- Itanium Processor Family
-
 Itanium
ItaniumDer Intel Itanium ist ein 64-Bit-Mikroprozessor, der gemeinsam von Hewlett-Packard und Intel entwickelt wurde. Entwicklungsziel war eine Hochleistungsarchitektur der „Post-RISC-Ära“ unter Verwendung eines abgewandelten VLIW-Designs. Der native Befehlssatz des Itanium ist IA-64. Die Befehle der älteren x86-Prozessoren können nur in einem (sehr langsamen) Firmware-Emulationsmodus ausgeführt werden. Daneben bestehen Erweiterungen zur leichteren Migration von Prozessoren der PA-RISC-Familie.
Inhaltsverzeichnis
Design
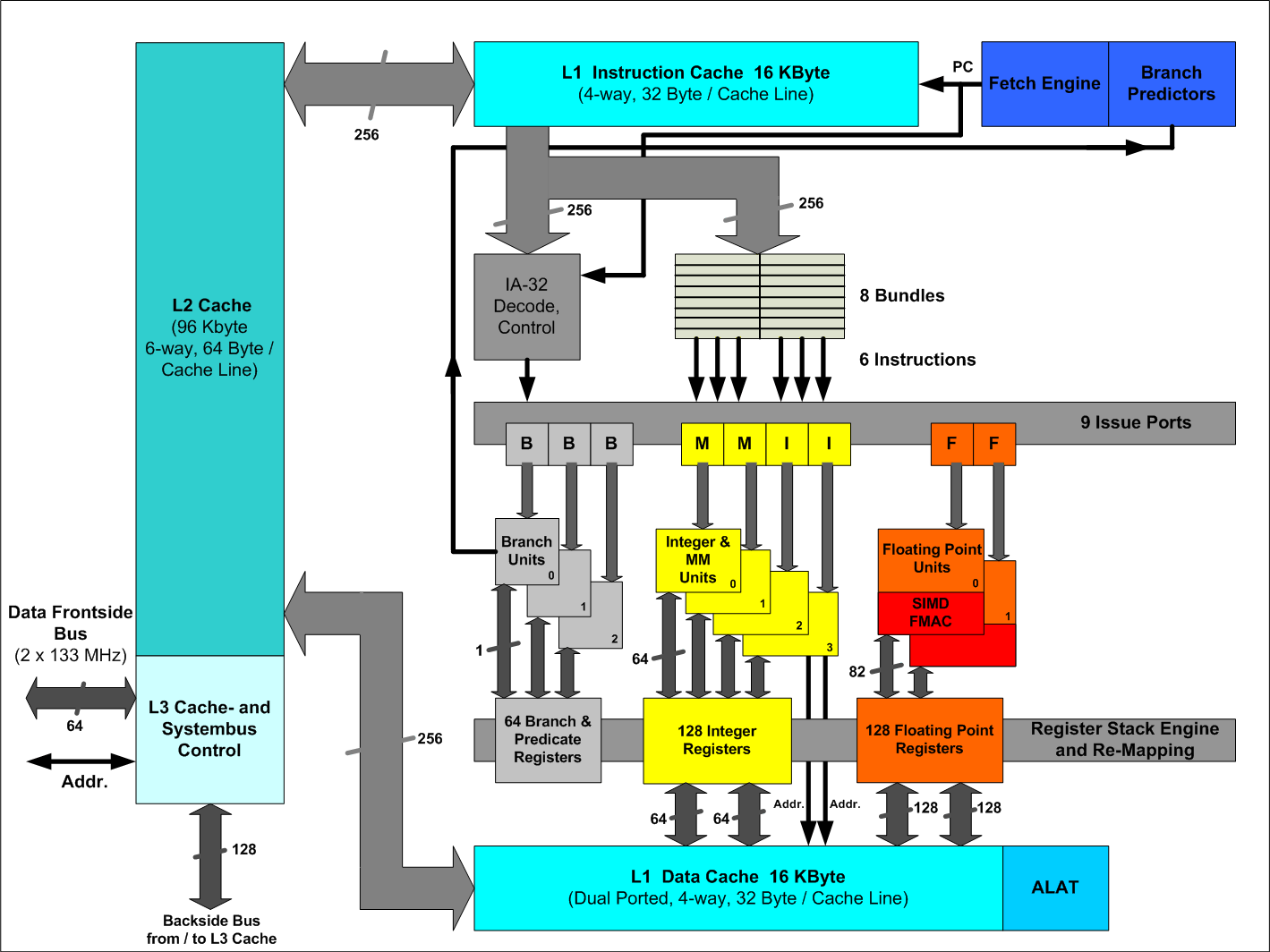
 Architektur des Itanium.
Architektur des Itanium.Die Post-RISC-Architektur des Itanium-Designs nennt sich Explicitly Parallel Instruction Computing (EPIC) und ist eine Variante der VLIW-Architekturen. Die Besonderheit von EPIC besteht darin, dass die CPU ausgewählte Instruktionen paarweise laden und auch zeitgleich ausführen kann – praktisch so, als ob es mehrere völlig unabhängige CPUs gäbe. Die Instruktionen passend parallel ausführbar zusammen zu bündeln ist eine nicht triviale Aufgabe, die hier bereits der Compiler optimal lösen muss. Daher kommt dem Compiler bzw. dessen Optimierungsfähigkeiten eine besonders wichtige Bedeutung zu. Das Design verlagert also einen Teil der Komplexität weg von der CPU und hin zum Compiler. Weiter verwendet die CPU ähnlich wie RISC-Prozessoren nur eine kleine Zahl von Instruktionen, die sehr schnell ausgeführt werden können. Der Itanium verfügt wie die meisten modernen CPUs über mehrere parallele Funktionseinheiten – eine Voraussetzung für EPIC. Beim Laden und der Weitergabe der Instruktionen an die Funktionseinheiten unterscheidet sich der Itanium jedoch von der RISC-Philosophie durch den explizit parallelen Ansatz.
In einem traditionellen, superskalaren Design untersucht eine komplexe Dekodierlogik jede Instruktion vor ihrem Durchlauf durch die Pipeline. Man spricht von dynamischem Scheduling. Es wird geprüft, welche Befehle parallel auf unterschiedlichen Einheiten ausgeführt werden können. Die Instruktionsfolgen
A = B + CundD = E + Fbeeinflussen sich nicht gegenseitig, sie können daher parallelisiert werden.Die Vorhersage, welche Befehle gleichzeitig ausgeführt werden können, ist jedoch oft kompliziert. Die Argumente einer Instruktion hängen vom Resultat einer anderen ab, jedoch nur, wenn auch eine weitere Bedingung wahr ist. Eine leichte Modifikation des obigen Beispiels führt genau auf diesen Fall:
A = B + C; IF A==5 THEN D = E + F. Hier sind die beiden Berechnungen weiter voneinander unabhängig, aber die zweite Befehlsfolge benötigt das Ergebnis der ersten Berechnung, um zu wissen, ob sie überhaupt ausgeführt werden soll.In diesen Fällen versucht eine CPU, die dynamisches Scheduling einsetzt, unter Verwendung verschiedener Methoden das wahrscheinliche Ergebnis der Bedingung vorherzusagen. Moderne CPUs erreichen dabei Trefferquoten von etwa 90 %. In den restlichen 10 % der Fälle muss nicht nur auf das Ergebnis der ersten Berechnung gewartet werden, sondern auch die gesamte bereits vorsortierte Pipeline gelöscht und neu aufgebaut werden. Dies führt dazu, dass etwa 20 % der theoretischen Maximalrechenleistung des Prozessors verloren gehen.
Der Itanium geht das Problem ganz anders an, er verwendet statisches Scheduling, verlässt sich für die Sprungvorhersage also auf den Compiler. Dieser hat einen besseren Überblick über das Programm. Außerdem kann man durch Testläufe ermitteln, welche Sprünge wie oft ausgeführt werden (der GCC bietet dazu beispielsweise die eher esoterischen Funktionen
fprofile-arcsundfbranch-probabilities). Diese Informationen kann der Compiler verwenden, um bereits bei der Übersetzung des Programmcodes die Entscheidungen zu treffen, die sonst auf dem Chip zur Laufzeit getroffen werden müssten. Sobald dem Compiler bekannt ist, welche Pfade genommen werden, bündelt er parallel ausführbare Instruktionen zu einer größeren Instruktion. Diese lange Instruktion wird in das übersetzte Programm geschrieben. Daher der Name VLIW (Very Long Instruction Word, „sehr lange Instruktionen“).Das Problem der effektiven Parallelisierung auf den Compiler zu verlagern hat mehrere Vorteile. Zunächst einmal kann der Compiler wesentlich mehr Zeit damit verbringen, den Code zu untersuchen. Diesen Vorteil hat der Chip nicht, da er so schnell wie möglich fertig sein muss. Zweitens ist die Vorhersage-Kernlogik recht komplex, und durch den neuen Ansatz lässt sich diese Komplexität enorm reduzieren. Der Prozessor muss den Code nicht mehr untersuchen, sondern löst die VLIW-Instruktionen nur noch in kleinere Einheiten auf, die er dann an seine Funktionseinheiten weiter gibt. Der Compiler kann daher so viel Parallelität wie möglich aus dem Programm holen und der Prozessor kann dann entsprechend seinen Fähigkeiten (der Anzahl der parallelen Funktionseinheiten) das Beste daraus machen.
Nachteil der Parallelisierung durch den Compiler ist die Tatsache, dass das Laufzeitverhalten eines Programms nicht notwendigerweise aus seinem Quellcode hervorgeht. Dies bedeutet, dass auch der Compiler „falsch“ entscheiden kann, theoretisch auch häufiger als eine ähnliche Logik auf der CPU. Die CPU hat z. B. noch den Vorteil, dass sie sich in gewissen Grenzen merken kann, welcher Sprung wie oft genommen wurde, was der Compiler ohne Testläufe nicht kann. Das Itanium-Design verlässt sich also stark auf die Leistung des Compilers. Es wird Hardwarekomplexität auf dem Mikroprozessor gegen Softwarekomplexität beim Compiler getauscht.
Programme können während der Ausführung von einem so genannten Profiler untersucht werden, der wiederum Daten über das Laufzeitverhalten der Anwendung sammelt. Diese Informationen können dann ebenfalls in den Compiliervorgang (Feedback-Directed Compilation) einfließen, um so eine bessere Optimierung zu erreichen.
Implementierung
Die Entwicklung der Itanium-Serie begann 1994 und basierte auf Grundlagenforschung seitens der Firma Hewlett-Packard bezüglich der VLIW-Technik. Ergebnis war ein von Grund auf neu entwickelter VLIW-Prozessor ohne Kompromisse, der sich jedoch nicht für den Arbeitseinsatz eignete (und auch nicht dafür vorgesehen war). Nachdem sich Intel an der Entwicklung beteiligte, wurden diesem „sauberen“ Prozessor verschiedene Funktionen hinzugefügt, die für die Vermarktung notwendig waren, insbesondere die Fähigkeit zur Ausführung von IA-32-(x86)-Instruktionen. HP steuerte Fähigkeiten zur Erleichterung der Migration von ihrer Hausarchitektur HP-PA bei.
Ursprünglich sollte der Itanium bereits 1997 erscheinen, seitdem hatte sich der Zeitplan jedoch mehrfach verschoben, bis im Jahr 2001 die erste Version mit dem Codenamen Merced ausgeliefert wurde. Angeboten wurden Geschwindigkeiten von 733 und 800 MHz sowie Cache-Größen von 2 oder 4 MB, die Preise lagen dabei zwischen 1.200 und ca. 4.000 US-Dollar. Die Leistung des neuen Prozessors war aber enttäuschend: Im IA-64-Modus war er nur unwesentlich schneller als ein gleich getakteter x86-Prozessor und wenn er x86-Code ausführen musste, brach die Leistung aufgrund der verwendeten Emulation auf etwa 1/8 der Leistung eines vergleichbaren x86-Prozessors ein. Intel behauptete dann, die ersten Itanium-Versionen seien keine „wirkliche“ Veröffentlichung gewesen.
Das größte (aber nicht einzige) Problem des Itanium ist die hohe Latenzzeit seines L3-Caches, wodurch die tatsächlich nutzbare Cache-Bandbreite stark vermindert wird. Intel war gezwungen, für den nächsten Anlauf den L3-Cache auf dem Die zu integrieren. Gleichzeitig wurden die Latenzen des primären und sekundären Caches bis unter die Werte des Power4-Prozessors von IBM gesenkt, der damals die niedrigsten Latenzzeiten erreichte. Außerdem wurde der Front Side Bus des Itanium von 266 MHz bei 64 Bit auf 400 MHz bei 128 Bit erweitert, so dass sich die Systembandbreite verdreifachte.
Diese Probleme wurden mit dem Nachfolger McKinley, der als Itanium 2 auf den Markt kam, behoben oder zumindest abgemildert.
Probleme
Schon kurz nach der offiziellen Vorstellung des Namens am 4. Oktober 1999 [1] wurde der Spitzname Itanic [2] geprägt, der den Namen der Titanic aufgriff und somit den neuen Prozessor mit dem als „unsinkbar“ geltenden Schnelldampfer verglich, der auf seiner Jungfernfahrt mit einem Eisberg kollidierte und versank.
Obwohl es verschiedene Bemühungen gab, die Ausführungsgeschwindigkeit von x86-Code zu steigern, bleibt der Itanium für diesen Zweck im Allgemeinen zu langsam. Die Relevanz dieser Fähigkeit ist umstritten, da die meisten Kunden keine Itanium-Systeme kaufen, um darauf x86-Code auszuführen. Trotzdem plant Intel, die Emulationseinheit für x86-Code durch eine von Digitals FX!32 für den Alpha-Prozessor inspirierte Softwarelösung zu ersetzen. Man erhofft sich davon schnellere Ausführung und verringerte Chip-Komplexität. Software-Prozessoremulation hat ihre Vorbilder im Bereich Enterprise-Computing, wo sie z. B. auf der VAX oder der S/390 zum Einsatz kommt.
Aufgrund der jüngsten Itanium-Entwicklungen sollen HPs Alpha-Prozessor und die PA-RISC-Architektur auslaufen (Support wird ab 2007 für noch etwa fünf Jahre gewährt), SGI hat seine MIPS-basierten Workstations inzwischen zugunsten des Itaniums eingestellt.
Einzelnachweise
- ↑ Kanellos, Michael (October 4, 1999). Intel names Merced chip Itanium. CNET News.com. Abgerufen am 30. April 2007.
- ↑ Finstad, Kraig (October 4, 1999, 3:00 a.m.). Re:Itanium. USENET group comp.sys.mac.advocacy. Abgerufen am 24. März 2007.
Siehe auch
Weblinks
- cpu-collection.de Bilder eines zerlegten Itanium-Moduls auf cpu-collection.de

Non-x86-Prozessoren: 4004 | 4040 | 8008 | 8080 | 8085 | iAPX 432 | i860 | i960 | Itanium | Itanium 2
Bis 4. Generation: 8086 | 8088 | 80186 | 80188 | 80286 | i386 | i486DX | i486DX2 | DX4 | i486GX | i486SL/SL-NM | i486SX | i486SX2
Pentium-Serie: Desktop: Pentium (MMX) | Pentium II | Pentium III | Pentium 4 | Pentium 4 XE | Pentium D | Pentium XE | Pentium Dual-Core
Mobil: Mobile Pentium 4 | Pentium M | Pentium Dual-Core Server: Pentium Pro
Celeron-Serie: Desktop: Celeron (P6) | Celeron (NetBurst) | Celeron D | Celeron (Core) | Celeron Dual-Core Mobil: Mobile Celeron | Celeron M
Core-Serie: Desktop: Core 2 Duo | Core 2 Quad | Core 2 Extreme Mobil: Core Solo | Core Duo | Core 2 Solo | Core 2 Duo | Core 2 Extreme
Nehalem-Serie: Core i5 | Core i7
Xeon-Serie: Server: Xeon (P6) | Xeon (NetBurst) | Xeon (Core)

Wikimedia Foundation.