- Zufallsstichprobe
-

Dieser Artikel wurde auf der Qualitätssicherungsseite des Portals Mathematik eingetragen. Dies geschieht, um die Qualität der Artikel aus dem Themengebiet Mathematik auf ein akzeptables Niveau zu bringen. Bitte hilf mit, die Mängel dieses Artikels zu beseitigen, und beteilige dich bitte an der Diskussion!
 Ein zufällig ausgewählter PKW wird in einer Stichprobe einer Rauschgiftfahndung unterzogen
Ein zufällig ausgewählter PKW wird in einer Stichprobe einer Rauschgiftfahndung unterzogen
Eine Zufallsstichprobe (auch Wahrscheinlichkeitsauswahl, Zufalls-Stichprobe, Zufallsauswahl, Random-Sample) ist eine Stichprobe aus der Grundgesamtheit die mit Hilfe eines speziellen Auswahlverfahrens gezogen wird. Bei einem solchen Zufallsauswahlverfahren hat jedes Element der Grundgesamtheit eine angebbare Wahrscheinlichkeit (größer Null), in die Stichprobe zu gelangen. Nur bei Zufallsstichproben sind, streng genommen, die Methoden der induktiven Statistik anwendbar.
Inhaltsverzeichnis
Mathematische Definition
Eine Stichprobe ist zunächst einmal eine Teilmenge einer Grundgesamtheit. Für eine Zufallsstichprobe werden zusätzliche Bedingungen gestellt:
- die Elemente werden zufällig aus der Grundgesamtheit gezogen, und
- die Wahrscheinlichkeit, mit der ein Element aus der Grundgesamtheit gezogen wird, ist angebbar.
Des Weiteren unterscheidet man zwischen einer uneingeschränkten und einer einfachen Zufallsstichprobe:
- Uneingeschränkte Zufallsstichprobe:
- jedes Element der Grundgesamtheit hat die gleiche Wahrscheinlichkeit, in die Stichprobe zu gelangen
- Einfache Zufallsstichprobe:
- jedes Element der Grundgesamtheit hat die gleiche Wahrscheinlichkeit, in die Stichprobe zu gelangen und
- die Ziehungen aus der Grundgesamtheit erfolgen unabhängig voneinander
Eine uneingeschränkte Zufallsstichprobe erhält man z.B. bei einem Ziehen ohne Zurücklegen und eine einfache Zufallstichprobe z.B. bei einem Ziehen mit Zurücklegen.
Beispiele
Literary Digest Desaster
Das Literary Digest Desaster von 1936 zeigt auf, was passieren kann, wenn keine Zufallsstichprobe aus der Grundgesamtheit gezogen wird.[1] Eine verzerrte Stichprobe führte zu einer vollständig falschen Wahlprognose.
Wahlbefragung
Eine Befragung von Wählern, nachdem sie aus der Wahlkabine kommen, bzgl. ihres Wahlverhaltens ist eine uneingeschränkte Zufallsstichprobe (wenn kein Befragter die Antwort verweigert) bzgl. der Wähler. Sie ist jedoch keine (uneingeschränkte) Zufallsstichprobe bzgl. der Wahlberechtigten.
Taschenkontrolle
Der Einzelhandel beklagt immer wieder, dass durch Diebstahl von Waren durch eigene Mitarbeiter große Schäden verursacht werden.[2] Deswegen führen größere Supermärkte unter anderem eine Taschenkontrolle durch, wenn Mitarbeiter den Supermarkt verlassen. Da eine vollständige Taschenkontrolle aller Angestellten zu aufwändig wäre (und dies vermutlich auch als Arbeitszeit bezahlt werden müsste), gehen die Angestellten beim Verlassen des Supermarktes durch den Personalausgang an einer Lampe vorbei. Sie zeigt computer-gesteuert entweder ein grünes Licht (Angestellter wird nicht kontrolliert) oder ein rotes Licht (Angestellter wird kontrolliert). Dieser Auswahl ist dann eine einfache Zufallsauswahl.
Zufallsstichproben in der mathematischen Statistik
In der mathematischen Statistik werden die Zufallsvariablen X1 bis Xn (auch: Stichprobenvariablen) als Zufallsstichproben bezeichnet (siehe zum Beispiel beim Stichprobenmittel und Stichprobenvarianz). Sie geben an, mit welcher Wahrscheinlichkeit bei der iten Ziehung mit einem bestimmten Auswahlverfahren ein bestimmtes Element der Grundgesamtheit gezogen werden kann. Die konkrete Stichprobe x1,...,xn wird dann Realisierungen der Zufallsvariablen
 betrachtet.
betrachtet.Wurde eine einfache Zufallsstichprobe gezogen, so kann man zeigen, dass die Stichprobenvariablen Xi unabhängig und identisch verteilt sind (Abkürzung i.i.d., aus dem engl. independent and identical distributed). D.h. der Verteilungstyp und die Verteilungsparameter aller Stichprobenvariablen sind gleich der Verteilung in der Grundgesamtheit (identical distributed), und aufgrund der Unabhängigkeit der Ziehungen sind die Stichprobenvariablen auch unabhängig voneinander (independent distributed). Bei vielen Problemen in der induktiven Statistik wird vorausgesetzt, dass die Stichprobenvariablen i.i.d. sind.
Abhängige und unabhängige Stichproben
Bei Analysen mit mehr als einer Stichprobe muss zwischen abhängigen und unabhängigen Stichproben unterschieden werden. Statt von einer abhängigen Stichprobe spricht man auch von verbundenen Stichproben[3] oder gepaarte Stichproben[4].
Abhängige Stichproben treten meist bei wiederholten Messungen an dem gleichen Untersuchungsobjekt auf. Zum Beispiel besteht die erste Stichprobe aus Personen vor der Behandlung mit einem bestimmten Medikament, und die zweite Stichprobe aus denselben Personen nach der Behandlung, d.h. die Elemente von zwei (oder mehr) Stichproben können einander jeweils paarweise zugeordnet werden.
Bei Unabhängigen Stichproben besteht kein Zusammenhang zwischen den Elementen der Stichproben. Dies ist beispielsweise der Fall, wenn die Elemente der Stichproben jeweils aus unterschiedlichen Population kommen. Die erste Stichprobe besteht beispielsweise aus Frauen, und die zweite Stichprobe aus Männern, oder wenn Personen nach dem Zufallsprinzip in zwei oder mehrere Gruppen aufgeteilt werden.
Formal bedeutet es für die Stichprobenvariablen Xij (mit i das ite Untersuchungsobjekt und j die jte Messung):
- bei unabhängigen Stichproben: alle Stichprobenvariablen Xij sind unabhängig voneinander.
- bei abhängigen Stichproben: die Stichprobenvariablen der ersten Stichprobe X11, ..., Xn1 sind unabhängig voneinander, jedoch gibt es eine Abhängigkeit zwischen den Stichprobenvariablen Xi1, ..., Xip, da sie am gleichen Untersuchungsobjekt i erhoben werden.
Einstufige Zufallsstichproben
Eine reine (auch: einfache) oder uneingeschränkte Zufallsstichprobe kann mittels eines Urnenmodells beschrieben werden. Dazu wird ein fiktives Gefäß mit Kugeln gefüllt, welche anschließend zufällig gezogen werden: Ziehen mit Zurücklegen ergibt eine einfache Zufallsstichprobe, Ziehen ohne Zurücklegen ergibt eine uneingeschränkte Zufallsstichprobe. Durch ein Urnenmodell lassen sich so verschiedene Zufallsexperimente, etwa eine Lottoziehung, simulieren.
Stichprobenumfang
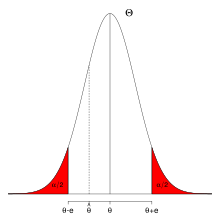 Zentrales Schwankungsintervall für einen unbekannten Parameter θ.
Zentrales Schwankungsintervall für einen unbekannten Parameter θ.Der Stichprobenumfang (oft auch Stichprobengröße genannt) ist die Anzahl der für eine Prüfung benötigten Proben einer Grundgesamtheit, um statistische Kenngrößen mit einer vorgegebenen Genauigkeit mittels Schätzung zu ermitteln. Der Stichprobenumfang wird aber häufig durch Normen bzw. Erfahrungswerte festgelegt.
Wenn θ der unbekannte Parameter in der Grundgesamtheit ist, dann wird eine Schätzfunktion Θ = Θ(X1,...,Xn) in Abhängigkeit der Stichprobenvariablen X1, ..., Xn konstruiert. Der Erwartungswert der Zufallsvariablen Θ ist meist E(Θ) = θ und es gilt:
mit
 ein Punktschätzung des unbekannten Parameters, e der absolute Fehler und 1 − α die Wahrscheinlichkeit, dass Θ eine Realisation im zentralen Schwankungsintervall annimmt.
ein Punktschätzung des unbekannten Parameters, e der absolute Fehler und 1 − α die Wahrscheinlichkeit, dass Θ eine Realisation im zentralen Schwankungsintervall annimmt.Der absolute Fehler ist gleich
 , also
, alsound
 hängt meist vom Verteilungstyp von Θ ab und die Varianz
hängt meist vom Verteilungstyp von Θ ab und die Varianz  . Die folgende Tabelle gibt für den unbekannten Mittelwert μ bzw. den unbekannten Anteilswert π eine Abschätzung des Stichprobenumfanges an.
. Die folgende Tabelle gibt für den unbekannten Mittelwert μ bzw. den unbekannten Anteilswert π eine Abschätzung des Stichprobenumfanges an.Unbekannter
ParameterBedingung e Abschätzung
Stichprobenumfangc1 − α / 2 
μ Xi∼N(μ;σ) und σ bekannt z1 − α / 2 

Xi∼N(μ;σ) und σ unbekannt tn − 1;1 − α / 2 

Xi∼(μ;σ) und n > 30 z1 − α / 2 
π 
z1 − α / 2 

Beispiel (Wahl)
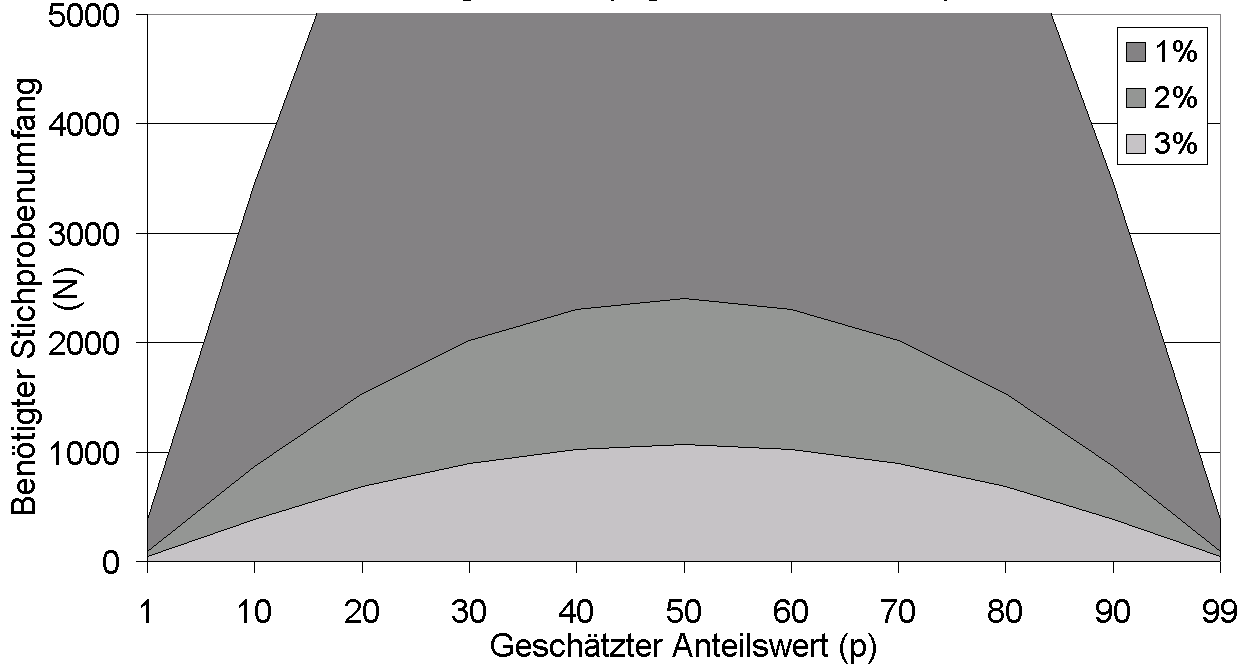
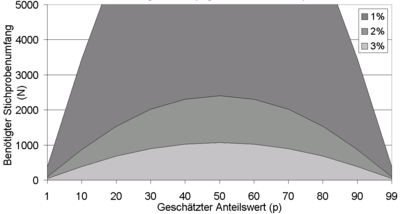 Benötigte Stichprobenumfänge bei einfacher Zufallsauswahl
Benötigte Stichprobenumfänge bei einfacher ZufallsauswahlEine Partei hat in einer Umfrage kurz vor der Wahl 6% erreicht. Welchen Umfang muss eine Wählerbefragung am Wahltag mit
 Sicherheit haben, damit der wahre Anteilswert mit einer Genauigkeit von
Sicherheit haben, damit der wahre Anteilswert mit einer Genauigkeit von  ermittelt werden kann?
ermittelt werden kann? bzw. etwas genauer
bzw. etwas genauer
 .
.
D.h. bei der etwas genaueren Abschätzung des Stichprobenumfanges für den Anteilswert ergibt sich, dass immer noch 2167 Wähler befragt werden müssen, um mit einer Genauigkeit von 1% das Wahlergebnis zu erhalten. Die Grafik rechts zeigt, welche Stichprobenumfänge nötig sind für einen bestimmten geschätzten Anteilswert und eine gegebene Sicherheit.
Beispiel (Werkstoffprüfung)
In der Werkstoffprüfung ist ein Stichprobenumfang von 10 pro 1000 produzierten Teilen durchaus üblich. Er ist u. a. von der Sicherheitsrelevanz des Bauteils oder des Werkstoffes abhängig. Bei den zerstörenden Prüfungen wie zum Beispiel beim Zugversuch wird versucht, den Prüfaufwand und damit die Stichprobe möglichst klein zu halten. Bei der zerstörungsfreien Prüfung – z. B. bei Bildverarbeitungssystemen für die Vollständigkeitsprüfung – wird häufig eine 100%-Kontrolle durchgeführt, um Fehler in der Produktion möglichst schnell zu erkennen.
Mehrstufige Zufallsauswahl (auch Komplexe Zufallsauswahl)
Insbesondere sind folgende Auswahlverfahren von Bedeutung, wobei die ersten beiden als Zweistufige Auswahlverfahren bezeichnet werden:
- Geschichtete Zufallsstichprobe (stratified sample): Die Elemente werden nach einem bestimmten Merkmal in Gruppen (Untermengen) eingeordnet. Innerhalb jeder dieser Gruppen wird dann eine reine Zufalls-Stichprobe gezogen. Hier wird auf mindestens 2 Ebenen gezogen. Beispielsweise werden auf der ersten Stufe Schulklassen nach einem vorher festgelegten Verfahren gezogen. Danach werden auf der zweiten Stufe die Untersuchungsgegenstände (hier Schüler) gezogen. Als Verfahren kommt die reine Zufalls-Stichprobe als auch ein gewichtetes Verfahren in Frage.
- Klumpen-Stichprobe (cluster sample): Zuerst wird eine (relativ kleine) reine Zufalls-Stichprobe gezogen. Danach werden die in den gezogenen Elementen enthaltenen Elemente komplett in die Stichprobe aufgenommen. Ein klassisches Beispiel ist die Befragung ganzer Häuserblocks oder von Schulklassen. Zuerst werden die zu befragenden Schulklassen per Zufallsauswahl bestimmt. Dann werden alle in den Schulklassen enthaltenen Schüler befragt. Bei der Klumpenstichprobe tritt der sogenannte Klumpeneffekt auf. Er ist umso größer, je homogener die Elemente innerhalb der Gruppen und heterogener die Gruppen untereinander sind[5].
- Gestufte Zufallsstichprobe (staged sample): Sie wird häufig aus Gründen der Kostensenkung und Zeitersparnis der Schichtung vorgezogen. Ebenfalls empfiehlt sich die Stufung, wenn eine Auflistung aller Fälle (Untersuchungsgegenstände, Merkmale etc.) der Grundgesamtheit nicht existiert und sich deshalb eine einfach Zufallsstichprobe nicht durchführen lässt (z. B. eine Untersuchung anhand von Texten. Da noch nicht alle Texte elektronisch erfasst bzw. verfügbar sind, entstehen durch das Aufsuchen der jeweiligen Archive hohe Kosten. Durch eine Stufung kann dies vermieden werden). Im Wesentlichen orientiert sich das Vorgehen der Stufung an der Schichtung, indem man:
-
- Stufungskriterien (Merkmale) bestimmt,
- die Grundgesamtheit nach diesen Merkmalen in einander ausschließende Teilgesamtheiten (Primäreinheiten) aufteilt,
- nun eine zufällige Auswahl der Teilgesamtheiten trifft und sich auf eine bestimmte Anzahl von Primäreinheiten begrenzt, die man untersucht. Die restlichen Teilgesamtheiten werden ignoriert.
- Aus den zufällig ausgewählten Primäreinheiten ermittelt man nun die Zufallsstichprobe der Merkmalsträger (Objekte, Individuen, Fälle). Ein Institut will bspw. 500 Personen nach ihrem Konsumverhalten befragen. In Schritt 2 wurde die Grundgesamtheit, z. B. aufgrund geographischer Merkmale, in Ost-, Nord-, Süd- und Westdeutschland aufgeteilt. In Schritt 3 wurde festgelegt, dass das Konsumverhalten in ost- und süddeutschen Supermärkten (Sekundäreinheiten) im Mittelpunkt der Untersuchung steht, sodass in jeder der beiden Regionen 250 Leute (Tertiäreinheiten) befragt werden.
- Die Teilgesamtheiten (der beiden untersuchten Regionen) werden nun zu einer Gesamtstichprobe zusammengefügt.
- Random-Route-Verfahren
Anwendungsmodelle
- ADM-Design als Kombination von Schichtung und Stufung
Literatur
- Behnke, Joachim u. a.: Empirische Methoden der Politikwissenschaft, UTB, Schöningh, Paderborn 2006, ISBN 3-506-99002-0
Einzelnachweise
- ↑ Literary Digest Desaster. Marktforschungs-Wiki, abgerufen am 12. Februar 2011.
- ↑ Diebstahl kostet Handel Milliarden. Der Tagesspiegel, 14. November 2007, abgerufen am 12. Februar 2011.
- ↑ Bernd Rönz, Hans G. Strohe: Lexikon Statistik. Gabler Wirtschaft, 1994, S. 412.
- ↑ Jürgen Janssen, Wilfried Laatz: Statistische Datenanalyse mit SPSS für Windows. 6. Auflage. Springer, 2007, S. 353.
- ↑ Vgl. Eckey,Kosfeld,Türck: Wahrscheinlichkeitsrechnung und Induktive Statistik. Kassel, Gabler, 2005. S. 185
Siehe auch
Kategorien:- Stichprobentheorie
- Empirische Sozialforschung





Wikimedia Foundation.