- Generation language
-
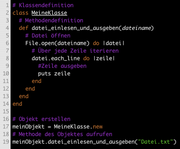 Quelltext eines Programms in der objektorientierten Programmiersprache Ruby.
Quelltext eines Programms in der objektorientierten Programmiersprache Ruby.Eine Programmiersprache ist eine Notation für Computerprogramme; sie dient sowohl dazu, diese während und nach ihrer Entwicklung (Programmierung) darzustellen als auch dazu, die daraus resultierenden Programme zur Ausführung an Rechensysteme zu übermitteln. Da nur die Maschinensprache vom Rechner unmittelbar ausführbar ist, bedürfen Programme in jeder anderen Programmiersprache einer maschinellen Weiterverarbeitung durch Übersetzung oder Interpretation; eine Programmiersprache muss also für eine maschinelle Analyse geeignet sein, was zahlreiche Einschränkungen zur Folge hat.
Programmiersprachen sollen die Programmierung nicht nur ermöglichen, sondern so gut wie möglich erleichtern. So hat sich die Entwicklung der Programmiersprachen seit den 1940er Jahren im Spannungsfeld von Übersetzbarkeit und Bequemlichkeit (Lesbarkeit, Knappheit, Sicherheit etc.) vollzogen. Dieses Spannungsfeld besteht auch zwischen Universalität und Anwendungsorientierung, denn je näher eine Programmiersprache an der Anwendung ist, desto bequemer und leichter ist sie anzuwenden, desto enger ist aber auch in der Regel ihr Anwendungsgebiet und desto unwirtschaftlicher ist sie.
Inhaltsverzeichnis
Übersicht
In der Regel hat jeder Rechnertyp seine eigene Maschinensprache, die man aber nur selten direkt benutzt; meist setzt man Hilfsprogramme ein (summarisch Assembler genannt), um in einer lesbareren (Assembler-) Sprache zu programmieren. Diese Programme erledigen unter anderem:
- Das Abzählen von Speicherzellen und Führen der Speicherbelegungstabelle,
- die Umwandlung von Zahlen, Texten, Maschinenbefehlen und (symbolischen) Adressen in die (binäre) Interndarstellung,
- das textliche Einfügen vorformulierter und parametrisierbarer Programmabschnitte (Makros)
Ein anderes Hilfsprogramm, der Binder, erlaubt es zudem, ein Programm um bereits übersetzte Unterprogramme zu ergänzen. Beide Möglichkeiten zusammengenommen erlauben eine Programmierung unter weitgehender Befreiung von repetitiven Details, wenn die entsprechenden Unterprogramme und Makros erst einmal geschrieben sind.
Fast immer ist es die Ein-/Ausgabe-Programmierung, die so als erstes dem gewöhnlichen Programmierer abgenommen wird, weil sie als besonders schwierig gilt, danach kommen mathematische Unterprogramme, deren Definition einigermaßen klar ist. Auf andere Gebiete ließen sich diese Methoden hingegen nicht mit vergleichbarem Erfolg übertragen.
Von dort zu einer einfachen höheren oder problemorientierten Sprache zu gelangen, ist kein großer Schritt mehr; Fortran beispielsweise bietet zunächst zusätzlich nur die Möglichkeit, einfach geformte arithmetische Ausdrücke in Folgen von Maschinenbefehlen zu übersetzen. So gab es schon bald eine große Zahl an Spezialsprachen für die verschiedensten Anwendungsgebiete, auch die Klassiker, Fortran, Lisp und Cobol, fingen so an. Damit steigt die Effizienz der Programmierer und die Portabilität der Programme; dafür nimmt man eine anfänglich erheblich geringere Leistungsfähigkeit der erzeugten Programme in Kauf. (Inzwischen hat man hier große Fortschritte gemacht.) Manche Sprachen sind so erfolgreich, dass sie wachsen und breitere Anwendung finden; immer wieder sind auch Sprachen mit dem Anspruch entworfen worden, Mehrzweck- und Breitbandsprachen zu sein, oft mit bescheidenem Erfolg (PL/1, Ada, Algol 68).
Nach der Entwicklung von Algol 60, nur einige Jahre nach Fortran, begann man zu fragen, welches Berechnungsmodell zweckmäßig zugrundezulegen und wie es systematisch auszugestalten sei (vgl. ISWIM).
- In der Rückschau kann man die bisherige Entwicklung der Programmiersprachen in Generationen einteilen, siehe das eigene Unterkapitel weiter unten.
Panorama
Die überragende Bedeutung von Programmiersprachen für die Informatik drückt sich auch in der Vielfalt der Ausprägungen und der Breite der Anwendungen von Programmiersprachen aus.
- Systemprogrammiersprachen, Assemblersprachen, C, Bliss usw. erlauben eine hardwarenahe Programmierung.
- CNC-Programmiersprachen dienen der Erzeugung von Steuerungsinformationen für Werkzeugmaschinen.
- Datenbanksprachen sind für den Einsatz in und die Abfrage von Datenbanken gedacht.
- Skriptsprachen dienen zur einfachen Steuerung von Rechnern, wie bei der Stapelverarbeitung.
- Sprachen mit visuellen Programmierumgebungen erleichtern die graphische Gestaltung von Benutzeroberflächen.
- Esoterische Programmiersprachen sind experimentelle Sprachen mit teilweise interessanten Konzepten.
Beispiel
Die durch eine Programmiersprache ausgedrückte, von einem Menschen lesbare Beschreibung heißt Quelltext (oder auch Quellcode oder Programmcode) (Beispiel Hallo Welt!). Jeder Benutzer muss die Bearbeitung von Problemen, die er einem Computer übergibt, in einem Programm formulieren. Das Erstellen dieser Computerprogramme nennt man Programmieren und den Ersteller Programmierer, wenn das Programmieren industriell erfolgt auch Softwaretechniker. Der entstandene Quelltext wird anschließend in eine Anweisungsfolge für den Computer übersetzt, die Maschinensprache des Computers auf dem das Programm läuft. Bevor das Programm, das der Programmierer schreibt, von einem Computer ausgeführt werden kann, muss es in eine vom Computer verständliche Folge von Bits, umgesetzt werden. Dies kann entweder offline durch einen Compiler oder – zur Laufzeit – durch einen Interpreter oder JIT-Compiler geschehen. In vielen Fällen wird mittlerweile eine Kombination aus beiden Varianten gewählt, bei der zuerst - meist vom Programmierer - der Quelltext der eigentlichen Programmiersprache in einen abstrakten Zwischencode übersetzt wird, welcher dann zur Laufzeit von einer sogenannten Laufzeitumgebung durch einen Interpreter oder JIT-Compiler in den eigentlichen Maschinencode überführt wird. Dieses Prinzip hat den Vorteil, dass ein und derselbe Zwischencode auf sehr vielen verschiedenen Plattformen ausführbar ist und somit nicht für jedes auf dem Markt übliche System eine eigene Version der Software erscheinen muss. Typische Beispiele für einen solchen Zwischencode sind der Java-Bytecode sowie die Common Intermediate Language. Mittels eines Debuggers kann die Funktionsweise des Programms zur Laufzeit verfolgt werden. Der Debugger ermöglicht in der Regel eine Ablaufverfolgung des zu untersuchenden Programmes in einzelnen Schritten oder zwischen definierten Haltepunkten und ist oft Bestandteil einer Programm-Entwicklungsumgebung.
Programmiersprachen wie C++, Java, Perl oder auch PHP arbeiten mit Begriffen, die Menschen leichter zugänglich sind. Bei der Programmierung wird dann auf der Grundlage der Begrifflichkeit der jeweiligen Programmiersprache ein so genannter Quellcode erstellt. Dieser ist im Vergleich zum Maschinencode besser verständlich, muss aber im nächsten Schritt noch in die maschinen-lesbare binäre Form gebracht werden. Im Gegensatz zur Assemblersprache oder Hochsprachen handelt es sich bei Maschinencode um einen für den Menschen kaum lesbaren Binärcode, der nur von Experten für den jeweiligen Code gelesen wird und zum Beispiel mit speziellen Programmen, so genannten Maschinensprachemonitoren (abgekürzt auch einfach Monitor genannt), bearbeitet werden kann. Der Maschinencode wird meist von einem Assembler oder Compiler erzeugt. Direkt in Maschinensprache muss nur programmiert werden, wenn kein Assembler für den Zielprozessor zur Verfügung steht. Wird von der Programmierung in Maschinensprache gesprochen, wird heute üblicherweise die Maschinenprogrammierung in Assemblersprache unter Verwendung eines Assemblers gemeint, der das als Textdatei vorliegende Assemblerprogramm in binäre Maschinenbefehle übersetzt. Das ist nicht direkt vergleichbar mit dem Übersetzen von natürlichen Sprachen, da dort aufgrund der Kulturabhängigkeit auch linguistische Phänomene eine Rolle spielen; bei Programmiersprachen dagegen kann (und wird im Allgemeinen) das Übersetzen mittels eines Übersetzungsprogramms automatisiert werden und ist so fehlersicherer im Übersetzen als eine Fremdsprache, da der Rechner die Syntax prüft. Das Endprodukt dieser Übersetzung nennt man Binärdatei, da es aus 0 und 1 besteht, der Sprache des Computers. Jede Software ist im Prinzip eine definierte, funktionale Anordnung der oben geschilderten Bausteine Berechnung, Vergleich und Bedingter Sprung, wobei die Bausteine beliebig oft verwendet werden können. Diese Anordnung der Bausteine, die als Programm bezeichnet wird, wird in Form von Daten im Speicher des Computers abgelegt. Von dort kann sie von der Hardware ausgelesen und abgearbeitet werden. Da digitale Computer intern nur die Werte 0 und 1 verarbeiten, wäre es nach heutigen Maßstäben extrem umständlich und mühsam, die vielen Formen der Informationsverarbeitung als Binärzahlen einzugeben (zu kodieren). Daher wurden in den letzten Jahrzehnten Verfahrensweisen etabliert, nach denen man häufig verwendete Zahlen und Zeichen und häufig verwendete grundlegende Operationen in symbolischen Befehlen angibt.
Typsystem
siehe Hauptartikel: Typsystem
- Daten, Datentypen und Typisierung
Fast alle Programmiersprachen kennen Typangaben im Programmtext (die sich auf Programmteile oder auch Werte beziehen können). Damit werden vor allem zwei Zwecke verfolgt:
- Deskriptiv dienen Typangaben der Erleichterung der Programmierung und Entlastung der Notation; es braucht so nicht jede Operation vollständig spezifiziert zu werden.
- Präskriptiv dienen sie dazu, bestimmte Operationen auszuschließen, durchaus nicht nur zur Fehlervermeidung, sondern (vor allem im Zusammenhang mit Abstrakten Datentypen) auch zur Zusicherung von Sicherheitseigenschaften.
So erspart eine Feldvereinbarung nicht nur (deskriptiv) die Angabe der Speicherabbildungsfunktion bei jedem Zugriff, sondern erlaubt (präskriptiv) auch die automatische Prüfung auf Einhaltung der Feldgrenzen. Das sichere Typsystem der Programmiersprache ML bildet die Grundlage für die Korrektheit der in ihr programmierten Beweissysteme (LCF, HOL, Isabelle); in ähnlicher Weise versucht man jetzt auch die Sicherheit von Betriebssystemen zu gewährleisten.[1] Schließlich ermöglichen erst Typangaben das populäre Überladen von Bezeichnern.
Nach Strachey sollte das Typsystem im Mittelpunkt der Definition einer Programmiersprache stehen.
Die Definition von Daten erfolgt im Allgemeinen durch die Angabe einer konkreten Spezifikation zur Datenhaltung und der dazu nötigen Operationen. Diese konkrete Spezifikation legt das allgemeine Verhalten der Operationen fest und abstrahiert damit von der konkreten Implementation der Datenstruktur (s. a. Deklaration (Programmierung)).
Um die üblichen Arten von Informationen im Computer abbilden zu können, müssen Möglichkeiten zur Definition von Daten oder Datenstrukturen bereitstehen, auch als Datentyp bezeichnet. Hierbei kann zwischen typisierten (zum Beispiel C++ oder Java) und typenlosen Sprachen (zum Beispiel JavaScript, Tcl oder Prolog) unterschieden werden. Bei typisierten Sprachen sind dies entweder vordefinierte Einheiten für einzelne Zahlen (Byte, Integer, Word, etc.) und Zeichen (Char) oder auch zusammengesetzte für Daten, Wörter, Text, sensorische Information und so weiter (Strukturen, Klassen). Zumeist besteht auch die Möglichkeit, zusammengesetzte Objekte oder Strukturen aufzubauen und als neuen Typ zu vereinbaren (etwa Arrays, Listen, Stacks, ganze Dateien). Die typenlosen Sprachen behandeln oftmals alle Einheiten als Zeichenketten und kennen für zusammengesetzte Daten eine allgemeine Liste (zum Beispiel Perl). Bei den typisierten Sprachen gibt es solche mit Typprüfungen zur Übersetzungszeit (statisch typisiert) und solche in denen Typprüfungen primär zur Laufzeit stattfinden (dynamisch typisiert, etwa Ruby, Smalltalk). Werden Typfehler spätestens zur Laufzeit erkannt, spricht man von typsicheren Sprachen. Oft wird fälschlicherweise die statische Typprüfung wegen des angenommenen qualitativen Vorteils gegenüber der dynamischen Typprüfung als sicher bezeichnet.
Es kann keine allgemeine Aussage über die Tauglichkeit beider Formen der Typprüfung getroffen werden – bei statischer Typprüfung ist der Programmierer versucht, diese zu umgehen, bzw. sie wird erst gar nicht vollständig durchgesetzt (zum jetzigen Stand der Technik muss es in jeder statischen Sprache eine Möglichkeit geben, typlose Daten zu erzeugen oder zwischen Typen zu wechseln – etwa wenn Daten vom Massenspeicher gelesen werden), in Sprachen mit dynamischer Typprüfung werden manche Typfehler erst gefunden, wenn es zu spät ist. Bei dynamischer Typprüfung wird jedoch der Programmcode meist sehr viel einfacher. Oft kann an den Bürgern erster Klasse (First class Citizens – FCCs) einer Programmiersprache – also den Formen von Daten, die direkt verwendet werden können, erkannt werden, welchem Paradigma die Sprache gehorcht. In Java z. B. sind Objekte FCCs, in LISP ist jedes Stück Programm FCC, in Perl sind es Zeichenketten, Arrays und Hashes. Auch der Aufbau der Daten folgt syntaktischen Regeln. Mit so genannten Variablen kann man bequem auf die Daten zugreifen und den dualen Charakter von Referenz und Datum einer Variablen ausnutzen. Um die Zeichenketten der Daten mit ihrer (semantischen) Bedeutung nutzen zu können, muss man diese Bedeutung durch die Angabe eines Datentyps angeben. Zumeist besteht im Rahmen des Typsystems auch die Möglichkeit neue Typen zu vereinbaren. Bei Java heißen Datentypen Klassen. LISP verwendet als konzeptionelle Hauptstruktur Listen. Auch das Programm ist eine Liste von Befehlen, die andere Listen verändern. Forth verwendet als konzeptionelle Hauptstruktur Stacks und Stackoperationen sowie ein zur Laufzeit erweiterbares Wörterbuch von Definitionen, und führt in den meisten Implementationen überhaupt keine Typprüfungen durch.
Wird der Schwerpunkt der Betrachtung auf die konkrete Implementation der Operationen verschoben, so wird anstelle des Begriffs Datenstruktur auch häufig von einem Abstrakten Datentypen gesprochen. Der Übergang von der Datenstruktur zu einem Abstrakten Datentyp ist dabei nicht klar definiert, sondern hängt einzig von der Betrachtungsweise ab. Von den meisten Datenstrukturen gibt es neben ihrer Grundform viele Spezialisierungen, die eigens für die Erfüllung einer bestimmten Aufgabe spezifiziert wurden. So sind beispielsweise B-Bäume als Spezialisierung der Datenstruktur Baum besonders gut für Implementationen von Datenbanken geeignet.
Implementation von Programmiersprachen
siehe Hauptartikel: Übersetzerbau
Die Tätigkeit eines Übersetzers kann als eine Folge von Transformationen („Phasen“) veranschaulicht werden, die ein „Quellprogramm“ stufenweise in ein „Objektprogramm“ umwandeln, auch wenn diese in der Praxis ineinander verschachtelt ablaufen. Das Quellprogramm ist dabei eine Zeichenfolge, die einer (kontextfreien) Grammatik genügt (der „Syntax“ einer Programmiersprache); die Größe einer solchen „Übersetzungseinheit“ liegt zwischen einer einzelnen Anweisung für interaktive Sprachen und einem ganzen Programm, ist meist aber ein Unterprogramm oder Modul („modulare Programmierung“).
Frontend
Als Frontend bezeichnet man die analytischen Phasen, die hauptsächlich von der Programmiersprache bestimmt sind.
- Die Symbolerkennung liest die Eingabe von links nach rechts (daher Scanner) und erkennt dabei einfache, durch reguläre Ausdrücke beschriebene Zeichenfolgen, z. B. „3.1415“ (Zahl), „if“ (Wortsymbol), „MainWindow“ (Bezeichner), „+“ (Operator), „{“ (Sonderzeichen). Die Bezeichner und Literale werden dabei in einer Symboltabelle abgelegt bzw. nachgesehen.
- Die Phrasenerkennung (Parser) erhält eine Folge von (Terminal-) Symbolen (tokens) als Eingabe und rekonstruiert daraus den dazugehörigen Ableitungsbaum. Insgesamt ist dies wesentlich schwieriger als die Symbolerkennung; dazu trägt einerseits die rekursive Struktur der Grammatik bei. Andererseits treten an die Stelle von Eingabezeichen Terminal- und Nichtterminalsymbole. Letztere bilden die Knoten des Ableitungsbaumes und stellen jeweils einen erkannten („reduzierten“) Ableitungsschritt dar.
- Die Symboltabelle enthält die in einer Übesetzungseinheit gebrauchten sowie die aus einem Bibliotheksmodul importierten Bezeichner. Der Zugriff erfolgt dabei unter Berücksichtigung der Sichtbarkeitsregeln der jeweiligen Sprache.
- Der Ableitungsbaum enthält viele überflüssige Details, etwa zur Implementation von Vorrangregeln („Punkt vor Strich“) oder zur u. U. variantenreichen Strukturierung des Programms („syntactic sugar“). Darum bereinigt man ihn zum „Abstract Syntax Tree“ (AST). Dieser stellt aber zunächst nur ein äußeres Gerüst des Programmes dar.
- Die semantische Analyse ergänzt („dekoriert“) darum den AST durch Informationen aus der Symboltabelle und aus dem Kontext (den übergeordneten Knoten). Zugleich werden die zahlreichen „Kontextbedingungen“ überprüft, die ein korrektes Programm erfüllen muss. So ergänzt wird der AST zur Interndarstellung des Programmes („Programmbaum“).
Compiler und Entwurfsphilosophie
Eine weitere technische Einrichtung übersetzt dann diese Angaben in interne Daten, einfachste Datenänderungsbefehle und Kontrollanweisungen, die der Computer dann schließlich ausführt. Wenn es ausführbar gemacht wurde, bezeichnet man es dann als Programm oder Bibliothek. Je nachdem, ob diese Übersetzung vor oder während der Ausführung des Computerprogramms erfolgt, und ob eine spezielle Ausführungsebene einer virtuellen Maschine an der Ausführung beteiligt wird, unterscheidet man zwischen kompilierenden oder interpretierenden Übersetzungsprogrammen. Wird ein Programmtext als Ganzes übersetzt, spricht man in Bezug auf den Übersetzungsmechanismus von einem Compiler. Der Compiler selbst ist ein Programm, welches als Dateneingabe den menschenlesbaren Programmtext bekommt und als Datenausgabe den Maschinencode liefert, der direkt vom Prozessor verstanden wird (z. B. Objectcode, EXE-Datei) oder in einer Laufzeitumgebung (z. B. JVM oder .NET CLR) ausgeführt wird. Wird ein Programmtext hingegen Schritt für Schritt übersetzt und der jeweils übersetzte Schritt sofort ausgeführt, spricht man von einem Interpreter. Interpretierte Programme laufen meist langsamer als kompilierte.
Es existieren verschiedene Meinungen, welche Eigenschaften eine Programmiersprache besitzen sollte. Allgemein wird jedoch akzeptiert, dass zumindest die grundlegende mathematische Arithmetik ausgedrückt werden können sollte und dass Schleifen und Verzweigungen, manchmal auch in Form von Sprüngen, notwendig sind, da sonst nicht alles Berechenbare berechnet werden kann. Oft ist der von der Programmiersprache vorgegebene Programmierstil und die Zweckgebundenheit der Programmiersprache wichtig. Es wird der eine oder andere Aspekt besonders betont. Mehr Datenstrukturen oder Freiheit in der Notation oder Raffinesse, was Zeigerstrukturen angeht. Die meisten Sprachen bieten eine gute Funktionalität, fordern aber auch ein hohes Maß an Disziplin bezüglich Fehlerfreiheit. Programmiersprachen sind nicht fehlertolerant, was durch Hilfen aber abgemildert wird. Einige wenige Sprachen bieten große gestalterische Freiheiten bis hin zum sich selbst verändernden Programm: dazu gehört Maschinensprache und auch LISP. Eine theoretische Erkenntnis ist die notwendige Eigenschaft der Turing-Vollständigkeit, falls sie die Turing-Berechenbarkeit des Computers ausnutzen soll; dies kann bis hin zum sich selbst verändernden Programm dienen.
Die Softwaretechnik hilft dabei dem Programmierer, diesen Zweck eines Computerprogramms zu realisieren.
Befehle
Ein Computer ist keine starre, nur auf eine Aufgabe spezialisierte Rechenmaschine. Vielmehr wird durch Einzelaktion in Mikroebene angegeben, wie der Computer mit welchen Daten zu verfahren hat. Durch die Reihenfolge der Befehle ist die zeitliche Abfolge vorgegeben. Das Steuerwerk enthält eine Menge von Mikroprogrammen, die jeweils aus einer Liste von Steuersignalen bestehen, die das Verhalten von Prozessorelementen – zum Beispiel der ALU und den Registern – regeln. Bei manchen Prozessoren können die Mikroprogramme auch nachträglich geändert werden. Man könnte die Mikroprogramme auch als Firmware der CPU bezeichnen. Imperative Programmiersprachen bilden dieses Konzept auf Makroebene durch Befehle ab. Um reagierende Programme schreiben zu können, gibt es Sprungbefehle, die die Abfolge der Befehle dynamisch verändern.
Befehle lassen sich semantisch nach dem EVA-Prinzip einteilen.
- Eingabe- oder Ausgabebefehle
- lesen Daten von der Tastatur, von einer Datei oder aus anderen Quellen ein oder sie geben sie auf den Monitor, auf einen Drucker oder in eine Datei aus.
- Berechnungen
- verändern Daten oder sie kombinieren Daten neu. Dies können auch mathematische Berechnungen, wie Addition oder Multiplikation sein.
- Kontrollstrukturen
- entscheiden aufgrund der vorliegenden Daten, welche Befehle als nächstes ausgeführt werden. Insbesondere kann eine Befehlsfolge wiederholt werden.
- Deklarationen
- reservieren Speicherplatz für Variablen, andere Datenstrukturen, Unterprogramme, Methoden oder Klassen unter frei wählbaren Namen, so dass auf sie im Laufe des Programms unter diesen Namen zugegriffen werden kann.
Geschichte

siehe Hauptartikel: Geschichte der Programmiersprachen
Zur Vorgeschichte der Programmiersprachen kann man von praktischer Seite die zahlreichen Notationen zählen, die sowohl in der Fernmeldetechnik (Morsekode) als auch zur Steuerung von Maschinen (Jacquard-Webstuhl) entwickelt worden waren; dann die Assemblersprachen der ersten Rechner, die doch nur deren Weiterententwicklung waren. Von theoretischer Seite zählen dazu die vielen Präzisierungen des Algorithmusbegriffs, von denen der λ-Kalkül die bei weitem bedeutendste ist. Auch Zuses Plankalkül gehört hierhin, denn er ist dem minimalistischen Ansatz der Theoretiker verpflichtet (Bit als Grundbaustein).
In einer ersten Phase wurden ab Mitte der 1950er Jahre unzählige Sprachen[2] entwickelt, die praktisch an gegebenen Aufgaben und Mitteln orientiert waren. Seit der Entwicklung von Algol 60 (1958-1963) ist die Aufgabe des Übersetzerbaus in der praktischen Informatik etabliert und wird zunächst mit Schwerpunkt Syntax (-erkennung, Parser) intensiv bearbeitet. Auf der praktischen Seite wurden erweiterte Datentypen wie Verbunde, Zeichenketten und „Zeiger“ eingeführt (konsequent z. B. in Algol 68).
In den 1950er Jahren wurden in den USA die ersten drei weiter verbreiteten, praktisch eingesetzten höheren Programmiersprachen entwickelt. Dabei verfolgten diese sowohl imperative als auch deklarativ-funktionale Ansätze.
Die Entwicklung von Algol 60 läutete eine fruchtbare Phase vieler neuer Konzepte, wie das der prozeduralen Programmierung ein. Der Bedarf an neuen Programmiersprachen wurde durch den schnellen Fortschritt der Computertechnik gesteigert. In dieser Phase entstanden die bis heute populärsten Programmiersprachen: BASIC und C.
In der Nachfolgezeit ab 1980 konnten sich die neu entwickelten logischen Programmiersprachen nicht gegen die Weiterentwicklung traditioneller Konzepte in Form des objektorientierten Programmierens durchsetzen. Das in den 1990er Jahren immer schneller wachsende Internet forderte seinen Tribut beispielsweise in Form von neuen Skriptsprachen für die Entwicklung von Webserver-Anwendungen.
Derzeit schreitet die Integration der Konzepte der letzten Jahrzehnte voran. Größere Beachtung findet so beispielsweise der Aspekt der Codesicherheit in Form von virtuellen Maschinen. Neuere integrierte, visuelle Entwicklungsumgebungen haben deutliche Fortschritte gebracht, was Aufwand an Zeit, Kosten angeht. Bedienoberflächen lassen sich meist visuell gestalten, Codefragmente sind per Klick direkt erreichbar. Dokumentation zu anderen Programmteilen und Bibliotheken ist direkt einsehbar, meist gibt es sogar lookup-Funktionalität, die noch während des Schreibens herausfindet, welche Symbole an dieser Stelle erlaubt sind und entsprechende Vorschläge macht (Autovervollständigen).
Neben der mittlerweile etablierten objektorientierten Programmierung ist die Model Driven Architecture ein weiterer Ansatz zur Verbesserung der Software-Entwicklung, in der Programme aus syntaktisch und semantisch formal spezifizierten Modellen generiert werden. Diese Techniken markieren gleichzeitig den Übergang von einer eher handwerklichen, individuellen Kunst zu einem industriell organisierten Prozess.
Klassifizierungen
Objektorientierte Programmiersprachen
Hier werden Daten und Befehle in Objekten verpackt. Objektorientierte Programmiersprachen sind sehr verbreitet und häufig. Man programmiert keine Befehlsketten mehr, sondern versucht sie in Objekte aufzuteilen und beachtet dabei eine geringe Kopplung. Beispiel: C#. Objektorientierung wird hauptsächlich im Rahmen der Objektorientierten Programmierung verwendet, um die Komplexität der entstehenden Programme zu verringern. Der Begriff existiert aber auch für andere Aspekte der Softwareentwicklung, wie die Objektorientierte Analyse und Design von Software. Weiterhin gibt es Anwendungen des Konzepts auf Objektorientierte Datenbanken: In einem solchen System werden reale Gegenstände direkt durch Datenbankobjekte repräsentiert. Ihre Identifikation erfolgt über eindeutige und unveränderliche Objektidentifikatoren, welche vom System vergeben werden. Solche Datenbankobjekte können, außer den üblichen, meist numerischen oder alphanumerischen Attributen, Bestandteile haben, die ihrerseits selbst wieder Objekte sind. Sie werden deshalb auch als komplexe Objekte bezeichnet. Es existieren auch Operatoren, mit deren Hilfe mit solchen Objekten umgegangen werden kann. Wird beispielsweise die Information über einen Angestellten im relationalen Datenbankensystem (DBS) über mehrere Relationen verstreut, so wird sie in einem OODBS als Gesamteinheit in einem Datenbankobjekt gehalten. Möchte man nun im Relationenmodell bestimmte Informationen abrufen, so müssen diese unter Umständen aus verschiedenen Relationen zusammengesetzt werden (mit Hilfe der vergleichsweise sehr aufwendigen Verbundoperationen).
Das Konzept der objektorientierten Programmierung kann im Allgemeinen dabei helfen, Programmcode zu modularisieren. Modularisierte Quelltexte sind in vielen Fällen leichter zu warten und können bedarfsgerecht in mehreren Projekten verwendet werden (Wiederverwendbarkeit), ohne den Verwaltungsaufwand zu erhöhen. Im einfachsten Fall dienen Objekte dazu, Dinge der realen Welt zu modellieren (Abstraktion). Echte Vererbungshierarchien sind im wirklichen Leben kaum anzutreffen. Von OOP-Experten wird empfohlen, Vererbungen zu vermeiden. OOP steht mit der Objektorientierung dem Paradigma der relationalen Modellierung von relationalen Datenbanken gegenüber. Relationale Datenbanken und Assoziationen objektorientierter Modelle bilden etwa das gleiche ab. In modernen Systemen sind wegen der hohen Geschwindigkeit die Informationen aus technischer Sicht in relationalen Datenbanken abgelegt, während sie sich aus der Sicht des Anwenders wie ein Objekt verhalten. Die hohe Geschwindigkeit von Transaktionen auf Datenbanken steht dabei den intuitiv zugänglicheren Methoden von Objekten gegenüber.
Die einzelnen Bausteine, aus denen ein objektorientiertes Programm während seiner Abarbeitung besteht, werden als Objekte bezeichnet. Die Konzeption dieser Objekte erfolgt dabei in der Regel auf Basis der folgenden Paradigmen:[3]
- Feedback
- Es steht die Kopplung als Index für den Grad des Feedback.
- Datenkapselung
- Als Datenkapselung bezeichnet man in der Programmierung das Verbergen von Implementierungsdetails.
- Vererbung
- Vererbung heißt vereinfacht, dass eine abgeleitete Klasse die Methoden und Objekte der Basisklasse ebenfalls besitzt, also erbt.
Weiteres dazu in: Objektorientierte Programmierung.
Imperative Programmiersprachen und Deklarative Programmiersprachen
Die derzeit am häufigsten verwendeten, imperativen Programmiersprachen halten eine spezielle Unterscheidung in Form und Funktion für Befehle (oft auch Anweisungen genannt) und Daten und deren Wiederverwendung bereit. Dieser Programmieransatz ist nicht unbedingt notwendig, da ein Computer diese Strukturen prinzipiell nicht unterscheiden kann, hat sich jedoch historisch durchgesetzt. Einen zu den imperativen Programmiersprachen konträren Ansatz verfolgen die deklarativen Programmiersprachen. Dabei beschreibt der Programmierer, welche Bedingungen ein Programm erfüllen muss. Wie etwas zu geschehen hat, ist Aufgabe des Übersetzungsprogramms. Oder anders gesagt: Der Programmierer gibt an, welches Ergebnis gewünscht ist. Die Problemlösung wird dem Computer überlassen.
Programmtexte sind dabei nicht die einzige Möglichkeit, einem Computer mitzuteilen, welche Aufgabe er erfüllen soll. Aus der Sicht der theoretischen Informatik ist ein Programm lediglich ein Schlüssel, mit dessen Hilfe die universelle Maschine, die ein Allzweckcomputer ist, auf eine spezielle Maschinenfunktion eingestellt wird. Da die Menge der berechenbaren Funktionen abzählbar unendlich ist, kann jede abzählbar unendliche Menge als (Syntax einer) Programmiersprache dienen.
Im Extremfall reicht bereits die Angabe einer einzigen natürlichen Zahl n, um die gewünschte Maschinenfunktion zu spezifizieren. (Daher ist dieses n ein Programm und die Menge aller natürlichen Zahlen
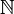 die (Syntax der) einfachste(n) Programmiersprache der Welt). Das ist keine große Einschränkung, d. h. es sind auch andere Arten von Programmen vorstellbar, deren Form nicht die einer abzählbaren Kette von Zeichen ist. Es könnten auch graphische Objekte sein. Schon gar nicht muss ein Programm eine explizite Liste von Anweisungsschritten enthalten (Imperative Programmierung); diese Idee führt u. a. zur deklarativen Programmierung.
die (Syntax der) einfachste(n) Programmiersprache der Welt). Das ist keine große Einschränkung, d. h. es sind auch andere Arten von Programmen vorstellbar, deren Form nicht die einer abzählbaren Kette von Zeichen ist. Es könnten auch graphische Objekte sein. Schon gar nicht muss ein Programm eine explizite Liste von Anweisungsschritten enthalten (Imperative Programmierung); diese Idee führt u. a. zur deklarativen Programmierung.Die Art der formulierten Bedingungen unterteilen die deklarativen Programmiersprachen in logische Programmiersprachen, die mathematische Logik benutzen und funktionale Programmiersprachen, die dafür mathematische Funktionen einsetzen. Deklarative Programmiersprachen haben keine große Popularität und sind oftmals im akademischen Bereich zu finden.
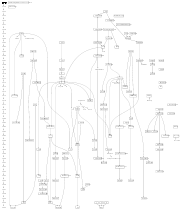 Entwicklungslinien in der Programmiersprachenentwicklung
Entwicklungslinien in der ProgrammiersprachenentwicklungProgrammiersprachen lassen sich in verschiedener Hinsicht klassifizieren. Klassifizierung kommt in nahezu allen Bereichen von Natur und Technik vor. In der Kategorisierung werden Wahrnehmungen klassifiziert; dies ist eine Voraussetzung für Abstraktion und Begriffsbildung und damit letztlich der Intelligenz. Da erst die Klassifizierung realer Informationen geordnete Verarbeitung ermöglicht, ist die Klassifizierung auch zentraler Bestandteil vieler Anwendungen der Informatik. Dort wird die Automatische Klassifizierung als Grundlage der Mustererkennung wissenschaftlich untersucht. Häufig ist die Unterteilung nach Programmierparadigmen, nach Sprachgenerationen oder Anwendungsgebieten.
Ergänzungen
Programmierparadigmen
Paradigmen in Programmiersprachen (Auswahl) Name funktional imperativ objektorientiert deklarativ logisch nebenläufig Ada X X X X C X Prolog X X Scheme X X (X) X (X) Haskell X (X) X (X) Programmierparadigmen dienen zur Klassifikation von Programmiersprachen. Grundlegend sind die Paradigmen der imperativen und der deklarativen Programmierung. Alle weiteren Paradigmen sind Verfeinerungen dieser Prinzipien. Eine Programmiersprache kann mehreren Paradigmen gehorchen.
- Sprachgenerationen
Man hat die Maschinen-, Assembler- und höheren Programmiersprachen auch als Sprachen der ersten bis dritten Generation bezeichnet; auch in Analogie zu den gleichzeitigen Hardwaregenerationen. Als vierte Generation wurden verschiedenste Systeme beworben, die mit Programmgeneratoren und Hilfsprogrammen z. B. zur Gestaltung von Bildschirmmasken (screen painter) ausgestattet waren. Die Sprache der fünften Generation schließlich sollte in den 1980er Jahren im Sinne des Fifth Generation Computing Concurrent-Prolog sein.
Hello World
Ein beliebter Einstieg in eine noch unbekannte Programmiersprache ist es, mit ihr die sehr einfache Aufgabe zu lösen, den Text Hello World (oder deutsch „Hallo Welt“) auf den Bildschirm oder ein anderes Ausgabegerät auszugeben, siehe bei Hallo-Welt-Programm. Entsprechend gibt es Listen und eigene Webseiten[4], die Lösungen in allen möglichen Programmiersprachen gegenüberstellen.
Siehe auch
Literatur
- Friedrich Ludwig Bauer, Hans Wössner: Algorithmische Sprache und Programmentwicklung. Springer, Berlin 11981, 21984, ISBN 3-540-12962-6.
- Peter A. Henning, Holger Vogelsang: Handbuch Programmiersprachen. Softwareentwicklung zum Lernen und Nachschlagen. Hanser, München 2007, ISBN 3-446-40558-5, 978-3-446-40558-5.
- Kenneth C. Louden: Programmiersprachen: Grundlagen, Konzepte, Entwurf. Internat. Thomson Publ., Bonn, Albany [u. a.] 1994, ISBN 3-929821-03-6.
- John C. Reynolds: Theories of Programming Languages. Cambridge Univ. Press, Cambridge 1998, ISBN 0-521-59414-6.
- Peter van Roy, Seif Haridi: Concepts, Techniques, and Models of Computer Programming. Mass.: MIT Press, Cambridge 2004, ISBN 0-262-22069-5.
- 2. ed.Michael L. Scott: Programming language pragmatics. 2. Auflage. Elsevier, Morgan Kaufmann, Amsterdam 2006, ISBN 0-12-633951-1.
Weblinks
- 99 Bottles of Beer: Ein Programm in hunderten von Programmiersprachen bzw. Dialekten (englisch)
- Literate Programs Ein Wiki mit Beispielen in vielen Sprachen (englisch)
Einzelnachweise
- ↑ Vgl. Sprachbasiertes System – z. B. Singularity basierend auf der Programmiersprache Sing#, JX für Java, Coyotos mit der Sprache BitC.
- ↑ Um 1965 zählte man 1700, vgl. ISWIM.
- ↑ Peter A. Henning, Holger Vogelsang: Taschenbuch Programmiersprachen. Fachbuchverlag im Carl Hanser Verlag, Leipzig 2007, ISBN 978-3-446-40744-2.
- ↑ Auflistung von Hello-World-Programmen nach Programmiersprachen


Wikimedia Foundation.