- Freenet
-
Freenet 
Maintainer Freenet Projekt[1] Aktuelle Version 0.7.5 Betriebssystem Plattformunabhängig Programmiersprache Java Kategorie Anonymität, Peer to peer Lizenz GNU General Public License http://freenetproject.org/ Freenet ist eine Peer-to-Peer-Software zum Aufbau eines Netzwerks aus Rechnern, dessen Ziel darin besteht, Daten verteilt zu speichern und dabei Zensur zu vereiteln und anonymen Austausch von Informationen zu ermöglichen. Dieses Ziel soll durch Dezentralisierung, Redundanz, Verschlüsselung und dynamisches Routing erreicht werden. Freenet wird als freie Software unter der GPL entwickelt. Vereinfacht kann man das Freenet als vagabundierenden Datenbestand (Datastore) betrachten, auf den alle Teilnehmer gleichberechtigt (peer-to-peer) zugreifen können. Zentrale Nameserver, Serverfestplatten und ähnliche Strukturen werden konsequent konstruktiv vermieden. Es wird nur die Übertragungsfunktionalität des regulären Internet benötigt. Nach Einstufung der Entwickler ist es noch eine Testversion.
Inhaltsverzeichnis
Geschichte
1999 beschrieb der irische Student Ian Clarke in einer Abhandlung ein „verteiltes dezentrales Informationsspeicher- und -abrufsystem“.[2] Kurz nach der Veröffentlichung begannen Clarke und eine kleine Zahl Freiwilliger, diese Idee als freie Software umzusetzen.
Im März 2000 war die erste Version bereit für die Veröffentlichung. In der folgenden Zeit wurde viel über Freenet berichtet, hauptsächlich beschäftigten die Presse dabei aber die Auswirkungen auf Urheberrechte und weniger das Ziel der freien Kommunikation. Auch die akademische Welt beschäftigte sich mit Freenet: Clarkes Abhandlung war laut CiteSeer das meistzitierte wissenschaftliche Dokument in der Informatik im Jahr 2000.
Freenet wird mit Hilfe des Internets verteilt entwickelt. Das Projekt gründete die gemeinnützige „The Freenet Project Inc.“ und beschäftigt seit September 2002 Matthew Toseland als Vollzeitprogrammierer, der von Spendengeldern und dem Erlös von Ablegerprodukten bezahlt wird. Darüber hinaus arbeiten andere frei mit.
Im Januar 2005 wurde geplant, die nächste Version, Freenet 0.7, komplett neu zu schreiben. Mitte April 2005 brachten die Entwickler von Freenet erstmals auf der offenen Mailingliste ins Gespräch, Freenet als so genanntes Darknet zu gestalten, das heißt, dass der Zugang nur auf „Einladung“ bestehender Teilnehmer erfolgen kann. (Für Einzelheiten siehe Abschnitt Darknet.) Dieses Element ist die wichtigste Neuerung in 0.7.
Die Idee hinter dem geplanten Freenet 0.7 wurde daraufhin von Ian Clarke und dem Mathematiker Oskar Sandberg auf zwei Hackerveranstaltungen präsentiert, am 29. Juli 2005 bei der 13. DEF CON und am 30. Dezember 2005 auf dem 22. Chaos Communication Congress (22C3).[3][4]
Anfang April 2006 wurde die erste Alpha-Version von Freenet 0.7 veröffentlicht.
Sonstiges
Bis Ende 2003 hat eine Gruppe namens Freenet-China das Programm ins Chinesische übersetzt und es in der Volksrepublik China auf CDs und Disketten verbreitet.[5] Die chinesischen Computer- und Internet-Filter sperren das Wort „Freenet“ (Stand: 30. August 2004).[6] Internetverbindungen Freenets werden für die Versionen vor 0.7 blockiert. Dies war möglich, weil bis dahin zu Beginn eines Verbindungsaufbaus einige vorhersagbare Bytes entstanden.
Eine im Mai 2004 veröffentlichte Analyse besagt, dass die meisten Freenet-Nutzer zu diesem Zeitpunkt aus den USA (35 %), Deutschland (15 %), Frankreich (11 %), Großbritannien (7 %) und Japan (7 %) kamen.[7] Diese Analyse gründet sich wahrscheinlich auf die IP-Adressliste der Teilnehmer, die für die Versionen vor 0.7 vom Projekt bereitgestellt wurde, und berücksichtigt somit keine separaten Freenet-Netzwerke wie Freenet-China.
Benutzung
Jeder Anwender stellt Freenet einen Teil seiner Festplatte als Speicher zur Verfügung. Man gibt hierbei nicht bestimmte Ordner oder Dateien für die anderen frei, wie das beim üblichen Filesharing der Fall ist, sondern reserviert einen bestimmten Anteil an Festplattenspeicher (in der Größenordnung von Gigabyte), den Freenet selbstständig mit Daten aus dem Netz belegt.
Die Benutzung von Freenet ist mit der des World Wide Web (WWW) vergleichbar. Mittels eines beliebigen Browsers kann, wie vom WWW gewohnt, im Freenet gesurft werden. Das Programmmodul FProxy arbeitet als lokales Server-Programm und ist im Allgemeinen unter http://localhost:8888/ erreichbar. Von dieser Einstiegsseite aus kann man einzelne Freenet-Adressen anfordern oder hochladen, außerdem werden Links zu einer kleinen Anzahl Freesites bereitgestellt, die als erste Anlaufstelle im Freenet dienen.
 Gateway von Freenet 0.5 (2005, Ausschnitt): Wenn das Activelink-Bild erfolgreich geladen wurde, ist die zugehörige Seite wahrscheinlich auch erreichbar.
Gateway von Freenet 0.5 (2005, Ausschnitt): Wenn das Activelink-Bild erfolgreich geladen wurde, ist die zugehörige Seite wahrscheinlich auch erreichbar.
Eine Freesite stellt für Freenet in etwa das gleiche dar, was Websites für das WWW darstellen. Es sind Dokumente, die durch das Freenet-Gateway zugänglich werden. Sie können Links zu anderen Freesites oder zu sonstigen Daten beinhalten, welche durch einen Freenet-Schlüssel erreichbar sind.
Mithilfe sogenannter Activelinks kann die Verbreitung ausgewählter Freesites gefördert werden. Bindet man auf der eigenen Freesite ein kleines Bild einer anderen Freesite ein, so wird diese automatisch gefördert, wenn die eigene Freesite (und damit das Bild) geladen wird.
Das Laden von Inhalten dauert verhältnismäßig lange, da Freenet die Prioritäten bei der Sicherheit setzt. Besonders am Anfang kann es mehrere Minuten dauern, da der Teilnehmer noch nicht gut in das Freenet-Netz integriert ist. Erst durch die Integration lernt das Programm, an welche anderen Teilnehmer am besten Anfragen versendet werden können.
Anwendungsgebiet
Neben der schlichten Veröffentlichung von Informationen eignet sich Freenet zur zeitversetzten Kommunikation, das heißt, sowohl eine Art E-Mail-System als auch Diskussionsforen können sinnvoll auf Freenet aufbauen.
Suchmaschinen, wie sie im WWW funktionieren, gibt es in Freenet nicht. Stattdessen führen einige Autoren Index-Seiten – Listen, die aus Links zu anderen Freesites bestehen. Diese Index-Seiten werden von ihren jeweiligen Autoren meistens mit Hilfe sogenannter Spider, die ähnlich wie Webcrawler funktionieren, erstellt. Sie sind eine Art von Suchmaschinen, die Freesites nach Links durchsuchen, diese Links besuchen, und falls es wiederum Freesites sind, diese dann ebenfalls durchsuchen und so weiter. Die Ergebnisse speichern sie dann und erzeugen daraus die oben genannten Listen.
Ein sehr verbreiteter Typ von Freesites sind Blogs (Weblogs), die von den Freenet-Nutzern analog als „Flogs“ (Freelogs) bezeichnet werden. Ein besonderer Anreiz für die Einrichtung ist die Anonymität, mit der man seine Berichte im Freenet veröffentlichen kann.
WebOfTrust: Spam-resistente, anonyme Kommunikation
Mit dem WebOfTrust-Plugin bietet Freenet ein Anti-Spam-System, das auf anonymen Identitäten und Vertrauenswerten aufbaut. Jede anonyme Identität kann jeder andere anonyme Identität positives oder negatives Vertrauen geben. Die Vertrauenswerte der bekannten Identitäten werden zusammengeführt, um unbekannte Identitäten einschätzen zu können. Nur die Daten von Identitäten mit nicht negativem Vertrauen werden heruntergeladen.
Neue Identitäten können über captcha-Bilder bekannt gemacht werden. Sie lösen Captchas anderer Identitäten und erhalten von diesen Identitäten ein Vertrauen von 0. Dadurch sind sie für diese Identitäten sichtbar, aber für keine anderen. Wenn sie dann sinnvolle Beiträge schreiben, können sie positives Vertrauen erhalten (>0), so dass sie für alle Identitäten sichtbar werden, die den vertrauenden Identitäten vertrauen.
Software für Freenet
Für das Hochladen von Daten gibt es spezielle Software, die insbesondere den Austausch größerer Dateien erleichtert. Diese werden intern in kleine Stücke zerlegt (Splitfiles) und gegebenenfalls mit redundanten Datenblöcken versehen (Fehlerkorrektur).
Technische Einzelheiten
Funktionsweise
Alle Inhalte werden in so genannten Schlüsseln gespeichert. Der Schlüssel ergibt sich eindeutig aus dem Hash-Wert des enthaltenen Inhalts und hat vom Aussehen her nichts mit dem Inhalt zu tun. (Zum Beispiel könnte eine Textdatei mit dem Grundgesetz den Schlüssel YQL haben.) Die Schlüssel sind in einer so genannenten verteilten Hashtabelle gespeichert.
Jeder Teilnehmer speichert nicht etwa nur die Inhalte, die er selbst anbietet. Stattdessen werden alle Inhalte auf die verschiedenen Rechner – die so genannten Knoten (engl. nodes) – verteilt. Die Auswahl, wo eine Datei gespeichert wird, erfolgt durch Routing. Jeder Knoten spezialisiert sich mit der Zeit auf bestimmte Schlüsselwerte.
Die Speicherung auf dem Rechner erfolgt verschlüsselt und ohne Wissen des jeweiligen Nutzers. Diese Funktion ist von den Entwicklern eingeführt worden, um den Freenet-Benutzern die Möglichkeit zu geben, die Kenntnis der Daten glaubhaft abstreiten zu können, die in dem für Freenet reservierten lokalen Speicher zufällig für das Netz bereitgehalten werden.[8] Bisher sind allerdings in der Rechtsprechung zumindest in Deutschland keine Fälle bekannt, in denen von der Möglichkeit Gebrauch gemacht wurde, die Kenntnis abzustreiten, so dass die Wirksamkeit dieser Maßnahme vor deutschen Gerichten nicht geklärt ist.
Wenn eine Datei aus dem Freenet heruntergeladen werden soll, wird sie mit Hilfe des Routing-Algorithmus gesucht. Die Anfrage wird an einen Knoten geschickt, dessen Spezialisierung dem gesuchten Schlüssel möglichst ähnlich ist.
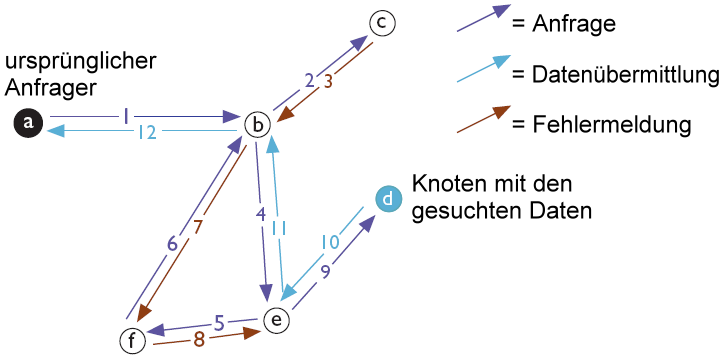
Beispiel: Wir suchen den Schlüssel HGS. Wir sind mit anderen Freenet-Knoten verbunden, die die folgenden Spezialisierungen haben: ANF, DYL, HFP, HZZ, LMO. Wir wählen HFP als Adressaten unserer Anfrage, da dessen Spezialisierung dem gesuchten Schlüssel am nächsten kommt.
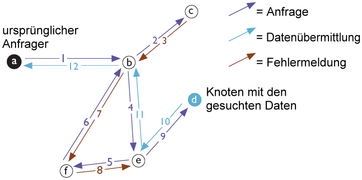 Typischer Ablauf einer Anfrage: Die Anfrage wird von Knoten zu Knoten durch das Netz geleitet, kehrt aus einer Sackgasse (Schritt 3) und einer Schleife (Schritt 7) zurück, findet schließlich die gesuchten Daten und liefert diese zurück.
Typischer Ablauf einer Anfrage: Die Anfrage wird von Knoten zu Knoten durch das Netz geleitet, kehrt aus einer Sackgasse (Schritt 3) und einer Schleife (Schritt 7) zurück, findet schließlich die gesuchten Daten und liefert diese zurück.Wenn der Adressat den Schlüssel nicht in seinem Speicher hat, wiederholt er die Prozedur, als ob er selbst den Schlüssel haben wollte: Er schickt die Anfrage weiter an den Knoten, der seiner Meinung nach am besten darauf spezialisiert ist.
Und so geht es weiter. Wenn ein Knoten schließlich über die gesuchte Datei verfügt, wird diese vom Fundort zum ursprünglichen Anfrager transportiert. Aber dieser Transport erfolgt über alle an der Anfrage-Kette beteiligten Knoten. Diese Gestaltung ist ein zentrales Merkmal von Freenet. Sie dient dazu, die Anonymität von Quelle und Empfänger zu wahren. Denn so kann man, wenn man selbst eine Anfrage erhält, nicht wissen, ob der Anfrager die Datei selbst haben oder nur weiterleiten will.
Wenn die Datei übertragen wird, speichern einige Rechner eine Kopie in ihrem Speicher. Beliebte Dateien gelangen so auf viele Rechner im Freenet-Netz. Damit steigt die Wahrscheinlichkeit, dass weitere Anfragen nach dieser Datei schneller erfolgreich sind.
Eine Datei ins Freenet hochzuladen, funktioniert ganz ähnlich: Freenet sucht auch hier den Knoten, dessen Spezialisierung dem Schlüssel am nächsten kommt. Das ist sinnvoll, damit die Datei dort ist, wo auch die Anfragen nach solchen Schlüsseln hingeschickt werden.
Da es beim Hochladen nicht darum geht, nach einigen Weiterleitungen jemanden mit den Daten zu finden, wird vorher ein Wert gesetzt, wie oft weitergeleitet wird.
Probleme
Damit Freenet funktioniert, benötigt man neben dem Programm selbst die Adresse mindestens eines anderen Benutzers. Das Projekt unterstützt die Integration neuer Knoten, indem es eine aktuelle Sammlung solcher Adressen (seednodes) auf seinen Seiten anbietet. Wenn dieses Angebot jedoch verschwindet oder für jemanden mit eingeschränktem Zugang zum Internet nicht erreichbar ist, wird der erste Verbindungspunkt zum Problem. Darüber hinaus ist es aus Gründen der Sicherheit und der Netz-Topologie eher wünschenswert, wenn private Seednodes im Freundeskreis verbreitet werden.
Knoten mit geringer Geschwindigkeit, asymmetrischer Verbindung oder kurzer Lebensdauer können den Datenfluss behindern. Hier versucht Freenet durch intelligentes Routing gegenzusteuern (siehe Routing).
Freenet kann kein permanentes Speichern von Daten garantieren. Da Speicherplatz endlich ist, besteht ein Zielkonflikt zwischen der Veröffentlichung neuer und der Bewahrung alter Inhalte.
Schlüssel
Freenet verfügt über zwei Schlüsseltypen.
Content-hash key (CHK)
CHK ist der systemnahe (low-level) Daten-Speicher-Schlüssel. Er wird erzeugt, indem die Inhalte der Datei, die gespeichert werden soll, gehasht werden. Dadurch erhält jede Datei einen praktisch einzigartigen, absoluten Bezeichner (GUID). Bis Version 0.5/0.6 wird dafür SHA-1 verwendet.
Anders als bei URLs kann man nun sicher sein, dass die CHK-Referenz sich auf genau die Datei bezieht, die man gemeint hat. CHKs sorgen auch dafür, dass identische Kopien, die von verschiedenen Leuten in Freenet hochgeladen werden, automatisch vereinigt werden, denn jeder Teilnehmer berechnet den gleichen Schlüssel für die Datei.
Signed-subspace key (SSK)
Der SSK sorgt durch ein asymmetrisches Kryptosystem für einen persönlichen Namensraum, den jeder lesen, aber nur der Besitzer beschreiben kann. Zuerst wird ein zufälliges Schlüsselpaar erzeugt. Um eine Datei hinzuzufügen, wählt man zuerst eine kurze Beschreibung, zum Beispiel politik/deutschland/skandal. Dann berechnet man den SSK der Datei, indem die öffentliche Hälfte des Subspace Key und die beschreibende Zeichenkette unabhängig voneinander gehasht werden, die Ergebnisse verkettet werden und das Ergebnis dann wieder gehasht wird. Das Unterschreiben der Datei mit der privaten Hälfte des Schlüssels ermöglicht eine Überprüfung, da jeder Knoten, der die SSK-Datei verarbeitet, deren Signatur verifiziert, bevor er sie akzeptiert.
Um eine Datei aus einem Unternamensraum zu beziehen, braucht man nur den öffentlichen Schlüssel dieses Raums und die beschreibende Zeichenkette, von welchen man den SSK nachbilden kann. Um eine Datei hinzuzufügen oder zu aktualisieren, braucht man den privaten Schlüssel, um eine gültige Signatur zu erstellen. SSKs ermöglichen so Vertrauen, da sie garantieren, dass alle Dateien im Unternamensraum von derselben anonymen Person erstellt wurden. So sind die verschiedenen praktischen Anwendungsgebiete von Freenet möglich (siehe Anwendungsgebiet).
Üblicherweise werden SSKs zur indirekten Speicherung von Dateien verwendet, indem sie Zeiger enthalten, die auf CHKs verweisen, anstatt die Daten selbst zu beinhalten. Diese „indirekten Dateien“ verbinden die Lesbarkeit für den Menschen und die Authentifikation des Autors mit der schnellen Verifizierung von CHKs. Sie erlauben es auch, Daten zu aktualisieren, während die referentielle Integrität erhalten bleibt: Um zu aktualisieren, lädt der Besitzer der Daten erst eine neue Version der Daten hoch, die einen neuen CHK erhalten, da die Inhalte anders sind. Der Besitzer aktualisiert dann den SSK, so dass dieser auf die neue Version zeigt. Die neue Version wird unter dem ursprünglichen SSK verfügbar sein, und die alte Version bleibt unter dem alten CHK erreichbar.
Indirekte Dateien kann man auch dazu verwenden, große Dateien in viele Stücke aufzuspalten, indem jeder Teil unter einem anderen CHK hochgeladen wird und eine indirekte Datei auf alle Teilstücke verweist. Hierbei wird aber auch für die indirekte Datei meist CHK verwendet. Schließlich können indirekte Dateien auch noch dazu verwendet werden, hierarchische Namensräume zu erstellen, bei denen Ordner-Dateien auf andere Dateien und Ordner zeigen.
SSK können auch verwendet werden, ein alternatives Domain Name System für Knoten zu implementieren, die häufig ihre IP-Adresse wechseln. Jeder dieser Knoten hätte seinen eigenen Unterraum, und man könnte ihn kontaktieren, indem sein öffentlicher Schlüssel abgerufen wird, um die aktuelle Adresse zu finden. Solche adress-resolution keys hat es bis Version 0.5/0.6 tatsächlich gegeben, sie wurden aber abgeschafft.
Schutz vor übermäßigen Anfragen
Anfragen und Uploads werden mit einer HTL (engl. Hops to live in Anlehnung an TTL, das heißt: Wie oft darf noch weitergeleitet werden?) ausgestattet, die nach jedem Weiterleiten um 1 verringert wird. Es gibt eine obere Grenze für den Startwert, damit das Netzwerk nicht durch Aktionen mit unsinnig hohen Werten belastet wird. Der derzeitige Wert liegt bei 20: Wenn eine Anfrage nach so vielen Hops kein Ergebnis liefert, ist der Inhalt wahrscheinlich nicht vorhanden – oder das Routing funktioniert nicht, dagegen helfen höhere HTL aber auch nicht. Ähnliches gilt für das Hochladen: Nach 20 Hops sollte eine Information ausreichend verbreitet sein. (Diese Ausbreitung kann durch Abfrage der Daten durchaus noch zunehmen.)
Routing
Bei Freenets Routing wird eine Anfrage von dem verarbeitenden Knoten an einen anderen weitergeleitet, dessen Spezialisierung, nach Einschätzung des Weiterleitenden, dem gesuchten Schlüssel möglichst ähnlich ist.
Damit hat sich Freenet gegen die beiden Hauptalternativen entschieden:
- Ein zentraler Index aller verfügbaren Dateien – das einfachste Routing, zum Beispiel von Napster verwendet – ist wegen der Zentralisierung angreifbar.
- Eine Verbreitung der Anfrage an alle verbundenen Knoten – zum Beispiel von Gnutella verwendet – verschwendet Ressourcen und ist nicht skalierbar.
Die Art und Weise, wie Freenet die Entscheidung trifft, an wen weitergeleitet wird, bildet den Kern des Freenet-Algorithmus.
Altes Routing
Freenets erster Routing-Algorithmus war relativ einfach: Wenn ein Knoten eine Anfrage nach einem bestimmten Schlüssel an einen anderen Knoten leitet und dieser sie erfüllen kann, wird die Adresse eines zurückleitenden Knotens in der Antwort aufgeführt. Das kann – nur möglicherweise – derjenige sein, der die Daten lokal gespeichert hatte. Es wird angenommen, dass der angegebene Knoten eine gute Adresse für weitere Anfragen nach ähnlichen Schlüsseln ist.
Eine Analogie zur Verdeutlichung: Weil dein Freund Heinrich eine Frage zu Frankreich erfolgreich beantworten konnte, dürfte er auch ein guter Ansprechpartner bei einer Frage zu Belgien sein.
Trotz seiner Einfachheit hat sich dieser Ansatz als sehr effektiv erwiesen, sowohl in Simulationen als auch in der Praxis. Einer der erwarteten Nebeneffekte war, dass Knoten dazu tendieren, sich auf bestimmte Schlüsselbereiche zu spezialisieren. Das kann analog dazu gesehen werden, dass Menschen sich auf bestimmte Fachbereiche spezialisieren. Dieser Effekt wurde bei realen Freenet-Knoten im Netzwerk beobachtet; das folgende Bild repräsentiert die Schlüssel, die von einem Knoten gespeichert sind:
 Darstellung der Schlüssel, die von einem Knoten gespeichert sind
Darstellung der Schlüssel, die von einem Knoten gespeichert sindDie x-Achse repräsentiert den Schlüsselraum, von Schlüssel 0 bis Schlüssel 2160-1. Die dunklen Streifen zeigen Bereiche, wo der Knoten detailliertes Wissen besitzt, wohin Anfragen für solche Schlüssel geroutet werden sollten.
Wenn der Knoten gerade initialisiert worden wäre, wären die Schlüssel gleichmäßig auf den Schlüsselraum verteilt. Das ist ein guter Indikator dafür, dass der Routing-Algorithmus korrekt arbeitet. Knoten spezialisieren sich wie in der Grafik durch den Effekt von Rückmeldungen, wenn ein Knoten erfolgreich auf eine Anfrage nach einem bestimmten Schlüssel antwortet – es erhöht die Wahrscheinlichkeit, dass andere Knoten Anfragen nach ähnlichen Schlüsseln in Zukunft zu ihm leiten werden. Über längere Zeit sorgt das für die Spezialisierung, die im obigen Diagramm deutlich sichtbar ist.
Next Generation Routing (NGR)
NGR soll Routing-Entscheidungen viel geschickter treffen, indem für jeden Knoten in der Routing-Tabelle umfangreiche Informationen gesammelt werden, darunter Antwortzeit beim Anfragen bestimmter Schlüssel, der Anteil der Anfragen, die erfolgreich Informationen gefunden haben, und die Zeit zur Erstellung einer ersten Verbindung. Wenn eine neue Anfrage empfangen wird, werden diese Informationen benutzt, um zu schätzen, welcher Knoten wahrscheinlich die Daten in der geringsten Zeit beschaffen kann, und das wird dann auch der Knoten, zu dem die Anfrage weitergeleitet wird.
DataReply Abschätzung
Der wichtigste Wert ist die Abschätzung bei einer Anfrage, wie lange es dauern wird, die Daten zu bekommen. Der Algorithmus muss die folgenden Kriterien erfüllen:
- Er muss sinnvoll raten können bei Schlüsseln, die er noch nicht gesehen hat.
- Er muss fortschrittlich sein: Wenn die Leistung eines Knotens sich über die Zeit verändert, sollte das repräsentiert sein. Aber er darf nicht übersensibel auf jüngste Fluktuationen reagieren, die stark vom Durchschnitt abweichen.
- Er muss skalenfrei sein: Man stelle sich eine naive Implementierung vor, die den Schlüsselraum in eine Anzahl Sektionen aufteilt und für jede einen Durchschnitt hat. Nun stelle man sich einen Knoten vor, bei dem die meisten der eingehenden Anfragen in einer sehr kleinen Sektion des Schlüsselraums liegen. Unsere naive Implementierung wäre nicht in der Lage, Variationen in der Antwort-Zeit in diesem kleinen Bereich zu repräsentieren und würde daher die Fähigkeit des Knotens beschränken, die Routing-Zeiten genau zu schätzen.
- Er muss effizient programmierbar sein.

NGR erfüllt diese Kriterien: Es werden N Referenzpunkte unterhalten – dabei ist N konfigurierbar, 10 ist ein typischer Wert –, die anfangs gleichmäßig über den Schlüsselraum verteilt sind. Wenn es einen neuen Routing-Zeit-Wert für einen bestimmten Schlüssel gibt, werden die zwei Punkte, die dem neuen Wert am nächsten sind, diesem angenähert. Das Ausmaß dieser Annäherung kann geändert werden, um einzustellen, wie „vergesslich“ die Schätzfunktion ist.
Das nebenstehende Diagramm zeigt, wie zwei Referenzpunkte (blau) hin zu dem neuen Wert (rot) bewegt werden.
Wenn eine Schätzung für einen neuen Schlüssel erstellt werden soll, ergeht aus der grünen Linie die Zuordnung von geschätzter Antwort zum Schlüssel.
Umgang mit unterschiedlichen Dateigrößen
Es gibt zwei Zeitwerte, die in Betracht gezogen werden müssen, wenn wir ein DataReply erhalten:
- Die Zeit, bis der Anfang der Antwort eintrifft.
- Die Zeit für den Transfer der Daten.
Um diese beiden Aspekte in einem Wert zu vereinen, werden beide Zahlen dazu verwendet, die Gesamtzeit zwischen dem Senden der Anfrage und der Fertigstellung des Transfers zu schätzen. Für die Transferzeit wird angenommen, die Datei habe die durchschnittliche Länge aller Daten im lokalen Speicher.
Jetzt haben wir einen Einzelwert, der direkt mit anderen Zeitmessungen bei Anfragen verglichen werden kann, selbst wenn die Dateien unterschiedliche Größen haben.
Verfahren, wenn die Daten nicht gefunden wurden
Wenn eine Anfrage die Höchstzahl an Knoten gemäß HTL (siehe Schutz vor übermäßigen Anfragen) durchlaufen hat, wird die Nachricht „Datei nicht gefunden“ (engl. DataNotFound, kurz DNF) zurück zum Anfrager geleitet.
Ein DNF kann zwei Ursachen haben:
- Die Daten sind im Freenet vorhanden, konnten aber nicht gefunden werden. Dieses DNF würde einen Mangel im Routing der beteiligten Knoten offenbaren. Wir nennen dieses DNF im Folgenden illegitim.
- Die Daten existieren gar nicht. Dieses DNF würde von keinem Mangel zeugen. Wir nennen es im Folgenden legitim.
Es gibt keinen praktischen Weg, herauszufinden, ob ein DNF legitim oder illegitim ist. Wir wollen aber für einen Augenblick annehmen, wir könnten illegitime DNFs identifizieren. Dann wären die Kosten die Zeit, das illegitime DNF zu empfangen plus eine neue Anfrage woanders hinzuschicken.
Ersteres können wir schätzen, indem wir schauen, wie lang vorherige DNFs von dem speziellen Knoten gedauert haben – in proportionaler Abhängigkeit vom HTL der Anfrage: Eine Anfrage mit HTL=10 wird doppelt so viele Knoten durchlaufen wie eine mit HTL=5 und deshalb etwa doppelt so lange brauchen, DNF zurückzuliefern. Den zweiten Wert können wir schätzen, indem wir die durchschnittliche Zeit nehmen, die es braucht, erfolgreich Daten zu empfangen.
Jetzt stellen wir uns einen Freenet-Knoten mit perfektem Routing vor, dessen einzige ausgegebene DNF legitim wären: Denn wenn die Daten im Netz wären, würde er sie mit seinem perfekten Routing finden. Der Anteil von DNF an den Antworten, die dieser Knoten zurückliefern würde, wäre gleich dem Anteil der legitimen DNF. Solch ein Knoten kann praktisch nicht existieren, aber wir können ihn approximieren, indem wir uns den Knoten mit dem niedrigsten Anteil an DNF in unserer Routing-Tabelle suchen.
Jetzt können wir die Zeit-Kosten von DNFs berechnen, und wir können außerdem approximieren, welcher Anteil von DNFs legitim ist – und der deshalb nicht als Zeitverlust angesehen wird. Damit können wir für jeden Knoten geschätzte Routing-Zeit-Kosten hinzufügen, um DNFs zu berücksichtigen.
Umgang mit fehlgeschlagenen Verbindungen
Mit stark überladenen Knoten können wir nicht interagieren. Diese Möglichkeit können wir berücksichtigen, indem wir den durchschnittlichen Anteil fehlgeschlagener Verbindungen für jeden Knoten speichern, und wie lange jede solche dauerte. Diese Werte werden der geschätzten Routing-Zeit für den jeweiligen Knoten hinzugefügt.
Gewonnenes Wissen
Eines der Probleme, das im Freenet zurzeit von NGR beobachtet wird, ist die Zeit, die für einen Freenet-Knoten erforderlich ist, ausreichendes Wissen über das Netz anzuhäufen, um effizient zu routen. Das ist besonders schädlich für Freenets Benutzerfreundlichkeit, da der erste Eindruck für neue Nutzer entscheidend ist, und dieser ist üblicherweise der schlechteste, da er auftritt, bevor der Freenet-Knoten effektiv routen kann.
Die Lösung ist es, etwas qualifiziertes Vertrauen zwischen Freenet-Knoten aufzubauen und ihnen zu ermöglichen, die über einander gesammelten Informationen zu teilen, wenn auch in ziemlich misstrauischer Weise.
Es gibt zwei Möglichkeiten, wie ein Freenet-Knoten von neuen Knoten erfährt.
- Wenn das Programm startet, lädt es eine Datei, die die Routing-Erfahrung eines anderen, erfahrenen Knotens enthält. Mit NGR sind diese Informationen um statistische Daten bereichert, so dass ein Knoten, selbst wenn er das erste Mal startet, bereits das Wissen eines erfahrenen Knotens hat. Dieses Wissen wird im Verlauf seiner Aktivität gemäß den eigenen Erfahrungen angepasst.
- Die andere Möglichkeit ist das Feld „Datenquelle“ (engl. DataSource), das auf erfolgreiche Anfragen hin zurückgeschickt wird. Dieses Feld enthält einen der Knoten in der Kette und statistische Informationen zu ihm. Da diese Informationen aber manipuliert sein könnten, werden sie von jedem Knoten, der sie weiterleitet, angepasst, falls der Knoten selbst über die genannte Adresse Bescheid weiß.
Vorteile von NGR
- Passt sich der Netz-Topologie an.
- Das alte Routing ignorierte die zugrundeliegende Internet-Topologie: Schnell und langsam angebundene Knoten wurden gleich behandelt. Dagegen legt NGR seinen Entscheidungen tatsächliche Routing-Zeiten zugrunde.
- Leistung kann lokal ausgewertet werden.
- Mit dem alten Routing konnte man seine Leistung nur auswerten, indem man sie testete. Mit NGR hat man mit der Differenz zwischen geschätzter und tatsächlicher Routing-Zeit einen einfachen Wert, wie effektiv man ist. Wenn nun eine Änderung am Algorithmus in besseren Schätzungen resultiert, wissen wir, dass sie besser ist; und umgekehrt. Das beschleunigt die Weiterentwicklung stark.
- Annäherung an das Optimum.
- In einer Umwelt, in der nur dem eigenen Knoten vertraut werden kann, ist es vernünftig zu sagen, dass alle Entscheidungen auf den eigenen Beobachtungen basieren sollten. Wenn die vorangegangenen eigenen Beobachtungen optimal genutzt werden, dann ist der Routing-Algorithmus optimal. Freilich gibt es immer noch Raum in Bezug darauf, wie der Algorithmus die Routing-Zeiten schätzt.
Sicherheit
Darknet
Bei der Benutzung von Freenet (Stand: Version 0.5/0.6) verbindet man sich schnell mit einer großen Zahl anderer Nutzer. Für einen Angreifer ist es somit kein Problem, in kurzer Zeit die IP-Adressen großer Teile des Freenet-Netzes zu sammeln. Dies wird als harvesting (engl. für „abernten“) bezeichnet.
Wenn Freenet in einem Land wie China illegal ist und Harvesting ermöglicht, können die Machthaber es einfach durch einen Techniker mit Zugang zu der nationalen Firewall blockieren: Er startet einen Knoten und sammelt Adressen. Damit erhält er eine Liste von Knoten innerhalb des Landes, und eine Liste von Knoten außerhalb. Er blockiert alle Knoten außerhalb des Landes, und er kappt die Verbindung aller Knoten innerhalb des Landes, so dass diese das Internet gar nicht mehr erreichen können.
Mitte April 2005 brachten die Entwickler von Freenet erstmals auf der offenen Mailingliste ins Gespräch, Freenet als so genanntes Darknet zu gestalten, das heißt, dass der Zugang nur auf „Einladung“ bestehender Teilnehmer erfolgen kann.
Mit dem Plan, ein globales Darknet zu erschaffen, betreten die Entwickler jedoch Neuland. Sie glauben an die Kleine-Welt-Eigenschaft eines solchen Darknets – das bedeutet, dass jeder Teilnehmer jeden anderen über eine kurze Kette von Hops erreichen kann –, weil auch die globale Menschheit dem Kleine-Welt-Phänomen gehorcht: Jeder Mensch (sozialer Akteur) auf der Welt ist mit jedem anderen über eine überraschend kurze Kette von Bekanntschaftsbeziehungen verbunden. Weil für eine Einladung in Freenet ein gewisses Vertrauen herrschen muss, erhoffen sie sich, dass die entstehende Netzstruktur das Beziehungsgeflecht der Menschen widerspiegelt.
Diskussionen über diesen Ansatz hatten zur Folge, dass nicht allein ein Darknet entwickelt werden, sondern dass es auch ein offenes Netz geben wird, wie es das ganze Freenet vor 0.7 war. Dabei gibt es zwei Möglichkeiten, wie diese beiden in Beziehung zueinander stehen sollen:
- Es gibt Verbindungen zwischen dem offenen Netz und dem Darknet. Es entstünde ein sogenanntes Hybrid-Netz. Inhalte, die in dem einen Netz veröffentlicht werden, sind auch von dem anderen Netz aus abrufbar. Zu einem Problem wird dieser Ansatz, wenn viele kleine, untereinander unverbundene Darknets von der Verbindung durch das offene Netz abhängen. Dies entspricht der aktuellen Implementierung der Version 0.7.0.
- Die beiden Netze sind unverbunden. Inhalte, die in dem einen Netz veröffentlicht werden, sind erst einmal nicht in dem anderen verfügbar. Es wäre aber möglich, Daten ohne Mitwirken des Autors zu übertragen, selbst bei SSK-Schlüsseln. Diese Option wurde in der Vergangenheit vom Hauptentwickler favorisiert (Stand: Mai 2005), da sie trotz des alternativen offenen Netzes ermöglicht, das Funktionieren eines alleinstehenden globalen Darknets zu überprüfen.
Möglichkeit einer demokratischen Zensur
Am 11. Juli 2005 präsentierte Vollzeitentwickler Matthew Toseland einen Vorschlag, wie im Darknet eine demokratische Zensur implementiert werden könnte. Dafür müssten Daten über Hochladevorgänge längere Zeit gespeichert werden. Wenn sich ein Knoten über einen Inhalt „beschwert“, wird diese Beschwerde verbreitet und andere Knoten können sich ihr anschließen. Wenn eine ausreichende Mehrheit benachbarter Knoten eine Beschwerde unterstützt, wird der Hochladevorgang anhand der gespeicherten Daten zurückverfolgt bis zu den Knoten, die die Beschwerde nicht unterstützen.
Sobald diese gefunden wurden, sind mögliche Sanktionen (in ansteigender Reihenfolge der benötigten Mehrheit)
- Rüge
- Deaktivierung des Premix-Routings für den Knoten
- Trennung der Verbindung zum Knoten
- Offenlegung der Identität des Knotens
Während an diesem Vorschlag vor allem kritisiert wurde, dass Freenet sich damit von der absoluten Zensurfreiheit entferne und damit für libertäre Menschen nicht mehr annehmbar sei, hielt Toseland dagegen, dass Freenet in seinem bisherigen Zustand für all diejenigen nicht annehmbar sei, die keine libertären Ansichten hätten und beispielsweise durch Kinderpornografie abgeschreckt würden.
Ein weiterer Kritikpunkt war die Möglichkeit von Gruppendenk-Verhalten bei den Beschwerden.
Zwei Tage nach der Vorstellung rückte Toseland von seinem Vorschlag ab, da die umfassende Datensammlung das Darknet gefährden könnte, wenn einzelne Knoten von einem Angreifer identifiziert und ausgewertet würden.
Zukunft
HTL
HTL (siehe Schutz vor übermäßigen Anfragen) wird aus Sicherheitsgründen umgestaltet. Es wurde sogar diskutiert, HTL abzuschaffen, da ein Angreifer aus der Zahl Informationen ziehen kann. Das Konzept sähe dann so aus, dass bei jedem Knoten eine bestimmte Wahrscheinlichkeit besteht, dass die Anfrage terminiert. So würden manche Anfragen aber unsinnig kleine Strecken zurücklegen und zum Beispiel nach einem Hop terminieren. Außerdem „lernen“ die Knoten bei so unsicheren Anfragen schlecht voneinander. Es wurde ein Kompromiss gefunden:
- Höchste HTL ist 11.
- Anfragen verlassen einen Knoten mit HTL=11.
- Es besteht eine 10-%-Chance, HTL von 11 auf 10 herabzusetzen. Dies wird einmal pro Verbindung bestimmt, um „correlation attacks“ zu erschweren.
- Es besteht eine 100-%-Chance, HTL von 10 auf 9, von 9 auf 8 und so weiter bis auf 1 herabzusetzen. Dadurch ist sichergestellt, dass Anfragen immer mindestens zehn Knoten durchlaufen; so werden die Schätzwerte nicht zu sehr durcheinander gebracht. (Die Knoten können besser übereinander „lernen“.)
- Es besteht eine 20-%-Chance, Anfragen mit HTL=1 abzubrechen. Dies soll einige Angriffe verhindern, zum Beispiel unterschiedlichen Inhalt auf verschiedene Knoten hochzuladen, oder den Speicher eines Knotens auszutesten.
Protokoll
Freenet benutzt seit der Version 0.7 UDP. Ein TCP-Transport könnte später implementiert werden, aber UDP ist der bevorzugte Transport. Ältere Versionen verwenden ausschließlich TCP.
Schlüssel
Entweder sollen alle Inhalte in 32KB oder in 1KB großen Schlüsseln gespeichert werden. Wie bisher werden kleinere Dateien durch zufällig wirkende, aber eindeutig aus der Datei resultierende Daten erweitert; größere Dateien werden aufgespalten.
Pre-mix Routing
Das Konzept des Pre-mix Routing dient allein der Sicherheit. Bevor ein Auftrag von anderen Nodes sachlich bearbeitet wird, wird er erst verschlüsselt durch ein paar Nodes getunnelt, so dass die erste zwar uns kennt, aber nicht den Auftrag, und die letzte den Auftrag, aber nicht uns. Die Nodes werden in vernünftigem Rahmen zufällig ausgewählt. Der Begriff des „Zwiebel-Routings“ (engl. Onion Routing) veranschaulicht das: Die Anfrage wird mehrfach verschlüsselt (zu einer Zwiebel), und jede Node im Premix-Verlauf „schält“ eine Verschlüsselungsinstanz, so dass erst die letzte Node die Anfrage erkennt – sie weiß aber nicht, von wem der Auftrag kommt.
I2P
Im Januar 2005 wurde diskutiert, das verwandte Projekt I2P als Transportschicht zu verwenden. Diese Überlegung wurde jedoch verworfen.
Passive und inverse passive Anfragen
Passive Anfragen sind Anfragen, die im Netzwerk bestehen bleiben, bis die gesuchte Datei erreichbar wird. Inverse passive Anfragen sollen durch einen Mechanismus ähnlich den passiven Anfragen halbwegs permanent Inhalte bereitstellen.
Die Sicherheitsaspekte sind noch nicht vollständig bekannt. Vor der Implementierung werden sie geklärt werden. Passive und inverse passive Anfragen kommen wohl erst nach Version 1.0.
Steganographie
Steganographie kommt erst nach 1.0
Unterstützung freier JVM (Java Virtual Machine)
Die Unterstützung freier JVM ist kein vorrangiges Entwicklungsziel. Durch den Verzicht auf New I/O NIO wird es aber wahrscheinlich sehr viel einfacher sein, Freenet auf freien JVM laufen zu lassen.
Verwandte Projekte
- Entropy – Wurde nach dem Vorbild von Freenet geschaffen, aber unter Verwendung anderer Algorithmen und der Programmiersprache C. Der Autor hat die Entwicklung eingestellt und rät von der Verwendung ab.
- GNUnet – anderes Programm mit ähnlicher Zielsetzung (hauptsächlich Filesharing)
- I2P – verwandtes Projekt, jedoch mit anderer Zielsetzung (Implementierung eines kompletten, dem Internet ähnlichen, Systems inklusive aller bekannten Anwendungsgebiete wie E-Mail, IRC oder BitTorrent)
- OMEMO[9] – Bereitstellung eines virtuellen anonymen Laufwerks durch Freigabe von individuellem Speicherplatz
- Metanet
- OFFSystem – verwandtes Projekt, jedoch mit anderer Zielsetzung
Siehe auch
- Verteilte Hashtabelle (DHT)
Weblinks
 Commons: Freenet – Sammlung von Bildern, Videos und Audiodateien
Commons: Freenet – Sammlung von Bildern, Videos und Audiodateien- Freenet Project – die offizielle Projektseite
- A Distributed Anonymous Information Storage and Retrieval System (PDF, englisch; 246 kB)
- The Freenet Help Site – inoffizielles Wiki mit Hilfetexten und Spezifikationen zu Freenet (englisch)
- Schöner Tauschen – ein ausführlicher Artikel unter anderen über Freenet beim Online Magazin Telepolis
- The Digital Evolution: Freenet and the Future of Copyright on the Internet – Artikel über Urheberrechte und Freenet mit Ausblick in die Zukunft (2002, englisch)
- Referat über Freenet (PDF)
- Freenet – Ein anonymes Netzwerk gegen Zensur und Überwachung, Artikel in der Computerwoche
Quellenangaben
- ↑ Freenet: People (22. September 2008). Abgerufen am 22. September 2008.
- ↑ Ian Clarke: A Distributed Anonymous Information Storage and Retrieval System. 1999.
- ↑ Kurzinformationen zum DefCon-Vortrag
- ↑ Kurzinformationen zum 22C3-Vortrag
- ↑ Freenet-China
- ↑ Xiao Qiang: The words you never see in Chinese cyberspace. in: China Digital Times. 30. August 2004.
- ↑ Antipiracy-Analyse vom 25. Mai 2004 (archivierte Version des Internet Archive)
- ↑ The Freenet Project: Understand Freenet, abgerufen am 15. Mai 2008, englisch, Zitat: „It is hard, but not impossible, to determine which files that are stored in your local Freenet Datastore. This is to enable plausible deniability as to what kind of material that lies on your harddrive in the datastore.“
- ↑ Omemo Website


Dieser Artikel wurde in die Liste der lesenswerten Artikel aufgenommen. Kategorien:- Wikipedia:Lesenswert
- Anonymität
- Freie Peer-to-Peer-Software

Wikimedia Foundation.