- Einfachregression
-
Die Regressionsanalyse ist ein statistisches Analyseverfahren. Ziel ist es, Beziehungen zwischen einer abhängigen und einer oder mehreren unabhängigen Variablen festzustellen.
Allgemein wird eine metrische Variable Y betrachtet, die von einer zweiten Variablen x abhängt. Üblicherweise ist
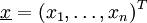 ein n-dimensionaler Vektor, wobei die einzelnen x-Werte untereinander unabhängig sind. Im eindimensionalen Fall spricht man von einer einfachen linearen Regressionsanalyse, in Dimensionen größer gleich zwei von einer multiplen Regressionsanalyse.
ein n-dimensionaler Vektor, wobei die einzelnen x-Werte untereinander unabhängig sind. Im eindimensionalen Fall spricht man von einer einfachen linearen Regressionsanalyse, in Dimensionen größer gleich zwei von einer multiplen Regressionsanalyse.Inhaltsverzeichnis
Grundbegriffe
Deskriptive Regression
Im Falle einer deskriptiven Regression wird angenommen, dass die Zusammenhänge zwischen x und den Beobachtungen Y deterministisch sind, also nicht vom Zufall abhängen. Dieser Fall lässt sich als Y = f(x) darstellen, wobei die Funktion f nicht oder nicht vollständig bekannt ist. Bei diesen deskriptiven Verfahren wird vor allem Wert auf den numerischen Aspekt der Regression gelegt. Das typische Instrument zur Analyse ist dabei die Methode der kleinsten Quadrate.
Wahrscheinlichkeitstheoretische Regression
Im Falle der wahrscheinlichkeitstheoretisch basierten Regression sind die beobachteten Variablen mit einem zufälligen Fehler ε behaftet, dieser Fall wird durch
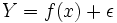 modelliert. Die „wahren“ Zusammenhänge zwischen Y und f(x) sind demnach nicht bekannt und müssen geschätzt oder prognostiziert werden. Entsprechend wird dieses statistische Regressionsmodell anhand von Schätz- und Testverfahren analysiert. Dennoch liegen der wahrscheinlichkeitstheoretisch basierten Regressionsanalyse immer die numerischen Verfahren der deskriptiven Regression zu Grunde.
modelliert. Die „wahren“ Zusammenhänge zwischen Y und f(x) sind demnach nicht bekannt und müssen geschätzt oder prognostiziert werden. Entsprechend wird dieses statistische Regressionsmodell anhand von Schätz- und Testverfahren analysiert. Dennoch liegen der wahrscheinlichkeitstheoretisch basierten Regressionsanalyse immer die numerischen Verfahren der deskriptiven Regression zu Grunde.In diesem Artikel soll vor allem auf die wahrscheinlichkeitstheoretisch basierte lineare Regression eingegangen werden.
Variablenbezeichnung
In der Regressionsanalyse unterscheidet man zwischen interessierenden und erklärenden Variablen.
- Die interessierende Variable
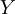 wird Kriterium, abhängige Variable, Response-Variable, endogene Variable, Regressand oder Zielvariable und
wird Kriterium, abhängige Variable, Response-Variable, endogene Variable, Regressand oder Zielvariable und - die erklärenden Variablen
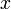 werden unabhängige Variablen, Prädiktor-Variablen, exogene Variable, Regressoren oder Kovariablen genannt.
werden unabhängige Variablen, Prädiktor-Variablen, exogene Variable, Regressoren oder Kovariablen genannt.
Es ist a priori nicht klar, welche Variablen erklärend und welche interessierend sind. Typischerweise wählt man diejenige Variable als Response, die eine natürliche Variabilität aufweist. Das Ziel der Regression ist es somit zu bestimmen, wie die interessierende Variable (Response) von den erklärenden Variablen (Kovariablen) abhängt.
Ein einfaches Beispiel ist die Darstellung des Körpergewichts in kg (hier: Y) in Abhängigkeit von der Körpergröße in cm (hier: x). Man sieht, dass der Response Y und die Kovariable x nicht vertauschbar sind, da die Körpergröße ab einem bestimmten Alter unverändert bleibt.
Zusammenhangsarten zwischen Variablen
Man verwendet zur Beschreibung eines Zusammenhangs zwischen der abhängigen Variable Y und der (oder den) unabhängigen Variablen x unterschiedliche Funktionen. Diese unterscheiden sich in ihrer Komplexität. Lineare Funktionen, das heißt durch Geraden gegebene Funktionen, sind dabei die einfachsten funktionalen Zusammenhänge. In diesem Fall wird angenommen, dass das interessierende Merkmal Y gut durch eine lineare Kombination anderer Merkmale x erklärt werden kann (lineare Regression). Die Gewichtung der Einflüsse der erklärenden Merkmale wird dabei aus Daten geschätzt. Ein lineares Regressionsmodell hat den Vorteil, dass es zum Beispiel mittels kleinster Quadrate exakt berechnet werden kann. Betrachtet man den Fall mit nur einer unabhängigen Variablen, so spricht man von linearer Einfachregression.
Nichtlineare Systeme müssen dagegen meist näherungsweise gelöst werden. Häufig können diese Regressionsmodelle dann nicht mehr wahrscheinlichkeitstheoretisch analysiert werden. Solche Regressionen sind beispielsweise die Geometrische Regression, Exponentielle Regression oder Potenzielle Regression. Bei der Logarithmischen Regression, welche nicht mit der Logistischen Regression zu verwechseln ist, arbeitet man, wie der Name bereits vermuten lässt, mit folgendem Ansatz für die Regression:
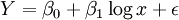 .
.
Die gängigen Statistik-Software-Pakete bieten diese Berechnungen heute automatisiert.
Dies kann für den Fall mit mehreren exogenen Variablen erweitert werden, wobei diese wiederum von mehreren abhängigen Variablen erklärt werden. Die abhängigen Variablen der einen Gleichung können hierbei als erklärende Variablen in einer anderen Gleichung erscheinen. Y und X werden dann durch Vektoren dargestellt (Ökonometrisches Modell).
Einfache Lineare Regression
Ein Spezialfall von Regressionsmodellen sind lineare Modelle. Hierbei spricht man von der einfachen linearen Regression, und die Daten liegen in der Form
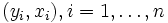 vor. Als Modell wählt man
vor. Als Modell wählt manman nimmt somit einen linearen Zusammenhang zwischen xi und Yi an. Die Daten yi werden als Realisierungen der Zufallsvariablen Yi angesehen, die xi sind nicht stochastisch, sondern Messstellen. Ziel der Regressionsanalyse ist in diesem Fall die Bestimmung der unbekannten Parameter β0 und β1.
Annahmen
Damit die Regressionsschätzungen inferentiell analysiert werden können, müssen für das lineare Regressionsmodell bestimmte Annahmen erfüllt sein:
1. Bezüglich der Störgröße εi
- Der Zufallsvektor
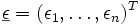 ist verteilt mit dem Erwartungswertvektor 0, d.h.
ist verteilt mit dem Erwartungswertvektor 0, d.h. 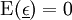 .
. - Die Zufallsvariablen εi sind stochastisch unabhängig voneinander d. h.
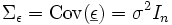 , wobei In die n dimensionale Einheitsmatrix bezeichnet. Dies kann man genauer auch schreiben als
, wobei In die n dimensionale Einheitsmatrix bezeichnet. Dies kann man genauer auch schreiben als
-
-
-
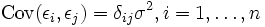 ,
,
-
-
-
-
- wobei δij das Kronecker-Delta bezeichnet. Hierbei gilt
-
-
-
-
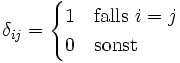 ,
,
-
-
-
-
- das heißt die Fehler sind unkorreliert mit homogener Varianz.
-
2. Die Datenmatrix
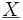 , welche im Abschnitt zur multiplen Regression explizit angegeben ist, ist fest vorgegeben.
, welche im Abschnitt zur multiplen Regression explizit angegeben ist, ist fest vorgegeben.3. Die Datenmatrix
hat den Rang (p + 1).- In der ersten Annahme haben also alle εi die gleiche Varianz (Homoskedastizität) und sie sind paarweise unkorreliert. Man interpretiert dies so, dass die Störgröße keinerlei Information enthalten darf und nur zufällig streut. Deshalb kann Y nur durch Informationen aus erklärt werden.
- Die zweite Annahme hält konstant.
- Die dritte Annahme ist für eine eindeutige Lösung des Regressionsproblems erforderlich.
Beispiel
Hier wird die einfache lineare Regression anhand eines Beispiels dargestellt.
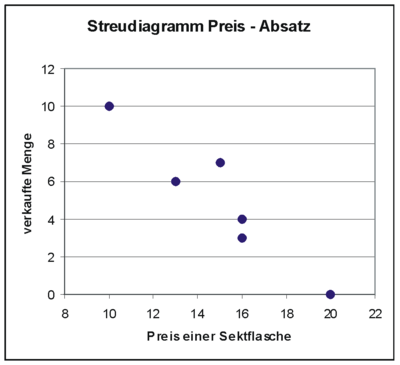
Eine renommierte Sektkellerei möchte einen hochwertigen Rieslingsekt auf den Markt bringen. Für die Festlegung des Abgabepreises soll zunächst eine Preis-Absatz-Funktion ermittelt werden. Dazu wurde in n = 6 Geschäften ein Testverkauf durchgeführt. Man erhielt sechs Wertepaare mit dem Ladenpreis x (in Euro) einer Flasche und die verkaufte Menge y an Flaschen:
Laden i 1 2 3 4 5 6 Preis einer Flasche xi 20 16 15 16 13 10 verkaufte Menge yi 0 3 7 4 6 10 Als Streudiagramm von Preis und abgesetzter Menge an Sektflaschen ergibt sich folgende Grafik.
Berechnung der Regressionsgeraden
Man geht von folgendem statistischen Modell aus:
Man betrachtet zwei Variablen Y und x, die vermutlich ungefähr in einem linearen Zusammenhang
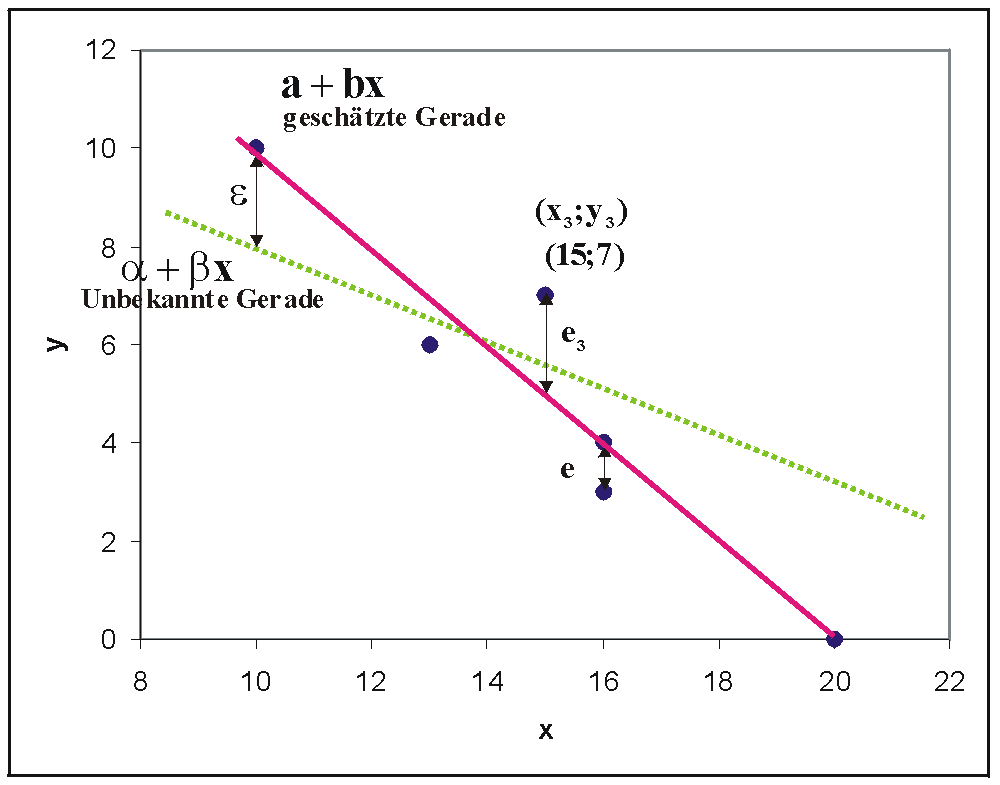
stehen. Auf die Vermutung des linearen Zusammenhangs kommt man, wenn man das obige Streudiagramm betrachtet, dort erkennt man, dass die eingetragenen Punkte nahezu auf einer Linie liegen. Im Weiteren sind x als unabhängige und Y als abhängige Variable definiert. Es existieren von x und y je n Beobachtungen xi und yi, wobei i von 1 bis n geht. Der funktionale Zusammenhang Y = f(x) zwischen x und Y kann nicht exakt festgestellt werden, da α + βx von einer Störgröße ε überlagert wird. Diese Störgröße ist als Zufallsvariable (der Grundgesamtheit) konzipiert, die nichterfassbare Einflüsse (menschliches Verhalten oder Messungenauigkeiten oder ähnliches) darstellt. Es ergibt sich also das Modell
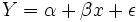 oder genauer
oder genauer 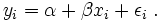
Da α und β nicht bekannt sind, kann y nicht in die Komponenten α + βx und ε zerlegt werden. Des Weiteren soll eine mathematische Schätzung für die Parameter α und β durch a und b gefunden werden, damit ergibt sich
mit dem Residuum ei der Stichprobe. Das Residuum gibt die Differenz zwischen der Regressionsgerade a + bxi und den Messwerten yi an. Des Weiteren bezeichnet man mit
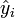 den Schätzwert für yi und es gilt
den Schätzwert für yi und es gilt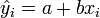 und somit kann man das Residuum schreiben als
und somit kann man das Residuum schreiben als 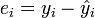 .
.
Es gibt verschiedene Möglichkeiten, die Gerade zu schätzen. Man könnte eine Gerade so durch den Punkteschwarm legen, dass die Quadratsumme der Residuen, also der senkrechten Abweichungen ei der Punkte von dieser Ausgleichsgeraden minimiert wird. Trägt man die wahre unbekannte und die geschätzte Regressionsgerade in einer gemeinsamen Grafik ein, dann ergibt sich folgende Abbildung.
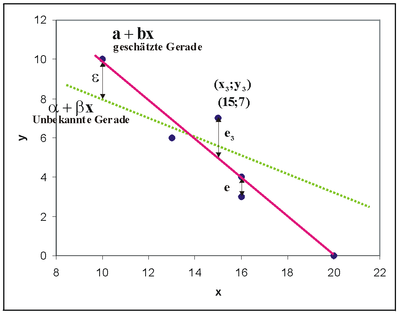
Diese herkömmliche Methode ist die Minimum-Quadrat-Methode oder Methode der kleinsten Quadrate. Man minimiert die summierten Quadrate der Residuen,
bezüglich a und b. Durch partielles Differenzieren und Nullsetzen der Ableitungen erster Ordnung erhält man ein System von Normalgleichungen.
Die gesuchten Regressionskoeffizienten sind die Lösungen
und
mit
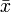 als arithmetischem Mittel der x-Werte und
als arithmetischem Mittel der x-Werte und 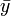 als arithmetischem Mittel der y-Werte. SSxy stellt die empirische Kovarianz zwischen den xi und yi dar. SSxx bezeichnet die empirische Varianz der xi. Man nennt diese Schätzungen auch Kleinste-Quadrate-Schätzer (KQ) oder Ordinary Least Squares-Schätzer (OLS).
als arithmetischem Mittel der y-Werte. SSxy stellt die empirische Kovarianz zwischen den xi und yi dar. SSxx bezeichnet die empirische Varianz der xi. Man nennt diese Schätzungen auch Kleinste-Quadrate-Schätzer (KQ) oder Ordinary Least Squares-Schätzer (OLS).Für das folgende Zahlen-Beispiel ergibt sich
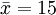 und
und 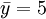 . Somit erhält man die Schätzwerte für a und b durch einfaches Einsetzen in obige Formeln. Zwischenwerte in diesen Formeln sind in folgender Tabelle dargestellt.
. Somit erhält man die Schätzwerte für a und b durch einfaches Einsetzen in obige Formeln. Zwischenwerte in diesen Formeln sind in folgender Tabelle dargestellt.i Flaschenpreis xi verkaufte Menge yi 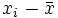
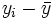
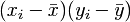
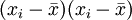
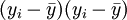
1 20 0 5 -5 -25 25 25 0,09 2 16 3 1 -2 -2 1 4 4,02 3 15 7 0 2 0 0 4 5,00 4 16 4 1 -1 -1 1 1 4,02 5 13 6 -2 1 -2 4 1 6,96 6 10 10 -5 5 -25 25 25 9,91 Total 90 30 0 0 -55 56 60 30,00 Es ergibt sich in dem Beispiel
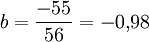 und
und 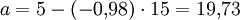 .
.
Die geschätzte Regressionsgerade lautet somit
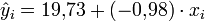 ,
,
so dass man vermuten kann, dass bei jedem Euro mehr der Absatz im Durchschnitt um ungefähr eine Flasche sinkt.
Multiple Regression
Im folgenden wird ausgehend von der einfachen linearen Regression die multiple Regression eingeführt. Der Response Y hängt linear von mehreren fest vorgegebenen Kovariablen
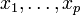 ab, somit erhält man die Form
ab, somit erhält man die Formwobei ε wieder die Störgröße repräsentiert. ε ist eine Zufallsvariable und daher ist Y als lineare Transformation von ε ebenfalls eine Zufallsvariable. Es liegen für die xj, wobei
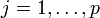 , und Y je n viele Beobachtungen vor, so dass sich für die Beobachtungen i, wobei
, und Y je n viele Beobachtungen vor, so dass sich für die Beobachtungen i, wobei 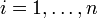 , das Gleichungssystem
, das Gleichungssystemergibt. p gibt somit die Anzahl der Kovariablen oder die Dimension des Kovariablenvektors
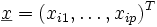 an. In der einfachen linearen Regression wurde nur der Fall p = 1 betrachtet, ausgehend davon wird nun die multiple Regression als Verallgemeinerung dessen mit
an. In der einfachen linearen Regression wurde nur der Fall p = 1 betrachtet, ausgehend davon wird nun die multiple Regression als Verallgemeinerung dessen mit 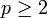 präsentiert. Als stichprobentheoretischer Ansatz wird jedes Stichprobenelement εi als eine eigene Zufallsvariable interpretiert und ebenso jedes Yi.
präsentiert. Als stichprobentheoretischer Ansatz wird jedes Stichprobenelement εi als eine eigene Zufallsvariable interpretiert und ebenso jedes Yi.Da es sich hier um ein lineares Gleichungssystem handelt, können die Elemente des Systems in Matrix-Schreibweise zusammengefasst werden. Man erhält die
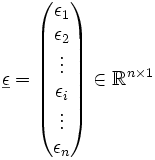
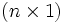 Spaltenvektoren der abhängigen Variablen Y und der Störgröße ε als Zufallsvektoren und den
Spaltenvektoren der abhängigen Variablen Y und der Störgröße ε als Zufallsvektoren und den 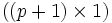 Spaltenvektor der Regressionskoeffizienten βj, wobei
Spaltenvektor der Regressionskoeffizienten βj, wobei 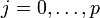 ,
,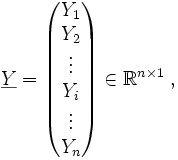
 und
und 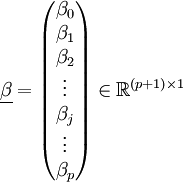 .
.
Die Datenmatrix
lautet in ausgeschriebener Form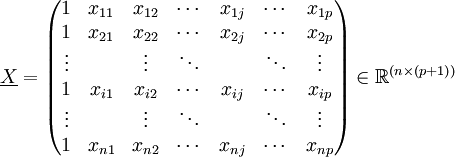 .
.
Die Einsen in der ersten Spalte gehören zum Absolutglied β0. Des Weiteren trifft man, wie bereits im Abschnitt zur einfachen linearen Regression erwähnt, die Annahmen
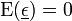 und
und 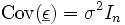 .
.
Somit gilt für
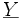
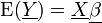 und
und 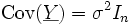 .
.
Ferner lässt sich das Gleichungssystem nun erheblich einfacher darstellen als
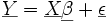 .
.
Schätzung der Regressionskoeffizienten
Auch im multiplen linearen Regressionsmodell wird die Quadratsumme der Residuen nach der Methode der kleinsten Quadrate minimiert. Man erhält als Lösung eines Minmierungsproblems den Vektor der geschätzten Regressionskoeffizienten als
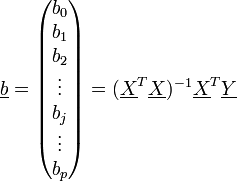 .
.
Dieser Schätzer ist nach dem Gauß-Markow-Theorem der BLUE (Best Linear Unbiased Estimator), also der beste (erwartungstreu mit kleinster Varianz) lineare unverzerrte Schätzer. Für die Eigenschaften der Schätzfunktion
 muss also keine Verteilungsinformation der Störgröße vorliegen.
muss also keine Verteilungsinformation der Störgröße vorliegen.Man erhält mit Hilfe des Minimum-Quadrat-Schätzers
das Gleichungssystemwobei
 der Vektor der Residuen und
der Vektor der Residuen und 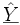 die Schätzung für ist. Das Interesse der Analyse liegt vor allem in der Schätzung
die Schätzung für ist. Das Interesse der Analyse liegt vor allem in der Schätzung 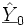 oder in der Prognose der abhängigen Variablen für ein gegebenes Tupel von
oder in der Prognose der abhängigen Variablen für ein gegebenes Tupel von 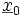 . Diese berechnet sich als
. Diese berechnet sich als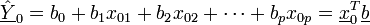 .
.
Ausgewählte Schätzfunktionen
Die Schätzwerte der Yi berechnen sich als
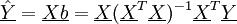 ,
,
wobei man dies auch kürzer als
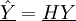 mit
mit 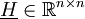
schreiben kann. Die Matrix
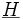 ist idempotent und maximal vom Rang p + 1. Sie wird auch Hat-Matrix genannt, weil sie den „Hut“ aufsetzt.
ist idempotent und maximal vom Rang p + 1. Sie wird auch Hat-Matrix genannt, weil sie den „Hut“ aufsetzt.Die Residuen werden ermittelt als
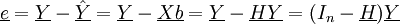 ,
,
wobei
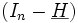 mit vergleichbare Eigenschaften hat.
mit vergleichbare Eigenschaften hat.Die Prognose
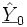 wird ermittelt als
wird ermittelt als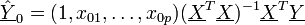 .
.
Da
fest vorgegeben ist, kann man alle diese Variablen als lineare Transformation von und damit von 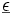 darstellen, und deshalb können auch ihr Erwartungswertvektor und ihre Kovarianzmatrix unproblematisch ermittelt werden.
darstellen, und deshalb können auch ihr Erwartungswertvektor und ihre Kovarianzmatrix unproblematisch ermittelt werden.Die Quadratsumme SSRes (von engl. „residual sum of squares“) der Residuen ergibt in Matrix-Notation
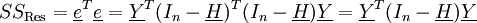 .
.
Dies kann ferner auch geschrieben werden als
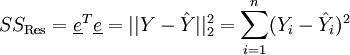 .
.
Die Varianz wird mit Hilfe der Residuen geschätzt, und zwar als mittlere Quadratsumme der Residuen
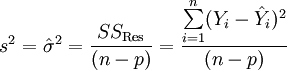 .
.
Schätzen und Testen
Für die inferentielle Regression (Schätzen und Testen) wird noch die Information über die Verteilung der Störgröße ε gefordert. Zusätzlich zu den bereits weiter oben aufgeführten Annahmen hat man hier als weitere Annahme:
4. Die Störgröße εi ist normalverteilt.
Zusammen mit der 1. Annahme erhält man für die Verteilung des Vektors der Störgröße:
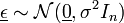 ,
,
wobei
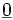 den Nullvektor bezeichnet. Hier sind unkorrelierte Zufallsvariablen auch stochastisch unabhängig. Da die interessierenden Schätzer zum größten Teil lineare Transformationen von sind, sind sie ebenfalls normalverteilt mit den entsprechenden Parametern. Ferner ist die Quadratsumme der Residuen als nichtlineare Transformation χ2-verteilt mit n − p Freiheitsgraden.
den Nullvektor bezeichnet. Hier sind unkorrelierte Zufallsvariablen auch stochastisch unabhängig. Da die interessierenden Schätzer zum größten Teil lineare Transformationen von sind, sind sie ebenfalls normalverteilt mit den entsprechenden Parametern. Ferner ist die Quadratsumme der Residuen als nichtlineare Transformation χ2-verteilt mit n − p Freiheitsgraden.-
Beweisskizze: Sei
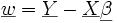 ,
,
damit erhält man
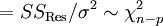 .
.
Wobei
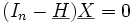 und der Satz von Cochran verwendet wurde.
und der Satz von Cochran verwendet wurde.
Ferner gilt ebenso
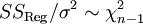 .
.
Betrachte hierzu auch den Artikel Bestimmtheitsmaß.
Güte des Regressionsmodells
Hat man eine Regression ermittelt, ist man auch an der Güte dieser Regression interessiert. Häufig verwendet wird als Maß für die Güte das Bestimmtheitsmaß R2. Generell gilt, je näher der Wert des Bestimmtheitsmaßes bei 1 liegt, desto größer ist die Güte der Regression. Ist das Bestimmtheitsmaß klein, kann man seine Signifikanz durch die Hypothese H0: R2 = 0 mit der Prüfgröße
testen. F ist F-verteilt mit n-1 und n-p Freiheitsgraden. Überschreitet die Prüfgröße bei einem Signifikanzniveau α den kritischen Wert F(1 − α;n − 1;n − p), das (1-α)-Quantil der F-Verteilung mit n-1 und n-p Freiheitsgraden, wird H0 abgelehnt. R2 ist dann ausreichend groß, X trägt also vermutlich genügend viel Information zur Erklärung von Y bei. Die Residualanalyse, bei der man die Residuen über den unabhängigen Variablen aufträgt, gibt Aufschluss über
- die Richtigkeit des angenommenen linearen Zusammenhangs,
- mögliche Ausreißer,
- Homoskedastizität, Heteroskedastizität.
Ein Ziel bei der Residualanalyse ist es, dass man die Voraussetzung der unbeobachteten Residuen εi überprüft. Hierbei ist es wichtig zu beachten, dass
gilt. ei ist mit der Formel
berechenbar. Im Gegensatz hierzu ist die Störgröße εi nicht berechenbar oder beobachtbar. Nach den oben getroffenen Annahmen soll für das Modell gelten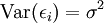 ,
,
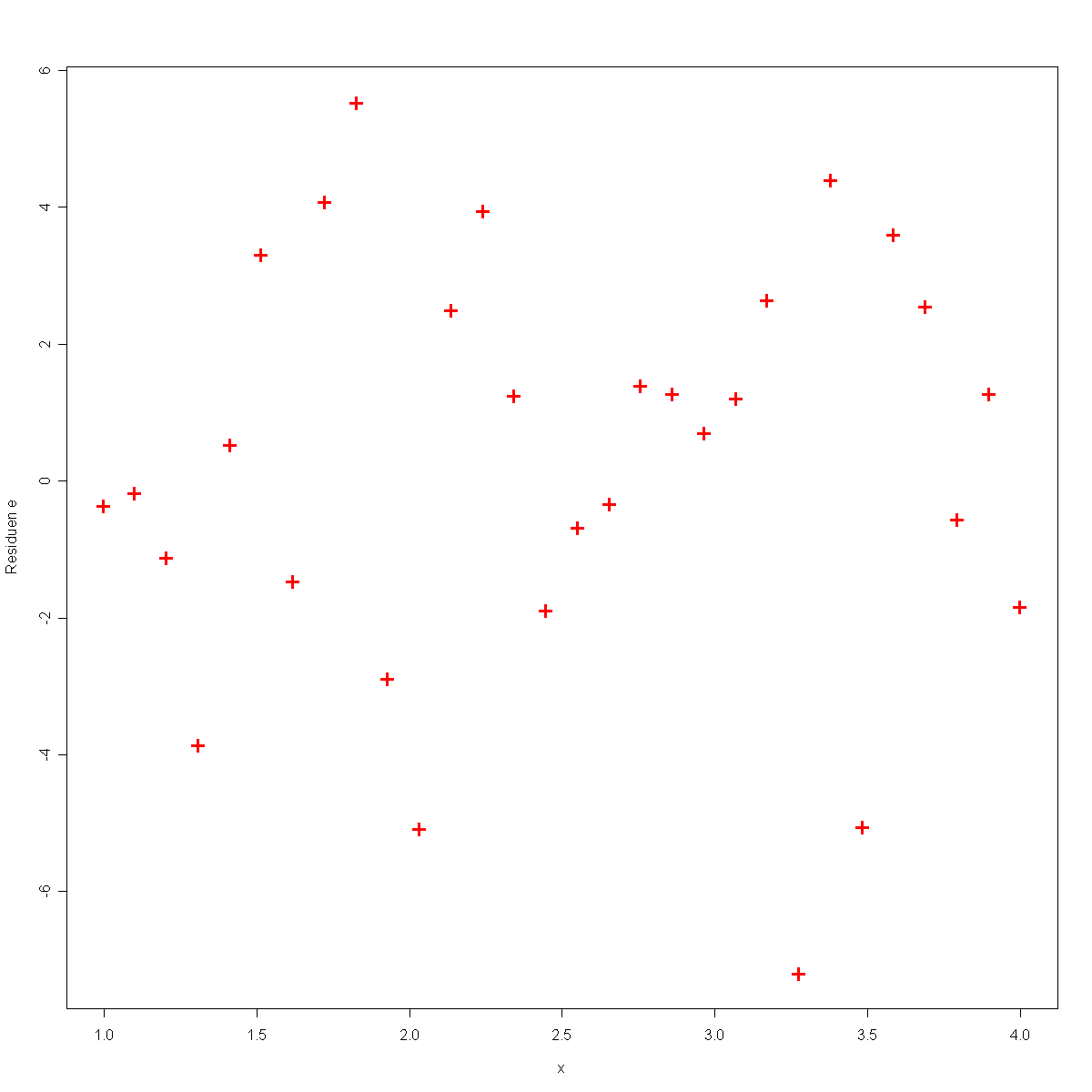
es liegt somit eine Varianzhomogenität vor. Dieses Phänomen wird auch als Homoskedastie bezeichnet und ist auf die Residuen übertragbar. Dies bedeutet, dass wenn man die unabhängigen Variablen x gegen die Residuen e aufträgt, dass dann keine systematischen Muster erkennbar sein sollten.
In der folgenden Grafik werden die unabhängigen Variablen x gegen die Residuen e geplottet.
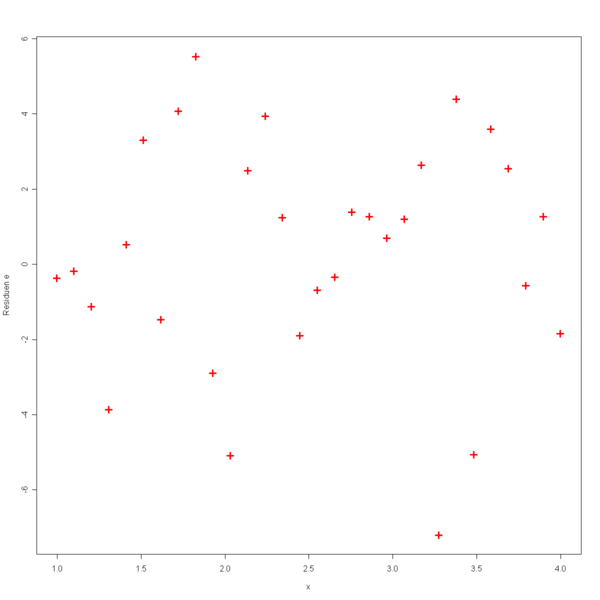
In dieser Grafik sieht man, dass kein erkennbares Muster in den Residuen vorliegt. Somit ist die Annahme der Varianzhomogenität erfüllt. Anschließend werden zwei Grafiken aufgeführt, bei denen diese Annahme nicht erfüllt ist.
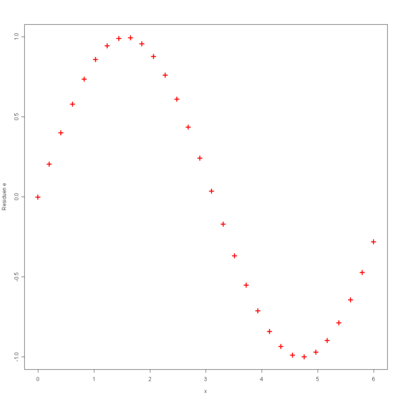
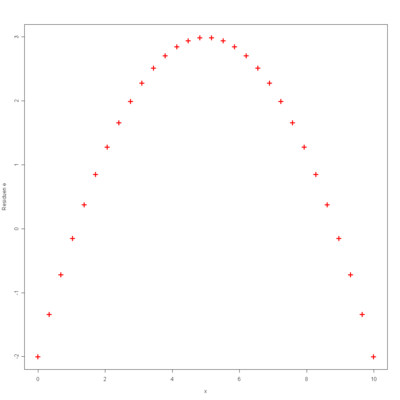
Bei der linken Abbildung erkennt man ein Muster, welches an die Sinus-Funktion erinnert. Somit wäre hier eine Daten-Transformation in der Form
denkbar. Bei der rechten Abbildung erkennt man ein Muster, welches die Form einer Parabel annimmt. Somit wäre hier eine Daten-Transformation in der Form
angebracht.
Beitrag der einzelnen Regressoren zur Erklärung von y
Man ist daran interessiert, ob man einzelne Parameter oder Kovariablen aus dem Regressionsmodell entfernen kann. Dies ist dann möglich, falls ein Parameter βj gleich Null ist, somit testet man die Nullhypothese H0: βj = 0. Das heißt man testet, ob der j-te Parameter gleich Null ist, falls dies der Fall ist, kann die zugehörige j-te Kovariable Xj aus dem Modell entfernt werden. Der Vektor b ist als lineare Transformation von Y verteilt wie
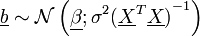 .
.
Wenn man die Varianz der Störgröße schätzt, erhält man für die geschätzte Kovarianzmatrix
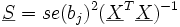 .
.
Die geschätzte Varianz se(bj)2 eines Regressionskoeffizienten bj steht als j-tes Diagonalelement in der geschätzten Kovarianzmatrix. Es ergibt sich die Prüfgröße
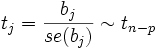 ,
,
die t-verteilt ist mit n-p Freiheitsgraden. Ist | tj | größer als der kritische Wert t(1-α/2; n-p), dem (1-α/2)-Quantil der t-Verteilung mit n-p Freiheitsgraden, wird die Hypothese abgelehnt. Somit wird die Kovariable Xj im Modell beibehalten und der Beitrag des Regressors Xj zur Erklärung von Y ist signifikant groß.
Prognose
Ermittelt man einen Prognosewert, möchte man möglicherweise wissen, in welchem Intervall sich die prognostizierten Werte mit einer festgelegten Wahrscheinlichkeit bewegen. Man wird also ein Konfidenzintervall für den durchschnittlichen Prognosewert E(Y0) ermitteln. Es ergibt sich als Varianz der Prognose
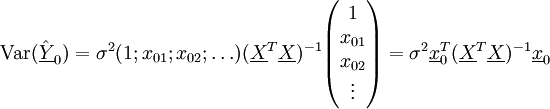 .
.
Man erhält dann als (1-α)-Konfidenzintervall für den durchschnittlichen Prognosewert mit geschätzter Varianz
![[\underline{\hat{Y}}_0 - s \cdot t_{1-\alpha /2; n-p} \; ; \; \underline{\hat{Y}}_0 + s \cdot t_{1-\alpha /2; n-p}]](/pictures/dewiki/101/e945a8fe0ebadf0b2979aa141696d8bb.png) .
.
Speziell für den Fall der einfachen linearen Regression ergibt das
Speziell aus dieser Form des Konfidenzintervalls erkennt man sofort, dass das Konfidenzintervall breiter wird, wenn die exogene Prognosevariable x0 sich vom „Zentrum“ der Daten entfernt. Schätzungen der endogenen Variablen sollten also im Beobachtungsraum der Daten liegen, sonst werden sie sehr unzuverlässig.
Beispiel
Zur Illustration der multiplen Regression wird im folgenden Beispiel untersucht, wie die abhängige Variable Y: Bruttowertschöpfung (in Preisen von 95; bereinigt, Mrd. Euro) von den unabhängigen Variablen „Bruttowertschöpfung nach Wirtschaftsbereichen Deutschland (in jeweiligen Preisen; Mrd. EUR)“ abhängt. Die Daten sind im Artikel Regressionsanalyse/Datensatz angegeben. Da man in der Regel die Berechnung eines Regressionsmodells am Computer durchführt, wird in diesem Beispiel exemplarisch dargestellt, wie eine multiple Regression mit der Statistik-Software R durchgeführt werden kann.
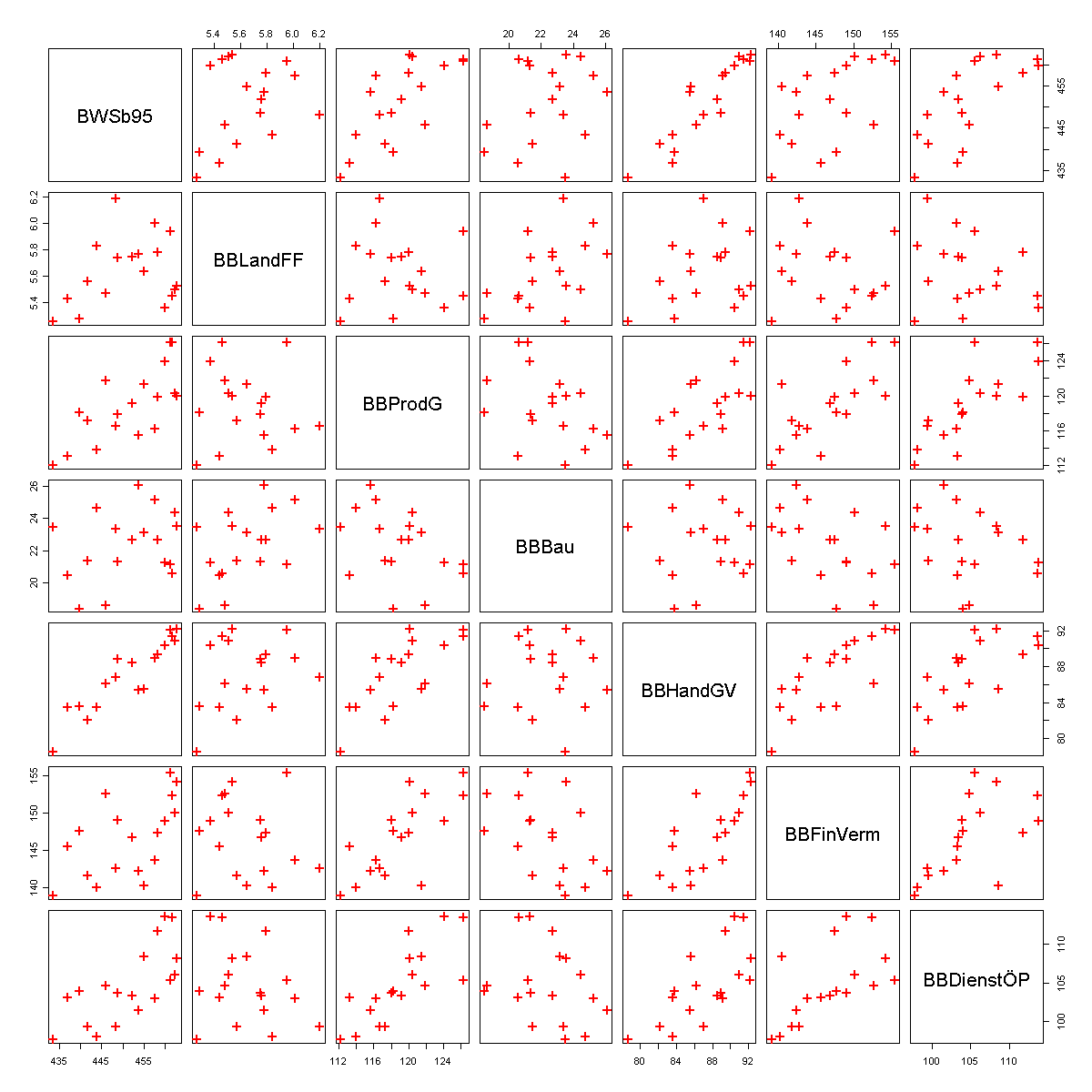
Variable Beschreibung der Variablen BWSb95 Bruttowertschöpfung in Preisen von 95 (bereinigt) BBLandFF Bruttowertschöpfung von Land- und Forstwirtschaft, Fischerei BBProdG Bruttowertschöpfung des produzierenden Gewerbes ohne Baugewerbe BBBau Bruttowertschöpfung im Baugewerbe BBHandGV Bruttowertschöpfung von Handel, Gastgewerbe und Verkehr BBFinVerm Bruttowertschöpfung durch Finanzierung, Vermietung und Unternehmensdienstleister BBDienstÖP Bruttowertschöpfung von öffentlichen und privaten Dienstleistern Zunächst lässt man sich ein Streudiagramm ausgeben, in diesem erkennt man, dass die gesamte Wertschöpfung offensichtlich mit den Wertschöpfungen der wirtschaftlichen Bereiche positiv korreliert ist. Dies erkennt man daran, dass die Datenpunkte in der ersten Spalte der Grafik in etwa auf einer Geraden mit einer positiven Steigung liegen. Auffällig ist, dass die Wertschöpfung im Baugewerbe negativ mit den anderen Sektoren korreliert. Dies erkennt man daran, dass in der vierten Spalte die Datenpunkte näherungsweise auf einer Geraden mit einer negativen Steigung liegen.
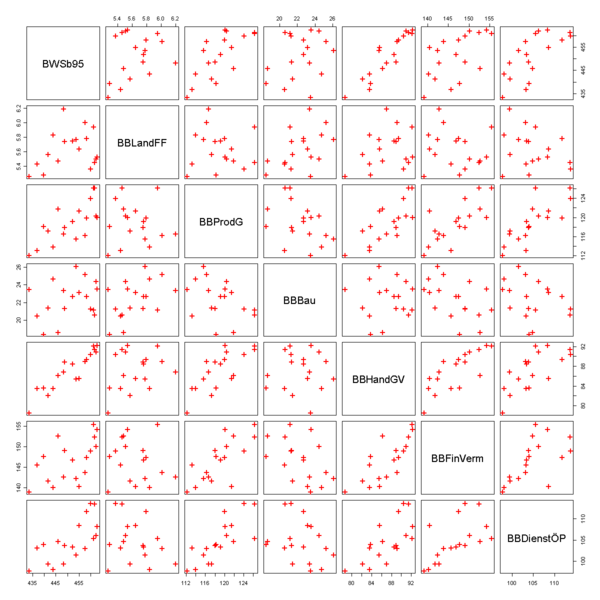
In einem ersten Schritt gibt man das Modell mit allen Kovariablen in R ein
lm(BWSb95~BBLandFF+BBProdG+BBBau+BBHandGV+BBFinVerm+BBDienstÖP)
Anschließend lässt man sich in R ein Summary des Modells mit allen Kovariablen ausgeben, dann erhält man folgende Auflistung.
Residuals: Min 1Q Median 3Q Max -1.5465 -0.8342 -0.1684 0.5747 1.5564 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 145.6533 30.1373 4.833 0.000525 *** BBLandFF 0.4952 2.4182 0.205 0.841493 BBProdG 0.9315 0.1525 6.107 7.67e-05 *** BBBau 2.1671 0.2961 7.319 1.51e-05 *** BBHandGV 0.9697 0.3889 2.494 0.029840 * BBFinVerm 0.1118 0.2186 0.512 0.619045 BBDienstÖP 0.4053 0.1687 2.402 0.035086 * --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 1.222 on 11 degrees of freedom Multiple R-Squared: 0.9889, Adjusted R-squared: 0.9828 F-statistic: 162.9 on 6 and 11 DF, p-value: 4.306e-10Der Test auf Güte des gesamten Regressionsmodells ergibt eine Prüfgröße von F = 162.9. Diese Prüfgröße hat einen p-Wert von
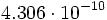 , somit ist die Anpassung signifikant gut.
, somit ist die Anpassung signifikant gut.Die Analyse der einzelnen Beiträge der Variablen (Tabelle Coefficients) des Regressionsmodells ergibt bei einem Signifikanzniveau von 0.05, dass die Variablen BBLandFF und BBFinVerm offensichtlich die Variable BWSB95 nur unzureichend erklären können. Dies erkennt man daran, dass die zugehörigen t-Werte zu diesen beiden Variablen verhältnismäßig klein sind, und somit die Hypothese, dass die Koeffizienten dieser Variablen Null sind, nicht verworfen werden kann.
Die Variablen BBHandGV und BBDienstÖP sind gerade noch signifikant. Besonders stark korreliert ist Y (in diesem Beispiel also BWSb95) mit den Variablen BBProdG und BBBau, was man an den zugehörigen hohen t-Werten erkennen kann.
Im nächsten Schritt werden die insignifikanten Kovariablen BBLandFF und BBFinVerm aus dem Modell entfernt.
lm(BWSb95~BBProdG+BBBau+BBHandGV+BBDienstÖP)
Anschließend lässt man sich wiederum ein Summary des Modells ausgeben, dann erhält man folgende Auflistung.
Residuals: Min 1Q Median 3Q Max -1.34447 -0.96533 -0.05579 0.82701 1.42914 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 158.00900 10.87649 14.528 2.05e-09 *** BBProdG 0.93203 0.14115 6.603 1.71e-05 *** BBBau 2.03613 0.16513 12.330 1.51e-08 *** BBHandGV 1.13213 0.13256 8.540 1.09e-06 *** BBDienstÖP 0.36285 0.09543 3.802 0.0022 ** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 1.14 on 13 degrees of freedom Multiple R-Squared: 0.9886, Adjusted R-squared: 0.985 F-statistic: 280.8 on 4 and 13 DF, p-value: 1.783e-12Dieses Modell liefert eine Prüfgröße von F = 280.8. Diese Prüfgröße hat einen p-Wert von
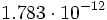 , somit ist die Anpassung besser als im ersten Modell. Dies ist vor allem darauf zurückzuführen, dass in dem jetzigen Modell alle Kovariablen signifikant sind.
, somit ist die Anpassung besser als im ersten Modell. Dies ist vor allem darauf zurückzuführen, dass in dem jetzigen Modell alle Kovariablen signifikant sind.Spezielle Anwendungen der Regressionsanalyse
Spezielle Anwendungen der Regressionsanalyse beziehen sich auch auf die Analyse von diskreten und im Wertebereich eingeschränkten abhängigen Variablen. Hierbei kann unterschieden werden nach Art der abhängigen Variablen und Art der Einschränkung des Wertebereichs. Im Folgenden werden die Regressionsmodelle, die an dieser Stelle angewandt werden können, aufgeführt. Nähere Angaben hierzu finden sich bei Frone (1997)[1] sowie Long (1997) [2].
Modelle für unterschiedliche Arten abhängiger Variablen:
- Binär: logistische Regression und Probit-Regression
- Ordinal: ordinale logistische Regression und ordinale Probit-Regression
- Absolut: Poisson Regression, negative binomiale Regression
- Nominal: multinomiale logistische Regression
Modelle für unterschiedliche Arten eingeschränkter Wertebereiche:
- zensiert: Tobit-Modell
- trunkiert: trunkierte Regression
- stichproben-selegiert: (sample-selected) stichproben-selegierte Regression
Anwendung in der Ökonometrie
Für quantitative Wirtschaftsanalysen im Rahmen der Regressionsanalyse, beispielsweise der Ökonometrie, sind besonders geeignet:
- Wachstumsfunktionen, wie zum Beispiel das Gesetz des organischen Wachstums oder die Zinseszinsrechnung,
- Abschwingfunktionen, wie zum Beispiel die hyperbolische Verteilungsfunktion oder die Korachsche Preisfunktion,
- Schwanenhalsfunktionen, wie zum Beispiel die im Rahmen der logistischen Regression verwendete logistische Funktion, die Johnson-Funktion oder die Potenzexponentialfunktion,
- degressive Saturationsfunktionen, wie zum Beispiel die Gompertz-Funktion oder die Törnquist-Funktion.
Literatur
- ↑ Frone, M.R. (1997). Regression models for discrete and limited dependent variables. Research Methods Forum No. 2. online
- ↑ Long, J. S. (1997). Regression models for categorical and limited dependent variables. Thousand Oaks, CA: Sage.
Siehe auch
- Korrelationskoeffizient
- Messfehler
- Dummy-Variable
- Faktorenanalyse
- Ausgleichsrechnung
- Response (Mathematik)
- Generalisierte Lineare Modelle
Literatur
- Draper, Norman R. und Smith Harry: Applied Regression Analysis, 1998, New York: Wiley
- Fahrmeir, Ludwig/ Kneib, Thomas/ Lang, Stefan: Regression: Modelle, Methoden und Anwendungen, Springer Verlag Berlin Heidelberg New York 2007, ISBN 9783540339328.
- Opfer, Gerhard: Numerische Mathematik für Anfänger, 2. Auflage, 1994, Vieweg Verlag
- Oppitz, Volker/Nollau, Volker: Taschenbuch Wirtschaftlichkeitsrechnung, Carl Hanser Verlag 2003, 400 S., ISBN 3446224637
- Oppitz, Volker Gabler Lexikon Wirtschaftlichkeitsberechnung, Gabler-Verlag 1995, 629 S., ISBN 3409199519
- Schönfeld, Peter: Methoden der Ökonometrie, Berlin, Frankfurt, 1969
- Urban, Dieter/ Mayerl, Jochen: Regressionsanalyse: Theorie, Technik und Anwendung, 2. überarb. Auflage, 2006, Wiesbaden: VS Verlag, ISBN 3531337394
- Zeidler E. (Hrsg.): Taschenbuch der Mathematik (bekannt als Bronstein und Semendjajew), Stuttgart, Leipzig, Wiesbaden 2003
- Backhaus, K./ Erichson, B./ Plinke, W./ Weiber, R.: Multivariate Analysemethoden - Eine anwendungsorientierte Einführung. 12. Auflage, Berlin et al. 2008'
Weblinks
- Die interessierende Variable
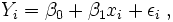

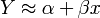
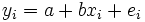
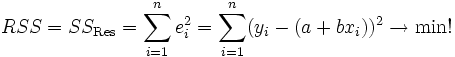
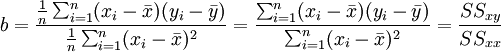
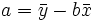
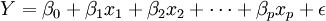
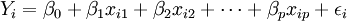
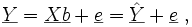
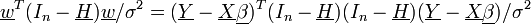
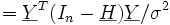
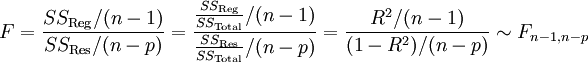
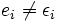


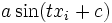
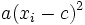
![\left[ \underline{\hat{Y}}_0 - t_{1- \alpha/2 ; n-p} \cdot s \cdot \sqrt { 1 + \frac {1}{n} + \frac {(x_0 - \bar x)^2} { \sum_{i=1}^n (x_i - \bar x)^2 }} \; ; \; \underline{\hat{Y}}_0 + t_{1- \alpha/2 ; n-p} \cdot s \cdot \sqrt {1 + \frac {1}{n} + \frac {(x_0 - \bar x)^2} { \sum_{i=1}^n (x_i - \bar x)^2 }} \right]](/pictures/dewiki/50/2159c856f78b28fc0d9c5bba5ad95436.png)
Wikimedia Foundation.