- Funktionale Programmiersprache
-
Funktionale Programmierung ist ein Programmierparadigma. Programme bestehen hier ausschließlich aus einer Vielzahl von Funktionen, daher der Name.
Das Hauptprogramm ist eine Funktion, welche die Eingabedaten als Argument erhält und die Ausgabedaten als seinen Wert zurückliefert. Diese Hauptfunktion verwendet in ihrer Definition üblicherweise weitere Funktionen, die wiederum ihrerseits weitere Funktionen verwenden, und das geht so weiter, bis irgendwann, am Boden der Aufrufhierarchie ankommend, nur noch die Grundfunktionen der Programmiersprache verwendet werden, z. B. Addition, Konkatenation etc.
Die Benutzung von Funktionen in der funktionalen Programmierung unterscheidet sich von der in imperativen Sprachen dadurch, dass die Reihenfolge der Berechnungen nicht angegeben werden muss. Das Programm beschreibt lediglich Abhängigkeiten von Daten.
Eine funktionale Programmiersprache ist eine Programmiersprache, die Sprachelemente zur Kombination und Transformation von Funktionen anbietet. Eine rein funktionale Programmiersprache ist eine Programmiersprache, die die Verwendung von Elementen ausschließt, die im Widerspruch zum funktionalen Programmierparadigma stehen. Einige Autoren verwenden den Ausdruck „funktionale Programmiersprache“ gleichbedeutend mit „rein funktionale Programmiersprache“.
Funktionen in Mathematik und Informatik
Der Begriff der Funktion wird in Informatik und Mathematik mit unterschiedlicher Bedeutung verwendet (vergleiche Funktion (Programmierung) und Funktion (Mathematik)). In der Mathematik wird eine Funktion als eine Abbildung der Funktionsargumente auf das jeweilige Funktionsergebnis betrachtet, so dass eine Funktion im mathematischen Sinne bei jeder Verwendung mit denselben Funktionsargumenten dasselbe Ergebnis liefert. Demgegenüber wird in der Informatik Funktion häufig als gleichbedeutend mit Unterprogramm verwendet. Anders als in der Mathematik brauchen in der Informatik Funktionen im allgemeinen Sprachgebrauch weder werttreu noch frei von einer Wirkung (auch als Seiteneffekt bezeichnet) zu sein: Erstens kann das Ergebnis eines Aufrufs neben den beim Aufruf übergebenen Funktionsparametern auch von der Vorgeschichte der Funktionsaufrufe oder allgemeiner vom augenblicklichen Zustand des umgebenden Computerprogramms abhängen, und zweitens kann der Funktionsaufruf selbst Auswirkungen auf das zukünftige Verhalten anderer Funktionen haben.
Die Funktionen funktionaler Programmiersprachen verhalten sich hingegen wie mathematische Funktionen. Dies wird unter anderem erreicht, indem eine Zuweisung der Form
x = x + 1
ausgeschlossen wird.
Mathematisch gelesen ergibt diese Zeile auch wenig Sinn, denn das wäre eine Gleichung und es käme
heraus, was unwahr ist. Gemeint ist diese Zuweisung als
- x: = x + 1,
wobei das x auf der linken Seite ein anderes x ist, als das auf der rechten Seite. Das ist zwar für die Programmierung nützlich, entspricht aber nicht dem Verhalten von Variablen in der Mathematik, wo eine Variable x, wenn sie einen Wert zugewiesen bekommen hat, genau diesen Wert immer behält und nicht mal den einen und mal den anderen Wert im Verlauf einer Rechnung annimmt (referenzielle Transparenz).
Ein Ansatz der funktionalen Programmierung ist, dass ihre Funktionen sich mehr wie mathematische Funktionen verhalten, damit die Rechen- und Beweismethoden der Mathematik besser auf Programme angewendet werden können (um vor allem ihre Korrektheit zu beweisen).
Sie vertritt weiter die Auffassung, dass Funktionen ein geeignetes Mittel zur Modularisierung von Programmen darstellen, indem die Hauptfunktionen aus einer Vielzahl anderer Funktionen zusammengesetzt (komponiert) werden. Hierfür bieten funktionale Programmiersprachen verstärkte Unterstützung, z. B. verhalten sich Funktionen weitestgehend wie andere Datentypen, können als Argumente und Rückgabewerte verwendet werden (Funktionen höherer Ordnung).
Der Programmierer legt fest, wie die Funktionen zusammengesetzt sind, es gibt jedoch noch Freiheiten in der Auswertung, die von Übersetzern zu Optimierungszwecken genutzt werden können.
Abgrenzung von imperativer Programmierung
Im Gegensatz zu imperativen Programmen, die aus Rechenanweisungen bestehen, sind funktionale Programme eine Menge von (Funktions)-Definitionen, die man mathematisch als partielle Abbildungen von Eingabedaten auf Ausgabedaten auffassen kann.
Ein typisches Beispiel ist die Berechnung der Fakultät n! einer Zahl n (n! = 1 ∙ 2 ∙ 3 ∙ ... ∙ n), hier eine imperative Lösung:
- Eingabe
- Zahl n
- Ausgabe
- Zahl b (=1 ∙ 2 ∙ 3 ∙ ... ∙ n)
- Algorithmus
- b := 1 (Zuweisung)
- solange n ≠ 0 führe aus:
-
- b := n ∙ b
- n := n − 1
-
- Ausgabe: b
Charakteristisch für die imperative Programmierung sind hier die Zuweisungen (Änderung von Werten, durch das Symbol „:=“ im Pseudocode repräsentiert). Zwar berechnet der Algorithmus die Fakultät der Zahl n, aber die Korrektheit dieses Rechenweges ist nicht offensichtlich.
Nun kann man die Fakultät jedoch auch mithilfe von rekursiven Funktionen definieren, was zur funktionalen Lösung führt.
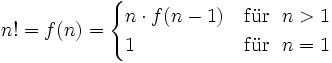
- Funktion f(n)
- wenn n > 1 dann:
- Ausgabe: n∙f(n-1)
- sonst wenn n = 1 dann:
- Ausgabe: 1
Die funktionale Programmierung kommt also ohne Schleifen und Zuweisungen aus, benötigt dafür aber Rekursion.
Mächtigkeit funktionaler Sprachen
Die Mächtigkeit einer Programmiersprache ist definiert durch die Menge an Problemen, die in dieser Programmiersprache entscheidbar sind. Die theoretische Informatik hat gezeigt, dass eine reine funktionale Programmiersprache mit Rekursion gleich mächtig ist wie eine imperative Programmiersprache, die Schleifen und Zuweisungen erlaubt (siehe Turing-Vollständigkeit). Dies zeigt, dass das Einhalten des funktionalen Paradigmas keinerlei Einschränkungen mit sich bringt, auch wenn dies auf den ersten Blick so scheinen mag.
Theoretische Grundlagen
Als theoretische Grundlage dient der λ-Kalkül (Lambda-Kalkül) von Alonzo Church. Jeder Ausdruck wird dabei als auswertbare Funktion betrachtet, so dass Funktionen als Parameter übergeben werden können.
Der Lambda-Kalkül erlaubt es, vollständige Teilausdrücke separat auszuwerten. Dies ist der wichtigste Vorteil gegenüber der imperativen Programmierung. Dieses Konzept vereinfacht die Programmverifikation und Programmoptimierung, beispielsweise die Überführung der Programme in eine parallel auswertbare Form.
Typsystem
Historisch ist LISP als die erste funktionale Programmiersprache aufzufassen; Sprachen der LISP-Familie (wie auch Scheme) sind dynamisch typisiert. Seit der Entwicklung von Standard-ML (SML) konzentriert sich die Forschung auf dem Gebiet der funktionalen Programmiersprachen jedoch auf statisch typisierte Sprachen, insbesondere auf solche, die das Typsystem nach Hindley und Milner verwenden. Der Vorteil dieses Typsystems ist die Verfügbarkeit von parametrischem Polymorphismus zusammen mit Typinferenz: Programmierer müssen die Typen ihrer Funktionen und anderen Werte nicht angeben, sondern bekommen sie gratis vom Übersetzer ausgerechnet, der zugleich noch während der Übersetzung Typfehler monieren kann. Dies wird allgemein als wesentlicher Vorteil gegenüber dynamisch typisierten Sprachen (LISP, Python) aufgefasst, die zwar ebenfalls keine Typennotationen benötigen (im Gegensatz z. B. zu Java oder C), dafür aber Typfehler, wenn überhaupt, erst zur Laufzeit anmahnen können.
Das Hindley-Milner-System erlaubt allerdings nur Polymorphismus ersten Ranges; Erweiterungen für Polymorphismus zweiten und allgemein k-ten Ranges sind inzwischen in dem Haskell-Übersetzer GHC als Erweiterungen verfügbar, bedingen jedoch wieder explizite Annotationen (Typinferenz ab Polymorphismus zweiten Ranges ist unentscheidbar).
Rein funktionale Programmiersprachen
Rein (engl. purely) funktionale Programmiersprachen fassen Programme als mathematische Funktion auf: Ein Ausdruck hat dort während der Programmausführung immer den gleichen Wert. Es gibt keine Zustandsvariablen, die während einer Berechnung geändert werden. Um erwünschte Wirkungen (Benutzerinteraktion, Eingabe/Ausgabe-Operationen) beschreiben zu können, sind meist besondere Vorkehrungen notwendig. Die meisten funktionalen Programmiersprachen (Standard ML, Caml) erlauben allerdings solche Wirkungen und sind daher keine reinen funktionalen Programmiersprachen.
Um Programmierung auch mit Wirkungen zu erlauben, ohne dabei zu einer unreinen (engl. impure) Sprache zu werden, wurde bei der Entwicklung der Sprache Haskell das aus der Kategorientheorie stammende Konzept der Monaden entwickelt (insbesondere von Eugenio Moggi und Philip Wadler), welches Wirkbehaftung durch parametrische Typen ausdrückt und somit das Typsystem dazu zwingt, zwischen Ausdrücken mit und Ausdrücken ohne Wirkungen zu unterscheiden. Auch in Clean und Mercury (Programmiersprache) wird das Typsystem verwendet, um solche Wirkungen zu kennzeichnen. Dort benutzt man allerdings das Konzept der "Uniqueness"-Typen.
Funktionen höherer Ordnung
Man unterscheidet Funktionen erster Ordnung und Funktionen höherer Ordnung. Bei Funktionen höherer Ordnung sind Funktionen selbst Werte. Dies erlaubt es insbesondere, Funktionen als Ergebnisse oder Argumente anderer Funktionen zu verwenden. Ein typisches Beispiel ist der Ableitungsoperator: Eingabe ist eine differenzierbare Funktion, Ausgabe ist die Ableitung dieser Funktion. Ein weiteres Standardbeispiel ist die Funktion
map, welche als Eingabe eine Funktionfund eine Listelerhält und die modifizierte Liste zurückgibt, die dadurch entsteht, dass die Funktionfauf jedes Element der Listelangewendet wird. Definition vonmapin Haskell:map f [] = [] map f (x:xs) = f x : map f xs
- In der ersten Zeile wird das Ergebnis für eine leere Liste [] zurückgegeben; die zweite Zeile wendet die Funktion
fauf das erste Listenelement x an und führt dann einen Rekursionsschritt für die restliche Liste xs durch.
Bedarfsauswertung und strenge Auswertung
Funktionale Sprachen kann man auch nach ihrer Auswertungsstrategie unterscheiden: Bei strenger Auswertung (engl. eager bzw. strict evaluation) werden die Argumente von Funktionen zuerst ausgewertet. Dagegen werden bei der nicht-strikten Auswertung zunächst die Ausdrücke als Ganzes übergeben und dann ausgewertet.
Man könnte zum Beispiel (3 + 5)2 auf zwei Arten berechnen, wobei die Gleichung im ersten Fall strikt ausgewertet wird, da erst die Argumente der Potenz-Funktion berechnet werden. Im zweiten Fall werden diese Argumente erst bei Bedarf ausgewertet, also nachdem die Potenzfunktion aufgelöst wurde:
Eine Variante der nicht-strikten Auswertung ist die Bedarfsauswertung (engl. lazy evaluation), bei der Ausdrücke erst ausgewertet werden, wenn deren Wert in einer Berechnung benötigt wird. Dadurch lassen sich z. B. unendlich große Datenstrukturen (die Liste aller natürlicher Zahlen, die Liste aller Primzahlen, etc.) definieren, und bestimmte Algorithmen vereinfachen sich.
Manche Berechnungen lassen sich mit strenger Auswertung, andere mit Bedarfsauswertung effizienter ausführen. Terminiert die strenge Auswertung eines Ausdruckes, so terminiert auch die nicht-strikte Auswertung. Hintergrund hiervon ist die Konfluenz-Eigenschaft des jeder funktionalen Sprache zugrundeliegenden λ-Kalküls, die aussagt, dass das Ergebnis der Berechnung nicht von der Reihenfolge der Auswertung abhängt.
Funktionale Algorithmen und Datenstrukturen
Algorithmen geben vorteilhafte Verfahren für die Lösung wichtiger Probleme an (z. B. Sortieren) und sind in der Regel gut analysiert, so dass ein Entwickler auf bewährte, einschätzbare Lösungen zurückgreifen kann. Gleiches leisten Datenstrukturen für die Organisation von Daten. Sammlungen von guten Algorithmen und Datenstrukturen haben somit eine große praktische Bedeutung.
Der Verzicht auf zerstörerische Zuweisungen führt dazu, dass etliche klassische Algorithmen und Datenstrukturen, die regen Gebrauch von dieser Möglichkeit machen, so nicht für funktionale Sprachen verwendet werden können und nach neuen Lösungen gesucht werden muss.
Chris Okasaki schreibt: „Auch wenn die meisten dieser Bücher [über Datenstrukturen] behaupten, dass sie unabhängig von einer bestimmten Programmiersprache sind, so sind sie leider nur sprachunabhängig im Sinne Henry Fords: Programmierer können jede Programmiersprache benutzen, solange sie imperativ ist.“
Gerade rein funktionale Datenstrukturen sind von ihrer Natur her anders als die gewohnten Datenstrukturen, die meist nur eine Version ihrer Daten verwalten (ephemere Datenstrukturen), wohingegen funktionale Datenstrukturen mehrere Versionen verwalten (persistente Datenstrukturen).
Beispiele
Folgende Programme definieren eine Funktion
ringarea, die die Fläche berechnet, die zwischen den beiden konzentrischen Kreisen mit den RadienRundrmit gemeinsamen Mittelpunkt liegt. Dazu werden die Konstantepiund die Hilfsfunktionsqdefiniert. Diese werden von ringarea dann für die Berechnung benutzt.Haskell
ringArea :: (Floating a) => a -> a -> a -- optionale explizite Typangabe ringArea r1 r2 = pi*(r1**2-r2**2)
Der Typ der Funktion
ringAreaist polymorph und wird durch die Angabe der TypklasseFloatingeingegrenzt. Die explizite Spezifikation des Typs ist optional und kann ebensogut durch den Haskell-Compiler inferenziert werden.SML
local val pi = 3.14 val sq = fn (x:real) => x*x in fun ringarea(R, r) = pi*(sq R - sq r) end
Der Typ von
xmuss hier explizit angegeben werden, da ein SML97-Übersetzer sonst den Typ int inferieren würde. Das zugrundeliegende Problem ist das der Überladung von Operatoren; dieses Problem wurde erst mit Einführung von Typklassen gelöst, allerdings in Haskell und verwandten Sprachen.Joy
DEFINE pi == 3.14; sq == dup *; ringarea == sq swap sq swap - pi *.
Man beachte, dass hier alle Variablen Funktionen bezeichnen (auch pi ist eine Funktion).
XSLT
Diese Programmiersprache dient dem Transformieren von XML (insbesondere in XHTML) und hat zusammen mit XML stark an Bedeutung gewonnen. Sie ist funktional, wie Dimitre Novatchev gezeigt hat.[1] Die im folgenden Beispiel[2] definierte Funktion kehrt die Reihenfolge der Wörter einer Zeichenkette um. Typisch für funktionale Programmiersprachen ist der rekursive Aufruf. Der zweite Absatz zeigt, wie die Funktion verwendet wird.
<xsl:function name="str:reverse" as="xs:string"> <xsl:param name="sentence" as="xs:string"/> <xsl:choose> <xsl:when test="contains($sentence, ' ')"> <xsl:sequence select="concat(str:reverse( substring-after($sentence, ' ')), ' ', substring-before($sentence, ' '))"/> </xsl:when> <xsl:otherwise> <xsl:sequence select="$sentence"/> </xsl:otherwise> </xsl:choose> </xsl:function> <xsl:template match="/"> <output> <xsl:value-of select="str:reverse('DOG BITES MAN')"/> </output> </xsl:template>Siehe auch
Literatur
- Chris Okasaki: Purely Functional Data Structures. Cambridge University Press 1999, ISBN 0-521-66350-4
- Peter Pepper und Petra Hofstedt: Funktionale Programmierung. Springer 2006, ISBN 3-540-20959-X
- Fethi Rabhi und Guy Lapalme: Algorithms – A Functional Programming Approach. Addison Wesley 1999, ISBN 0-201-59604-0
Weblinks
- Can Programming Be Liberated from the von Neumann Style? A Functional Style and Its Algebra of Programs − Vorlesung von John Backus anlässlich der Verleihung des Turing-Preises (1977)
- Why Functional Programming Matters − einführender Artikel von John Hughes.
- Amr Sabry: What is a Purely Functional Language?. In: J. Functional Programming, 8(1), 1-22, Januar 1998.
Fußnoten
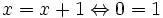
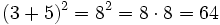
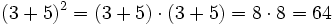
Wikimedia Foundation.