- Maximum Likelihood-Schätzung
-
Die Maximum-Likelihood-Methode (von engl. maximale Wahrscheinlichkeit) bezeichnet in der Statistik ein parametrisches Schätzverfahren.
Inhaltsverzeichnis
Motivation
Einfach gesprochen bedeutet die Maximum-Likelihood-Methode folgendes: Wenn man statistische Untersuchungen durchführt, untersucht man in der Regel eine Stichprobe mit einer bestimmten Anzahl von Objekten einer Population. Da die Untersuchung der gesamten Population in den meisten Fällen hinsichtlich der Kosten und des Aufwandes unmöglich ist, sind die wichtigen Kennwerte der Population unbekannt. Solche Kennwerte sind z. B. der Erwartungswert oder die Standardabweichung. Da man diese Kennwerte jedoch zu den statistischen Rechnungen, die man durchführen möchte, benötigt, muss man die unbekannten Kennwerte der gesamten Population anhand der bekannten Stichprobe schätzen.
Die Maximum-Likelihood-Methode wird nun in Situationen benutzt, in denen die Elemente der Population als Realisierung eines Zufallsexperiments interpretiert werden können, das von einem unbekannten Parameter abhängt, bis auf diesen aber eindeutig bestimmt und bekannt ist. Entsprechend hängen die interessanten Kennwerte ausschließlich von diesem unbekannten Parameter ab, lassen sich also als Funktion von ihm darstellen. Als Maximum-Likelihood-Schätzer wird nun derjenige Parameter bezeichnet, der die Wahrscheinlichkeit, die Stichprobe zu erhalten, maximiert.
Die Maximum-Likelihood-Methode ist aufgrund ihrer Vorteile gegenüber anderen Schätzverfahren (beispielsweise Kleinste-Quadrate- und Momentenmethode) das wichtigste Prinzip zur Gewinnung von Schätzfunktionen für die Parameter einer Verteilung.
Eine heuristische Herleitung
Es wird nun folgendes Beispiel betrachtet: Es gibt eine Urne mit einer großen Anzahl von Kugeln, die entweder schwarz oder rot sind. Da die Untersuchung aller Kugeln praktisch unmöglich erscheint, wird eine Stichprobe von zehn Kugeln gezogen. In dieser Stichprobe seien nun eine rote und neun schwarze Kugeln. Ausgehend von dieser einen Stichprobe soll nun die wahre Wahrscheinlichkeit, eine rote Kugel in der Gesamtpopulation (Urne) zu ziehen, geschätzt werden.
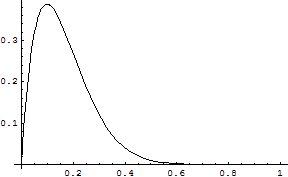 Verlauf der Kurve für f(p)=B(10;1,p)
Verlauf der Kurve für f(p)=B(10;1,p)Die Maximum-Likelihood-Methode versucht diese Schätzung nun so zu erstellen, dass das Ergebnis unserer Stichprobe damit am wahrscheinlichsten wird. Dazu könnte man „herumprobieren“, bei welchem Schätzer die Wahrscheinlichkeit für unser Stichprobenergebnis maximal wird.
„Probiert“ man beispielsweise 0,2 als Schätzer für die Wahrscheinlichkeit einer roten Kugel, so kann man mit Hilfe der Binomialverteilung B(10|1, 0,2) die Wahrscheinlichkeit des beobachteten Ergebnisses (eine rote Kugel) berechnen - das Ergebnis ist 0,2684.
„Probiert“ man es mit 0,1 als Schätzer, berechnet also B(10|1, 0,1) für den Fall, dass eine rote Kugel gezogen wird, ist das Ergebnis 0,3874. Die Wahrscheinlichkeit, dass das beobachtete Ergebnis (1x rot, 9x schwarz) in der Stichprobe durch eine Populationswahrscheinlichkeit für rote Kugeln von 0,1 verursacht wurde, ist also größer als bei 0,2 als geschätzte Wahrscheinlichkeit. Damit wäre nach der Maximum-Likelihood-Methode 0,1 ein besserer Schätzer für den Anteil roter Kugeln in der Population.Definition
Bei der Maximum-Likelihood-Methode wird von einer Zufallsvariablen
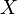 ausgegangen, deren Dichte- bzw. Wahrscheinlichkeitsfunktion
ausgegangen, deren Dichte- bzw. Wahrscheinlichkeitsfunktion 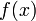 von einem Parameter
von einem Parameter 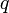 abhängt. Liegt eine einfache Zufallsstichprobe mit
abhängt. Liegt eine einfache Zufallsstichprobe mit 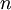 unabhängigen und identisch verteilten Realisationen vor, so lässt sich die Dichtefunktion bzw. Wahrscheinlichkeitsfunktion wie folgt faktorisieren:
unabhängigen und identisch verteilten Realisationen vor, so lässt sich die Dichtefunktion bzw. Wahrscheinlichkeitsfunktion wie folgt faktorisieren:Statt nun für einen festen Parameter
die Dichte für beliebige Werte 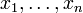 auszuwerten, kann umgekehrt für beobachtete und somit feste Realisationen die Dichte als Funktion von betrachtet werden. Dies führt zur Likelihood-Funktion
auszuwerten, kann umgekehrt für beobachtete und somit feste Realisationen die Dichte als Funktion von betrachtet werden. Dies führt zur Likelihood-FunktionWird diese Funktion in Abhängigkeit von
maximiert, so erhält man die Maximum-Likelihood-Schätzung für . Es wird also der Wert von gesucht, bei dem die Stichprobenwerte die größte Dichte- bzw. Wahrscheinlichkeitsfunktion haben. Der Maximum-Likelihood-Schätzer ist in diesem Sinne der plausibelste Parameterwert für die Realisierungen der Zufallsvariablen . Die Maximierung dieser Funktion erfolgt, indem man die erste Ableitung nach bildet und diese dann Null setzt. Da dieses bei Dichtefunktionen mit komplizierten Exponentenausdrücken sehr aufwändig werden kann, wird häufig die logarithmierte Likelihood-Funktion verwendet, da sie an derselben Stelle wie die nicht-logarithmierte Dichtefunktion ein Maximum besitzt, jedoch einfacher zu berechnen ist:Beispiel
Diskrete Verteilung, endlicher Parameterraum
Eine Urne enthält
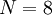 Kugeln, die entweder rot oder schwarz sind. Die genaue Anzahl
Kugeln, die entweder rot oder schwarz sind. Die genaue Anzahl 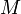 der roten Kugeln ist nicht bekannt. Nacheinander werden
der roten Kugeln ist nicht bekannt. Nacheinander werden 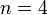 Kugeln gezogen und jeweils wieder zurück in die Urne gelegt. Beobachtet werden
Kugeln gezogen und jeweils wieder zurück in die Urne gelegt. Beobachtet werden 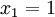 (erste Kugel ist rot),
(erste Kugel ist rot), 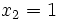 (zweite Kugel ist rot),
(zweite Kugel ist rot), 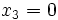 (dritte Kugel ist schwarz) und
(dritte Kugel ist schwarz) und 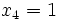 (vierte Kugel ist rot).
(vierte Kugel ist rot).Gesucht ist nun die nach dem Maximum-Likelihood-Prinzip plausibelste Zusammensetzung der Kugeln in der Urne.
Die möglichen Parameter der Wahrscheinlichkeitsfunktion
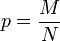 sind
sind 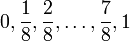 . Hier entspricht die Erfolgswahrscheinlichkeit
. Hier entspricht die Erfolgswahrscheinlichkeit 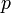 einer Ziehung gerade dem Parameter der Likelihood-Funktion.
einer Ziehung gerade dem Parameter der Likelihood-Funktion.Die zugehörige Likelihood-Funktion ist bis auf den Binomialkoeffizienten
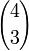
Nun können wir die Funktionswerte berechnen:
p 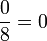







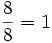
L(p) 0 0,002 0,012 0,033 0,063 0,092 0,105 0,084 0
Damit ist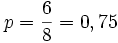 der plausibelste (größte) Parameterwert für die Realisation drei roter Kugeln bei vier Ziehungen und somit der Schätzwert für nach der Maximum-Likelihood-Methode, d.h.
der plausibelste (größte) Parameterwert für die Realisation drei roter Kugeln bei vier Ziehungen und somit der Schätzwert für nach der Maximum-Likelihood-Methode, d.h. 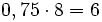 rote Kugeln sind die wahrscheinlichste Anzahl.
rote Kugeln sind die wahrscheinlichste Anzahl.
Dies kann auch direkt über die Ableitung nach p der Likelihoodfunktion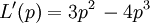 berechnet werden:
berechnet werden:
Die Nullstellen der Ableitung sind bei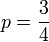 und 0; überprüfen zeigt, dass das Maximum nicht an den Randpunkten sondern für angenommen wird. Wir haben damit das gewünschte Ergebnis.
und 0; überprüfen zeigt, dass das Maximum nicht an den Randpunkten sondern für angenommen wird. Wir haben damit das gewünschte Ergebnis.Stetige Verteilung, kontinuierlicher Parameterraum
Zu der Normalverteilung
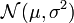 , die die Wahrscheinlichkeitsdichte
, die die Wahrscheinlichkeitsdichtehat, ist die Likelihoodfunktion
oder umgeschrieben
 ,
,
wobei
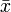 der Mittelwert ist.
der Mittelwert ist.Diese Familie von Verteilungen hat zwei Parameter: q=( m, s), wir maximieren die Likelihoodfunktion
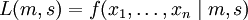 nach diesen beiden Parametern.
nach diesen beiden Parametern.Da der Logarithmus eine streng monoton wachsende Funktion ist, können wir auch den Logarithmus der Likelihoodfunktion maximieren.
Wir bilden die partiellen Ableitungen
und
-
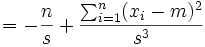 .
.
Wir setzen beide Gleichungen gleich null und erhalten
und
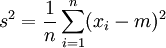 .
.
Tatsächlich hat die Funktion L an dieser Stelle ihr Maximum.
Wir berechnen noch die Erwartungswerte von m und s:
![E \left[ m \right] = \mu](/pictures/dewiki/100/d2d9fe4cfd9c99dfb447a688654b479f.png) ,
,
das heißt der Maximum-Likelihood-Schätzer m ist erwartungstreu.
Aber
![E \left[ s^2 \right]= \frac{n-1}{n}\sigma^2](/pictures/dewiki/98/b0388a68c22ae4d58e732b552af6fca8.png) , denn
, denn
Der Schätzer s ist also nicht erwartungstreu.
Maximum-Likelihood-Schätzung
Als Maximum-Likelihood-Schätzung bezeichnet man in der Statistik eine Parameterschätzung, die nach der Maximum-Likelihood-Methode berechnet wurde. In der englischen Fachliteratur ist die Abkürzung MLE (maximum likelihood estimate) dafür sehr verbreitet. Eine Schätzung, bei der Vorwissen in Form einer a priori-Wahrscheinlichkeit einfließt, wird Maximum-A-Posteriori-Schätzung (MAP) genannt.
Existenz und asymptotische Eigenschaften von Maximum-Likelihood-Schätzern
Die besondere Qualität von Maximum-Likelihood-Schätzern äußert sich darin, dass sie in der Regel die effizienteste Methode zur Schätzung bestimmter Parameter darstellt.
Es lässt sich zum einen unter bestimmten Regularitätsannahmen beweisen, dass Maximum-Likelihood-Schätzer existieren, was aufgrund ihrer impliziten Definition als eindeutiger Maximalstelle einer nicht näher bestimmten Wahrscheinlichkeitsfunktion nicht offensichtlich ist. Die für diesen Beweis benötigten Voraussetzungen bestehen im Prinzip ausschließlich aus Annahmen zur Vertauschbarkeit von Integration und Differentiation, was in den meisten betrachteten Modellen erfüllt ist.
Zum anderen sind Maximum-Likelihood-Schätzer, sofern sie unter den oben angesprochenen Bedingungen existieren, asymptotisch effizient, d. h. sie konvergieren in Verteilung gegen eine normalverteilte Zufallsvariable, deren Varianz das Inverse der Fisher-Information ist. Formal gesprochen sei
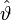 der Maximum-Likelihood-Schätzer für einen Parameter
der Maximum-Likelihood-Schätzer für einen Parameter 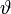 und
und 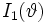 die Matrix der Fisher-Information von
die Matrix der Fisher-Information von 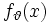 . Dann gilt die folgende Konvergenzaussage
. Dann gilt die folgende Konvergenzaussage 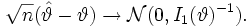
Dieser Grenzwertsatz ist speziell deswegen von Bedeutung, weil als Konsequenz aus der Cramer-Rao-Ungleichung das Inverse der Fisher-Information die bestmögliche Varianz für die Schätzung eines unbekannten Parameters darstellt. In dieser Hinsicht ist die Maximum-Likelihood-Methode bezüglich asymptotischer Betrachtungen optimal.
Nachteil
Diese wünschenswerten Eigenschaften des Maximum-Likelihood-Ansatzes beruhen jedoch auf der entscheidenden Annahme über den datenerzeugenden Prozess, das heißt auf der unterstellten Dichtefunktion der untersuchten Zufallsvariable. Der Nachteil von Maximum-Likelihood besteht deshalb, weil eine konkrete Annahme über die gesamte Verteilung der Zufallsvariable getroffen werden muss. Wenn diese jedoch verletzt ist, kann es sein, dass die Maximum-Likelihood-Schätzer inkonsistent sind. Nur in einigen Fällen ist es unerheblich, ob die Zufallsvariable tatsächlich der unterstellten Verteilung gehorcht, allerdings gilt dies nicht im Allgemeinen. Per Maximum-Likelihood gewonnene Schätzer, die konsistent sind, auch wenn die zu Grunde gelegte Verteilungsannahme verletzt wird, sind sogenannte Pseudo-Maximum-Likelihood-Schätzer. Diese Schätzer können Effizienzprobleme in kleinen Stichproben aufweisen.
Anwendungsbeispiel: Maximum-Likelihood in der molekularen Phylogenie
Das Maximum-Likelihood-Kriterium gilt als eine der Standardmethoden zur Berechnung von phylogenetischen Bäumen, um Verwandtschaftsbeziehungen zwischen Organismen – meist anhand von DNA- oder Proteinsequenzen – zu erforschen. Als explizite Methode ermöglicht Maximum-Likelihood die Anwendung verschiedener Evolutionsmodelle, die in Form von Substitutionsmatrizen in die Stammbaumberechnungen einfließen. Entweder werden empirische Modelle verwendet (Proteinsequenzen) oder die Wahrscheinlichkeiten für Punktmutationen zwischen den verschiedenen Nucleotiden werden anhand des Datensatzes geschätzt und hinsichtlich des Likelihood-Wertes (-lnL) optimiert (DNA-Sequenzen). Allgemein gilt ML als die zuverlässigste und am wenigsten Artefakt-anfällige Methode unter den phylogenetischen Baumkonstruktionsmethoden. Dies erfordert jedoch ein sorgfältiges Taxon-„Sampling“ und meist ein komplexes Evolutionsmodell.
Literatur
- Schwarze, Jochen: Grundlagen der Statistik – Band 2: Wahrscheinlichkeitsrechnung und induktive Statistik, 6. Auflage, Berlin; Herne: Verlag Neue Wirtschaftsbriefe, 1997
- Blobel, Volker und Lohrmann, Erich: Statistische und numerische Methoden der Datenanalyse, Stuttgart; Leipzig: Teubner Studienbücher, 1998
- Felsenstein, Joseph: Inferring Phylogenies. Sinauer Associates, 2003
- Internet-Lexikon der Methoden der empirischen Sozialforschung: Maximum Likelihood-Schätzung ILMES
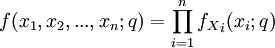
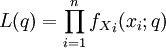
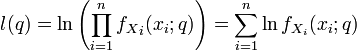
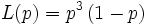


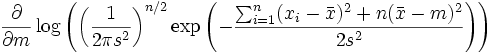
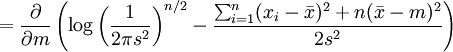
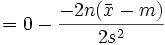
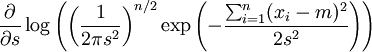
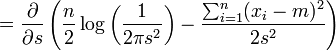
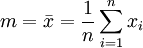
![E \left[ s^2 \right]= E \left(\frac {1}{n}\sum_{i=1}^n x_i^2-\frac{1}{n^2}\left(\sum_{i=1}^n x_i\right)^2\right)](/pictures/dewiki/50/216e4fa17701d9521a505a78cecfe0c8.png)
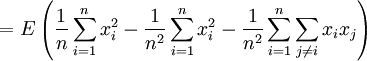
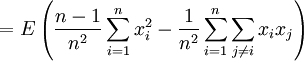
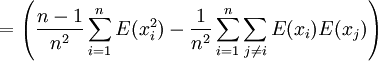
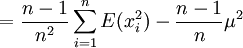
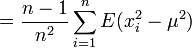
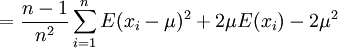
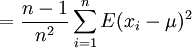
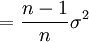
Wikimedia Foundation.