- Statistische Verteilung
-
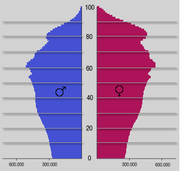 Beispiel einer (absoluten) Häufigkeitsverteilung: prognostizierte Altersverteilung für Deutschland im Jahr 2050
Beispiel einer (absoluten) Häufigkeitsverteilung: prognostizierte Altersverteilung für Deutschland im Jahr 2050Eine Häufigkeitsverteilung ist eine Methode zur statistischen Beschreibung von Daten (Messwerten, Merkmalswerten). Mathematisch gesehen ist eine Häufigkeitsverteilung eine Funktion, die zu jedem vorgekommenen Wert angibt, wie häufig dieser Wert vorgekommen ist. Man kann eine solche Verteilung als Tabelle, als Grafik oder modellhaft über eine Funktionsgleichung beschreiben.
Die Häufigkeitsverteilung ist in der Deskriptiven Statistik, was die Wahrscheinlichkeitsverteilung in der Wahrscheinlichkeitstheorie ist; letztere bietet eine Reihe mathematischer Funktionen, die zur Annäherung und Analyse von Häufigkeitsverteilungen herangezogen werden (wie etwa die Normalverteilung).
Die Datenmenge (Messwerte, Umfragedaten) bildet die zunächst ungeordnete Urliste. Als erstes wird sie geordnet oder sortiert. Aus der geordneten Urliste (Rangliste) lassen sich bereits Medianwert, Spannweite (statistische Streuung), Quantile und Interquantilsabstand entnehmen und die Standardabweichung abschätzen (Faustformel: Standardabweichung = Spannweite/6).
Dann fassen wir gleiche Werte zusammen und notieren zu jedem Wert, wie oft er vorkommt, also seine absolute Häufigkeit. Beziehen wir die absoluten Häufigkeiten auf die Gesamtzahl der Werte, die sog. Stichprobe (Probenumfang), so erhalten wir die relativen Häufigkeiten. Wir haben nun eine geordnete Menge von Wertepaaren (Merkmalswert und zugehörige relative Häufigkeit), eine sogenannte Rangfolge.
Addieren wir - beim kleinsten Merkmalswert beginnend - die relativen Häufigkeiten auf und ordnen jedem Merkmalswert die bis dahin erreichte Summe (einschließlich seines eigenen Beitrags) zu, so erhalten wir die Verteilungssumme. Sie gibt für jeden Merkmalswert an, wie groß der Anteil der Werte kleiner oder gleich dem zugehörigen Merkmalswert ist. Der Anteil beginnt mit 0 und geht bis 1 oder 100 Prozent. Stellt man die Tabelle grafisch dar, ergibt sich eine schwach monoton steigende Kurve, meist in gestreckter S-Form. Es gibt zahlreiche Versuche, reale Verteilungssummen durch Funktionsgleichungen näherungsweise wiederzugeben. Die Verteilungssummen in Abhängigkeit von den Merkmalswerten sind die einfachste Art der Darstellung einer Häufigkeitsverteilung.
Die weitere Rechnung erfordert eine Einteilung der Merkmalswerte in Klassen. Dazu teilt man den vorkommenden Wertebereich in zum Beispiel 10 oder 20 meist gleichbreite Klassen (die seltenen Werte an den Rändern (siehe "Ausreißer") werden bisweilen in größeren Klassen zusammengefasst). Man gelangt dann zu den Verteilungsdichten, die im Fall einer stetigen Verteilung die Ableitung der Verteilungssummenfunktion nach dem Merkmalswert sind. Ferner lässt sich die Häufigkeit nicht nur durch Zählen ermitteln, sondern beispielsweise auch durch Wiegen. Wir erhalten dann eine Massenverteilung anstelle einer Anzahlverteilung. Im Prinzip eignet sich jede additive Größe zum Messen der Häufigkeit.
Wenn eine Zufalls-Stichprobe stark von der Normalverteilung (Glockenkurve) abweicht, können die Daten durch unerkannte Einflüsse, Auswahleffekte oder einen Trend verfälscht sein. Verschiedene Auswege bieten statistische Tests oder eine Varianzanalyse. Besteht der Probenumfang in einer Überlagerung mehrerer Teilmengen (Altersverteilung, Berufe, Gruppen), so kann die Häufigkeitsverteilung statt eines Maximums auch zwei- oder mehrgipfelig sein.
Siehe auch
- Bimodale Verteilung, Fisher-Test
- Histogramm, Dichtekurve, Kerndichteschätzung
- DIN 66 141 Darstellung von Korngrößenverteilungen; Grundlagen
Literatur
- Lothar Sachs: Statistische Methoden. ISBN 3540520252
Wikimedia Foundation.