- Kernel density estimation
-
Die Kerndichteschätzung (auch Parzen-Methode[1], englisch: Kernel Density Estimation, KDE) ist ein Verfahren zur Darstellung einer eindimensionalen Verteilung.
In der klassischen Statistik geht man davon aus, dass statistische Phänomene einer bestimmten Wahrscheinlichkeitsverteilung folgen und dass sich diese Verteilung in Stichproben realisiert. In der nichtparametrischen Statistik werden Verfahren entwickelt, um aus der Realisation einer Stichprobe die zu Grunde liegende Verteilung zu identifizieren. Ein bekanntes Verfahren ist die Erstellung eines Histogramms. Nachteil dieses Verfahrens ist, dass das resultierende Histogramm nicht stetig ist. Vielfach ist aber davon auszugehen, dass die zu Grunde liegende Verteilung als stetig betrachtet werden kann. So etwa die Verteilung von Wartezeiten in einer Schlange oder die Rendite von Aktien.
Der im folgenden beschriebene Kerndichteschätzer ist dagegen ein Verfahren, das eine stetige Schätzung der unbekannten Verteilung ermöglicht. Genauer: die Kerndichteschätzung ist ein gleichmäßig konsistenter, stetiger Schätzer der Lebesgue-Dichte eines unbekannten Wahrscheinlichkeitsmaßes durch eine Folge von Dichten.
Inhaltsverzeichnis
Beispiel
 Kerndichteschätzung
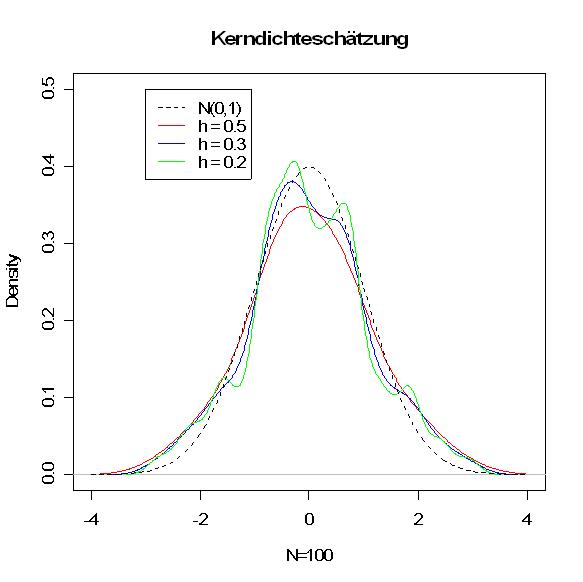
KerndichteschätzungIm folgenden Beispiel wird die Dichte einer Standardnormalverteilung (schwarz gestrichelt) durch Kerndichteschätzung geschätzt. In der konkreten Situation des Schätzens ist diese Kurve natürlich unbekannt und soll durch die Kerndichteschätzung geschätzt werden. Es wurde eine Stichprobe (vom Umfang 100) generiert, die gemäß dieser Standardnormalverteilung verteilt ist. Mit verschiedenen Bandbreiten h wurde dann eine Kerndichteschätzung durchgeführt. Man sieht deutlich, dass die Qualität des Kerndichteschätzers von der gewählten Bandbreite abhängt. Eine zu kleine Bandbreite erscheint "verwackelt", während eine zu große Bandbreite zu "grob" ist.
Kerne
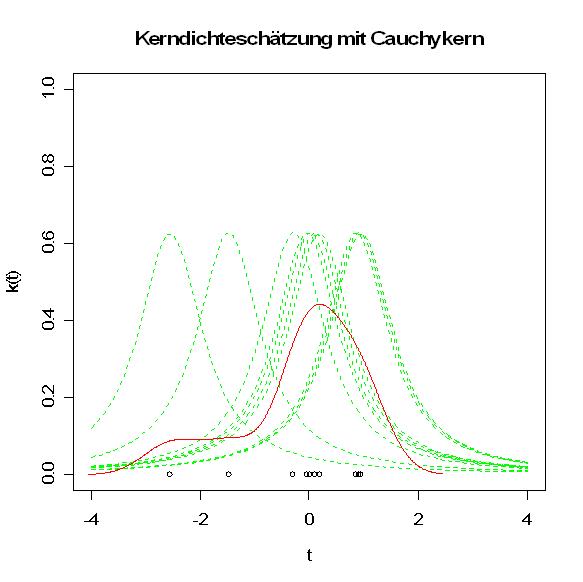
 Kerndichteschätzung mit Cauchykern
Kerndichteschätzung mit CauchykernMit Kern wird die stetige Lebesgue-Dichte k eines fast beliebig zu wählenden Wahrscheinlichkeitsmaßes K bezeichnet. Mögliche Kerne sind etwa:
- Gaußkern
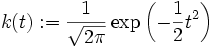
- Cauchy-Kern
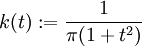
- Picard-Kern
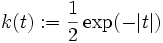
Diese Kerne sind Dichten von ähnlicher Gestalt wie der abgebildete Cauchykern. Der Kerndichteschätzer stellt eine Überlagerung in Form der Summe entsprechend skalierter Kerne dar, die abhängig von der Stichprobenrealisation positioniert werden. Die Skalierung und ein Vorfaktor gewährleisten, dass die resultierende Summe wiederum die Dichte eines Wahrscheinlichkeitsmaßes darstellt. Der folgenden Abbildung wurde eine Stichprobe vom Umfang 10 zu Grunde gelegt, die als schwarze Kreise dargestellt ist. Darüber sind die Cauchykerne (grün gestrichelt) dargestellt, aus deren Überlagerung der Kerndichteschätzer resultiert (rote Kurve).
Der Epanechnikov-Kern ist dabei derjenige Kern, der unter allen Kernen die mittlere quadratische Abweichung des zugehörigen Kerndichteschätzers minimiert.
Der Kerndichteschätzer
Ist
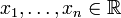 eine Stichprobe, k ein Kern, so wird der Kerndichteschätzer zur Bandbreite h > 0 definiert als:
eine Stichprobe, k ein Kern, so wird der Kerndichteschätzer zur Bandbreite h > 0 definiert als: 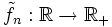 ,
, 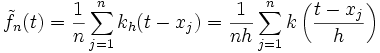 .
.Die Wahl der Bandbreite h ist entscheidend für die Qualität der Approximation. Mit entsprechender, in Abhängigkeit vom Stichprobenumfang gewählter Bandbreite konvergiert die Folge
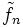 der Kerndichteschätzer fast sicher gleichmäßig gegen die Dichte des unbekannten Wahrscheinlichkeitsmaßes. Diese Aussage wird im folgenden Satz von Nadaraja konkretisiert.
der Kerndichteschätzer fast sicher gleichmäßig gegen die Dichte des unbekannten Wahrscheinlichkeitsmaßes. Diese Aussage wird im folgenden Satz von Nadaraja konkretisiert.Satz von Nadaraja
Der Satz liefert die Aussage, dass mit entsprechend gewählter Bandbreite eine beliebig gute Schätzung der unbekannten Verteilung durch Wahl einer entsprechend großen Stichprobe möglich ist.
Sei k ein Kern von beschränkter Variation. Die Dichte f eines Wahrscheinlichkeitsmaßes sei gleichmäßig stetig. Mit
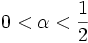 und c > 0 seien für
und c > 0 seien für 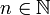 die Bandbreiten
die Bandbreiten 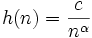 definiert. Dann konvergiert die Folge der Kerndichteschätzer
definiert. Dann konvergiert die Folge der Kerndichteschätzer  mit Wahrscheinlichkeit 1 gleichmäßig gegen f, d. h.
mit Wahrscheinlichkeit 1 gleichmäßig gegen f, d. h. 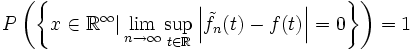
Siehe auch
Schätzfunktion, Histogramm, Empirische Verteilungsfunktion, Stichprobe, Dichteschätzer
Einzelnachweise
- ↑ Parzen E. (1962). On estimation of a probability density function and mode, Ann. Math. Stat. 33, pp. 1065-1076.
- Gaußkern

Wikimedia Foundation.