- MPEG-1 Audio Layer 3
-
MPEG-1 Audio Layer 3 Dateiendung .mp3MIME-Type audio/mpegMagische Zahl FFFB hex
\xFF\xFB (ASCII-C-Notation)Art Audio MP3 (MPEG-1 Audio Layer 3) ist ein Dateiformat zur verlustbehafteten Audiodatenkompression. MP3 bedient sich dabei der Psychoakustik mit dem Ziel, nur für den Menschen bewusst hörbare Audiosignale zu speichern. Dadurch wird eine Datenkompression möglich, welche die Audioqualität nicht oder nur gering beeinträchtigt. Das Format ist ein indirekter Vorgänger qualitativ und funktionell überlegener Formate wie AAC oder Vorbis.[1]
Inhaltsverzeichnis
Geschichte
Entwickelt wurde das Format MP3 ab 1982 von einer Gruppe um Karlheinz Brandenburg am Fraunhofer-Institut für Integrierte Schaltungen (IIS) in Erlangen sowie an der Friedrich-Alexander-Universität Erlangen-Nürnberg in Zusammenarbeit mit AT&T Bell Labs und Thomson. 1992 wurde es als Teil des MPEG-1-Standards festgeschrieben. Die Dateiendung .mp3 (als Abkürzung für ISO MPEG Audio Layer 3) wurde am 14. Juli 1995 nach einer institutsinternen Umfrage festgelegt.[2] Wie bei vielen der aktuellen Kodierverfahren, sind Kernbereiche von MP3 durch Patente geschützt. Prof. Dr. Brandenburg wurde für die Entwicklung dieses Datenformates mehrfach ausgezeichnet.
Patente und Lizenzstreitigkeiten
Die Fraunhofer-Gesellschaft und andere Firmen besitzen Softwarepatente auf Teilverfahren, die für MPEG-Kodierung eingesetzt werden. Ein alles umfassendes MP3-Patent gibt es nicht. Die Fraunhofer-Gesellschaft hat den größten Teil an der Entwicklung des MP3-Standards beigetragen und sich einige Verfahren zur MP3-Kodierung patentieren lassen. In einem Zusammenschluss mit Thomson besitzen beide Unternehmen 18 MP3-bezogene Patente. Seit September 1998, nachdem sich der MP3-Standard sechs Jahre lang hatte unbelastet etablieren können, verlangt FhG/Thomson Lizenzgebühren für die Nutzung des MP3-Formats.
Bei der Entwicklung des Formats soll auf Patente der Bell Laboratories zurückgegriffen worden sein. Diese Rechte liegen derzeit bei Alcatel-Lucent, die Bell Labs übernommen haben. Die Firma hat vor einigen Jahren Patentklagen gegen Microsoft, Dell und Gateway eingereicht. Im Verfahren gegen Microsoft wurden Lucent im Februar 2007 erstinstanzlich 1,52 Milliarden US-Dollar zugesprochen.[3] Dieses Urteil wurde allerdings im August 2007 vom Bundesbezirksgericht in San Diego aufgehoben.[4] Die Firma Sisvel erhebt im Auftrag von Philips ebenfalls Patentansprüche.
Verfahren
Wie die meisten verlustbehafteten Kompressionsformate für Musik nutzt MP3 sogenannte psychoakustische Effekte der Wahrnehmung aus. Zum Beispiel kann der Mensch zwei Töne erst ab einem gewissen Mindestunterschied der Tonhöhe (Frequenz) voneinander unterscheiden, und er kann vor und nach sehr lauten Geräuschen für kurze Zeit leisere Geräusche schlechter oder gar nicht wahrnehmen. Man braucht also nicht das Ursprungssignal exakt abzuspeichern, sondern es reichen die Signalanteile, die das menschliche Gehör auch wahrnehmen kann. Die Aufgabe des Kodierers ist es, das Signal so aufzuarbeiten, dass es weniger Speicherplatz benötigt, aber für das menschliche Gehör noch genauso klingt wie das Original.
Der Dekoder erzeugt aus diesen MP3-Daten dann ein für die überwiegende Anzahl von Hörern original klingendes Signal, das aber nicht mit dem Ursprungssignal identisch ist, da bei der Umwandlung in das MP3-Format Informationen entfernt wurden.
Während die Dekodierung stets einem festgelegten Algorithmus folgt, kann die Kodierung nach verschiedenen Algorithmen erfolgen (z. B. Fraunhofer-Encoder, LAME-Encoder) und liefert dementsprechend unterschiedliche akustische Ergebnisse. Die hörbaren Verluste hängen von der Qualität des Kodierers, von der Komplexität des Signals, von der Datenrate, von der verwendeten Audiotechnik (Verstärker, Verbindungskabel, Lautsprecher) und schließlich auch vom Gehör des Hörers ab. Das MP3-Format erlaubt neben festen Datenraten von 8 kbit/s bis zu 320 kbit/s auch beliebige freie Datenraten (Freeform-MP3). Die Qualitäts-Eindrücke sind recht subjektiv und von Mensch zu Mensch sowie von Gehör zu Gehör unterschiedlich. Die meisten Menschen können jedoch ab einer Bitrate von etwa 160 kBit/s und bei Nutzung eines ausgereiften Enkodierers auch bei konzentriertem Zuhören das kodierte Material nicht mehr vom Ausgangsmaterial unterscheiden.
Neben der Kodierung mit konstanter Datenrate (und damit schwankender Qualität) ist auch eine Kodierung mit konstanter Qualität (und damit schwankender Datenrate) möglich. Man vermeidet dadurch (weitgehend) Qualitätseinbrüche an schwierig zu kodierenden Musikstellen, spart jedoch andererseits bei ruhigen, oder gar völlig stillen Passagen des Audiostromes an der Datenrate und somit an der endgültigen Dateigröße. Man gibt die Qualitätsstufe[5] vor und erhält auf diese Art die dafür minimal notwendige Datei.
Datenkompression
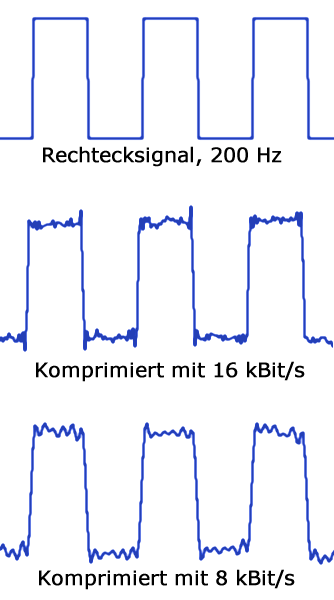
 Mit zwei verschiedenen Bitraten komprimiertes Rechtecksignal
Mit zwei verschiedenen Bitraten komprimiertes RechtecksignalSiehe auch: Audiodatenkompression mit Hilfe des psychoakustischen Modells
- Ein erster Schritt der Datenkompression beruht zum Beispiel auf der Kanalkopplung des Stereosignals durch Differenzbildung. Das ist ein verlustloses Verfahren, die Ausgangssignale können vollständig reproduziert werden. (siehe Mid/Side-Stereo unter Joint-Stereo)
- Nicht hörbare Frequenzen – das für einen Erwachsenen erfassbare Spektrum deckt etwa den Bereich 20 Hz bis 18 kHz ab – werden im fouriertransfomierten Datenmaterial abgeschnitten. Aus dem Abtasttheorem ergibt sich dabei die Forderung, die Abtastrate mindestens doppelt so hoch zu halten wie die Grenzfrequenz, um das ursprüngliche Signal rekonstruieren zu können. Wird eine geringere Abtastfrequenz verwendet, kann das Signal auch nur bis zur Hälfte dieser Frequenz rekonstruiert werden.
- Sogenannte Maskierungseffekte werden genutzt, um weitere Redundanzen zu beseitigen. Dabei werden vom Menschen nicht bewusst wahrgenommene Töne aus dem Signal weggelassen. Das können etwa schwache Frequenzanteile in der Nähe von starken Obertönen sein. Die größte Ersparnis liegt aber darin, dass die Töne nur gerade so genau (mit so vielen Bits) abgespeichert werden, dass das dadurch entstehende Quantisierungsrauschen noch maskiert wird und nicht hörbar ist.
- Die Daten, die in sogenannten Frames vorliegen, werden schließlich Huffman-entropiekodiert.
Bei starker Kompression werden auch hörbare Frequenzen von der Kompression erfasst, sie sind dann als Kompressionsartefakte hörbar.
Ein Designfehler ist, dass das Verfahren blockweise angewandt wird und so am Ende einer Datei Lücken entstehen können. Das stört beispielsweise bei Hörbüchern, in denen ein zusammenhängender Vortrag zum besseren Auffinden der Passagen in einzelne Tracks zerlegt wurde. Hier fallen die letzten Blöcke als störende Pausen auf. Abhilfe schafft die Verwendung des LAME-Encoders, der exakte Längeninformationen hinzufügt, in Kombination mit einem Abspielprogramm, das mit diesen umgehen kann, etwa foobar2000 oder Winamp. Einige Abspielprogramme wie Windows Media Player unterstützen Gapless Playback immer noch nicht. Apple iTunes unterstützt es ab Version 7[6].
Kompression im Detail
Als digitales Eingangssignal wird hier von einem Mono-Signal ausgegangen. Zu Beginn wird das digitale Audiosignal für jeden Frame mittels einer Mehrphasen-Filterbank in 32 gleichbreite Subbänder aufgeteilt. Ein solcher Frame beinhaltet 1152 Samples und ist somit in 36 Zeiteinheiten unterteilt (1152/32 = 36). Oft kommt es vor, dass Frequenzen in mehreren (benachbarten) Bändern gespeichert werden. Diese Redundanzen werden zu einem späteren Zeitpunkt wieder herausgefiltert.
Jedes Subband wird nun separat durch eine eindimensionale Kosinustransformation (MDCT) in eine Frequenzdarstellung übertragen. Die MDCT bringt eine 50 prozentige Überlappung mit sich. Transformiert und rücktransformiert man einen einzelnen Frame, so hat man ein abweichendes Ergebnis. Addiert man den vorherigen und nachfolgenden Frame partiell, so kürzen sich diese Fehler weg. Aus diesem Grund kann man die 36 Zeitwerte auf 18 reduzieren. Es entstehen somit 18 Frequenzbänder pro Subband. Der gesamte Frame enthält dann ein Spektrum von 576 (32·18) Frequenzbändern. Die dadurch entstehende Verschlechterung der zeitlichen Auflösung kann zu Pre-Echo-Effekten führen.
Als nächstes werden nun die entstandenen Redundanzen mittels der „Butterfly“-Berechnung (im MPEG-Standard enthalten) eliminiert. Dabei werden alle Frequenzen in den Subbandrändern miteinander verrechnet.
Die Daten für das psychoakustische Modell werden mittels einer Fast-Fourier-Transformation (FFT) erzeugt. Das geschieht zeitgleich zu der Aufspaltung des Signals in Subbänder, da die Daten des psychoakustischen Modells (Maskierungskurven) helfen, den bei der MDCT auftretenden Pre-Echo-Effekt auszugleichen.
Im nächsten Schritt findet die eigentliche Kodierung statt. Als Eingangsparameter dienen hier die von der MDCT erzeugten Frequenzbänder, die Maskierungskurven aus dem psychoakustischen Modell und die vom Anwender eingestellte Bitrate. Die Datenrate wird für jeden Frame separat gespeichert. Das ermöglicht eine Kodierung mit variabler Datenrate. Die Frequenzbänder werden nun nicht-linear quantisiert (diskretiert) und anschließend Huffman-kodiert (komprimiert). Hier findet also eine erhebliche Datenreduktion statt. Anhand der Maskierungskurve des psychoakustischen Modells lässt sich die Quantisierungsqualität beurteilen.
Ein fertig kodiertes MP3-Frame besteht nun aus einem 32 Bit großen Header, der zum Hin- und Herspringen in der MP3-Datei benötigt wird (also zum Vor- und Zurückspulen). Im Kapitel Spezifikation wird der Header im Detail aufgeschlüsselt. Diesem Header folgen dann die Seiteninformationen, die zur Dekomprimierung benötigt werden. Diese setzen sich aus den Huffman-Tabellen, der Quantisierungschrittgröße und den MDCT-Blockgrößen zusammen. Danach folgen die eigentlichen Audio-Daten, also die kodierten Frequenzen.
Dekompression
Bei der Dekompression werden die Schritte der Kompression in umgekehrter Reihenfolge ausgeführt. Nach der Huffman-Dekodierung werden die Daten mittels inverser Quantisierung für die inverse modifizierte Cosinustransformation (IMCT) aufbereitet. Diese leitet ihre Daten weiter zu einer inversen Filterbank, welche nun die ursprünglichen Samples berechnet (natürlich verlustbehaftet durch die Quantisierung im Kodierprozess).
Weiterentwicklung
MP3 ist ein besonders im Internet viel verwendetes Format. In der Industrie wird es hauptsächlich für PC-Spiele-Software verwendet. Es handelt sich um ein proprietäres Format, das als Nachfolger von MP2 entwickelt und in letzter Minute in den ISO-Standard aufgenommen wurde.
In der Industrie wurde zu dieser Zeit schon an dem MDCT-basierten AAC gearbeitet, das sauberer entworfen ist und bei vergleichbarem Aufwand bessere Ergebnisse liefert. Manche sehen daher AAC als Weiterentwicklung von MP2.
Neben dieser Weiterentwicklung (in Richtung einer hochqualitativen Kodierung) gibt es auch Weiterentwicklungen, um bei sehr niedrigen Datenraten (weniger als 96 kbit/s) noch akzeptable Klangqualität zu erreichen. Vertreter dieser Kategorie sind mp3PRO sowie MPEG-4 AAC HE beziehungsweise AAC+. Transparenz ist mit diesen Verfahren allerdings nur durch High Definition (HD-) AAC erreichbar (AAC LC + SLS).
_label_svg.png) Zeichen für 5.1-Klang
Zeichen für 5.1-KlangDie Erweiterung um Multikanalfähigkeiten bietet das MP3-Surround-Format des Fraunhofer-Instituts für Integrierte Schaltungen IIS. MP3-Surround erlaubt die Wiedergabe von 5.1-Ton bei Bitraten, die mit denen von Stereoton vergleichbar sind, und ist zudem vollständig rückwärtskompatibel: So können herkömmliche MP3-Decoder das Signal in Stereo decodieren, MP3-Surround-Decoder aber vollen 5.1-Surround-Klang erzeugen.
Dafür wird das Multikanal-Material zu einem Stereosignal gemischt und von einem regulären MP3-Encoder kodiert. Gleichzeitig werden die Raumklanginformationen aus dem Original als Surround-Erweiterungsdaten in das „Ancillary Data“-Datenfeld des MP3-Bitstroms eingefügt. Die MP3-Daten können dann von jedem MP3-Decoder als Stereosignal wiedergegeben werden. Der MP3-Surround-Decoder nutzt die eingefügten Erweiterungsdaten und gibt das volle Multikanal-Audiosignal wieder. Vergleichbar ist das Verfahren mit Dolby Surround pro Logic.
Weitere Entwicklungen betreffen Verfahren zum Urheberschutz (engl. Digital Rights Management, kurz DRM), das nach verschiedenen Quellen in zukünftigen Versionen implementiert werden soll.
Anwendung
Audio-Rohmaterial benötigt viel Speicherplatz (1 Minute Stereo in CD-Qualität benötigt etwa 10 MB) und zum Transfer (beispielsweise über das Internet) hohe Datenübertragungsraten und/oder viel Zeit. Die verlustlose Komprimierung reduziert die zu übertragenden Datenmengen nicht so stark wie verlustbehaftete Verfahren, die für die meisten Fälle (Ausnahmen sind beispielsweise Studioanwendungen oder Archivierung) noch annehmbare Qualität liefern. So erlangte das MP3-Format für Audio-Daten schnell den Status, den die JPEG-Komprimierung für Bilddaten hat.
MP3 wurde in der breiten Öffentlichkeit vor allem durch Musiktauschbörsen bekannt, wurde aber vor der Verbreitung preisgünstiger DVD-Brenner auch bei vielen DVD-Rips als Audioformat benutzt.
Ein weiterer Anwendungsschwerpunkt sind die sogenannten MP3-Player, mit denen man auch unterwegs Musik hören kann. MP3-Player unterscheiden sich untereinander im wesentlichen in der Speichertechnik, so gibt es Abspielgeräte mit Festplatten (beispielsweise iriver und die meisten iPod-Modelle), mit Festspeicher (Flash-Speicherung), mit verschiedenen Speicherkarten und mit CD oder Mini-CD als Speichermedium.
Im WWW finden sich zahlreiche Anwendungen zur MP3-Technik, von selbstkomponierter Musik über (selbst)gesprochene Hörbücher, Hörspiele, Vogelstimmen und andere Klänge bis hin zum Podcasting. Musiker können nun auch ohne einen Vertrieb ihre Musik weltweit verbreiten und Klangaufnahmen ohne großen Aufwand (abgesehen von den GEMA-Gebühren, auch auf eigene Kompositionen, die bei der GEMA angemeldet sind) auf einer Website zur Verfügung stellen. Nutzer können über Suchmaschinen alle erdenklichen (nicht kommerziellen) Klänge und Musikrichtungen finden.
Auch bei multimedialer Software, vor allem bei PC-Spielen, werden die oft zahlreichen Audiodateien im MP3-Format hinterlegt. Zudem findet MP3 bei zahlreichen, meist kleineren Online-Musikläden Anwendung.
Tagging
Im Gegensatz zu moderneren Codecs boten MP3-Dateien ursprünglich keine Möglichkeit, abgesehen vom Dateinamen, Metadaten (beispielsweise Titel, Interpret, Album, Jahr, Genre) zu dem enthaltenen Musikstück zu speichern.
Unabhängig vom Entwickler des Formats wurde dafür eine Lösung gefunden, die von fast allen Soft- und Hardwareplayern unterstützt wird: Die ID3-Tags werden einfach an den Anfang oder das Ende der MP3-Datei gehängt. Die erste Version (ID3v1) wird am Ende angehängt und ist auf 30 Zeichen pro Eintrag und wenige Standard-Einträge beschränkt. Die wesentlich flexiblere Version 2 (ID3v2) wird allerdings nicht von allen MP3-Playern (insbesondere Hardware-Playern) unterstützt, da sie am Anfang der MP3-Datei eingefügt wird. Zudem gibt es auch innerhalb von ID3v2 noch beträchtliche Unterschiede. Am weitesten verbreitet sind ID3v2.3 und ID3v2.4, wobei erst ID3v2.4 offiziell die Verwendung von UTF-8-kodierten Zeichen zulässt (vorher waren nur ISO-8859-1 und UTF-16 zulässig). Viele Hardwareplayer zeigen aber UTF-8-Tags nur als wirre Zeichen an. Da ID3v2-Tags am Anfang der Datei stehen, lassen sich diese Daten beispielsweise auch bei der Übertragung über HTTP lesen, ohne erst die ganze Datei zu lesen oder mehrere Teile der Datei anzufordern. Um zu vermeiden, dass bei Änderungen die ganze Datei neu geschrieben werden muss, verwendet man üblicherweise Padding, das heißt man reserviert im Vorfeld Platz für diese Änderungen.
Die Metadaten aus dem ID3-Tag können beispielsweise genutzt werden, um Informationen zum gerade abgespielten Stück anzuzeigen, die Titel in Wiedergabelisten (Playlists) zu sortieren oder Archive zu organisieren.
Spezifikation
- Frame-Header
Element Größe Beschreibung Sync 11 Bit alle Bits sind auf 1 gesetzt ID 2 Bit 0 = MPEG Version 2.5
1 = reserviert
2 = MPEG Version 2
3 = MPEG Version 1Layer 2 Bit 0 = reserviert
1 = Layer III
2 = Layer II
3 = Layer IProtection 1 Bit 0 = 16-Bit CRC nach dem Header
1 = keine CRCBitrate 4 Bit gemäß Bitraten-Tabelle Samplingfrequenz 2 Bit gemäß Sampling-Tabelle Padding 1 Bit 0 = Frame wird nicht aufgefüllt
1 = Frame mit Extraslot gefüllt
Slotgröße: Layer I = 32 Bits; Layer II+III 8 BitsPrivate 1 Bit nur informativ Kanalmodus 2 Bit 0 = Stereo
1 = Joint Stereo
2 = 2 Mono Kanäle
3 = ein Kanal (Mono)Mode-Extension 2 Bit (nur für Joint Stereo)
gemäß Mode-Extension-TabelleCopyright 1 Bit 0 = ohne Copyright
1 = mit CopyrightOriginal 1 Bit 0 = Kopie
1 = OriginalEmphasis 2 Bit 0 = keine
1 = 50/15 ms
2 = reserviert
3 = ITU-T J.17- Tabelle Bitraten (Angaben in kbps)
Wert MPEG 1, Layer I MPEG 1, Layer II MPEG 1, Layer III MPEG 2/2.5, Layer I MPEG 2/2.5, Layer II/III 0 freies Format 1 32 32 32 32 8 2 64 48 40 48 16 3 96 56 48 56 24 4 128 64 56 64 32 5 160 80 64 80 40 6 192 96 80 96 48 7 224 112 96 112 56 8 256 128 112 128 64 9 288 160 128 144 80 10 320 192 160 160 96 11 352 224 192 176 112 12 384 256 224 192 128 13 416 320 256 224 144 14 448 384 320 256 160 15 nicht erlaubt - Tabelle Samplingfrequenz
Wert MPEG 1 MPEG 2 MPEG 2.5 0 44100 Hz 22050 Hz 11025 Hz 1 48000 Hz 24000 Hz 12000 Hz 2 32000 Hz 16000 Hz 8000 Hz 3 reserviert - Tabelle Mode-Extension
Wert Layer I/II Layer III 0 Subbänder 4 bis 31 Intensity-Stereo: aus; M/S-Stereo: aus 1 Subbänder 8 bis 31 Intensity-Stereo: ein; M/S-Stereo: aus 2 Subbänder 12 bis 31 Intensity-Stereo: aus; M/S-Stereo: ein 3 Subbänder 16 bis 31 Intensity-Stereo: ein; M/S-Stereo: ein Auf den Frame-Header folgen die Frame-Daten (gegebenenfalls zunächst CRC), in denen die kodierten Audio-Daten enthalten sind.
Verbreitete Implementierungen
Zum Codieren von MP3-Dateien stehen der lizenzpflichtige Encoder der Fraunhofer-Gesellschaft und der Encoder des Open-Source-Projektes LAME zur Verfügung. Daneben existieren der Referenzencoder der ISO dist10 und weitere Projekte wie beispielsweise Xing, blade und Gogo.
Als Decoder stehen mpg123, MAD, libavcodec und weitere zur Verfügung.
Alternative Formate
Neben MP3 existieren zahlreiche weitere Audioformate.
Das Format Ogg-Vorbis (Dateiendung .ogg) ist quelloffen und wird von den Entwicklern als im Gegensatz zu MP3 patentfrei bezeichnet. Vorbis hat sich bei technischen Analysen und in Blindtests gegenüber MP3 vor allem in niedrigen und mittleren Bitratenbereichen als überlegen erwiesen, während im hohen Bereich (um 256 kbit/s) der Vorsprung minimal ist. Außerdem bietet Ogg-Vorbis Mehrkanal-Unterstützung, und das Containerformat Ogg erlaubt zudem auch Video- und Textdaten.[7]
Das freie, auf MP2-Algorithmen basierende Musepack (früher MPEGPlus) wurde entwickelt, um bei Bitraten über 160 kbit/s noch bessere Qualität als das MP3-Format zu ermöglichen. Es konnte sich aber nicht breit durchsetzen, da es auf die Anwendung im High-End-Bereich abzielt und im kommerziellen Bereich kaum unterstützt wird. Dateien im Musepack-Format erkennt man an der Erweiterung mpc oder mp+.[8]
Advanced Audio Coding (AAC) ist ein im Rahmen von MPEG-2 und MPEG-4 standardisiertes Verfahren, welches von mehreren großen Firmen entwickelt wurde. Apple und RealMedia setzen dieses Format für ihre Online-Musikläden ein, und die Nero AG stellt einen Encoder für das Format bereit. Mit faac ist auch ein freier Encoder erhältlich.[9] AAC ist bei niedrigen Bitraten bis etwa 160 kbit/s MP3 in der Klangqualität überlegen – je niedriger die Bitrate, desto deutlicher –, erlaubt Mehrkanal-Ton, und wird von der Industrie (z. B. bei Mobiltelefonen und MP3-Playern) breit unterstützt.
Triviales
Das Team um Brandenburg machte die ersten Praxistests mit der A-cappella-Version des Liedes Tom’s Diner von Suzanne Vega. Brandenburg hörte das Lied durch Zufall und empfand das Stück sogleich als geeignete Herausforderung für eine Audiodatenkompression.
Literatur
- Roland Enders: Das Homerecording Handbuch. 3. Auflage, Carstensen Verlag, München, 2003, ISBN 3-910098-25-8
- Hubert Henle: Das Tonstudio Handbuch. 5.Auflage, GC Carstensen Verlag, München, 2001, ISBN 3-910098-19-3
- Thomas Görne: Tontechnik. 1. Auflage, Carl Hanser Verlag, Leipzig, 2006, ISBN 3-446-40198-9
Einzelnachweise
- ↑ heise.de: c't-Hörtest: Voller Sound bei halbierter Dateigröße
- ↑ Fraunhofer.de: Hergang der Namensfestlegung
- ↑ heise.de: Microsoft sieht Hunderte von Firmen von MP3-Patentstreit betroffen
- ↑ heise.de: Microsoft erringt Erfolg im Streit um MP3-Patente
- ↑ http://www.audiohq.de/index.php?showtopic=20 AudioHQ über MP3-Qualität
- ↑ Apple.com: What is Gapless Playback (englisch)
- ↑ Digit-Life.com: OGG vs. LAME (englisch)
- ↑ hydrogenaudio.org: MPC vs VORBIS vs MP3 vs AAC at 180 kbps, 2nd checkup with classical music (englisch)
- ↑ SourceForge.net: Freeware Advanced Audio Coder (englisch)
Siehe auch
- Moving Picture Experts Group
- MP3-Encoder
- AAC, Nachfolger des MP3-Formats
- Audiograbber, CDex, Exact Audio Copy (Programme zum Umwandeln von Audio-CDs in komprimierte Audiodaten wie MP3)
- MPEG-1 Audio Layer 2
Weblinks
- Die MP3-Geschichte: Ein Blick ins Labor … aus der Sicht vom Fraunhofer IIS
- Fraunhofer-MP3-Seite
- Ausführliche MP3-Anleitung mit technischem Hintergrund
- Technische Spezifikation zum MP3-Codec
- Informationen zur Lizenzierung und Gebührenliste (englisch)
- Demosoftware und Informationen zu MP3-Surround
- Gemeinfreie historische MP3s
- MP3-Encoder im Überblick auf AudioHQ
- faac-Website
- Podcast „Grünes Glück“: Suzanne Vega über ihre Rolle als „Mutter von mp3“
_label.svg)
Wikimedia Foundation.