- Pearson-Koeffizient
-
Der Korrelationskoeffizient (auch: Korrelationswert) oder die Produkt-Moment-Korrelation (von Bravais und Pearson, daher auch Pearson-Korrelation genannt) ist ein dimensionsloses Maß für den Grad des linearen Zusammenhangs (Zusammenhangsmaße) zwischen zwei mindestens intervallskalierten Merkmalen. Er kann Werte zwischen −1 und 1 annehmen. Bei einem Wert von +1 (bzw. −1) besteht ein vollständig positiver (bzw. negativer) linearer Zusammenhang zwischen den betrachteten Merkmalen. Wenn der Korrelationskoeffizient den Wert 0 aufweist, hängen die beiden Merkmale überhaupt nicht linear voneinander ab. Allerdings können diese ungeachtet dessen in nicht-linearer Weise voneinander abhängen. Damit ist der Korrelationskoeffizient kein geeignetes Maß für die (reine) stochastische Abhängigkeit von Merkmalen.
Je nachdem, ob der lineare Zusammenhang zwischen zeitgleichen Messwerten zweier verschiedener Merkmale oder derjenige zwischen zeitlich verschiedenen Messwerten eines einzigen Merkmals betrachtet wird, spricht man entweder von der Kreuzkorrelation oder von der Autokorrelation (siehe Zeitreihenanalyse).
Definitionen
Korrelationskoeffizient (nach Pearson)
Für zwei quadratisch integrierbare Zufallsvariablen X und Y mit jeweils positiver Varianz
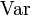 ist der Korrelationskoeffizient (Pearsonscher Maßkorrelationskoeffizient) durch
ist der Korrelationskoeffizient (Pearsonscher Maßkorrelationskoeffizient) durchdefiniert, wobei
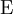 den Erwartungswert-Operator und
den Erwartungswert-Operator und 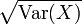 die Standardabweichung von X bezeichnet. Weitere übliche Schreibweisen sind
die Standardabweichung von X bezeichnet. Weitere übliche Schreibweisen sind 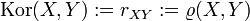 .
.Ferner heißen X,Y unkorreliert, falls
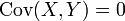 .
.Empirischer Korrelationskoeffizient
Sind für die beiden Zufallsvariablen lediglich zwei Messreihen
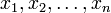 und
und 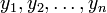 bekannt, so wird der empirische Korrelationskoeffizient berechnet durch
bekannt, so wird der empirische Korrelationskoeffizient berechnet durchDabei sind
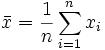 und
und 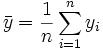
die empirischen Erwartungswerte X und Y anhand der Messreihe.
Sind diese Messreihenwerte z-transformiert mit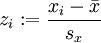 , wobei
, wobei 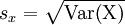 die Streuung bezeichnet, gilt auch:
die Streuung bezeichnet, gilt auch:wobei df für die Freiheitsgrade bei der Berechnung der zugrundegelegten Streuung zu ersetzen ist (also n oder (n − 1)).
Eigenschaften
Mit der Definition des Korrelationskoeffizienten gilt unmittelbar
-
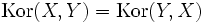 bzw. rxy = ryx
bzw. rxy = ryx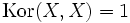 .
.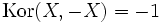 .
.
Mit der Cauchy-Schwarz-Ungleichung sieht man, dass
-
![\operatorname{Kor}(X,Y)\in[-1,1]](/pictures/dewiki/100/d447dd03e64dcc5e757489b3b56b5d99.png) .
.
Durch Optimieren ergibt sich, dass Y = aX + b fast sicher genau dann, wenn
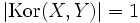 .
.Sind die Zufallsgrößen X und Y voneinander unabhängig, dann gilt:
-
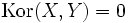 . Die Umkehrung dieses Satzes gilt jedoch im allgemeinen nicht (Voraussetzungen für die Umkehrung des Satzes sind z.B. in en:normally distributed and uncorrelated does not imply independent skizziert).
. Die Umkehrung dieses Satzes gilt jedoch im allgemeinen nicht (Voraussetzungen für die Umkehrung des Satzes sind z.B. in en:normally distributed and uncorrelated does not imply independent skizziert).
Voraussetzungen für die Pearson-Korrelation
Der Korrelationskoeffizient nach Pearson erlaubt Aussagen über statistische Zusammenhänge unter folgenden Bedingungen:
Skalierung
Der Pearsonsche Korrelationskoeffizient liefert korrekte Ergebnisse bei intervallskalierten und bei dichotomen Daten. Für niedrigere Skalierungen existieren andere Korrelationskonzepte (z. B. Rangkorrelationskoeffizienten).
Normalverteilung
Beide Variablen müssen annähernd normalverteilt sein. Bei zu starken Abweichungen von der Normalverteilung muss auf Rangkorrelationen zurückgegriffen werden.
Linearitätsbedingung
Zwischen den Variablen x und y wird ein linearer Zusammenhang vorausgesetzt. Diese Bedingung wird in der Praxis nicht selten ignoriert; daraus erklären sich mitunter enttäuschend niedrige Korrelationen, obwohl der Zusammenhang zwischen x und y bisweilen trotzdem hoch ist. Ein einfaches Beispiel für einen hohen Zusammenhang trotz niedrigem Korrelationskoeffizienten ist die Fibonacci-Folge. Alle Zahlen der Fibonacci-Folge sind durch ihre Position in der Reihe durch eine mathematische Formel exakt determiniert (siehe die Formel von Jacques-Philippe-Marie Binet in Fibonacci-Folge). Der Zusammenhang zwischen der Positionsnummer einer Fibonacci-Zahl und der Größe der Zahl ist vollkommen determiniert. Dennoch beträgt der Korrelationskoeffizient zwischen den Ordnungsnummern der ersten 360 Fibonacci-Zahlen und den betreffenden Zahlen nur 0,20; das bedeutet, dass in erster Näherung nicht viel mehr als 4 % ( = 0,22) der Varianz durch den Korrelationskoeffizienten erklärt werden und 96 % der Varianz „unerklärt“ bleiben. Der Grund ist die Vernachlässigung der Linearitätsbedingung, denn die Fibonacci-Zahlen wachsen progressiv an: In solchen Fällen ist der Korrelationskoeffizient nicht korrekt interpretierbar. Eine mögliche Alternative, welche ohne die Voraussetzung der Linearität des Zusammenhangs auskommt, ist die Transinformation.
Signifikanzbedingung
Ein Korrelationskoeffizient > 0 bei positiver Korrelation bzw. < 0 bei negativer Korrelation zwischen x und y berechtigt nicht a priori zur Aussage, es bestehe ein statistischer Zusammenhang zwischen x und y. Eine solche Aussage ist nur gültig, wenn der ermittelte Korrelationskoeffizient signifikant ist. Der Begriff 'signifikant' bedeutet hier 'signifikant von Null verschieden'. Je höher die Anzahl der Wertepaare (x, y) und das Signifikanzniveau sind, desto niedriger darf der Absolutbetrag eines Korrelationskoeffizienten sein, um zur Aussage zu berechtigen, zwischen x und y gebe es einen linearen Zusammenhang. Ein t-Test zeigt, ob die Abweichung des ermittelten Korrelationskoeffizient von Null auch signifikant ist.
Bildliche Darstellung und Interpretation
Sind zwei Merkmale vollständig miteinander korreliert (d. h. | r | = 1), so liegen alle Messwerte in einem 2-dimensionalen Koordinatensystem auf einer Geraden. Bei einer perfekten positiven Korrelation (r = + 1) steigt die Gerade; wenn die Merkmale perfekt negativ miteinander korreliert sind (r = − 1), sinkt die Gerade. Besteht zwischen zwei Merkmalen eine sehr hohe Korrelation, sagt man oft auch, sie erklären dasselbe.
Je näher der Betrag von r bei 0 liegt, desto kleiner der lineare Zusammenhang. Für r = 0 kann der statistische Zusammenhang zwischen den Messwerten nicht mehr durch eine eindeutig steigende oder sinkende Gerade dargestellt werden. Dies ist z. B. der Fall, wenn die Messwerte rotationssymmetrisch um den Mittelpunkt verteilt sind. Dennoch kann dann ein nicht-linearer statistischer Zusammenhang zwischen den Merkmalen gegeben sein. Umgekehrt gilt jedoch: Wenn die Merkmale statistisch unabhängig sind, nimmt der Korrelationskoeffizient stets den Wert 0 an.
Der Korrelationskoeffizient ist kein Indiz eines ursächlichen (d. h. kausalen) Zusammenhangs zwischen den beiden Merkmalen: Die Besiedlung durch Störche im Süd-Burgenland korreliert zwar positiv mit der dortigen Geburtenzahl, doch das bedeutet noch lange keinen kausalen Zusammenhang. Trotzdem ist ein statistischer Zusammenhang gegeben. Dieser leitet sich aber aus einem dritten, vierten etc. Faktor ab, wie in unserem Beispiel der Industrialisierung, der Wohlstandssteigerung, die einerseits den Lebensraum der Störche einschränkten und andererseits zu einer Verringerung der Geburtenzahlen führten.
Der Korrelationskoeffizient kann schon gar kein Indiz über die Richtung eines Zusammenhanges sein: Steigen die Niederschläge durch die höhere Verdunstung oder steigt die Verdunstung an, weil die Niederschläge mehr Wasser liefern? Bedingt das eine das andere möglicherweise in beiderlei Richtung?
Ob ein gemessener Korrelationskoeffizient als groß oder klein interpretiert wird, hängt stark von der Art der untersuchten Daten ab. Bei psychologischen Fragebogendaten werden z. B. Werte bis ca. 0,3 häufig als klein angesehen, während man ab ca. 0,8 von einer sehr hohen Korrelation spricht.
Das Quadrat des Korrelationskoeffizienten r2 nennt man Bestimmtheitsmaß. Es gibt in erster Näherung an, wieviel Prozent der Varianz, d. h. an Unterschieden der einen Variable durch die Unterschiede der anderen Variable erklärt werden können. Beispiel: Bei r = 0,3 bzw. 0,8 werden 9 % bzw. 64 % der gesamten auftretenden Varianz im Hinblick auf einen statistischen Zusammenhang erklärt.
Verteilung des Korrelationskoeffizienten
Korrelationskoeffizienten sind nicht normalverteilt. Sie verteilen sich eingipfelig nach rechts verzerrt (rechtssteil oder auch linksschief). Vor der Berechnung von Vertrauensbereichen (Konfidenzintervallen) muss daher erst eine Korrektur der Verteilung mit Hilfe der Fisher-Transformation (s.u.) vorgenommen werden. Die transformierten Korrelationen sind dann annähernd normalverteilt. Das so errechnete Konfidenzintervall wird danach wieder auf die ursprünglichen Korrelationen zurückgeführt. Konfidenzintervalle von Korrelationen liegen in aller Regel unsymmetrisch bezüglich ihres Mittelwerts.
Partieller Korrelationskoeffizient
Eine Korrelation zwischen zwei Zufallsvariablen X und Y kann unter Umständen auf einen gemeinsamen Einfluss einer dritten Zufallsvariablen U zurück geführt werden. Um solch einen Effekt zu messen, gibt es das Konzept der partiellen Korrelation. Die „partielle Korrelation von X und Y unter U“ ist gegeben durch
Das folgende Bild zeigt ein Beispiel:
Zwischen X und Y besteht eine merkliche Korrelation. Betrachtet man die beiden rechten Plots, so erkennt man, dass X und Y jeweils stark mit U korrelieren. Die beobachtete Korrelation zwischen X und Y basiert nun fast ausschließlich auf diesem Effekt.
Fisher-Transformation
Der Korrelationskoeffizient r ist rechtssteil unimodal verteilt. Durch die Transformation
ist f(r) annähernd normalverteilt. Das auf Basis dieser Normalverteilung errechnete Konfidenzintervall der Form
wird sodann retransformiert zu
Das Konfidenzintervall für die Korrelation lautet sodann
 .
.
Schätzung der Korrelation zwischen nicht-metrischen Variablen
Die Schätzung der Korrelation mit dem Korrelationskoeffizient nach Pearson setzt voraus, dass beide Variablen intervallskaliert und normalverteilt sind. Dagegen können die Rangkorrelationskoeffizienten immer dann zur Schätzung der Korrelation verwendet werden, wenn beide Variablen mindestens ordinalskaliert sind. Die Korrelation zwischen einer dichotomen und einer intervallskalierten und normalverteilten Variablen kann mit der punktbiserialen Korrelation geschätzt werden. Die Korrelation zwischen zwei dichotomen Variablen kann mit dem Vierfelderkorrelationskoeffizienten geschätzt werden. Hier kann man die Unterscheidung treffen, dass bei zwei natürlich dichotomen Variablen die Korrelation sowohl durch den Odds Ratio (OR) als auch durch den Phi-Koeffizient berechnet werden kann. Eine Korrelation aus zwei ordinal oder einer intervall und einer ordinal gemessenen Variablen ist mit Spearman's Rho oder Kendall's Tau berechenbar.
Siehe auch
- Zusammenhangsmaß
- Bestimmtheitsmaß
- Transinformation
- Kontingenztafel
- Streudiagramm
- Kovarianz
- Faktorenanalyse
Literatur
- Hartung, Joachim: Statistik, 12. Auflage, Oldenbourg Verlag 1999, S. 561 f, ISBN 3-486-24984-3
- Zöfel, Peter: Statistik für Psychologen, Pearson Studium 2003, München, S. 154.
Weblinks
- http://mathworld.wolfram.com/CorrelationCoefficient.html – Darstellung des Korrelationskoeffizienten als Kleinste-Quadrate-Schätzer
- http://www.zotteljedi.de/software/kkf/index.xhtml – Demonstration der Kreuzkorrelation, wie sie in der digitalen Signalverarbeitung Anwendung findet, um verrauschte Signale zu finden.
Einzelnachweise
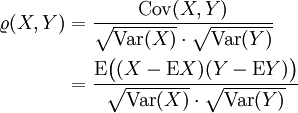

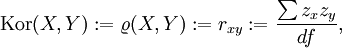
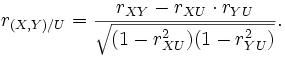



Wikimedia Foundation.