- Kohortenmodell
-
 Das Kohortenmodell im Schema.
Das Kohortenmodell im Schema.
Das Kohortenmodell ist ein Modell über die auditive Worterkennung, welches in den 80er Jahren des 20. Jahrhunderts von Wissenschaftlern unter Führung des amerikanischen Psychologen William Marslen-Wilson entwickelt wurde. Es beschreibt, wie auf einzelne Wörter, die im mentalen Lexikon gespeichert sind, beim Hören zugegriffen wird. Dabei wird aus einer Menge potentieller Kandidaten dasjenige Wort Laut für Laut ausgefiltert, welches den eingehenden akustischen Informationen am besten entspricht.
Inhaltsverzeichnis
Überblick
Worterkennung vs. Spracherkennung
Das Kohortenmodell ist ein Modell über die auditive Worterkennung, das heißt, es versucht zu erklären, wie der Zugriff auf die im Kopf gespeicherten Informationen einzelner Wörter beim Hören von Sprache funktioniert. Es geht dabei um die Frage, wie von den akustischen Signalen, welche zusammen ein Wort ergeben, auf den passenden Eintrag im mentalen Lexikon geschlossen wird. Für diese Modelle ist zunächst nicht von Interesse, wie sich die Bedeutungen einzelner Wörter im Gesamtkontext einer sprachlichen Äußerung ergeben. Vielmehr geht es nur um die Bedeutung der Wörter selbst, die durch den Kontext lediglich spezifiziert wird.
Dazu ein Beispiel: Ein ambiges Wort wie Bank umfasst viele verschiedene Bedeutungen (zum Beispiel Flussbank, Kreditinstitut, Sitzgelegenheit, …). Welche davon in einer sprachlichen Äußerung gerade gemeint ist, ergibt sich in den meisten Fällen aus dem sprachlichen und nichtsprachlichen Kontext. In der Theorie sind alle Bedeutungen eines Wortes in demselben Eintrag im mentalen Lexikon gespeichert, so auch alle Bedeutungen des Wortes Bank. Die eigentliche Bedeutung wird erschlossen, wenn diese durch den Kontext gefördert (im Fachjargon: geprimt) wird. Dies gilt auch für morpho-syntaktische Prozesse. So wird beispielsweise beim Verstehen des Wortes Banken ebenfalls zunächst auf den Eintrag für das Lexem Bank zugegriffen, dann für den der Pluralendung -en. In einem weiteren, für die Worterkennung selbst aber irrelevanten Prozess, werden die beiden erkannten Lexeme zusammengeführt und das Wort in seiner spezifischen Bedeutung (hier: mehrere Kreditinstitute, nicht aber mehrere Sitzgelegenheiten, da hier der Plural Bänke wäre) verstanden. Dasselbe gilt für komplexe Ausdrücke wie endozentrische Komposita (z.B. Bankangestellter) oder derivierte Wörter (z.B. Arbeiter aus den Einträgen für den Verbstamm arbeit- und dem substantivierenden Suffix -er). Ebenfalls zur Spracherkennung, nicht aber zur Worterkennung, gehört die syntaktische Analyse, wie zum Beispiel die Frage, ob das Wort Bank, in einem Satz eingebettet, als Subjekt (Die Bank befindet sich in der Innenstadt) oder als Objekt (Der Geldautomat befindet sich in der Bank) fungiert.
Geht es bei Modellen der Spracherkennung allgemein um das Finden einer konkreten Bedeutung eines Wortes oder eines Satzes in Abhängigkeit des semantischen, syntaktischen und sprachlichen Kontextes, beschränken sich Modelle der Worterkennung einzig auf das Finden des Eintrages im mentalen Lexikon entsprechend dem zu verstehenden Wort. Die Existenz eines solchen mentalen Lexikons wird als gegeben vorausgesetzt. Zusammengefasst befassen sich Modelle der Worterkennung allgemein mit der Frage, wie auf dieses Lexikon zugegriffen wird. Bei solchen Modellen ist es zunächst unerheblich, welche konkrete Bedeutung des Eintrages letztlich durch den Kontext vorgegeben ist. Somit ist die Worterkennung ein Teil der Spracherkennung, nicht aber mit ihr gleichzusetzen.[1]
Vorgeschichte und Abgrenzung
In der Psycholinguistik unterscheidet man grob zwei Arten von Modellen über auditive Worterkennung. Zum Einen gibt es die phonologischen Ansätze, zum Anderen die psycholinguistischen. Die phonologischen Ansätze sind forschungsgeschichtlich älter als die psycholinguistischen, beide existieren aber nach wie vor nebeneinander und werden von unterschiedlichen Wissenschaftlern je nach gegebener Fragestellung angenommen.
Phonologische Ansätze
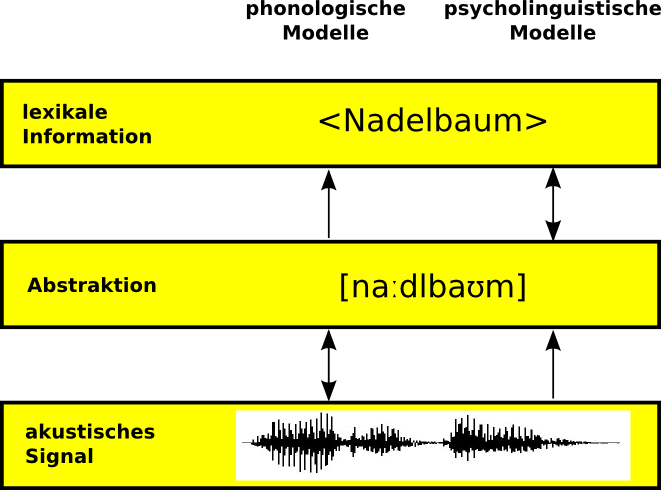
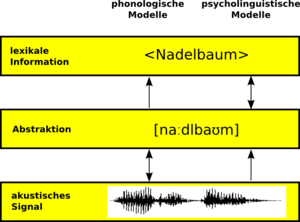 Schema, das die beiden Ansätze zur auditiven Worterkennung gegenüberstellt.
Schema, das die beiden Ansätze zur auditiven Worterkennung gegenüberstellt.
Die phonologischen Ansätze (links) greifen auf das akustische Signal (unterste Ebene) wiederholt zurück, und erst nach der vollständigen Abstraktion (mittlere Ebene) wird auf den Eintrag im mentalen Lexikon (obere Ebene) zugegriffen.
In den psycholinguistischen Modellen (rechts) wird das akustische Signal einmalig rekodiert und das Wort unter mehrmaligem Zugriff auf das mentale Lexikon erkannt.Die phonologischen Ansätze beschreiben Worterkennung als einen dynamischen Prozess, bei dem nach Eingang des akustischen Signals im Laufe der Erkennung wiederholt auf dieses Signal zurückgegriffen wird. Man spricht dabei von bottom-up-Ansätzen, das heißt, die Worterkennung geht allein vom akustischen Signal aus. Darüber hinaus gehen diese Modelle von früher Abstraktion aus. Demnach wird das einkommende Signal recht früh in diskrete Einheiten, beispielsweise distinktive Merkmale, zerlegt. Auch phonologische Eigenschaften der Sprache spielen bei der Erkennung eine wichtige Rolle.
Als Beispiele sind die Motor-Theorie, die Akustische Invarianztheorie oder die Quantentheorie der Sprachwahrnehmung zu nennen.
Psycholinguistische Ansätze
Die Psycholinguistischen Ansätze dagegen legen den Fokus auf die Wortsegmentierung und die Worterkennung. Spielt Weltwissen bei den phonologischen Ansätzen keine oder nur eine untergeordnete Rolle, wird in den psycholinguistischen Ansätzen dieses zur Reparatur von phonetisch verstümmelten Signalen verwendet. Damit sind diese Modelle top-down-orientiert, was bedeutet, dass bei der Erkennung von Wörtern auf vorhandenes Wissen, beispielsweise über strukturelle Eigenschaften der bekannten Wörter, zurückgegriffen wird. Das Kohortenmodell ist eine der ersten psycholinguistischen Theorien über die auditive Worterkennung. Weitere sind zum Beispiel das TRACE-Modell von McClalland und Elman, sowie seine Weiterentwicklungen Shortlist-Modell oder Merge-Modell, welche zum Teil auf Mechanismen des Kohortenmodells zurückgreifen.
Die Wissenschaftler um William Marslen-Wilson entwickelten das Kohortenmodell Anfang der 80er Jahre des 20. Jahrhunderts auf Basis einer Reihe von Experimenten, welche Ergebnisse brachten, die bisherige Modelle nicht oder nur mit zusätzlichen Annahmen erklären konnten.
Allgemeine Funktionsweise
Das Modell
Marslen-Wilson unterteilt die auditive Worterkennung in drei Makrostufen: Zugriff (engl. Access), Auswahl (engl. selection) und Integration.
Unter Zugriff wird im Modell die Umwandlung von akustischen Signalen in Merkmale bzw. Laute verstanden. In der Auswahlphase wird über den Mechanismus der Kohortenbildung (siehe unten) der passende Eintrag im mentalen Lexikon ausgewählt und in der Integrationsphase in den entsprechenden semantischen und syntaktischen Kontext eingebettet. Das Modell allein macht keine Aussagen über das Erfassen der Bedeutung von komplexen Sinneinheiten wie Sätzen oder Phrasen.
Lexikaler Zugriff im Kohortenmodell
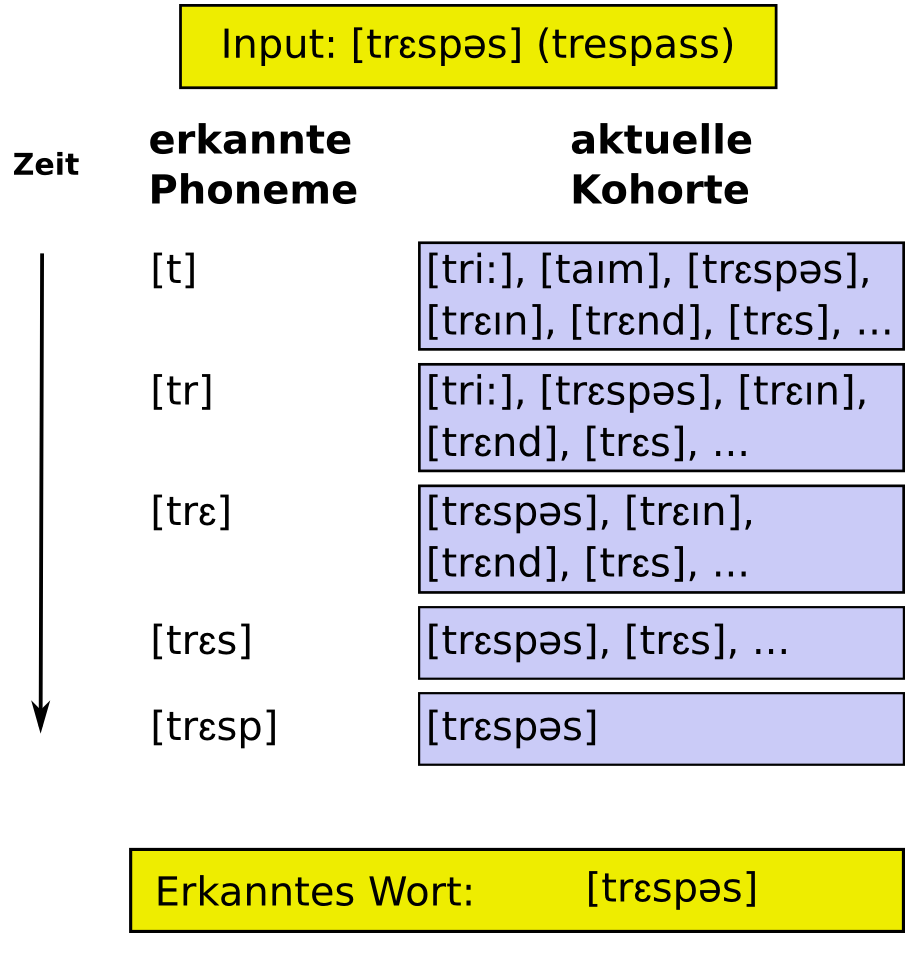
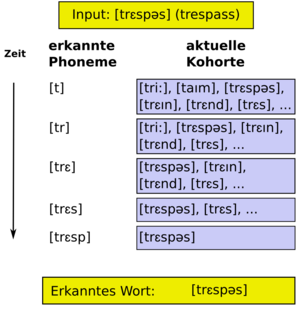 Schema der Funktionsweise des Kohortenmodells. Dabei nimmt der Hörer den Input Laut für Laut wahr und schließt iterativ alle Lexeme aus, die nicht zum Gehörten passen.
Schema der Funktionsweise des Kohortenmodells. Dabei nimmt der Hörer den Input Laut für Laut wahr und schließt iterativ alle Lexeme aus, die nicht zum Gehörten passen.Die Grundidee des Modells ist, dass das eingehende akustische Signal (der so genannte Input) beim Hören gesprochener Sprache seriell in Phone zerlegt wird. Der Hörer erkennt dabei den ersten Laut des zu verstehenden Wortes und öffnet eine Menge aller in seinem mentalen Lexikon gespeicherter Einträge, die mit eben diesem Laut beginnen. Diese Menge lexikaler Einträge wird Kohorte genannt. Im nächsten Schritt wird der zweite Laut des Wortes analysiert. Aus der ersten Kohorte werden nun alle die Einträge ausgewählt, deren zweiter Laut mit dem erkannten des Inputs übereinstimmt. Die übrigen Lexeme werden aus der Kohorte entfernt. Im weiteren stehen also nur die Lexeme zur Wahl, die nach wie vor mit den bisher erkannten Informationen des Inputs übereinstimmen. Diese Vorgehensweise wird nun mit den nachfolgenden Lauten solange wiederholt, bis das Wort eindeutig erkannt ist. Dies ist dann der Fall, wenn die Kohorte nur noch einen Eintrag enthält. Die nebenstehende Grafik verdeutlicht diese allgemeine Funktionsweise des Modells am Beispiel des zu erkennenden englischen Wortes „trespass“ (zu Deutsch: unbefugtes Betreten).
Das ursprüngliche Kohortenmodell war in der Lage, Kontexteffekte und den seriellen Charakter der auditiven Worterkennung zu erklären. Nachdem als Schwächen des Modells Frequenzeffekte und der Umgang mit defektem Input bekannt wurden, erweiterte Marslen-Wilson das Modell in der Mitte der 1980er Jahre. In der Literatur haben sich für diese beiden Stadien des Modells die Begriffe Cohort I bzw. Cohort II eingebürgert.
Experimentelle Grundlagen
William Marslen-Wilson führte eine Reihe von Experimenten durch, welche zwei wichtige Eigenschaften der auditiven Worterkennung aufzeigten. Zum einen den seriellen Charakter und zum anderen den Einfluss von kontextuellen Informationen auf die Worterkennung. Gleichzeitig konnte er damit Schwächen in den bis dahin bestehenden Modellen über die Sprachwahrnehmung demonstrieren. Aus den Ergebnissen dieser Experimente ist dann das Kohortenmodell erwachsen, welches die zu beobachtenden Effekte erklären sollte.
Shadowing-Experimente
Die ersten Experimente, welche Marslen-Wilson durchführte, waren so genannte Shadowing-Experimente. Bei diesen Experimenten liest der Versuchsleiter einen Text vor, der von der Versuchsperson so schnell wie möglich nachgesprochen werden muss. Bei einer durchschnittlichen Wortlänge von 500 ms ergab sich eine Verzögerung zwischen den Worten des Versuchsleiters und der Wiederholung durch die Versuchsperson von 250 ms. Dies heißt, dass die Versuchsperson ein Wort erkennen und nachsprechen konnte, noch bevor der Versuchsleiter das Wort vollständig ausgesprochen hatte. Abzüglich der Zeit, welche die Artikulation der wahrgenommenen Wörter in Anspruch nimmt, geht man heute davon aus, dass der Prozess des reinen Erkennen eines Wortes innerhalb von etwa 200 ms vonstattengeht. Dies entspricht bei normaler Sprechgeschwindigkeit einer Länge von etwa zwei bis drei Lauten (Phonemen).
In diesem Zusammenhang spricht man von den so genannten uniqueness bzw. recognition points.[2] Der uniqueness point (auch Diskriminationspunkt) ist dabei der Punkt, ab dem ein Wort zweifelsfrei erkannt ist, wenn es also kein anderes Wort gibt, welches durch dieselbe Phonemsequenz kodiert ist, wie das zu erkennende. Dies ist spätestens dann gegeben, wenn ein neues Wort beginnt. Der recognition point ist dagegen der Punkt, ab dem der Hörer mit hoher Sicherheit sagen kann, welches Wort er wahrnimmt, also nach etwa 200 ms.
Versuchsleiter
meintVersuchsleiter
liest vorpresident howident company comsiny tomorrow tommorane In weiteren derartigen Experimenten wurde der Versuchsperson ein Text vorgelesen, der im Gegensatz zum ersten Experiment aber Fehler enthielt. Dabei variierte die Position des Fehlers innerhalb eines Wortes, wobei der Fehler am Anfang, in der Mitte oder am Ende des Wortes platziert sein konnte. Die nebenstehende Tabelle zeigt einige Beispiele. Diese teilweise fehlerbehafteten Wörter wurden in drei verschiedene Texte verpackt, wobei der eine ein normaler Text war. Der zweite Text war semantisch anormal, die darin vorkommenden Sätze waren grammatisch richtig, ergaben aber keinen zusammenhängenden Sinn. Der dritte Text war semantisch und syntaktisch anormal, also eine zusammenhanglose Aneinanderreihung von Wörtern.
In diesen Experimenten lag das Augenmerk auf der Restauration der fehlerhaften Wörter. Unter Restauration versteht man, wenn die Versuchsperson ein fehlerhaftes Wort trotzdem korrekt wiedergegeben kann und es nicht als fehlerhaft erkennt. Es stellt sich heraus, dass die Versuchspersonen fehlerhafte Wörter am ehesten restaurieren, wenn die Fehler am Ende des Wortes und unter normalen Bedingungen auftraten. Traten die Fehler dagegen am Anfang eines Wortes bzw. in anormalen Kontexten auf, wurden sie fast immer als solche erkannt und die entsprechenden Wörter nicht restauriert.
Einerseits sprechen diese Beobachtungen für einen seriellen Charakter der auditiven Worterkennung, was die Restauration zu späteren Zeitpunkten erklärt. Auf der anderes Seite geben solche Experimente Aufschluss über die Rolle des Kontextes bei der Erkennung von fehlerbehafteten Wörtern, was sich durch das Restaurieren in normalen Kontexten und dem Bemerken der Fehler in anormalen Kontexten belegen lässt.
Word-Monitoring-Experimente
Eine dritte Reihe von Experimenten waren so genannte Word-Monitoring-Experimente. Die Versuchsperson bekommt dabei in kurzen Abständen eine Reihe von Wörtern akustisch über Kopfhörer präsentiert und hat die Aufgabe, eine vor sich befindliche Taste zu drücken, wenn sie ein vorher bestimmtes Wort vernimmt. Gemessen wurde die Reaktionszeit, also die Zeit zwischen dem Beginn des zu erkennenden Wortes und dem Drücken der Taste. Das jeweilige Wort konnte dabei in drei verschiedenen Kontexten auftauchen. Entweder nach einem semantisch relatierten, nach einem syntaktisch relatierten oder nach einem unrelatierten Wort. Ist das zu erkennende Wort beispielsweise „Adler“, so kann ein semantisch relatiertes Wort „Vogel“ (denn Vogel ist Hyperonym zu Adler), ein syntaktisch relatiertes Wort „der“ („der Adler“) und ein unrelatiertes Wort „blau“ („blau“ und „Adler“ stehen weder semantisch noch in der Form syntaktisch in Beziehung) sein.
Bei diesen Experimenten stellte sich heraus, dass bei einem semantisch relatierten vorausgehenden Wort die Reaktionszeit am kürzesten war. Bei einem syntaktisch relatierten Vorgängerwort war die Reaktionszeit erheblich länger, bei unrelatierten Vorgängerwörtern am längsten.
Schlussfolgerungen aus den Ergebnissen
Neben dem Nachweis des seriellen Charakters der auditiven Worterkennung, verdeutlichten die Experimente darüber hinaus den so genannten Kontext-Effekt.
In bestimmten sprachlichen Kontexten ist das Auftreten bestimmter Klassen von Wörtern wahrscheinlicher als das anderer. So ist es beispielsweise in Sprachen wie Deutsch oder Englisch relativ unwahrscheinlich, dass nach einem Artikel ein Verb folgt. In diesem Falle spricht man vom syntaktischen Kontext, der bestimmte Wortklassen primt, also wahrscheinlich werden lässt. Das Priming offenbart sich in einer kürzeren Erkennungszeit im Gegensatz zu ungeprimten Lexemen.[3]
Neben dem syntaktischen spielt auch der semantische Kontext eine wichtige Rolle bei der Geschwindigkeit der Worterkennung. So ist es beispielsweise relativ unwahrscheinlich, dass in einem Sprechakt, der Kernphysik zum Thema hat, ein Fachbegriff aus dem Landschaftsbau verwendet wird. Ähnliche Effekte sind auch auf phonologischer Ebene zu erkennen. Reimen sich beispielsweise zwei aufeinander folgende Wörter, so wird das zweite schneller erkannt. Reimen sie sich dagegen nicht, dauert die Erkennung des zweiten Wortes länger.[4]
Cohort I
Serielle Worterkennung
Der serielle Charakter der auditiven Worterkennung wird im Kohortenmodell wie folgt erklärt: Wenn ein Wort gesprochen wird, so erreicht dies den Hörer in Form von akustischen Wellen, wobei jeder Laut des Wortes als ein spezifisches Muster von sich überlagernden Wellen kodiert ist. Ein dem lexikalen Zugriff vorgelagertes kognitives Modul erschließt aus diesen Wellen nun, welchen konkreten Laut sie jeweils repräsentieren. Unter seriell ist in diesem Zusammenhang zu verstehen, dass zu jedem Zeitpunkt genau ein Laut übertragen wird. Demnach ist es also nicht der Fall, dass zu einem Zeitpunkt zwei unterschiedliche Laute vom Sprecher auf den Hörer übertragen werden. Das zu verstehende Wort wird also Laut für Laut betrachtet.
Nach Erkennen des ersten Lautes wird ein erstes Mal auf das mentale Lexikon, also dem Modul des kognitiven Systems, in dem alle Wörter gespeichert sind, die im Laufe des Lebens gelernt wurden, zugegriffen. Dabei werden alle Einträge aktiviert, die mit dem erkannten Laut beginnen. Unter Aktivation, versteht man in der Psycholinguistik, dass auf einen Eintrag zugegriffen wird und dabei weitere Informationen abgerufen werden. Diese werden als ebenfalls im Eintrag verzeichnet angenommen. Diese Informationen können beispielsweise
- semantischer Natur sein, also Informationen über die Bedeutung des Wortes beinhalten;
- morpho-syntaktischer Natur sein, also Informationen darüber, ob es sich beispielsweise um ein Verb oder um ein Substantiv handelt, ob das Wort Argumente benötigt, welchem Genus es angehört, usw.;
- phonologischer Natur sein, die unter anderem besagen, mit welchen Lauten das Wort gebildet wird.
Mit dem Erkennen der folgenden Laute werden alle die Einträge aus der Kohorte entfernt, die nicht mehr zum Gehörten passen, das heißt, die Aktivierung wird aufgehoben, die abgerufenen Informationen werden „vergessen“. Ab einem bestimmten Punkt ist die Kohorte nur noch einen Eintrag groß, dies ist der Punkt, ab dem das Wort zweifelsfrei erkannt ist. In der Literatur wird dieser Punkt als uniqueness point bezeichnet. In dieser ersten Version des Kohortenmodells folgt Marslen-Wilsen einem Alles-oder-nichts-Ansatz, ein Lemma kann entweder aktiviert oder nicht aktiviert sein, es gibt keine Abstufungen oder Unterschiede in der Aktivierung.
Marslen-Wilson verdeutlichte dies am englischen Wort trɛs.pʌs (trespass, dt. unbefugtes Betreten). Das erste, was der Hörer erkennt, ist das Phonem [t], gefolgt von [r], dann [ɛ], usw. Bereits beim ersten Laut wird mental eine Kohorte geöffnet. Dabei werden alle Wörter aktiviert, welche im mentalen Lexikon verzeichnet sind und die ebenfalls mit dem Laut [t] beginnen. Wird das zweite Phonem ([r]) erkannt, werden alle Wörter aus der Kohorte gestrichen, die nicht mit der Phonemfolge [tr] beginnen. Besteht die Kohorte beispielsweise mit Erkennen des [t] aus den Worten tree (Baum), trespass (unbefugtes Betreten), time (Zeit), train (trainieren), tress (Locke), so wird mit Erkennen des zweiten Lautes das time aus der Kohorte entfernt, da es nicht mit der Lautfolge [tr] beginnt. Wird der dritte Laut erkannt ([ɛ]), wird die Kohorte auf die Einträge trespass, tress und training verkürzt (tree wird phonetisch als [triː] realisiert). Erst mit Erkennen des fünften Lautes, [p], befindet sich nur noch ein Wort in der Kohorte (nämlich trespass), und die Kette von Lauten ist als das Wort tresspass eindeutig erkannt.
Erklärung der Kontexteffekte
Im Kohortenmodell wird die schnellere Erkennung von durch den Kontext gebundenen Lexemen durch die Annahme der parallelen Aktivierung erklärt. Diese Annahme besagt, dass alle Mitglieder einer Kohorte gleichermaßen aktiviert werden, das heißt, der Hörer greift mental auf alle Mitglieder der Kohorte zu. Diese Aktivierung wird dann wieder zurückgenommen, wenn das Lexem nicht mehr zum gegebenen Input passt, wenn das Lexem also auf Grund einer anderen Phonemfolge aus der Kohorte gestrichen wird.
Da bei der Aktivierung einzelner Lexeme sämtliche Informationen des Lexems, also morpho-syntaktische, phonologische, wie auch semantische, stets mitaktiviert werden, greift der Hörer auch auf relatierte Einträge im mentalen Lexikon zurück. Das sind andere Einträge im Lexikon, die über dieselben oder hinreichend ähnliche Eigenschaften verfügen.
Die Ergebnisse der oben genannten Experimente lassen sich mit dem Kohortenmodell wie folgt erklären: Beim Verstehen des ersten Wortes werden dieses sowie alle zu ihm relatierten Wörter aktiviert. Beim Erkennen des folgenden Wortes stehen die aktivierten Informationen immer noch zur Verfügung. Wird nun eines der indirekt aktivierten Lexeme in die Kohorte für das folgende Wort aufgenommen, erfolgt die Erkennung des zweiten Wortes nach kürzerer Zeit im Vergleich zu unrelatierten und damit noch nicht aktivierten Wörtern.
Eine weitere Folge der Annahme über die parallele Aktivierung ist, dass sich die Diskrepanz zwischen uniqueness point und recognition point direkt erklären lässt.
Kritik
Sehr bald nach der Veröffentlichung des Kohortenmodells wurden Probleme bekannt, die das Modell nicht ohne weitere Annahmen lösen konnte. Dazu zählen der Frequenzeffekt sowie der Umgang mit defektem Input.
Der Frequenzeffekt besagt im engeren Sinne, dass der Hörer ein Wort, welches er häufig benutzt, schneller erkennt als ein anderes, welches er tendenziell seltener verwendet. Mit defektem Input ist gemeint, dass bei gesprochener Sprache selten das Wort als Ganzes beim Hörer ankommt. Rauschen und Nebengeräusche verstümmeln in vielen Fällen einen Teil der akustischen Information, der vom Sprecher auf den Hörer übertragen wird. Trotzdem ist der Hörer in den meisten Fällen in der Lage, das Gesprochene zu verstehen.
Diese Kritik kam maßgeblich von James L. McClelland und Jeffrey L. Elman und führte in der Folge zur Entwicklung des TRACE-Modells, einem Gegenentwurf zum Kohortenmodell, welches aber auf wesentliche Kernpunkte desselben zurückgreift[5]
Um den Problemen zu begegnen, erweiterte Marslen-Wilson nach einer Reihe von Experimenten sein Modell, welches in der gegenwärtigen Literatur als Cohort II bekannt ist.
Cohort II
Bald nach Erscheinen der Kritik an seinem Modell, führte Marslen-Wilson eine Reihe von weiteren Experimenten durch, um die genannten Effekte zu überprüfen, und änderte sein Modell danach den Ergebnissen entsprechend ab. Die Experimente, die Ergebnisse derselben und die Abwandlungen am Modell erläuterte Marslen-Wilson in einem Aufsatz von 1987 (siehe Literatur).
Frequenzeffekt
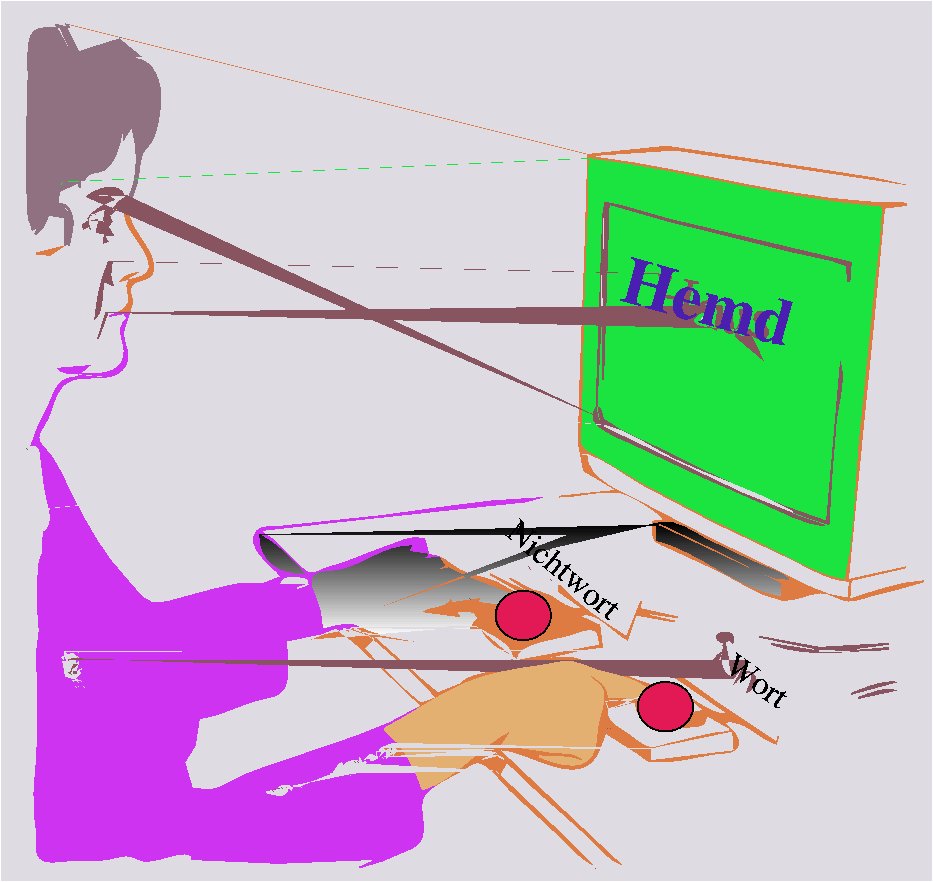
 Allgemeiner Versuchsaufbau eines Experiments zur lexikalen Entscheidung
Allgemeiner Versuchsaufbau eines Experiments zur lexikalen EntscheidungUm die Wirksamkeit des Frequenzeffektes zu testen, ließ Marslen-Wilson in der Mitte der 1980er Jahre erneut Experimente durchführen. Bei diesen handelte es sich um so genannte Lexikale Entscheidungsexperimente mit visuellen Zielwörtern. Bei diesen Experimenten bekommen die Versuchspersonen die Aufgabe, von Wörtern, die sie auf einem Bildschirm angezeigt bekommen, per Tastendruck zu entscheiden, ob sie Wörter ihrer Sprache sind oder nicht. Zusätzlich wurden den Versuchspersonen über Kopfhörer verschiedene Wörter präsentiert (so genannte Destruktorwörter). Variiert wurde bei diesen Experimenten der Zeitpunkt, bei dem das Wort auf dem Bildschirm in Bezug auf das gehörte Wort eingeblendet wurde.
auditiver Input visueller Input Erkennungszeit CAP‣T SHIP schnell CAP‣T GUARD normal CAPTAIN‣ SHIP sehr schnell CAPTIVE‣ SHIP langsam CAPTAIN‣ GUARD langsam CAPTIVE‣ GUARD sehr schnell Die nebenstehende Tabelle verdeutlicht die Ergebnisse dieses Experimentes. Den Versuchspersonen wurden beispielsweise die Worte captain (engl. „Kapitän“) oder captive (engl. „Gefangener“) akustisch dargeboten. Die entsprechenden zur lexialen Entscheidung visuell dargebotenen Wörter waren ship (engl. „Schiff“) oder guard (engl. hier: „Bewacher“). Der Zeitpunkt, zu dem das Wort auf dem Bildschirm dargeboten wurde, konnte unmittelbar vor dem T oder am Ende des akustisch dargebotenen Wortes sein (in der Tabelle durch das Zeichen „‣“ dargestellt).
Das Wort captain wird als frequenter angenommen als captive, das bedeutet, dass captain im durchschnittlichen Wortschatz eines englischen Muttersprachlers tendenziell häufiger vorkommt als captive. Wie die Tabelle zeigt, erkannten die Versuchspersonen das Wort ship schneller als das Wort guard, wenn es zum frühen Zeitpunkt (also unmittelbar vor dem gehörten /t/) präsentiert wurde. Dies ist dadurch zu erklären, dass das Wort captain beim Verstehen der ersten drei Phoneme (cap) aktiviert ist und dadurch das Wort ship primen kann, während das andere mögliche Wort (captive) nicht oder schwächer aktiviert wurde, wodurch ein priming-Effekt für guard ausblieb und die Erkennung entsprechend länger dauerte. Wurden hingegen die zu erkennenden Wörter spät präsentiert, verlor sich dieser Effekt. Marslen-Wilson schloss daraus, dass der Frequenzeffekt zwar gilt, aber nur früh wirkt und zu einem späteren Zeitpunkt durch allgemeine Kontexteffekte überschrieben wird und seine Wirksamkeit verliert.
Um den Frequenzeffekt mit seinem Modell erklären zu können, ließ Marslen-Wilson in der zweiten Version des Modells die Alles-oder-nichts-Annahme fallen und ersetzte sie durch einen goodness-of-fit-Ansatz (engl., sinngemäß: was am besten passt). Wurden nach ersterem die Mitglieder einer Kohorte noch allesamt gleichermaßen aktiviert und deaktiviert, nimmt man in der zweiten Version des Modells an, dass bestimmte Einträge im Lexikon ein größeres Aktivierungspotential haben als andere. Frequente Einträge werden innerhalb einer Kohorte demnach stärker aktiviert als weniger frequente, was das frühere Aktivieren der frequenteren Wörter erklären soll.
Defekter Input
Verschiedene Experimente haben gezeigt, dass Versuchspersonen in der Lage sind, Wörter zu erkennen, wenn bestimmte Teile der Wörter durch Störgeräusche, beispielsweise Rauschen oder durch Einspielen eines anderen Lautes, verstümmelt wurden. Spielt man den Versuchspersonen zum Beispiel das Wort universal in einen Satz eingebettet vor, ersetzt das s durch Rauschen und fragt die Versuchspersonen, wo der Fehler war, so fällt es den Meisten schwer, den Fehler genau zu lokalisieren, geschweige denn dass sie überhaupt einen Fehler bemerken. Lässt man an Stelle des s jedoch eine geräuschlose Lücke, so erkennen die Versuchspersonen den Fehler in nahezu allen Fällen korrekt.
Die Ursprungsversion des Kohortenmodells arbeitet auf Phonem-Ebene. Die sprachlichen Einheiten, welche seriell erkannt werden, sind dabei die Laute des zu erkennenden Wortes. Um die Beobachtung des Verstehens sprachlicher Äußerungen trotz potentieller Störgeräusche zu erklären, ließ man diese Annahme fallen und veränderte das Modell derart, dass es nun mit distinktiven Merkmalen arbeitet. In der Theorie können Laute in verschiedene distinktive Merkmale zerlegt werden, so trägt beispielsweise der Laut /t/ die Merkmale [–stimmhaft, KORONAL, -sonorantisch, –nasal] und so weiter.
In der zweiten Version des Modells werden die Kohorten nicht mehr nach Erkennen bestimmter Laute geöffnet, sondern dann, wenn eine unbestimmte Menge an sich überschneidenden phonologischen Merkmalen gegeben ist. Dies zieht nach sich, dass auch die Einträge im mentalen Lexikon phonologisch nicht ausspezifiziert, also als Kette von Phonemen gespeichert sind, sondern in Form von Ketten distinkitver Merkmale. Wird nun ein Teil dieser Merkmale durch Störgeräusche überspielt, bleiben die Einträge in der Kohorte, wenn die restlichen Merkmale übereinstimmen.
Kritik
Als wichtiges Problem beider Versionen des Kohortenmodells wird die Abgrenzung von Wörtern genannt[6]. Das Modell sehe keinen Mechanismus vor, der Anfang und Ende eines Wortes in einem zusammenhängenden Text zu erkennen vermag. Dennoch bietet es einen sehr robusten Mechanismus, die Erkennung isolierter Wörter zu erklären.
Aktuelle Entwicklungen
Das Kohortenmodell gilt trotz seiner Schwächen heute als ein Standardmodell über die auditive Worterkennung, welches in seinen Grundzügen in viele spätere Modelle integriert wurde.
Das sukzessive Ausschließen von unpassenden Elementen einer Kandidatenmenge findet sich auch in der Optimalitätstheorie wieder, einem formalen Modell über die Grammatik menschlicher Sprachen.
Auch in der Computerlinguistik wurden Grundzüge des Modells integriert. Die Trunkierung bei der Recherche in Datenbanksystemen macht sich den grundlegenden Mechanismus der Verkleinerung einer relevanten Ergebnismenge durch segmentweises Ausschließen von potentiellen Ergebnissen zunutze. Sie bildet somit eine direkte Anwendung des Kohortenmodells in der Computerlinguistik.
Literatur
Primärliteratur
- William D. Marslen-Wilson und Alan Welsh: Processing Interactions and Lexical Access during Word Recognition in Continuous Speech. In: Cognitive Psychology Bd. 10, Nr. 1, 1978, S. 29–63 (doi:10.1016/0010-0285(78)90018-X)
- William D. Marslen-Wilson: Spoken Word Recognition. In H. Bouma und D.G. Bouwhuis (Hrsg.): Attention and Performance X. Lawrence Erlbaum, Hove, 1984
- William D. Marslen-Wilson: Functional Parallelism in Spoken Word Recognition. Cognition 25:71–102 1987 (doi:10.1016/0010-0277(87)90005-9)
Sekundärliteratur
- Rainer Dietrich: Psycholinguistik. 1. Auflage, Metzler, Stuttgart, 2002, ISBN 3-476-10342-0
- Trevor A. Harley: The Psychology of Language. From Data to Theory. 3. Auflage, Psychology Press, Hove, New York, 2008, ISBN 978-1-84169-382-8, Seiten 268–273
- M. Gareth Gaskell und Gerry Altmann (Hrsg): The Oxford Handbook of Psycholinguistics. Oxford University Press, Oxford, 2007, ISBN 9780198568971 (Online, Stand: 18. April 2009)
Einzelnachweise
- ↑ vergleiche Harley (2008:241f.)
- ↑ William D. Marslen-Wilson und Lorraine Komisarjevsky Tyler: The temporal structure of spoken language understanding. In: Cognition Nr. 8, 1980, S. 1-71
- ↑ D. E. Meyer und R. W. Schvaneveldt: Facilitation in recognizing pairs of words: Evidence of a dependence between retrieval operations. In: Journal of Experimental Psychology Nr. 90, 1971, S. 227–234
- ↑ D. E. Meyer, R. W. Schvaneveldt und M. G. Ruddy: Functions of graphemic and phonemic codes in visual word recognition. In: Memory & Cognition Nr. 2, 1974, S. 309–321
- ↑ James L. McClelland und Jeffrey L. Elman: The TRACE Model of Speech Perception. In: Cognitive Psychology Bd. 18, Nr.1, 1986, doi:10.1016/0010-0285(86)90015-0, S. 1–86.
- ↑ siehe zum Beispiel Harley (2008), Seite 273

Wikimedia Foundation.