - statt dessen Result-Forwarding: Weil die zeitliche Abfolge, in der die einzelnen Befehle des Datenflussprogramms ausgeführt werden, nicht im Voraus festgelegt ist, können Register als Zwischenspeicher für Operanden nicht genutzt werden.
- Schlechtes Ausnutzen von Caches: Die in der von-Neumann-Architektur genutzte Referenzlokalität beim Zugriff auf Daten- und Instruktionscaches, die aufgrund des sequenziellen Verarbeitungsmodells sehr stark ausgeprägt ist, ist in der Datenfluss-Architektur kaum vorhanden, bestimmt aber maßgeblich die Leistungsfähigkeit eines Caches. Highspeed-Prozessoren benötigen Caches, um ihre Ausführungseinheiten auslasten zu können.
- Leistungseinbußen aufgrund von Duplikationsoperationen
- Schlechte Performance beim Verarbeiten eines einzelnen Threads: Beim Verarbeiten eines einzelnen Threads müssen Operationstupel warten, bis die Vorgängeroperation beendet wurde. Ein Datenflussrechner hat seine Stärke beim Ausführen vieler Threads, um mit vielen unabhängigen Operationen seine Pipelines füllen und auslasten zu können
- Relativ breite Maschineninstruktionen: Die Breite der Maschineninstruktionen des Monsoon-Datenflussrechners betrug beispielsweise 144 Bit
- Overhead aufgrund des Token-Matching-Problems
Motivation für Multithreading
Datenflussrechner haben eine schlechte Performance, wenn sie einen einzelnen sequenziellen Thread ausführen. Die jeweiligen Ergebnisse eines Operationstupels werden in der letzten Stufe der Pipeline berechnet und Datenkonflikte würden dazu führen, dass nur jeweils eine Instruktion in der Pipeline verarbeitet wird, so dass die Pipeline offensichtlich keinen Nutzen bringt. Datenflussprogramme bestehen jedoch im Allgemeinen aus vielen nebenläufigen Threads, so dass es möglich ist, die Pipeline fortlaufend mit datenunabhängigen Instruktionen zu füllen, die zu verschiedenen Prozesskontexten gehören, so dass keine Pipelinekonflikte entstehen und die Pipeline voll ausgelastet werden kann. Insbesondere ist es so auch möglich, lange Latenzzeiten zu überbrücken, die beispielsweise Lade- und Speicheroperationen verursachen; in der Zwischenzeit werden einfach datenunabhängige Instruktionen anderer Threads in die Pipeline gespeist. Dem Multithreading heutiger Prozessoren, oder Hyperthreading bei Intels Pentium, liegt dasselbe Prinzip zugrunde.
Hybride Architekturen
Datenflussrechner wurden vor allem in den 1980er Jahren gebaut, erwiesen sich aber mit von-Neumann-Supercomputern aufgrund des Flaschenhalses beim Speicherzugriff als nicht wettbewerbsfähig. Die Nachteile, welche die Datenfluss-Architektur mit sich bringt, führten zur Entwicklung hybrider Architekturen, welche die Vorteile sowohl der Datenfluss-Architektur als auch der von-Neumann-Architektur nutzen. Beide Architekturen dürfen aber nicht als orthogonale Rechner-Paradigmen gesehen werden[1]. Das Spektrum solcher Hybride ist relativ breit; es reicht von einer einfachen Erweiterung des von-Neumann-Prozessors mit einigen wenigen zusätzlichen Instruktionen bis zu spezialisierten Datenflusssystemen, die sich einer Vielzahl von Techniken bedienen, die für von-Neumann-Rechner entwickelt wurden.
Einige wichtige Konzepte von Datenflussrechnern „überlebten“ aufgrund dieser „Konvergenz“ und sind in den allermeisten heutigen Prozessoren zu finden, so das dem Datenflussprinzip entsprechende nicht-reihefolgeerhaltende Ausführen der Maschinenbefehle beim dynamischen Scheduling superskalarer Prozessoren und das Multithreading.
Siehe auch
Einzelnachweise
- ↑ a b c d e J. Silic, B. Robic und T. Ungerer: Asynchrony in parallel computing: From data flow to multithreading. Technical report CSD, Computer Systems Department, Josef Stefan Institute, Ljubljana, Slowenien, 1997
- ↑ a b c d Theo Ungerer: Datenflußrechner. Teubner-Verlag 1993
Literatur
- Arvind und R. Nikhil: Executing a program on the MIT tagged-token dataflow architecture IEEE Transaction on computers, 1990
- G. Papadopoulos und D. Culler: Monsoon: an explicit token-store architecture. International Symposium on Computer Architecture (ISCA), 1990 (Beschreibt die Architektur des Monsoon-Datenflussrechners)
- J. Silic, B. Robic und T. Ungerer: Asynchrony in parallel computing: From data flow to multithreading. Technical report CSD, Computer Systems Department, Josef Stefan Institute, Ljubljana, Slowenien, 1997 (Listet alle bedeutenden Datenflussrechner, beschreibt deren historische Entwicklung und erklärt, warum heutige multithreadingfähige Prozessoren Abkömmlinge der Datenflussrechner sind)
- J. Rumbaugh: A Parallel Asynchronous Computer Architecture For Data Flow Programs, MIT-LCS-TR-150, 1975 (die Dissertation von J. Rumbaugh)
Wikimedia Foundation.