- Gewöhnliche stochastische Ordnung
-
Stochastische Ordnungen sind Ordnungsrelationen für Zufallsvariablen. Sie verallgemeinern das Konzept von größer und kleiner auf zufällige Größen und dienen zum Beispiel dem Vergleich von Risiken in der Versicherungswirtschaft. Die Theorie der stochastischen Ordnungen ist ein jüngeres mathematisches Teilgebiet und hat in den letzten Jahrzehnten eine starke Entwicklung erfahren und eine breite Anwendung in Finanzmathematik, ökonomischer Forschung und Operations Research gefunden. Spezielle stochastische Ordnungen wurden schon in der Nachkriegszeit erforscht, die erste umfassende Monographie des Themas von Dietrich Stoyan wurde 1977 veröffentlicht. Es werden zahlreiche stochastische Ordnungen mit jeweils unterschiedlichen Anwendungsbereichen betrachtet, die Theorie der Integralordnungen ermöglicht es dabei, unterschiedliche Ordnungen mit einheitlichen Methoden zu untersuchen.
Inhaltsverzeichnis
Ordnung im Mittel
Eine in der Praxis oft genutzte Ad-hoc-Ordnung entsteht aus dem Vergleich von Erwartungswerten. Man sagt die reelle Zufallsvariable X ist im Mittel kleiner als die Zufallsvariable Y, wenn
![\mathbb E[X] < \mathbb E[Y]](/pictures/dewiki/57/989b59508faeeb1e4b4b72d50bd8097f.png) gilt. Diese Ordnung berücksichtigt keine weiteren Eigenschaften der Verteilungen wie Varianz oder Schiefe.
gilt. Diese Ordnung berücksichtigt keine weiteren Eigenschaften der Verteilungen wie Varianz oder Schiefe.Gewöhnliche stochastische Ordnung
Eine besondere Rolle spielt die gewöhnliche stochastische Ordnung (engl.: usual stochastic order). Ausgehend von der Notwendigkeit, Bewertungen und Entscheidungen auch unter Unsicherheit vornehmen zu können, überträgt sie den anschaulichen Ordnungsbegriff reeller Zahlen (formalisiert durch die Ordnungsaxiome reeller Zahlen) auf reellwertige Zufallsvariablen. Sie wurde vor anderen stochastischen Ordnungen untersucht und 1947 (Mann und Whitney) und 1956 (Lehmann) in mathematischen Arbeiten verwendet. Von Samuel Karlin wurde sie 1960 in das Operations Research eingeführt. In der ökonomischen Literatur ist sie als first order stochastic dominance bekannt.[1]
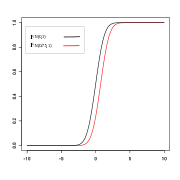 N(0, 1) ≼ N(0.75, 1).
N(0, 1) ≼ N(0.75, 1).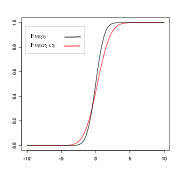 N(0, 1) und N(0.25, 1.5) sind nicht vergleichbar.
N(0, 1) und N(0.25, 1.5) sind nicht vergleichbar.Definition: Seien X und Y reelle Zufallsvariablen. Y ist größer-gleich X bezüglich der gewöhnlichen stochastischen Ordnung, wenn für alle
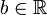 gilt
gilt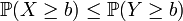 .
.
Das heißt für eine beliebige Schranke b liegen die Werte von Y mit größerer (oder gleicher) Wahrscheinlichkeit über b als die Werte von X. Als Symbol wird häufig
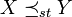 eingeführt. Das lässt sich ebenfalls als Kriterium für die Verteilungsfunktionen FX und FY formulieren:
eingeführt. Das lässt sich ebenfalls als Kriterium für die Verteilungsfunktionen FX und FY formulieren: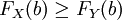 für alle .
für alle .
Eine äquivalente Definition lautet
![X \preceq_{st} Y :\Leftrightarrow \mathbb E[f(X)] \le \mathbb E[f(Y)]](/pictures/dewiki/97/ace77dd19d8da49c38f75b223d82f315.png) für alle monoton wachsenden Funktionen
für alle monoton wachsenden Funktionen 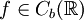 .
.
Diese Definition lässt sich für Zufallsvariablen mit Werten in einem topologischen Raum E, auf dem eine Halbordnung
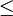 definiert sind, auf natürliche Weise verallgemeinern (wobei die Ordnung mit der Topologie verträglich sein muss und daher die Abgeschlossenheit der Menge
definiert sind, auf natürliche Weise verallgemeinern (wobei die Ordnung mit der Topologie verträglich sein muss und daher die Abgeschlossenheit der Menge 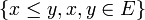 gefordert wird.)
gefordert wird.)Der Satz von Strassen macht die Aussage, dass
für Zufallsvariablen X,Y mit Werten in einem polnischen Raum mit Halbordnung äquivalent dazu ist, dass ein Wahrscheinlichkeitsraum und zwei Zufallsvariablen 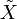 und
und 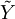 existieren, welche wie X respektive Y verteilt sind und
existieren, welche wie X respektive Y verteilt sind underfüllen. Der Beweis dieser Existenzaussage ist außer in einfachen Fällen nicht konstruktiv.
Zufallsgrößen mit dem gleichen Erwartungswert und unterschiedlicher Verteilung kann man mit der gewöhnlichen stochastischen Ordnung nicht vergleichen, je nach Anwendung ist es erforderlich, andere stochastische Ordnungen zu betrachten.
Integralordnungen
Viele stochastische Ordnungen von Interesse (für Zufallsvariablen mit Werten in einem geordneten polnischen Raum E ) lassen sich ebenso wie die gewöhnliche stochastische Ordnung über Klassen von „Testfunktionen“
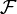 (mit
(mit 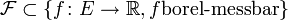 )
)![(\star)\quad X \preceq_{\mathcal F} Y :\Leftrightarrow \mathbb E[f(X)] \le \mathbb E[f(Y)]](/pictures/dewiki/49/1883a27d6d22d04fd4c25184b7fdae9d.png) für alle
für alle 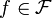 für die beide Erwartungswerte definiert sind
für die beide Erwartungswerte definiert sind
definieren. Solche stochastischen Ordnungen heißen Integralordnungen,
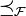 heißt die von generierte stochastische Ordnung, ihr Generator. Die so definierte Operation ist nicht unbedingt transitiv, eine Möglichkeit, dieses Problem zu umgehen, ist die Einschränkung auf solche Funktionen und Zufallsvariablen, für die alle Erwartungswerte existieren.
heißt die von generierte stochastische Ordnung, ihr Generator. Die so definierte Operation ist nicht unbedingt transitiv, eine Möglichkeit, dieses Problem zu umgehen, ist die Einschränkung auf solche Funktionen und Zufallsvariablen, für die alle Erwartungswerte existieren.Dies ist eine wahrscheinlichkeitstheoretische Begriffsbildung – das heißt es kommt nur auf die Verteilungen von X und Y an und Integralordnungen lassen sich ebenso für Verteilungen auf geordneten polnischen Räumen
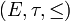 ausgestattet mit der σ-Algebra der Borelmengen definieren:
ausgestattet mit der σ-Algebra der Borelmengen definieren: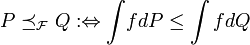 für alle für die beide Integrale definiert sind,
für alle für die beide Integrale definiert sind,
wobei P,Q Wahrscheinlichkeitsmaße auf
 seien.
seien.Oft wird eine Ordnung schon von einer Unterklasse von
generiert (es reicht also aus, die rechte Seite von  für einen Teil der Funktionen aus überprüfen, um
für einen Teil der Funktionen aus überprüfen, um 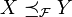 zu folgern), im Fall der gewöhnlichen stochastischen Ordnung zum Beispiel für alle isotonen messbaren Indikatorfunktionen oder für alle unendlich oft differenzierbaren isotonen Funktionen.
zu folgern), im Fall der gewöhnlichen stochastischen Ordnung zum Beispiel für alle isotonen messbaren Indikatorfunktionen oder für alle unendlich oft differenzierbaren isotonen Funktionen.In der Anwendung der Ordnung ist oft von Interesse, aus der linken Seite von
die Gültigkeit der rechte Seite für eine bestimmte Funktion f0 zu folgern. Die Frage danach, für welche Funktionen dies möglich ist, führte A. W. Marshall 1991 zum Begriff des maximalen Generator. [2]Bei der Bestimmung eines maximalen Generators wird wie bei der Sicherung der Transitivität eine Einschränkung auf bestimmte Funktionen benötigt. Es werden eine Gewichtsfunktion
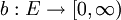 eingeführt und nur b-beschränkte Funktionen
eingeführt und nur b-beschränkte Funktionen 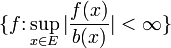 und Maße, bezüglich denen b integrierbar ist, betrachtet.
und Maße, bezüglich denen b integrierbar ist, betrachtet.Stop-loss order
Die für die Versicherungsmathematik wichtige stop-loss order
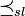 ist ein weiteres Beispiel für eine Integralordnung. Sie wird generiert von der Klasse der reellen Funktionen der Gestalt
ist ein weiteres Beispiel für eine Integralordnung. Sie wird generiert von der Klasse der reellen Funktionen der Gestalt 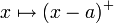 ,
, 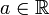 . Die stop-loss order ist schwächer als die gewöhnliche stochastische Ordnung und wird unter anderem beim Vergleich von Schadenssummen und als Kriterium bei der Wahl eines Prämienprinzips eingesetzt. Werden X und Y als Risiken interpretiert, bedeutet
. Die stop-loss order ist schwächer als die gewöhnliche stochastische Ordnung und wird unter anderem beim Vergleich von Schadenssummen und als Kriterium bei der Wahl eines Prämienprinzips eingesetzt. Werden X und Y als Risiken interpretiert, bedeutet 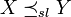 , dass die Stop-Loss-Rückversicherungsprämie für das Risiko Y größer ist als die für X bei jeder Wahl des Selbstbehalts a.[3]
, dass die Stop-Loss-Rückversicherungsprämie für das Risiko Y größer ist als die für X bei jeder Wahl des Selbstbehalts a.[3]Abhängigkeitsordnungen
Sind (X1,X2) und (Y1,Y2) Zufallsvektoren im
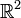 , so ist über den Vergleich der Kovarianzen
, so ist über den Vergleich der Kovarianzenein Vergleich des Grades der gegenseitigen Abhängigkeit der Komponenten der beiden Vektoren möglich. Abhängigkeitsordnungen (engl. dependence orders) verallgemeinern dieses Konzept und sind unter anderem von Interesse für die Versicherungswirtschaft, wo Häufung und Abhängigkeit von Risiken wie Hagel- oder Hochwasserschäden ein finanzielles Risiko für die Versicherer darstellen und die traditionell in der Versicherungsmathematik gemachte Annahme der Unabhängigkeit der Risiken zu einer Unterschätzung der Ruin-Wahrscheinlichkeit führt.
Zu den Abhängigkeitsordnungen gehört die supermodulare Ordnung
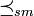 . Sie wird generiert von der Klasse der supermodularen Funktionen
. Sie wird generiert von der Klasse der supermodularen Funktionen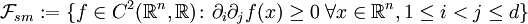 .
.
Sie ermöglicht zusammen mit der stop-loss order den Vergleich von multivariaten Risiko-Portfolios mit abhängigen Risiken.
Genauer gilt: Seien
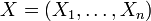 und
und 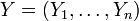 zwei Risiko-Portfolios mit gleichen Randverteilungen. Ist der Vektor der Risiken von Portfolio X supermodular kleiner als der von Portfolio Y, ist die Zufallsvariable der Schadenssumme von Portfolio X kleiner als die von Portfolio Y bezüglich der stop-loss order, und damit auch der Preis einer Stop-Loss-Rückversicherung:[4]
zwei Risiko-Portfolios mit gleichen Randverteilungen. Ist der Vektor der Risiken von Portfolio X supermodular kleiner als der von Portfolio Y, ist die Zufallsvariable der Schadenssumme von Portfolio X kleiner als die von Portfolio Y bezüglich der stop-loss order, und damit auch der Preis einer Stop-Loss-Rückversicherung:[4]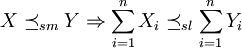 .
.
Einzelnachweise
- ↑ Alfred Müller, Dietrich Stoyan: Comparison methods for stochastic models and risks. Wiley, Chichester 2002, ISBN 9780471494461, S. 2.
- ↑ A. W. Marshall: Multivariate Stochastic Orderings and generating cones of functions. In: Mosler K. und Scarsini M. (Editoren): Stochastic Orders and Decision under Risk. IMS Lecture Notes - Monograph Series 1991, Band 19, S. 231- 247.
- ↑ Nicole Bäuerle, Alfred Müller: Modeling and Comparing Dependencies in Multivariate Risk Portfolios. In: ASTIN Bulletin International Actuarial Association, Brüssel 1998, Band 28:1, S. 62. (pdf)
- ↑ Nicole Bäuerle, Alfred Müller: Modeling and Comparing Dependencies in Multivariate Risk Portfolios. In: ASTIN Bulletin International Actuarial Association, Brüssel 1998, Band 28:1, S. 64. (pdf)
Literatur
- Dietrich Stoyan: Qualitative Eigenschaften und Abschatzungen stochastischer Modelle. R. Oldenbourg, München 1977.
- Alfred Müller, Dietrich Stoyan: Comparison methods for stochastic models and risks. Wiley, Chichester 2002, ISBN 9780471494461.
- R. Szekli: Stochastic Ordering and Dependence in Applied Probability (Lecture Notes in Statistics). Springer, New York 1995, ISBN 978-0387944500.
- Klaus D. Schmidt: Versicherungsmathematik. Springer, Berlin/Heidelberg/New York 2005, ISBN 9783540290971.


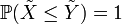
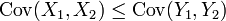
Wikimedia Foundation.