- Lexik
-
Als Wortschatz (auch Vokabular oder Lexik(on)) bezeichnet man
- die Gesamtheit aller Wörter einer Sprache zu einem bestimmten Zeitpunkt.
- die Gesamtheit aller Wörter einer Sprache, die ein einzelner Sprecher kennt oder verwendet. Man unterscheidet in dieser Bedeutung zwischen passivem (präziser: rezeptivem) und aktivem (präziser: produktivem) Wortschatz.
-
- Der rezeptive Wortschatz (passiver Wortschatz) wird vom Sinn her verstanden, wird jedoch nicht aktiv verwendet. Er ist jener, der meist nur zum Verstehen gesprochener und geschriebener Texte beiträgt, also eher als Verstehenswortschatz bezeichnet werden kann, der im entscheidenden Augenblick als bekannt aus dem Gedächtnis abgerufen oder über andere Wege (z. B. Wortbildung) erschlossen wird.
-
- Der produktive Wortschatz (aktiver Wortschatz) wird auch beim Sprechen benutzt, seine Einsatzmöglichkeiten sind so weit bekannt, dass sinnvolle verständliche Sätze damit geformt werden können.
Inhaltsverzeichnis
Deutscher Wortschatz
Der Wortschatz der deutschen Standardsprache umfasst ca. 75.000 Wörter,[1] die Gesamtgröße des deutschen Wortschatzes wird je nach Quelle und Zählweise auf 300.000 bis 500.000 Wörter bzw. Lexeme geschätzt. So gibt Duden. Deutsches Universalwörterbuch an, der Wortschatz der Alltagssprache werde auf etwa 500.000, der zentrale Wortschatz auf rund 70.000 Wörter geschätzt. [2] Das Deutsche Wörterbuch von Jacob und Wilhelm Grimm (1852-1960) wird auf ca. 350.000 Stichwörter geschätzt; Wahrig (2008) gibt im abgedruckten Vorwort zur Neuausgabe 2006 an, dieses einbändige Wörterbuch enthalte über 260.000 Stichwörter. [3]. Solche Angaben geben Aufschluss darüber, als wie groß der deutsche Wortschatz mindestens geschätzt werden muss. Diese Wörterbücher enthalten jedoch nur geringe Anteile der vielen Fachwortschätze und sind auch insofern unvollständig, als Ableitungen und Komposita nur teilweise aufgenommen werden und die neuesten Neubildungen naturgemäß fehlen. Ein entscheidendes Kriterium für die Aufnahme von Wörtern ist ihre Verwendungshäufigkeit/ Gebräuchlichkeit; ausgeschlossen werden solche Wörter, die aus einfachen zusammengesetzt sind und sich bei Kenntnis ihrer Bestandteile von selbst verstehen lassen. [4] Damit ist klar, dass der Wortschatz insgesamt noch wesentlich größer sein muss; die Angabe von 500.000 Wörtern ist kaum übertrieben. Nimmt man Fachwortschatz hinzu, ist mit mehreren Millionen Wörtern zu rechnen. Allein die Fachsprache der Chemie enthält nach Winter (1986) rund 20 Millionen Benennungen. [5]
Zum Wortschatzumfang einzelner Personen und Texte
Die Schätzungen zur Wortschatzkenntnis einzelner Personen gehen weit auseinander. Als handfeste Zahl kann man die Angaben zum aktiven, d.h. in seinen Werken nachweisbaren Wortschatz bei Goethe ansehen, der im 3. Band des Goethewörterbuchs auf ca. 90.000 Wörter beziffert wird. [6] Da nur wenige Menschen ein so reichhaltiges Werk geschaffen haben, dürfte diese Angabe zumindest in ihrer Dimension etwa die Obergrenze benennen. Allerdings ist dabei der passive Wortschatz noch nicht berücksichtigt: Goethe wird ja das eine oder andere Wort gekannt haben, das sich aber nicht in seinen Werken findet.
In etwa gilt: Je höher der Bildungsstand eines Menschen ist, desto größer ist sein Wortschatz. Ein größerer Wortschatz hilft beim differenzierteren Informationsaustausch. „Ein einfacher Bürger kommt im täglichen Leben mit wenigen tausend Wörtern aus. Der Wortschatz einer Person ist abhängig vom Interessensgebiet und Berufsfeld (Fachterminologie) sowie der Sozialisation dieser Person. Ein Gebildeter, beispielsweise ein Gelehrter oder Schriftsteller, kann mehrere zehntausend Wörter benutzen (aktiver Wortschatz) und sehr viel mehr verstehen, wenn sie ihm begegnen (passiver Wortschatz).“ [7]. Der Wortschatz von 15Jährigen wurde in einschlägigen Untersuchungen bereits auf rund 12.000 Wörter beziffert. [8] Die Schätzungen für den Umfang des Wortschatzes eines erwachsenen Muttersprachlers reichen von 3.000 bis 216.000 Wörtern. [9] Die teilweise sehr markanten Unterschiede in den Schätzungen des Wortschatzumfanges erklären sich durch unterschiedliche, für diese Schätzungen angewandte Methoden. Somit ist die Bestimmung des Wortschatzumfanges vornehmlich ein methodologisches Problem. Prinzipiell stehen für die Schätzung zwei unterschiedliche Methoden zur Verfügung: eine qualitative und eine quantitative. Die qualitative Methode untersucht die Art der vorzufindenden Wörter, während die quantitative Methode das Type-Token-Verhältnis bestimmt, also misst, wie häufig unterschiedliche Wörter vorkommen.
Einige Daten zum Wortschatz einzelner Texte oder Textgruppen im Deutschen findet man bei Billmeier (1969: 35). Hier ist zu erfahren, dass man im Jahr 1964 über 4.000 Wörter (im Sinne von Lexem = Stichwörter im Wörterbuch) beherrschen musste, um auch nur einen Auszug der Zeitung Die Welt in den Monaten Januar und Februar lesen zu können, eine der in dieser Hinsicht anspruchsloseren Lektüren. Für E. Strittmatters Roman Ole Bienkopp ist schon die Kenntnis von über 18.000 Lexemen vonnöten. [10]
Ein methodologisches Problem entsteht, wenn Texte unterschiedlicher Länge auf ihren Wortschatzreichtum hin untersucht werden sollen (wobei als "Text" auch Wortschatztests interpretiert werden können, die entworfen wurden, um den Wortschatz eines Probanden zu messen). Für die Messung des Wortschatzreichtums ist der Index von Guiraud ein häufig verwendetes Maß. Der Index berechnet sich wie folgt:
Ziel des Index ist es, Aussagen über den Wortschatzreichtum unterschiedlich langer Texte zu ermöglichen. Nimmt man als "Text" etwa die Ergebnisse vorher durchgeführter C-Tests her, lässt sich der Index von Guiraud als Maß für den Wortschatzumfang von Individuen einsetzen. Wie der Index wirkt, lässt sich nachvollziehen, wenn man annimmt, die Zahl der Types sei mit der Zahl der Tokens identisch - d.h., in einem Text würde sich kein Wort wiederholen. Als Index von Guiraud ergibt sich dann:
Der zugehörige Graph entspricht einer liegenden Parabel. Für sehr hohe X-Werte, also bei langen Texten, nähert sich die Parabel einer Geraden. Daher ergibt sich für unterschiedlich lange Texte mit gleichem Type-Token-Verhältnis auch ein annähernd gleicher Wert für G. Bei kürzeren Texten ist mit Verzerrungen zu rechnen: hier resultieren unterschiedliche G-Werte auch aus einem konstanten Type-Token-Verhältnis. Diese unterschiedlichen Werte sind dann allerdings allein durch die Formel bedingt. Der G-Wert ist also bei kürzeren Texten nicht nur vom Wortschatzreichtum, sondern auch von der Textlänge abhängig.[11]
Wortschatz in anderen Sprachen
Dazu führt Wolff (1969: 48) aus: „Neuere Schätzungen geben für den englischen Wortschatz eine Zahl von 500.000 bis 600.000 Wörtern an, der deutsche liegt knapp darunter, der französische bei etwa 300.000 Wörtern.“ [12] Man darf daraus nicht schließen, das Französische sei eine wortarme Sprache. Der Unterschied ist in erheblichem Maße auf die unterschiedliche Art der Wortbildung zurückzuführen: Dem deutschen Wort „Kartoffelbrei“ (1 neues Wort) entspricht im Französischen „purée de pommes de terre“ (eine Wortgruppe, bestehend aus 5 Wörtern). In Wörterbüchern der estnischen Literatursprache werden im 20. Jahrhundert um 120.000 Wörter aufgeführt. [13]
Wortschatz und Wortformen
Zum Vergleich: Der Rechtschreib-Duden enthält nach eigenen Angaben ca. 120.000 Stichwörter. [14] Durch Flexion kann in flektierenden Sprachen aus vielen dieser relativ wenigen Grundformen ein mehrfaches an Wortformen entstehen, im Deutschen zum Beispiel erheblich mehr als in dem die Flexion langsam verlierenden Englischen. Die Häufigkeitsverteilung von Wörtern lässt sich mit dem Zipfschen Gesetz beschreiben.
Wortschatzerweiterung und -verlust
Der Wortschatz einer Sprache ist keine statische Größe; er ist vielmehr in ständiger Veränderung begriffen. Einerseits gehen Bezeichnungen für Gegenstände verloren, die allmählich außer Gebrauch geraten. So wird wohl der Ausdruck Rechenschieber mit der Zeit verschwinden, da die Leistung des so bezeichneten Geräts heute von Taschenrechner und Computer übernommen wird. Oft werden auch Gegenstände auf Kosten der alten Bezeichnung neu benannt, wie dies mit der Ersetzung von Elektronengehirn durch Computer geschehen ist. [15]. Andererseits müssen immer wieder neue Gegenstände benannt werden, was mit Hilfe der Wortbildung oder der Übernahme von Fremdwörtern bewältigt wird. Diese Prozesse des Verlusts oder der Zunahme von Wörtern unterliegen einem Sprachgesetz, dem Piotrowski-Gesetz. [16]
Erwerb des muttersprachlichen Wortschatzes
Wir Menschen lernen unsere Muttersprache zunächst durch Imitation; wir ahmen die Ausdrucksweise und die Aussprache unseres sozialen Milieus nach. Das ist nicht nur in den Kinderjahren, sondern auch noch im Erwachsenenalter der Fall. Das heißt, dass sich sowohl unser Wortschatz als auch unsere Aussprache, unser Dialekt, falls wir einen besitzen, unserem sozialen Milieu anpasst.
Allerdings kann Imitation nicht allein verantwortlich sein für den Spracherwerb, da gerade Kinder regelmäßig mit etwa drei Jahren eine Phase der Übergeneralisierung durchlaufen, in der sie nie gehörte Verbformen wie „gingte“, „gangte“, „is gegeht“ usw. bilden, also Analogien bilden. [17]
Die Spracherwerbs-Prozesse laufen, soweit das bisher zu überblicken ist, gesetzmäßig ab und folgen offenkundig dem Spracherwerbsgesetz, wie mehrfach gezeigt werden konnte. [18]
Wege zur Vergrößerung des Wortschatzes
- Gegenbegriffe (Antonyme) und Synonyme finden
- Viel lesen und schreiben (z. B. Aufsätze)
- Bücher und Artikel aus verschiedenen Themengebieten lesen
- Bücher mit hohem Sprachniveau lesen
- Unbekannte Wörter in Lexika oder Wörterbüchern nachschlagen oder die Bedeutung aus dem Kontext entnehmen
- Kommunizieren jeglicher Art
- Das bewusste Streben, sich immer möglichst präzise und vielfältig auszudrücken
- In Gesprächen den Mut haben, den Gesprächspartner nach der Bedeutung eines unbekannten Wortes zu fragen
- Buchstabenspiele wie Scrabble oder Kreuzworträtsel
Literatur
- Karl-Heinz Best: Unser Wortschatz. Sprachstatistische Untersuchungen. In: Rudolf Hoberg & Karin Eichhoff-Cyrus (Hrsg.), Die deutsche Sprache zur Jahrtausendwende. Sprachkultur oder Sprachverfall?. Dudenverlag, Mannheim/ Leipzig/ Wien/ Zürich 2000, S. 35-52. ISBN 3-411-70601-5.
- Karl-Heinz Best: Quantitative Linguistik. Eine Annäherung. 3., stark überarb. u. ergänzte Aufl. Peust & Gutschmidt, Göttingen 2006, ISBN 3-933043-17-4. (Bes. die Abschnitte Wie viel Wörter hat das Deutsche? Und Der Wortschatz des Einzelnen, S. 13-21.)
- Duden. Das große Wörterbuch der deutschen Sprache. 10 Bände. Dudenverlag, Mannheim/ Leipzig/ Wien/ Zürich 1999. ISBN 3-411-04743-7 (für Bd. 1)
- Ulrike Haß-Zumkehr: Deutsche Wörterbücher. de Gruyter, Berlin, New York 2001. ISBN 3-11-014885-4 (Bes. Kap. 17: Wie viele Wörter hat die deutsche Sprache? S. 381-385.)
- Elisabeth Knipf-Komlósi, Roberta Rada, Bernáth Csilla: Aspekte des deutschen Wortschatzes. Bölcsész Konzorcium, Budapest 2006, ISBN 963-9704-33-4 (Volltext als PDF)
- Dieter Wolff: Statistische Untersuchungen zum Wortschatz englischer Zeitungen. Saarbrücken, diss. phil. 1969.
Einzelnachweise
- ↑ Dornseiff nennt im Vorwort zur 1. Auflage (1933) „30000 bis 100000 Wörter, die in einer Kultursprache gesprochen und geschrieben werden“ (Franz Dornseiff: Der deutsche Wortschatz nach Sachgruppen. 5. Auflage. de Gruyter, Berlin 1959, S. 7), was etwa den Angaben zum zentralen Wortschatz entspricht.
- ↑ Duden. Deutsches Universalwörterbuch. 6., überarbeitete und erweiterte Auflage. Dudenverlag, Mannheim/Leipzig/Wien/Zürich 2007, S. 13. ISBN 3-411-05506-5
- ↑ Wahrig, Deutsches Wörterbuch. Hrsg. von Renate Wahrig-Burfeind. Bertelsmann Lexikon Institut, Gütersloh/ München 2008. ISBN 978-3-577-10241-4
- ↑ So Wahrig (2008), S. 9.
- ↑ Horst Winter: Benennungsmotive für chemische Stoffnamen. In: Special Language/ Fachsprache 8, 1986, 155-162.
- ↑ So in den Hinweisen für Benutzer in: Goethe-Wörterbuch Bd. III: Hrsg. von der Berlin-Brandenburgischen Akademie der Wissenschaften, der Akademie der Wissenschaften in Göttingen und der Heidelberger Akademie der Wissenschaften. Stuttgart/ Berlin/ Köln/ Mainz: Kohlhammer 1998.
- ↑ Hans Joachim Störig: Abenteuer Sprache. Ein Streifzug durch die Sprachen der Erde. 2., überarbeitete Aufl. München: Humboldt-Taschenbuchverlag 1997, S. 207. ISBN 3-581-66936-6
- ↑ Karl-Heinz Best: LinK. Linguistik in Kürze mit einem Ausblick auf die Quantitative Linguistik. Skript.. 5., durchgesehene Auflage. RAM-Verlag, Lüdenscheid 2008, S. 124.
- ↑ Rubin Goulden, Paul Nation, John Read: How Large Can A Receptive Vocabulary Be?. In: Applied Linguistics Jg. 11, Heft 4. 341 - 363.
- ↑ Günther Billmeier: Worthäufigkeitsverteilungen vom Zipfschen Typ, überprüft an deutschem Textmaterial. Hamburg: Buske 1969. Weitere derartige Informationen sind in Ju. K. Orlov: Ein Modell der Häufigkeitsstruktur des Vokabulars. In: Ju. K. Orlov, M.G. Boroda, & I. Nadareijšvili: Sprache, Text, Kunst. Quantitative Analysen. Bochum: Brockmeyer 1982, S. 118-192. ISBN 3-88339-243-X und in einer kleinen Übersicht speziell zum Deutschen in Karl-Heinz Best: LinK. Linguistik in Kürze mit einem Ausblick auf die Quantitative Linguistik. Skript.. 5., durchgesehene Auflage. RAM-Verlag, Lüdenscheid 2008, S. 135f. zu finden.
- ↑ Helmut Daller: Migration und Mehrsprachigkeit. Frankfurt am Main: Peter Lang. ISBN 3-631-34559-3. S. 121f.
- ↑ Dieter Wolff: Statistische Untersuchungen zum Wortschatz englischer Zeitungen. Saarbrücken, diss. phil. 1969.
- ↑ Juhan Tuldava: Probleme und Methoden der quantitativ-systemischen Lexikologie. Wissenschaftlicher Verlag Trier, Trier 1998 (russ. 1987), S. 137. ISBN 3-88476-314-8
- ↑ Angabe auf dem Buchumschlag von Duden. Die deutsche Rechtschreibung. 22., völlig neu bearbeitete und erweiterte Auflage. Dudenverlag, Mannheim, Leipzig, Wien, Zürich 2000. ISBN 3-411-04012-2
- ↑ Best 2008, 118; weitere Beispiele für Wortschatzverlust in Best 2006, S. 14, 117
- ↑ Zum Wachstum des englischen Wortschatzes: Karl-Heinz Best: Quantitative Linguistik. Eine Annäherung. 3., stark überarb. u. ergänzte Aufl. Peust & Gutschmidt, Göttingen 2006, S. 114-116; ISBN 3-933043-17-4; zum Estnischen: Karl-Heinz Best: Spracherwerb, Sprachwandel und Wortschatzwachstum in Texten. Zur Reichweite des Piotrowski-Gesetzes. In: Glottometrics 6, 2003, S. 9-34, zum Estnischen S. 20f.
- ↑ vgl. Mills 1985 in Spada, 2006, S. 279.
- ↑ Best, Karl-Heinz: Zur Entwicklung von Wortschatz und Redefähigkeit bei Kindern. In: Göttinger Beiträge zur Sprachwissenschaft 9, 2003, 7-20; Best, Karl-Heinz: Gesetzmäßigkeiten im Erstspracherwerb. In: Glottometrics 12, 2006, 39-54.
Siehe auch
- Lexikologie
- Korpuslinguistik
- Terminologie
- Wörterbuch
- Basiswortschatz
- Basic English
- Sprache des Nationalsozialismus
- Unwort bzw. Wort des Jahres
Weblinks
- wortschatz.uni-leipzig.de: Umfangreichste Sammlung des Deutschen Wortschatzes. Automatische Relationsanalyse des Deutschen Wortschatzes mit 9 Mio. Einträgen
- Liste der Bedrohten Wörter – so zu sagen vom Aussterben bedrohte Wörter
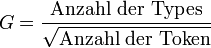
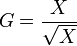
Wikimedia Foundation.