- Hamming-Kode
-
Der Hamming-Code ist ein von Richard Hamming entwickelter linearer fehlerkorrigierender Blockcode, der in der digitalen Signalverarbeitung und der Nachrichtentechnik zur gesicherten Datenübertragung oder Datenspeicherung verwendet wird.
Beim Hamming-Code handelt es sich um eine Klasse von Blockcodes unterschiedlicher Länge, welche durch eine allgemeine Bildungsvorschrift gebildet werden. Die Besonderheit dieses Codes besteht in der Verwendung mehrerer Paritätsbits. Diese Bits ergänzen jeweils unterschiedlich gewählte Gruppen von den die Information tragenden Nutzdatenbits. Durch eine geschickte Wahl der Gruppierung, deren mathematische Grundlagen im Folgenden beschrieben sind, ist nicht nur eine Fehlererkennung, sondern auch eine Fehlerkorrektur der übertragenden Datenbits möglich.
Die einzelnen Codewörter des Hamming-Codes weisen einen Hamming-Abstand von drei auf. Durch diesen Unterschied von jeweils drei Bitstellen kann der Decoder einen Bitfehler in einem Datenblock immer erkennen und korrigieren, bei zwei oder mehr Bitfehlern wird der Datenblock allerdings falsch decodiert. Der erweiterte Hamming-Code mit einem Hamming-Abstand von vier kann durch eine zusätzliche Paritystelle auch zwei Bitfehler in einem Datenblock erkennen, aber nicht korrigieren.
Eigenschaften Stellenzahl 2k-1, k ≥ 2 und ganzzahlig Gewicht 3 Maximaldistanz 3 Hamming-Distanz 3 Redundanz ld(2k-1) - ld(2k-k-1) k ist die Anzahl der Paritätsbits pro Codewort Inhaltsverzeichnis
Geschichte
In den 1940er Jahren arbeitete Richard Hamming in der Firma Bell Labs an einem Computer namens Bell Model V, welcher mit fehleranfälligen elektromechanischen Relais mit zwei Maschinenzyklen pro Sekunde ausgestattet war. Die zu Dateneingaben verwendeten Lochkarten konnten durch Abnutzung bei der Leseoperation Fehler aufweisen, die zu den normalen Bürozeiten durch Angestellte der Bell Labs von Hand korrigiert werden mussten. Zu den üblichen Arbeitszeiten von Richard Hamming, außerhalb der Bürozeiten und am Wochenende, führten diese Lesefehler dazu, dass der Computer die fehlerhaften Lochkarten übersprang und an anderen Lochkarten weiterarbeitete.
Hamming, durch diese Fehler und den mehrfachen Aufwand frustriert, entwickelte in Folge einen speziellen Code, durch den die Maschine Lesefehler von Lochkarten in bestimmten Umfang selbstständig erkennen und korrigieren konnte. Im Jahr 1950 publizierte er diesen Hamming-Code[1], der noch heute und in teilweise erweiterten Formen im Bereich der Kanalcodierung verbreitete Anwendung findet.
Aufbau des Codes
Im folgenden werden nur binäre Hamming-Codes dargestellt. Binäre Hamming-Codes basieren auf Paritycodes über einem Datenblock fixer Länge. Der Datenblock, auch als „Datenwort“ oder „Nachrichtenwort“ bezeichnet, umfasst n Bits und enthält die eigentliche Nutzinformation. n kann bei dem Hamming-Code nur spezifische ganzzahlige Werte annehmen, welche sich aus der Bildungsvorgabe dieses Codes ergeben. Die Bitkombinationen in dem n Bit umfassenden Datenblock können grundsätzlich beliebig gewählt werden, das heißt es sind alle beliebigen Bitkombinationen zulässig.
Das Codewort des Hamming-Codes wird aus dem Datenwort durch Integration zusätzlicher Kontrollstellen, den so genannten Parity-Bits, gewonnen. Dabei wird in jedes Datenwort von n Bit Länge eine fixe Anzahl k Kontrollstellen eingefügt. Daraus ergibt sich das Codewort mit einer Länge von N = n + k. Für ein Codewort sind, da die Kontrollstellen redundante, aus dem Datenblock abgeleitete Information tragen, nur noch bestimmte Bitkombinationen möglich. Auf diesen wesentlichen Umstand gründet sich sowohl die Fehlererkennung, als auch in weiterer Folge die Fehlerkorrektur des Datenwortes.
Die Vorgabe zur Codebildung durch eine weitere Gleichung von N zu k ist in folgender Form beschrieben:
- N = 2k − 1
Dies bedeutet, dass wenn beispielsweise drei binäre Stellen für Kontrollbits (Parity-Bits) zur Verfügung stehen, das Codewort zwangsläufig eine Länge von N=7 aufweisen muss. Für das Datenwort ergibt sich dann eine Länge von n = 7-3 = 4 Bits pro Codewort oder allgemein:
- n = 2k − k − 1
In folgender Tabelle sind alle möglichen Hamming-Codes unterschiedlicher Codewortlängen bis zur Blockgröße von 255 Bits dargestellt:
Parameterkombinationen bei Hamming-Codes n k N = n + k Datenbits
(Datenwort)Paritybits
(Kontrollstellen)Gesamtlänge
des Codewortes1 2 3 4 3 7 11 4 15 26 5 31 57 6 63 120 7 127 247 8 255 Zur Klassifikation der unterschiedlich langen Hamming-Codes wird in der Literatur meist folgende Schreibweise verwendet: (N,n)-Code. Die erste Zahl gibt die Anzahl der Nachrichtenbits (N) des Codewortes an, die zweite Zahl die Anzahl der Datenbits (n) pro Codewort. Vor allem in Demonstrationsbeispielen ist der Einfachheit wegen oft der (7,4)-Hamming-Code anzutreffen. Für reale Applikationen ist hier der Overhead, d. h. die Relation von Kontrollbits zu Datenbits, zu ungünstig, weshalb längere Hamming-Codes wie der (63,57)-Hamming-Code verwendet werden.
Manchmal wird bei der Klassifizierungsangabe noch eine dritte Stelle, welche die Distanz des Codes angibt, angegeben. Aufgrund der fixen Hamming-Distanz wird jedoch zumeist statt „(63,57,3)-Hamming-Code“ nur „(63,57)-Hamming-Code“ geschrieben.
Berechnung der Parity-Stellen
Die k Parity-Stellen (Kontrollbits) in einem Codewort werden nach einem Verfahren berechnet, wie es auch bei dem einfachen Parity-Prüfbit zur Anwendung kommt. Im Regelfall wird vereinbarungsgemäß eine gerade Parität für alle Kontrollstellen gewählt: Ist die Anzahl der logischen-1 der in die jeweilige Kontrollstelle eingerechneten Datenbitstellen eine gerade Anzahl, ist das jeweilige Parity-Bit logisch-0. Ist die Anzahl der logisch-1 in den Datenbitstellen eine ungerade Anzahl, wird das jeweilige Parity-Bit auf logisch-1 gesetzt, so dass sich in Summe in den Datenbitstellen und den Parity-Bit, immer eine gerade Anzahl von logisch-1 Bits ergibt.
Die einzelnen Parity-Bits eines Codewortes werden nicht über alle Stellen (Bits) des Datenwortes gebildet, sondern nur über einzelne, ausgewählte Datenbits. Zur Konstruktion welche Datenbitstellen in welche Kontrollbits eingerechnet werden, kann nach einer anschaulichen Methode vorgegangen werden. Zunächst wird dazu der Rahmen des Codewortes aus den Datenbits und den Kontrollstellen gebildet:
- Im Codewort befinden sich an den Positionen welche Zweierpotenzen sind (1,2,4,8,16,…) die einzelnen Parity-Kontrollbits p.
- Die Datenbits d des zu übertragenen Datenwortes werden dazwischen auf den freien Stellen im Codewort von links aufsteigend, eingetragen.
Sind p1, p2, … pk Parity-Bits, und d1, d2, … dN-k Bits des Datenwortes und c1, c2, … cN die Bits des zu bildenden Codewortes, hat ein Codewort des so konstruierten Hamming-Code diese Form: (diese Darstellung kann für größere Codewortlängen entsprechend erweitert werden)
 Anordnung der Parity-Kontrollstellen p1…pk und der Datenbits d1…dN-k in einem Codewort mit den Stellen c1…cN für die im folgende dargestellte Bitanordnung.
Anordnung der Parity-Kontrollstellen p1…pk und der Datenbits d1…dN-k in einem Codewort mit den Stellen c1…cN für die im folgende dargestellte Bitanordnung.In das erste Parity-Bit p1 werden nur jene Datenbits einbezogen, welche um eine Bitstelle weiter rechts im Codewort stehen und ein Bit als Datenbreite umfassen. Für das erste Parity-Bit ergibt sich als Folge von Codewortstellen somit alle Datenbits, welcher an ungerade Position im Codewort stehen:
Das Symbol
 ist die logische XOR-Funktion und stellt zugleich die Bildungsvorschrift für die Kontrollbits dar. Wie weiter mit Hilfe obiger Tabelle zu erkennen ist, kommen an den angeführten Bitpositionen im Codewort auf der rechten Seite der Gleichung nur Datenbits vor. Dies gilt für alle Parity-Bits.
ist die logische XOR-Funktion und stellt zugleich die Bildungsvorschrift für die Kontrollbits dar. Wie weiter mit Hilfe obiger Tabelle zu erkennen ist, kommen an den angeführten Bitpositionen im Codewort auf der rechten Seite der Gleichung nur Datenbits vor. Dies gilt für alle Parity-Bits.In das zweite Parity-Bit p2 wird das rechts von p2 im Codewort stehende Bit c3 einberechnet, dann zwei Stellen im Codewort übersprungen, die nächsten zwei Bit c6 und c7 einberechnet, wieder zwei Stellen übersprungen, und so weiter. Statt eines Datenbits werden also zwei benachbarte Datenbits genommen und im Codewort zwei Stellen übersprungen. Damit ergibt sich für p2 die Bildungsvorschrift:
In das dritte Parity-Bit p3 werden die rechts im Codewort folgenden drei Stellen einberechnet, es werden vier Stellen des Codewortes übersprungen, dann vier Bit einberechnet, dann vier Stellen übersprungen, und so weiter. Es werden also Gruppen zu je vier Bits für die Bildung des Parity-Bits herangezogen. Damit ergibt sich für p3:
Das Parity-Bit pi wird also über alle Stellen cj des Codeworts berechnet, in denen an der i-ten Stelle der Binärkodierung des Index j eine logische Eins steht. Nach diesem Verfahren wird für die restlichen Parity-Bits analog fortgefahren, bis alle Parity-Bits des gewählten Hamming-Code bestimmt sind. Das Bestimmen des Codeworts wird in praktischen Applikationen durch den so genannten Encoder vorgenommen.
Im konkreten Fall des (7,4)-Hamming-Code ergibt sich so die nachfolgende Codeworttabelle. Darunter sind in den jeweiligen Spalten die Verknüpfungen der einzelnen Parity-Bits eingetragen, aus denen sich unmittelbar die später dargestellte Kontrollmatrix H, auch Prüfmatrix genannt, für dieses Beispiel ergibt. In den Spalten der letzten drei Zeilen sind Pfeile an jenen Stellen eingetragen, wo sich in der Kontrollmatrix H dann logisch-'1' finden. Nach diesem Muster kann mit etwas Aufwand die Kontrollmatrix bei jedem Hamming-Code bestimmt werden. Es ist pro Zeile immer ein Parity-Bit mit einem aufwärts gerichteten Pfeil (↑) eingezeichnet, und die Datenbits zur Bestimmung des betreffenden Parity-Bit sind mit einem abwärtsgerichteten Pfeil (↓) markiert.
Bestimmung der Parity-Bits am Beispiel des (7,4)-Hamming-Code c1 c2 c3 c4 c5 c6 c7 p1 p2 d1 p3 d2 d3 d4 ↑ ↓ ↓ ↓ ↑ ↓ ↓ ↓ ↑ ↓ ↓ ↓ Die Anordnung von Parity- und Datenbits ist hierbei willkürlich gewählt. Es kann ohne Einschränkung eine andere Abfolge der einzelnen Bits im Codewort gewählt werden, ohne die Eigenschaft des Hamming-Codes zu ändern. Diesen Umstand wird im nachfolgenden systematischen, oder auch separierbaren Hamming-Code genutzt, bei dem zur Bildung des Codeworts die Parity-Bits immer ans Ende des Datenwortes angehängt werden. Der separierbare Hamming-Code wird nach der gleichen Bildungsvorschrift gewonnen, ist aber durch eine andere Anordnung der Zeilen in der Generatormatrix G und damit verbunden andere Kontrollmatrix H gekennzeichnet.
Kürzester Hamming-Code
Der kürzeste Hamming-Code ist der (3,1)-Hamming-Code. Dabei wird ein Nutzdatenbit einem drei Bit langen Codewort zugeordnet. Mit obiger allgemeiner Berechnung ergibt sich, dass die beiden „Paritätsbits“ p1 und p2 nur in diesem Fall direkt dem einen Nutzdatenbit entsprechen. Es kann nur die beiden gültigen Codewörter 000 und 111 geben. Die ungültigen Codewörter 001, 010 und 100 werden bei der Decodierung mittels des Verfahrens der Mehrheitsentscheidung dem Codewort 000 zugewiesen. 110, 101 und 011 dem Codewort 111. Damit ist der (3,1)-Hamming-Code als ein Spezialfall gleich einem Wiederholungs-Code mit einer Länge von 3. Der (3,1)-Hamming-Code ist auch der einzige Hamming-Code, welcher nur durch die Angabe (3,1) eindeutig im Aufbau des Codewortes spezifiziert ist.
Eigenschaften
Korrekturleistung
Der Hamming-Code weist, unabhängig von der gewählten Blockgröße, immer eine Distanz von drei auf. Dies bedeutet, dass sich benachbarte Codewörter immer um drei Bits unterscheiden. Tritt ein Fehler an einer Stelle eines Codeworts auf, wird dieses als ungültig erkannt und kann eindeutig dem richtigen Codewort zugeordnet, der Übertragungsfehler also korrigiert werden. Treten hingegen zwei Fehler in einem Codewort auf, funktioniert diese Zuordnung nicht mehr – die Korrektur des Decoders ordnet das empfangene Codewort fälschlich einem anderen zu. Dies wird als „Falschkorrektur“ bezeichnet. Eine andere Form des Versagens tritt bei drei Übertragungsfehlern auf: Hier erkennt der Decoder das fehlerhafte Codewort als gültig an.
Hamming-Codes können also nur einen Bitfehler pro Datenwort korrekt korrigieren. Bis zu zwei Bitfehler können erkannt werden. Wegen seiner Fähigkeit, alle empfangenen Codeworte einem validen Codewort zuordnen zu können, ist der Hamming-Code ein perfekter Code. Die meisten anderen Binärcodes – etwa der erweiterte Hamming-Code – sind nicht perfekt. Bei diesen Codes können durch Übertragungsfehler Codeworte auftreten, die der Decoder zwar als falsch erkennen kann, jedoch keinem gültigen Wort zuordnen kann (Dekodierversagen).
Linearität
Hamming-Codes sind grundsätzlich lineare Codes. Bei diesen – auch als binäre Gruppencodes bezeichneten – Codierungen führt jede Modulo-2-Addition (XOR-Verknüpfung) zweier Codewörter wieder zu einem gültigen Codewort. Zu den Voraussetzungen eines linearen Code zählt die Existenz eines neutralen Elements. Im Falle eines Hamming-Codes bedeutet dies, dass das Nullwort – dessen Stellen sämtlich logisch-'0' sind – gültig sein muss. Das so genannte „Codegewicht“ entspricht somit bei Hamming-Codes dem Hamming-Abstand von drei.
Eine weitere allgemeine Eigenschaft von Gruppencodes besteht darin, dass sich die einzelnen gültigen Codewörter c aus einer Generatormatrix G und den Datenwörtern d nach folgender Form erzeugen lassen:
Aus dieser Gleichung ergibt sich mit der im vorherigen Abschnitt dargestellten Bildungsvorschrift, und den Rechenregeln für Matrizen für einen nicht separierbaren (7,4)-Hamming-Code, die folgende Generatormatrix G:
Die ersten beiden Zeilen der Matrix bilden die ersten beiden Parity-Bits p1 und p2 des Codewortes. Die Einsen der Zeilen geben hierbei an, welche Datenbitstellen in das jeweilige Parity-Bit eingerechnet werden. Die dritte Zeile, ebenso wie alle nachfolgenden Zeilen mit nur einer Eins pro Zeile, bilden die Datenbits dn im Codewort ab. Die vierte Zeile bildet das dritte Parity-Bit p3.
Aus der Generatormatrix lässt sich direkt die Kontrollmatrix H ableiten, die vom Decoder verwendet wird, um fehlerhafte Bitstellen mittels Matrixmultiplikation zu erkennen. Die Prüfmatrix muss so gewählt sein, dass sie orthogonal zu allen gültigen Codewörtern c ist:
Für obige Generatormatrix G lässt sich die folgende Kontrollmatrix H ermitteln:
Der Inhalt der Matrix kann hierbei beispielsweise über das im vorigen Abschnitt vorgestellte, tabellarische Verfahren zur Bestimmung der Parity-Bits aus der Generatormatrix gewonnen werden.
Tritt ein einzelner Bitfehler auf, so gilt für das entstehende, ungültige Codewort:
Durch den Wert dieser Gleichung kann über eine Syndromtabelle die fehlerhafte Bitstelle eindeutig bestimmt und durch Invertieren korrigiert werden.
Separierbarer Hamming-Code
Aufgrund der Linearität können beliebige Zeilen der Generatormatrix G vertauscht werden, ohne die Codeeigenschaften zu verändern. Die jeweilige Form der Generatormatrix muss nur zwischen Encoder und Decoder abgestimmt sein. Ein separierbarer Code liegt vor, wenn im Codewort zuerst alle Datenbits dn und nachfolgend alle Parity-Bits pn angeordnet sind. Durch die Separierbarkeit können Encoder und Decoder schaltungstechnisch in elektronischen digitalen Schaltungen wie ASICs oder FPGAs mit weniger Speicheraufwand und mit geringerer Latenzzeit realisiert werden. Separierbare Codes werden auch als „systematische Codes“ bezeichnet.
Obige Generatormatrix G kann durch Umstellen der Zeilen auf folgende Generatormatrix G′ so umgeformt werden, dass der (7,4)-Hamming-Code ein separierbarer Code wird. Eine mögliche Generatormatrix des separierbaren (7,4)-Hamming-Codes lautet:
Die assoziierte Kontrollmatrix H′ kann leichter bestimmt werden, denn bei separierbaren Blockcodes gilt mit Modulo-2-Operationen:
Damit bestimmt sich H′ zu:
Die ersten 4 Spalten der Kontrollmatrix H′ bestehen dabei aus den letzten drei Zeilen der Generatormatrix G′. Der rechte Teil der Kontrollmatrix ist mit der Einheitsmatrix aufgefüllt.
Damit ist dargestellt, dass nur die Angabe (7,4)-Hamming-Code für eine konkrete Implementierung nicht eindeutig den genauen Codierungsvorgang und Decodierungsvorgang beschreibt. Dies ist erst durch Angabe der jeweiligen Generatormatrix, oder bei zyklischen Hamming-Codes durch das Generatorpolynom, gewährleistet.
Zyklischer Hamming-Code
Bei der praktischen Anwendung spielen zyklische Codes, insbesondere zyklische separierbare Hamming-Codes, eine bedeutende Rolle. Mit diesen kann die Berechnung der einzelnen Prüfbits im Encoder und die Decodierung im Decoder mit minimalen Speicheraufwand in Form von linear rückgekoppelten Schieberegistern (LFSR) realisiert werden. Zyklische Codes sind lineare Codes, bei denen zusätzlich noch die Forderung gilt, dass eine Rotation oder zyklische Verschiebung eines Codewortes wiederum auf ein gültiges Codewort führen muss.
Der zyklische Hamming-Code kann allgemein in der Beschreibung äquivalent auch als eine Untergruppe der BCH-Codes (Bose-Chaudhuri-Hocquenghem-Codes) aufgefasst werden. BCH-Codes sind sehr große Gruppe von zyklischen Blockcodes, welche in ihren Parametern und Aufbau stärker als die Hamming-Codes variiert werden können.
Die Erzeugung zyklischer Hamming-Codes wird je nach Blocklänge durch primitive Generatorpolynome von entsprechendem Grad vorgenommen. Das Generatorpolynom kann direkt im LFSR zum Berechnen der Parity-Bits abgebildet werden.
In folgender Tabelle sind beispielhaft übliche Generatorpolynome angeführt. Es können in konkreten Implementierungen aber auch andere Generatorpolynome gewählt werden ohne die Eigenschaften des Hamming-Codes zu ändern, so das gewählte Polynom nur primitiv ist und zwischen Encoder und Decoder vereinbart ist:
Zyklische Hamming-Codes k N n Generatorpolynom G(z) 3 7 4 z3 + z + 1 4 15 11 z4 + z + 1 5 31 26 z5 + z2 + 1 6 63 57 z6 + z + 1 7 127 120 z7 + z3 + 1 Praktische Realisierung eines Hamming-Encoders
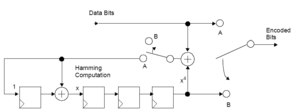 (15,11)-Hamming-Code-Encoder.
(15,11)-Hamming-Code-Encoder.Zyklische separierbare Hamming-Codes lassen sich schaltungsttechnisch in digitalen elektrischen Schaltungen einfach realisieren. In nebenstehender Abbildung ist zur Veranschaulichung ein (15,11)-Hamming Encoder mit Generatorpolynom z4 + z + 1 dargestellt.
In der Darstellung werden die Datenbits d als serieller Datenstrom in der Mitte oben eingelesen und rechts das Codewort c seriell ausgegeben. Die Schalter befinden sich zunächst in Stellung A: Damit werden im Codewort zunächst die Datenbits direkt ausgegeben und gleichzeitig in das LFSR geschoben. Sind alle Datenbits eines Datenwortes eingelesen, wechseln die beiden Schalter in Stellung B: Es wird nun bitweise der Inhalt des LFSR ausgegeben, der den Parity-Bits p entspricht. Sind alle Prüfstellen ausgegeben, wiederholt sich der Vorgang. Zur Vereinfachung sind die nötigen Taktleitungen und Synchronisationschaltungen nicht dargestellt.
Der Hamming-Decoder gestaltet sich ähnlich: Der empfangene, serielle Bitdatenstrom von den Codewörtern wird in ein entsprechendes LFSR geschoben und gleichzeitig in einer separaten Schieberegisterkette zwecks Latenzanpassung geschoben. Der Inhalt des LFSR beim Decoder dient nach dem kompletten Empfang eines Codewortes als Adresszeiger in einem Syndromspeicher, welcher meist als eine fixe ROM-Tabelle in der Schaltung realisiert ist. Der Datenausgang des Syndromspeichers wirkt dabei direkt auf den seriellen Datenstrom der Datenbits ein und korrigiert bei Bedarf fehlerhaft erkannte Datenbitstellen durch Invertieren.
Decodierung
Bei der Decodierung können verschiedene Verfahren angewendet werden die sich in der Komplexität des Decoders und Decoderleistung unterscheiden. Ein wesentliches Verfahren basiert auf der oben ermittelten Syndromtabelle welche Aufschluss darüber gibt, welche Stelle im Codewort falsch ist. Dies ist bei empfangenen oder gelesenen binären Symbolen ein relativ einfaches Verfahren. Allerdings ist kein allgemeines Verfahren bekannt, mit dem ein linearer Blockcode beliebiger Codewortlänge deterministisch in Polynomialzeit decodierbar wäre. Bei einem (N,n)-Hamming-Code ist der Decodierungsaufwand von der Codewortlänge N abhängig und steigt exponentiell. Durch Verwendung des Syndroms bei der Decodierung lassen sich die Anzahl der möglichen Fehlerkombinationen von 2N auf 2n reduzieren. In der Komplexitätstheorie wird die Zeitklasse jener Entscheidungsprobleme als NP-hart bezeichnet.
Ein weitere Möglichkeit die Decodierungsleistung zu verbessern, besteht in dem Umstand, dass in realen Nachrichtensystemen der Decoder die einzelnen Codewörter im Regelfall nicht als binäre, sondern als mehrstufige Signale erhält. Die empfangenen analogen Signale werden von einem vorgeschalteten Analog-Digital-Umsetzer zunächst quantisiert. Die entstehenden Abstufungen des Signals zwischen logisch-0 und logisch-1 werden vom Decoder als Wahrscheinlichkeiten aufgefasst und das Codewort anhand dieser iterativ konstruiert. Diese Verfahrensweise wird in der meist englischsprachigen Fachliteratur als Soft-Decision bezeichnet und bewirkt einen höheren Codegewinn.
Das Gegenstück dazu ist die so genannten Hard Decision welche als ein Extremfall der Soft Decision aufgefasst werden kann. Dabei wird das analoge Empfangssignal vor der Decodierung mittels 1-Bit breiten Analog-Digital-Umsetzer, einem so genannten Komparator, als ein digitales Eingangssignal für die Codewörter abgebildet. Damit ist bereits vor der Decodierung festgelegt ob ein bestimmtes Bit des empfangenen Codewortes logisch-'1' oder logisch-'0' ist.
Decodierung mittels Hard Decision
In diesem Fall liegen die empfangenen Codewörter bereits als digitale Folgen vor, weshalb sich der Decodierprozess in einem einstufigen Prozess auf die Auswertung der Syndromtabelle reduziert. Dieses Verfahren wird großteils dann verwendet, wenn der Decoder möglichst einfach gestaltet sein soll und keine so genannten verketteten Codes, bestehend aus Kombinationen unterschiedlicher Hamming-Codes, zum Einsatz kommen.
Bei der oben eingeführten Darstellung mittels Kontrollmatrix wurde bereits erläutert, dass das Produkt aus empfangenen Codewort c und der Kontrollmatrix bei einem Fehler einen Wert ungleich 0 annimmt:
Durch entsprechende Anordnung der Parity-Stellen, und damit in Folge der Form der Kontrollmatrix, lässt sich im einfachsten Fall der Wert dieser Gleichung als Syndrom direkt zur Korrektur der betreffenden Bitstelle verwenden. Wenn diese Gleichung bei (7,4)-Hamming-Code den Wert 1 liefert, ist genau das erste Bit des empfangenen Codewortes falsch. Bei dem Wert 2 der Gleichung das zweite Bit, und so weiter. Durch Negation der betreffenden Bitstelle im Codewort kann der Fehler korrigiert werden. Im fehlerfreien Fall liefert obige Gleichung den Wert 0 und keine Bitstelle wird korrigiert.
Diese einfache Übereinstimmung von Syndromwert zu fehlerhafter Bitstelle ist bei einem Hamming-Code nur dann der Fall, wenn sich die einzelnen Parity-Bits genau an den Positionen im Codewort befinden, welche Zweierpotenzen darstellen. Dies ist bei der eingangs dargestellten Generatormatrix G der Fall. Damit entfällt eine Syndromtabelle (ROM-Tabelle) welche erst den jeweiligen Wert der Gleichung von Kontrollmatrix und Codewort auf eine bestimmte Bitposition umsetzt. Diese Vereinfachung für die Decodierung ist auch der Grund, warum Hamming-Codes in Beispielen meistens in der oben dargestellten Form der Generatormatrix G vorgenommen werden.
Zur Decodierung des oben dargestellten separierbaren (7,4)-Hamming-Code mit seiner Kontrollmatrix H′ ist hingegen zur Ermittlung der fehlerhaften Stelle im Codewort eine Umsetzung des Wertes aus der Prüfgleichung notwendig. Im fehlerfreien Fall liefert die Prüfgleichung, so wie bei allen Hamming-Codes, den Wert 0. Im Fehlerfall liefert sie einen Wert ungleich 0 welcher nicht der fehlerhaften Bitstelle im Codewort entsprechen muss. Die Umsetzung auf die fehlerhafte Bitstelle kann mittels eines ROM-Speichers erfolgen, dessen Adressen den Wert der Prüfmatrix erhält und die Datenausgänge angeben welche Bitstelle durch Invertierung zu korrigieren ist. Im Fall des oben angegebenen separierbaren (7,4)-Hamming-Code muss der ROM-Speicher folgenden Dateninhalt aufweisen:
Eingabewert
(ROM-Speicheradresse)Ausgabewert
(Fehlerhafte Bitposition im Codewort)0 0 1 5 2 6 3 1 4 7 5 2 6 3 7 4 Erweiterter Hamming-Code
Da der Hamming-Code nur einen Bitfehler pro Datenwort erkennen und korrigieren kann und zwei Bitfehler pro Datenwort bei dem Decoder zu einem falschen Codewort führen, besteht der Wunsch diese Eigenschaften zu verbessern. Dieser Code wird als so genannter erweiterter Hamming-Code (engl. extended Hamming Code) bezeichnet. Dazu wird bei dem Hamming-Code ein weiteres Parity-Bit angefügt, in dem alle binäre Stellen des nicht erweiterten Hamming-Code einfließen. Damit wird beispielsweise aus dem (7,4)-Hamming-Code ein erweiterter (8,4)-Hamming-Code.
Die Erweiterung eines allgemeinen Blockcodes um eine zusätzliche Kontrollstelle macht nur Sinn, wenn das sogenannte Codegewicht ungerade ist, da nur dann zusätzliche Information in diesem zusätzlichen Kontrollbit vorhanden ist. Dies ist bei Hamming-Codes mit einem Codegewicht von 3 immer erfüllt. Damit wird der Hamming-Abstand bei dem erweiterten Hamming-Code von drei auf vier erhöht und der erweiterte Hamming-Code kann folgende Fehler pro Codewort erkennen bzw. korrigieren:
- Es kann beliebig positionierte einzelne Bitfehler erkennen und korrigieren. In diesem Fall ist der Syndromwert ungleich 0 und das zusätzliche Parity-Bit 1.
- Er kann beiliebig positionierte zweifache Bitfehler erkennen aber nicht mehr korrigieren. In diesem Fall ist der Syndromwert ungleich 0 und das zusätzliche Parity-Bit 0.
- Es kann alle dreifache Bitfehler entweder als ungültiges Codewort erkennen, weist bei der Decodierung ein gültiges Codewort zu welches nicht gesendet wurde. Oder erkennt dreifache Bitfehler die nicht korrigiert werden können. Welcher Fall eintritt hängt von den Position der drei Bitfehler im Codewort ab. Im ersten Fall ist der Syndromwert ungleich 0 und das zusätzliche Parity-Bit 1, im zweiten Fall ist der Syndromwert 0 und das zusätzliche Parity-Bit 1.
- Vierfache Bitfehler eines Codewortes werden entweder als ungültiges und korrierbares Codewort wie im ersten Punkt erkannt und einem gültigen Codewort zugewiesen welches nicht gesendet wurde. Oder es wird unmittelbar ein gültiges Codewort, welches gar nicht gesendet wurde, empfangen. Welcher Fall eintritt hängt auch in diesem Fall davon ab, an welchen Bitpositionen im Codewort die Bitfehler auftreten. Im ersten Fall ist der Syndromwert ungleich 0 und das zusätzliche Parity-Bit 0. Im zweiten Fall ist der Syndromwert 0 und das zusätzliche Parity-Bit 0, was einem gültigen Codewort entspricht. In allen Fällen werden bei vierfachen Bitfehlern andere als die gesendeten Codewörter ausgegeben, was als Decodierversagen bezeichnet wird.
Für den Decoder von erweiterten Hamming-Codes welcher nur mittels Hard-Decision arbeitet lässt sich damit folgende Wahrheitstabelle aufstellen, nach deren Eingangsgrößen in Form des Syndromvektors und der zusätzlichen Parity-Prüfung der Decoder entscheiden kann ob kein Fehler, ein korrigierbarer Fehler oder ein nicht korrigierbarer Fehler vorliegt:
Syndromvektor zusätzliche Parity-Prüfung Aktion des Decoders Empfangenes Codewort = 0 0 kein Fehler gültig ≠ 0 1 korrigierbarer Fehler ungültig = 0 1 korrigierbarer Fehler (im Parity-Bit) ungültig ≠ 0 0 erkannter, nicht korrigierbarer Fehler ungültig Der erweiterte Hamming-Code ist kein perfekter Code, da nicht mehr alle ungültigen Codewörter eindeutig gültigen Codewörtern zugeordnet werden können. Was in den Fällen mit erkannten aber nicht korrigierbaren Datenfehlern passiert, müssen weitere Verarbeitungsebenen nach dem Hamming-Decoder entscheiden. Weiters kann bei drei oder mehr Bitfehlern pro Codewort so genanntes Decodierversagen auftreten. Das heißt, diese Mehrfachfehler werden entweder nicht erkannt oder nicht gesendeten gültigen Codewörtern zugewiesen. Dies ist vor allem bei Hamming-Codes mit langen Codewörtern zu beachten, da sich dieses Verhalten durch Wahl der Codewortlänge nicht verändert.
Anwendung findet der erweiterte Hamming-Code beispielsweise als so genannter innerer Blockcode in Turbo-Product-Codes, wie sie in drahtlosen Funknetzen zur Datenübertragung nach dem Standard IEEE 802.16 im Rahmen von WiMAX auf der Funkschnittstelle verwendet werden.
Codeverkürzung
Sowohl der Hamming-Code als auch der erweiterte Hamming-Code können in der Länge ihrer Codewörter verkürzt werden, um in Anwendungen Codewörter mit bestimmter, fixer Länge zu erhalten. Dies wird als Codeverkürzung bezeichnet. Alle Hamming-Codes weisen, wie dargestellt, nur vergleichsweise wenige wählbare Codewortlängen in groben Schrittweiten zu 2k-1 auf, wobei k ganzzahlig und größer 1 gewählt werden muss. Dazwischenliegende Codewortlängen sind bei dem Hamming-Code nicht möglich.
Durch das Verfahren der Codeverkürzung werden Codewortlängen zwischen diesen einzelnen groben Stufen wählbar, allerdings wird dieser Vorteil je nach Verfahren entweder durch ein schlechteres Verhältnis von Datenbitstellen (Nutzdaten) zur der Anzahl der Kontrollstellen im Codewort erkauft, oder es wird durch das Verfahren die Mindestdistanz des Codes und damit seine Korrekturleistung reduziert.
Zur Codeverkürzung können grundsätzlich bei allen Codes folgende Verfahren zur Anwendung kommen:
- Es werden auf Seite des Encoders nur jene möglichen Codewörter ausgewählt und in Folge als gültige Codewörter verwendet, welche an den ersten oder letzten Stellen des Codewortes immer logisch-0 sind. Je nach gewünschter resultierender Codewortlänge wird eine entsprechende Anzahl an Stellen ausgewählt, zwischen Encoder und Decoder vereinbart und im Verfahren nicht mehr geändert. Durch den Umstand das die weggelassenen Stellen immer bekannte Werte aufweisen, müssen sie nicht mehr übertragen bzw. gespeichert werden: Das resultierende Codewort ist in seiner Länge verkürzt. Bei diesem Verfahren bleibt die Mindestdistanz des Hamming-Code von drei und somit seine Korrekturleistung erhalten. Es stellt sich allerdings ein ungünstigeres Verhältnis von Datenbitanteil zur Kontrollbitanteil im Codewort ein. Dies bedeutet, dass jene verkürzten Hamming-Codes einen größeren Anteil von Kontrollstellen (Parity-Bits) im Codewort aufweisen als im Optimum bei Hamming-Codes mit unverkürzten Codewortlänge nötig wäre.
- Es werden ausgewählte Stellen des Codewortes auf Seite des Encoder punktiert, das heißt gelöscht und auf einen fix Wert von entweder logisch-1 oder logisch-0 gesetzt. Durch den Umstand des fixen Wertes müssen die entsprechenden Binärstellen nicht mehr übertragen bzw. gespeichert werden, es ergibt sich eine entsprechende Längenreduktion des resultierenden Codewortes. Je nach Wahl der Stellen im Codewort ergeben sich unterschiedlich starke Reduktionen der Mindestdistanz des Codes. Da bei Hamming-Codes der Mindestabstand immer drei ist, würde eine Punktierung zu einem vollständigen Verlust der Korrekturleistung führen. Punktierungen haben daher bei Blockcodes wie dem Hamming-Code keine praktische Bedeutung und finden sich typischerweise bei Faltungscodes mit entsprechend hohen Mindestabstand.
Praktische Anwendungen von verkürzten und erweiterten Hamming-Codes finden sich beispielsweise bei der Korrektur von einfachen Speicherfehlern und der sicheren Detektion von zweifachen Speicherfehlern pro Adresse bei DRAM-Speichern. Diese kostengünstigen Speicher weisen pro Bit nur einen kleinen Kondensator zur Datenspeicherung auf und es kann durch Störeffekte relativ leicht zur Bitfehlern kommen. Handelsübliche Speichermodule weisen pro Speicheradresse eine Datenbusbreite von typischerweise 36 Bit oder 72 Bit auf − beides sind Werte welche nicht direkt durch entsprechende Codewortlängen des Hamming-Codes erreicht werden können.
Durch die Codeverkürzung nach dem ersten Verfahren kann relativ einfach ein verkürzter Hamming-Code mit genau passender Codewortlänge konstruiert werden. In Applikationsschriften der Firma Xilinx zur Fehlerkorrektur mittels Hamming-Codes [2] wird von einem erweiterten Hamming-Code mit den Parametern (128,120) als Basis ausgegangen. Daraus wird ein verkürzter Hamming-Code (72,64) gebildet, dessen Codewortlänge exakt der Datenbusbreite des DRAM-Speichermoduls entspricht und 64 Nutzdatenbits pro Adresse speichern kann. Dabei werden alle Parity-Bits des (128,120) Hamming-Codes in das auf 72 Stellen verkürzte Codewort übernommen. Die Datenbitstellen 65 bis 120 sind immer auf logisch-0 gesetzt und werden nicht gespeichert.
Weitere Zahlensysteme
Bei dem im Artikel vorgestellten binären Hamming-Code gibt es nur zwei mögliche Zustände pro Stelle des Datenwortes oder Codewortes (genau das bedeutet „binär“). In der Zahlentheorie wird dieser Umstand mittels Galois-Körpern der Charakteristik zwei, abgekürzt GF(2), ausgedrückt. Besondere Eigenschaft aller binärer, fehlerkorrigierender Codes ist, dass bereits die Ermittlung der Fehlerposition zur Fehlerkorrektur ausreicht: Da nur zwei mögliche Zustände pro Stelle existieren, kann ein Fehler mit ermittelter Position immer durch Inversion der betreffenden Stelle korrigiert werden.
Neben den binären Hamming-Code gibt es auch Verallgemeinerungen auf weitere, höhere Zahlensysteme wie beispielsweise den ternären Hamming-Code in GF(3). Der ternäre Hamming-Code weist pro Stelle drei Zustände auf: {0, 1, 2}. Zur Fehlerkorrektur ist bei allen nicht-binären Codes, neben der Lokalisierung der Fehlerposition, auch eine zusätzliche Information, auf welche der anderen Möglichkeiten eine bestimmte Stelle geändert werden muss, nötig.
Allgemein lassen sich auch Hamming-Codes auf Galois-Körpern GF(p) bilden, wobei p eine Primzahl sein muss (p ∈ {2, 3, 5, 7, ...}).
Literatur
- Martin Bossert: Kanalcodierung. Teubner, 1998, ISBN 3-519-16143-5.
- Todd K. Moon: Error Correction Coding. John Wiley & Sons Inc., 2005, ISBN 0-471-64800-0.
- André Neubauer: Kanalcodierung. J.Schlembach Fachverlag, 2006, ISBN 3-935340-51-6.
- Hermann Rohling: Einführung in die Informations- und Codierungstheorie. Teubner, 1995, ISBN 3-519-06174-0.
Einzelnachweise
- ↑ Richard W. Hamming: Error Detection and Error Correction Codes. The Bell System Technical Journal, Vol. XXVI 2, 1950, Seite 147-160.
- ↑ Fehlererkennung mittels verküztem Hamming-Code, Firmenschrift (engl.)
Weblinks

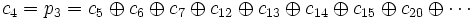
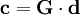
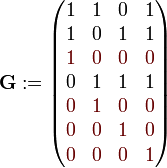
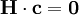
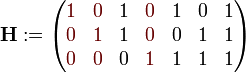
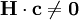
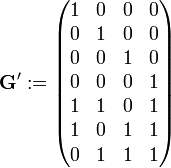
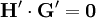
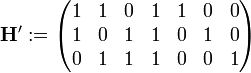

Wikimedia Foundation.